24年12月来自CMU、上海交大和Nvidia的论文“WebLLM: A High-Performance In-Browser LLM Inference Engine”。
大语言模型 (LLM) 的进步释放了非凡的功能。虽然部署这些模型通常需要服务器级 GPU 和基于云的推理,但最近出现的小型开源模型和功能日益强大的消费设备使设备部署变得切实可行。Web 浏览器作为设备部署的平台,是普遍可访问的,提供了自然的智体环境,并方便地抽象出来自不同设备供应商的不同后端。为了抓住这个机会,引入 WebLLM,这是一个开源 JavaScript 框架,可完全在 Web 浏览器中实现高性能 LLM 推理。WebLLM 提供 OpenAI 风格 API 以无缝集成到 Web 应用程序中,并利用 WebGPU 实现高效的本地 GPU 加速和 WebAssembly 实现高性能 CPU 计算。借助机器学习编译器 MLC-LLM 和 Apache TVM,WebLLM 利用优化的 WebGPU 内核,克服缺乏高性能 WebGPU 内核库的问题。评估表明,WebLLM 在同一设备上可保持高达 80% 的原生性能,并且还有进一步缩小差距的空间。
WebLLM 为在 Web 浏览器中实现普遍可访问、隐私保护、个性化和本地支持的 LLM 应用程序铺平道路。
WebLLM 概览如图所示:
大语言模型 (LLM) 的最新进展释放了诸多非凡的功能,例如问答、代码生成(Roziere 2023) 甚至推理(OpenAI 2024;Team 2024)。由于最强大的模型需要服务器级 GPU,因此这些模型通常在推理期间托管在云端。然而,开源提供商最近开始发布具有约 10 到 30 亿个参数的较小模型,这些模型可实现具有竞争力的性能(Grattafiori 2024;Abdin 2024;Team 2024;Hui 2024)。与此同时,消费设备的功能也越来越强大:4 位量化的 3B 模型在 Apple M3 笔记本电脑上每秒可解码 90 个 token。这些趋势使得设备上的 LLM 部署既有前景又实用。设备上部署可保护隐私、使用本地数据实现个性化,并解锁新范式,例如基于云和设备上部署共存的混合推理 (Qualcomm 2023)。
Web 浏览器是用于设备上部署有吸引力的平台,原因有三。首先,浏览器是一个自然的智体环境 (Zhou et al. (2023)),可用于管理日历、回复电子邮件和创建文档等任务——这些活动可能会由基于浏览器智体自动执行。其次,Web 浏览器是普遍可访问的:用户只需打开 URL 而无需安装任何其他软件。第三,浏览器抽象不同设备后端的复杂性。尽管移动设备来自不同的供应商,但基于浏览器的技术(例如 WebGPU)与后端无关。例如,开发人员无需为每个新的 LLM 运算符的每个后端 (例如 CUDA 和 Metal) 实现 GPU 内核,而只需在 WebGPU (Kenwright 2022) 中提供单个实现。
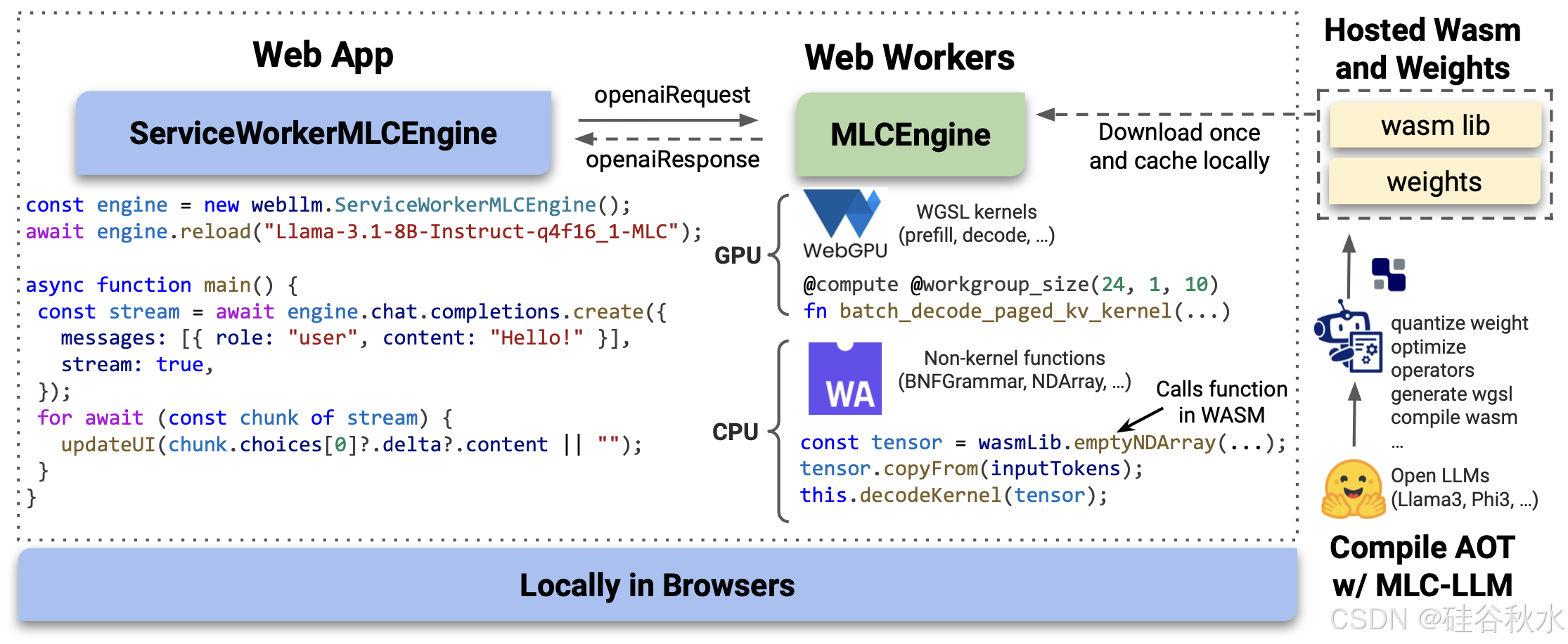
WebLLM 是一个 JavaScript 框架,可在客户端浏览器中本地部署 LLM,从而在 Web 应用程序中启用基于 LLM 的功能。实现这一目标面临三个挑战:WebLLM 需要 (1) 一个 Web 应用程序可以轻松合并的标准化 API;(2) 适应浏览器的运行时环境;(3) 高效的 GPU 加速。WebLLM 的架构通过将系统相应地分为三个部分来解决这些挑战:具有类似端点行为的面向用户引擎 ServiceWorkerMLCEngine、驻留在 Web 工作器(JavaScript 中的后台线程)中封装 MLCEngine 以及提前编译的高效 WebGPU 内核。
Web 开发人员在 Web 应用程序前端实例化轻量级 ServiceWorkerMLCEngine,并将其视为端点。引擎在指定时加载 LLM,随时接收 OpenAI 样式的请求,并以 OpenAI 样式的响应流回输出,Web 应用程序可以使用该响应来更新前端。
这种熟悉的端点式设计带来许多好处。端点式 API 是 JSON 输入 JSON 输出,因此具有明确定义的行为。此外,OpenAI 样式的 API 被广泛采用,使 WebLLM 易于集成到现有项目中。这种设计还允许 WebLLM 以最少的 API 更改来扩展到高级功能。 WebLLM 使用此 API 支持的高级功能包括:使用 JSON Schema 和上下文无关语法进行结构化生成 (Dong et al. 2024)、使用视觉语言模型进行图像输入 (Abdin et al. 2024;Hui et al. 2024),以及在同一引擎中加载多个模型以用于检索增强生成等应用 (Lewis et al. 2020)。
与大多数基于 C++ 或 Python 的 LLM 推理引擎不同,WebLLM 是用 JavaScript 实现的。这种非传统的 LLM 运行时环境要求 WebLLM 适应浏览器中提供的技术,以确保高性能。
Web 工作线程 LLM 工作负载计算量很大,如果在主线程上运行,可能会阻塞 UI。在 JavaScript 中,Web 工作线程用于将繁重的计算分离到后台线程中,以实现流畅的 UI。因此,WebLLM 通过两个引擎来利用 Web 工作线程:一个轻量级的前端引擎 ServiceWorkerMLCEngine,它暴露给 Web 应用程序,以及一个后端引擎 MLCEngine,它位于工作线程中,实际计算 LLM 工作负载。这两个引擎通过消息传递进行通信,消息只是 OpenAI 请求和响应。
WebGPU LLM 推理需要 GPU 加速。WebGPU 是一个 JavaScript API,允许 Web 应用程序在浏览器中利用设备的 GPU(Kenwright 2022)。 WebGPU 也与后端无关:同一个 WebGPU 内核可以在具有不同 GPU 供应商设备上运行,例如具有 M 芯片的 Apple 笔记本电脑和具有 NVIDIA GPU 的笔记本电脑。因此,WebLLM 利用 WebGPU 处理需要 GPU 的任何 LLM 推理工作负载。
WebAssembly 仅拥有 WebGPU 是不够的,因为 LLM 推理还需要在 CPU 上进行非平凡计算。WebAssembly (WASM) 是一种可移植的低级字节码,可以从 C++ 代码编译并在 JavaScript 运行时以接近原生的性能运行(Haas 2017)。因此,WebLLM 无需用 JavaScript 重新实现 CPU 工作负载,而是利用 Emscripten(Zakai 2011)将用 C++ 编写的高性能子系统编译成 WebAssembly,以应对 LLM 推理中的各种 CPU 工作负载,包括用于结构化生成的语法引擎(Dong et al. 2024)、分页 KV 缓存中的序列管理(Team 2023)和用于启动内核的张量操作(Chen et al. 2018)。这使得 WebLLM 可以重用 C++ 代码,而不会牺牲性能。
GPU 加速对于高性能 LLM 推理至关重要。WebGPU 提供一个标准化的 API 来利用 JavaScript 中的 GPU,并抽象出具有不同 GPU 供应商的设备。但是,与 CUDA 等本机后端不同,WebGPU 没有用于通用内核的加速 GPU 库。这使得为 WebGPU 编写高性能定制 GPU 内核(如 PagedAttention 和 FlashAttention)变得具有挑战性(Kwon 等人(2023 年),Dao 等人(2022 年))。
WebLLM 通过利用机器学习编译库 MLC-LLM 和 Apache TVM 来编译高性能 WebGPU 内核来解决此问题。MLC-LLM 接受任何开源模型的 Python 实现,它使用前面提到的 PagedAttention 和 FlashAttention 等技术,并将模型的计算编译到感兴趣的后端(在本例中为 WebGPU)。除了编译到指定目标之外,MLC-LLM 还提供图级优化(例如内核融合)和运算符级优化(例如 GEMM 平铺),以确保内核性能。
MLC-LLM 将开源模型转换为两个工件:转换后的权重和 WASM 库。WASM 库包含 WebAssmebly 中的 WebGPU 内核和非内核函数。WebLLM 加载的模型,提前编译并在线托管。