24年7月来自百度的论文“BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space”。
世界模型因其预测潜在未来场景的能力,在自动驾驶领域受到越来越多的关注。本文提出 BEVWorld,它将多模态传感器输入token化为统一且紧凑的鸟瞰图 (BEV) 潜空间,用于环境建模。世界模型由两部分组成:多模态 token化器和潜 BEV 序列扩散模型。多模态token化器首先对多模态信息进行编码,解码器能够以自监督的方式通过光线投射渲染将潜 BEV tokens重建为 LiDAR 和图像观测。然后,潜 BEV 序列扩散模型以动作tokens作为条件预测未来场景。
代码将在 GitHub - zympsyche/BevWorld 上提供。
近年来,自动驾驶取得了重大进展,但仍面临诸多挑战。首先,训练可靠的自动驾驶系统需要大量精确标注的数据,这需要大量资源和时间。因此,探索如何在自监督学习范式中利用未标注的多模态传感器数据至关重要。此外,可靠的自动驾驶系统不仅需要感知环境的能力,还需要全面了解环境信息以便做出决策。
解决这些挑战的关键,是构建一个用于自动驾驶的多模态世界模型。通过对环境进行建模,世界模型可以预测未来的状态和行为,使自主智体能够做出更复杂的决策。最近,一些世界模型已经证明了它们在自动驾驶中的实际意义[12,42,40]。然而,大多数方法都是基于单一模态的,无法适应当前的多传感器、多模态自动驾驶系统。由于多模态数据的异构性,将它们集成到统一的生成模型中并无缝适应下游任务仍然是一个尚未解决的问题。
BEVworld整体架构如图所示。给定一系列多视角图像和激光雷达观测 {ot−P , · · · , ot−1, ot, ot+1, · · · , ot+N },其中 ot 是当前观测,+/− 表示未来/过去观测,P/N 是过去/未来观测的数量,旨在预测 {ot+1, · · · , ot+N },条件是 {ot−P , · · · , ot−1, ot}。鉴于在原始观测空间中学习世界模型的计算成本很高,提出了一种多模态token化器,将多视角图像和激光雷达信息逐帧压缩到统一的 BEV 空间中。编码器-解码器结构和自监督重建损失保证适当的几何和语义信息很好地存储在 BEV 表示中。这种设计恰好为世界模型和其他下游任务提供了足够简洁的表示。
其世界模型被设计为基于扩散的网络,以避免像自回归那样出现错误累积的问题。它以自运动和 {xt−P , · · · , xt−1, xt}(即 {ot−P , · · · , ot−1, ot} 的 BEV 表示)为条件,学习在训练过程中添加到 {xt+1 , · · · , xt+N } 的噪声 {εt+1, · · · , εt+N }。在测试过程中,应用 DDIM [32] 调度程序从纯噪声中恢复未来的 BEV tokens。接下来,用多模态token化器的解码器来渲染出未来的多视图图像和激光雷达帧。
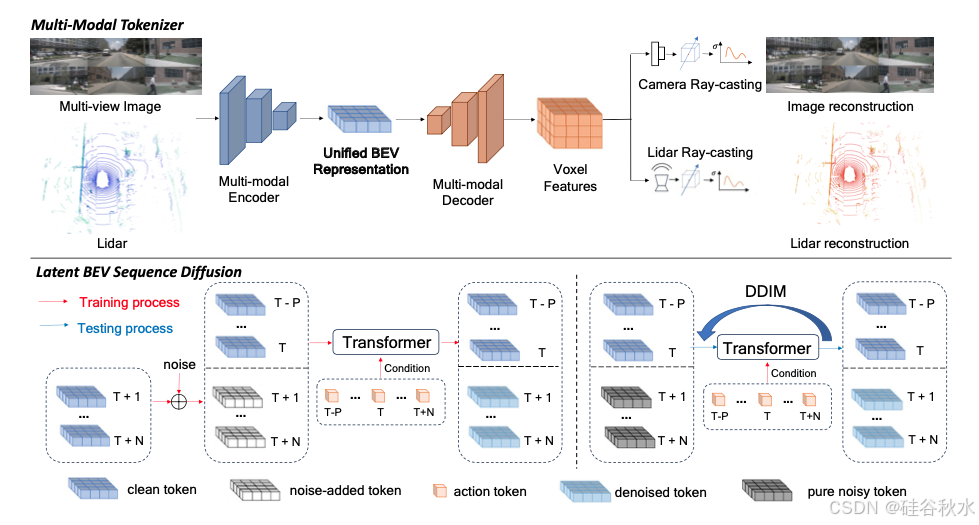
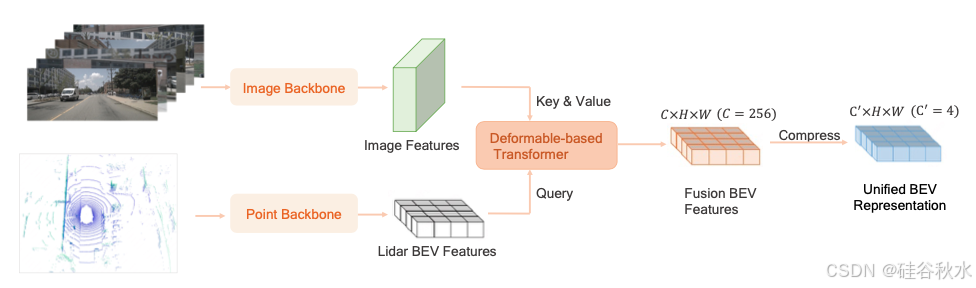
设计的多模态token化器包含三部分:BEV 编码器网络、BEV 解码器网络和多模态渲染网络。BEV 编码器网络的结构如图所示。为了使多模态网络尽可能同质,采用 Swin-Transformer [22] 网络作为图像主干来提取多图像特征。对于激光雷达特征提取,首先在 BEV 空间上将点云分割成柱 [19]。然后,用 Swin-Transformer 网络作为激光雷达主干来提取激光雷达 BEV 特征。用基于可变形的Transformer [46] 将激光雷达 BEV 特征和多视角图像特征融合在一起。具体来说,在柱的高度维上采样 K(K = 4)个点,并将这些点投影到图像上,采样相应的图像特征。采样的图像特征被视为V,并将激光雷达 BEV 特征作为可变形注意计算中的Q。考虑到未来预测任务需要低维输入,进一步将融合的 BEV 特征压缩为低维(C′ = 4)BEV 特征。
对于 BEV 解码器,直接使用解码器恢复图像和激光雷达存在歧义问题,因为融合的 BEV 特征缺少高度信息。为了解决这个问题,首先通过堆叠的上采样和 swin-blocks 层将 BEV token 转换为 3D 体素特征。然后用基于体素化的 NeRF 射线渲染来恢复多视角图像和激光雷达点云。
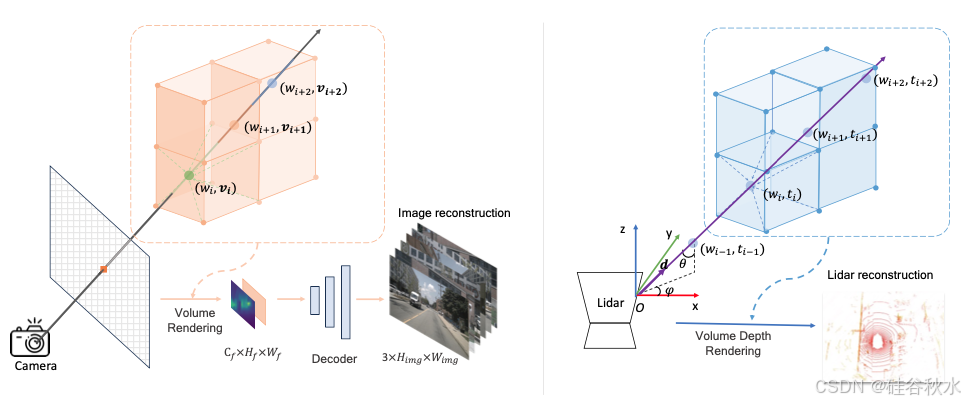
多模态渲染网络可以优雅地分为两个不同的部分,图像重建网络和激光雷达重建网络。对于图像重建网络,首先得到射线 r(t) = o + td,它从相机中心 o 沿方向 d 射向像素中心。然后沿射线均匀采样一组点 {(xi,yi,zi)}Nr,其中 Nr(Nr = 150) 是 沿射线采样的点总数。给定一个采样点 (xi , yi , zi ),根据其位置从体素特征中获取相应的特征 vi。然后,将射线中的所有采样特征聚合为逐像素特征描述子。遍历所有像素并得到图像的二维特征图 V。二维特征通过 CNN 解码器转换为 RGB 图像 Ig。为了提高生成图像的质量,添加了三种常见损失,即感知损失 [14]、GAN 损失 [8] 和 L1 损失。
对于激光雷达重建网络,射线定义在球面坐标系中,倾角为θ,方位角为φ。θ和φ是通过从激光雷达中心向激光雷达点当前帧进行拍摄获得的。以与图像重建相同的方式对点进行采样并获取相应的特征。由于激光雷达对深度信息进行编码,因此计算采样点的预期深度Dg(r),这样进行激光雷达模拟。
如图所示:左图是多视角图像渲染细节。对沿射线的一系列采样点应用三线性插值以获得权重 wi 和特征 vi。{vi} 分别由 {wi} 加权并相加以获得渲染后的图像特征,这些特征被连接起来并输入到解码器进行 8 倍上采样,从而产生多视角 RGB 图像。右图是激光雷达渲染细节。还应用三线性插值来获得权重 wi 和深度 ti。{ti} 分别由 {wi} 加权并相加以获得点的最终深度。然后将球面坐标系中的点变换到笛卡尔坐标系以获得原始激光雷达点坐标。
现有的大多数世界模型 [42, 12] 采用自回归策略来获得更长的未来预测,但这种方法很容易受到累积误差的影响。相反,本文提出潜序列扩散框架,该框架输入多帧噪声 BEV tokens并同时获取所有未来的 BEV tokens。
潜在序列扩散的结构如上第一图所示。在训练过程中,首先从传感器数据中获得低维 BEV tokens (xt−P , · · · , xt−1, xt, xt+1, · · · , xt+N )。多模态token化器中只有 BEV 编码器参与此过程,并且多模态token化器的参数被冻结。为了方便世界模型模块学习 BEV token 特征,沿通道维度 (xt−P,···,xt−1,xt,xt+1,···,xt+N) 标准化输入的 BEV 特征。最新历史 BEV tokens 和当前帧 BEV tokens (xt−P , · · · , xt−1, xt) 用作条件tokens,而 (xt+1, · · · , xt+N ) 则根据噪声 {ε } 扩散为 BEV tokens (xεt+1, · · · , xεt+N ) ,其中 t 是扩散过程的时间戳。
去噪过程由包含一系列transformer块的时空transformer执行,其架构如图所示。时空transformer的输入是条件 BEV tokens和噪声 BEV tokens (xt−P , · · · , xt−1, xt, xεt+1, · · · , xεt+N ) 的串联。这些tokens通过车辆运动和转向的动作tokens {ai} 进行调制,它们共同构成时空transformer的输入。
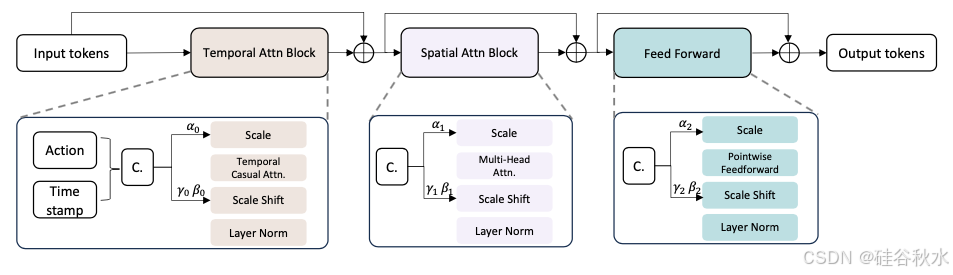
更具体地说,输入的 token 首先被传递到时域注意块以增强时间平滑度。为了避免时间混淆问题,在时域注意中添加了因果掩码。然后,时域注意块的输出被发送到空域注意块以获得准确的细节。空域注意块的设计遵循标准transformer块标准 [24]。动作 token 和扩散时间戳 {ti} 被连接起来作为扩散模型的条件 {ci},然后发送到 AdaLN [28] 调制 token 特征。
时空transformer的输出是噪声预测 {εi(x)}。在测试过程中,归一化的历史帧和当前帧 BEV token(xt−P , · · · , xt−1 , xt)和纯噪声 token(εt+1, εt+2, · · · , εt+N )被连接起来作为世界模型的输入。自运动tokens {ai },从时刻 T − P 到 T + N ,作为条件输入。
采用 DDIM [32] 的进度来预测后续的 BEV token。随后,将非规范化操作应用于预测的 BEV tokens,然后将其输入到 BEV 解码器和渲染网络中,从而产生一组全面的预测多传感器数据。
采用三阶段训练来预测未来的 BEV。1)下一次 BEV 的预训练。该模型使用 {xt-1, xt} 条件预测下一帧。在实践中,采用 nuScenes 的扫描数据来降低时间特征学习的难度。该模型训练 20000 次迭代,批次大小为 128。2)短序列训练。该模型预测扫描数据的 N(N = 5)个未来帧。在此阶段,网络可以学习如何执行短期(0.5 秒)特征推理。该模型训练 20000 次迭代,批次大小为 128。3)长序列微调。该模型使用 {xt-2,xt-1,xt} 条件预测关键帧数据 N(N = 6)个未来帧(3 秒)。该模型训练 30000 次迭代,批次大小为 128。三个阶段的学习率为 5e-4,优化器为 AdamW [23]。该方法在训练过程中没有引入无分类器指导 (CFG) 策略,以便更好地与下游任务集成,因为 CFG 需要额外的网络推理,这会使计算成本翻倍。
在Carla数据上,该模型使用批次大小为 32 的 nuScenes 预训练模型进行 30000 次迭代微调。初始学习率为 5e-4,优化器为 AdamW [23]。训练过程中未引入 CFG 策略,遵循与 nuScenes 相同的设置。
如图是在nuscenes上重建结果可视化例子:
如图是在Carla数据集上的重建结果例子:

