25年2月来自 DeepSeek-AI、北京大学和西雅图华盛顿大学的论文“Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention”。
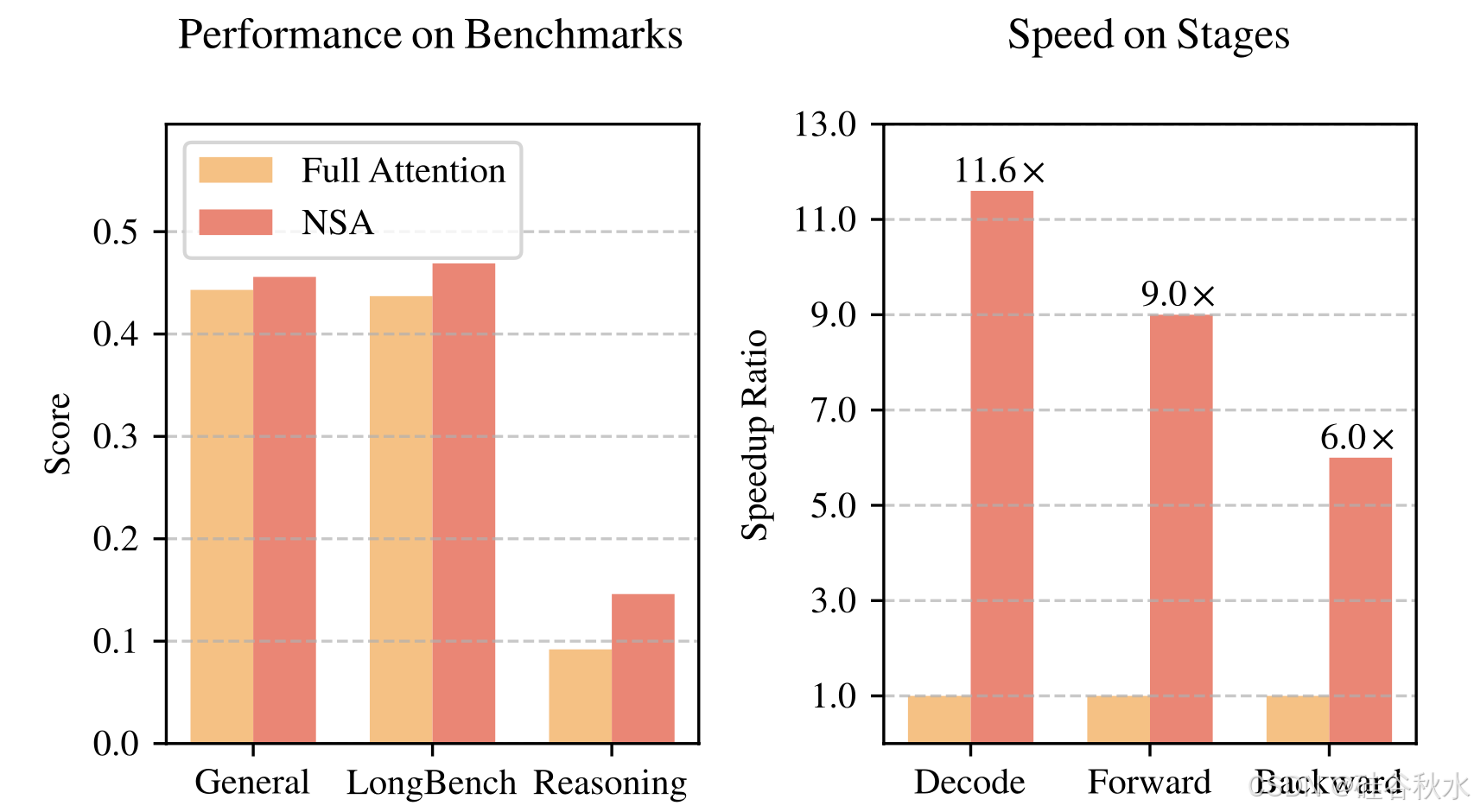
长上下文建模对于下一代语言模型至关重要,但标准注意机制的高计算成本带来巨大的计算挑战。稀疏注意为提高效率同时保持模型能力提供一个有希望的方向。NSA,一种原生可训练的稀疏注意机制,它将算法创新与硬件对齐的优化相结合,以实现高效的长上下文建模。NSA 采用动态分层稀疏策略,将粗粒度 tokens 压缩与细粒度 tokens 选择相结合,以保持全局上下文-觉察和局部精度。该方法通过两项创新推进稀疏注意设计:(1)通过算术-强度平衡的算法设计实现显着的加速,并针对现代硬件进行实现优化。(2)实现端到端训练,在不牺牲模型性能的情况下减少预训练计算。如图所示,实验表明,使用 NSA 预训练的模型在一般基准、长上下文任务和基于指令的推理中保持或超过全注意模型。同时,NSA 在 64k 长度序列的解码、前向传播和后向传播过程中实现比全注意机制显著的加速,验证其在整个模型生命周期中的效率。
研究界越来越认识到长上下文建模是下一代大语言模型的关键功能,其驱动力来自各种现实世界的应用,包括深度推理(DeepSeek-AI,2025;Zelikman,2022)、存储库-级代码生成(Zhang,2023a;Zhang)和多轮自主智体系统(Park,2023 年)。最近的突破包括 OpenAI 的 o 系列模型、DeepSeek-R1(DeepSeek-AI,2025)和 Gemini 1.5 Pro(Google,2024),使模型能够处理整个代码库、冗长的文档,在数千个 token 上保持连贯的多轮对话,并跨远程依赖关系执行复杂的推理。然而,随着序列长度的增加,普通注意机制(Vaswani,2017)的高复杂性(Za-heer,2020)成为关键的延迟瓶颈。理论估计表明,在解码 64k 长度的上下文时,使用 softmax 架构的注意计算占总延迟的 70-80%,这凸显对更高效注意机制的迫切需求。
高效长上下文建模的自然方法是利用 softmax 注意固有的稀疏性(Ge,2023;Jiang,2023),其中选择性计算关键Q-K对可以显着减少计算开销,同时保持性能。最近的进展通过多种策略证明这种潜力:K-V 缓存驱逐方法(Li,2024;Zhang,2023b;Zhou,2024)、分块 K-V 缓存选择方法(Tang,2024;Xiao,2024)以及基于采样、聚类或哈希的选择方法(Chen,2024;Desai,2024;Liu,2024)。尽管这些策略很有前途,但现有的稀疏注意方法在实际部署中往往达不到要求。许多方法未能实现与其理论收益相当的加速;此外,大多数方法主要侧重于推理阶段,缺乏有效的训练时间支持来充分利用注意的稀疏模式。
为了解决这些限制,部署有效的稀疏注意必须解决两个关键挑战:(1)与硬件对齐的推理加速:将理论上的计算减少转化为实际的速度提升需要在预填充和解码阶段进行硬件友好的算法设计,以缓解内存访问和硬件调度瓶颈;(2)训练-觉察算法设计:使用可训练的算子实现端到端计算,以降低训练成本,同时保持模型性能。这些要求对于实际应用实现快速的长上下文推理或训练至关重要。从这两个方面考虑,现有方法仍然存在明显差距。
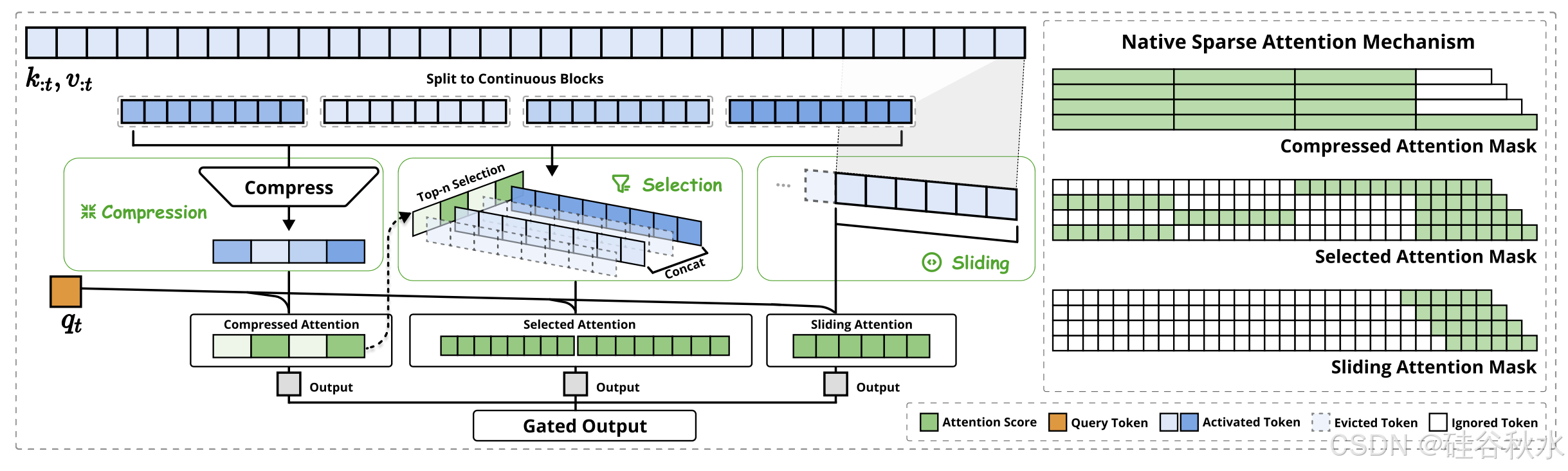
为了实现更有效、更高效的稀疏注意,提出 NSA,一种集成分层 token 建模的原生可训练稀疏注意架构。如图所示:
固定稀疏模式
滑动窗是一种常用的方法,它允许查询仅在固定窗口内计算注意。StreamingLLM (Xiao et al., 2023) 通过维护上下文的两个关键部分来解决处理长文本流的挑战:注意池(早期 token)和局部上下文窗。虽然这些方法有效地降低内存和计算成本,但它们忽略上下文的僵化模式限制它们在需要完全上下文理解任务上的性能。
动态 token 修剪
H2O (Zhang et al., 2023b) 实现一种自适应方法来减少解码过程中 KV 缓存的内存使用量。该方法根据注意得分,根据其最近的效用动态地逐出被认为对未来预测不太重要的 tokens。SnapKV (Li et al., 2024) 还引入一种 tokens 修剪策略,通过有选择地仅保留最重要的特征来减少 KV 缓存,从而实现高效的内存使用。 SnapKV 通过注意权重分析和预填充期间的投票来识别重要特征,然后通过将选定的压缩特征与最近的上下文相结合来更新 KV 缓存,以保持提示一致性。
查询-觉察选择
Quest (Tang et al., 2024) 采用分块选择策略,其中每个块的重要性由 Q 和 K 块的坐标最小值最大值之间乘积来估计。结果分数有助于为注意选择 top-𝑛 重要的 KV 块。InfLLM (Xiao et al., 2024) 通过维护注意池、局部上下文和可检索块,将固定模式与检索相结合。该方法从每个块中选择代表性 K 来估计块重要性。HashAttention (Desai et al., 2024) 通过使用学习的函数将 Q 和 K 映射到 Hamming 空间,将关键 tokens 识别公式化为推荐问题。 ClusterKV(Liu et al.,2024)通过首先对 K 进行聚类,然后根据 Q-群相似性,选择最相关的群进行注意计算来实现稀疏性。
现代稀疏注意方法在降低 Transformer 模型的理论计算复杂度方面取得重大进展。然而,大多数方法主要在推理过程中应用稀疏性,同时保留预训练的全注意主干,这可能会引入架构偏差,从而限制其充分利用稀疏注意优势的能力。
尽管在注意计算中实现稀疏性,但许多方法未能实现相应的推理延迟减少,这主要归因于两个挑战:
相位-限制稀疏性。诸如 H2O(Zhang,2023b)之类的方法在自回归解码期间应用稀疏性,而在预填充期间需要计算密集型预处理(例如注意图计算、索引构建)。相比之下,像 MInference(Jiang,2024)这样的方法只关注预填充稀疏性。这些方法未能在所有推理阶段实现加速,因为至少一个相位的计算成本与全注意(Full Attention)相当。相位专业化降低这些方法的加速能力,包括以预填充为主的工作负载,如书籍摘要和代码完成,或以解码为主的工作负载,如长链思维推理(Wei,2022)。
与高级注意架构不兼容。一些稀疏注意方法无法适应现代解码高效架构,如多查询注意 (MQA) (Shazeer,2019) 和分组查询注意 (GQA) (Ainslie,2023),它们通过在多个查询头之间共享 KV 显著减少解码过程中的内存访问瓶颈。例如,在 Quest (Tang,2024) 等方法中,每个注意力头独立选择其 KV 缓存子集。虽然它在多头注意 (MHA) 模型中表现出一致的计算稀疏性和内存访问稀疏性,但它在基于 GQA 等架构的模型中呈现出不同的场景,其中 KV 缓存的内存访问量对应于同一 GQA 组内所有查询头选择的并集。这种架构特性意味着虽然这些方法可以减少计算操作,但所需的 KV 缓存内存访问仍然相对较高。这种限制迫使人们做出一个关键的选择:虽然一些稀疏注意方法减少计算量,但它们分散的内存访问模式与高级架构的高效内存访问设计相冲突。
这些限制的出现是因为许多现有的稀疏注意方法专注于减少 KV 缓存或理论计算量,但难以在高级框架或后端实现显著的延迟减少。这促使去开发结合高级架构和硬件高效实现的算法,以充分利用稀疏性来提高模型效率。
对原生可训练稀疏注意的追求,源于对仅推理方法分析的两个关键见解:(1)性能下降:事后应用稀疏性会迫使模型偏离其预训练的优化轨迹。正如 Chen(2024)所证明的那样,前 20% 的注意只能覆盖总注意得分的 70%,使得预训练模型中的检索头等结构在推理过程中容易受到修剪。(2)训练效率要求:高效处理长序列训练对于现代 LLM 开发至关重要。这包括对较长文档进行预训练以增强模型容量,以及后续的适应阶段,例如长上下文微调和强化学习。然而,现有的稀疏注意方法主要针对推理,而训练中的计算挑战基本上没有得到解决。这种限制阻碍通过高效训练开发更强大的长上下文模型。此外,将现有的稀疏注意机制用于训练的努力也暴露出一些挑战:
不可训练的组件。ClusterKV(Liu,2024)(包括 k-均值聚类)和 MagicPIG(Chen,2024)(包括基于 SimHash 的选择)等方法中的离散操作,会在计算图中产生不连续性。这些不可训练的组件,会阻止 token 选择过程中的梯度流通过,从而限制模型学习最佳稀疏模式的能力。
低效的反向传播。一些理论上可训练的稀疏注意方法,存在实际训练效率低下的问题。HashAttention(Desai,2024)等方法中使用 token 粒度选择策略,导致需要在注意计算期间从 KV 缓存中加载大量单个 token。这种非连续内存访问阻碍 FlashAttention 等快速注意技术的有效适应,这些技术依赖于连续内存访问和分块计算来实现高吞吐量。因此,实现被迫回退到低硬件利用率,从而显著降低训练效率。
原生稀疏性是当务之急。推理效率和训练可行性的这些限制,促使对稀疏注意机制进行根本性的重新设计。NSA,这是一个原生稀疏注意框架,可同时满足计算效率和训练要求。
介绍一点儿背景知识。
注意机制广泛应用于语言建模,其中每个 Q token q_𝑡 都会计算与所有前面的 K k_:𝑡 的相关性分数,以生成 V 的加权和 v_:𝑡。注意计算如下:
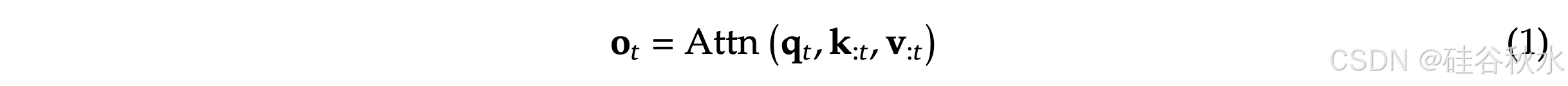
其中
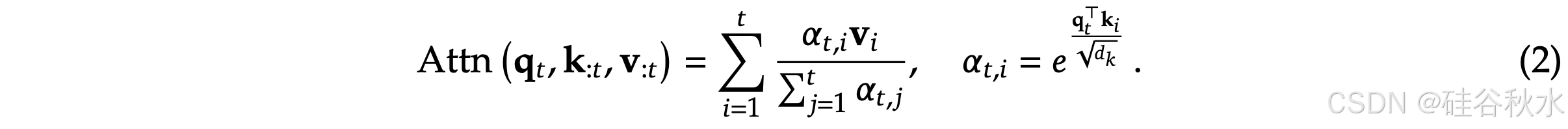
随着序列长度 t 的增加,注意计算在总体计算成本中变得越来越占主导地位,这对长上下文处理提出重大挑战。
算术强度是计算操作与内存访问的比率。它本质上决定硬件上的算法优化。每个 GPU 都有一个关键的算术强度,由其峰值计算能力和内存带宽决定,以这两个硬件限制的比率计算。对于计算任务,高于此临界阈值的算术强度,将成为计算限制(受 GPU FLOPS 限制),而低于此阈值的算术强度,将成为内存限制(受内存带宽限制)。
具体来说,对于因果自注意机制,在训练和预填充相位,分批矩阵乘法和注意计算,表现出高算术强度,使得这些阶段在现代加速器上成为计算限制。相反,自回归解码会受到内存带宽的限制,因为它每次前向传递都会生成一个 token,同时需要加载整个 KV 缓存,从而导致算术强度较低。这导致不同的优化目标——降低训练和预填充期间的计算成本,同时减少解码期间的内存访问。
总体框架的细节如下。
为了发挥自然稀疏模式的注意潜力,给定每个查询 q_𝑡,用一组更紧凑、信息密集的表示 K-V 对 𝐾 ̃_𝑡, 𝑉 ̃_𝑡 替换注意计算的原始 K-V 对 k_:𝑡 , v_:𝑡 。优化的注意计算如下:
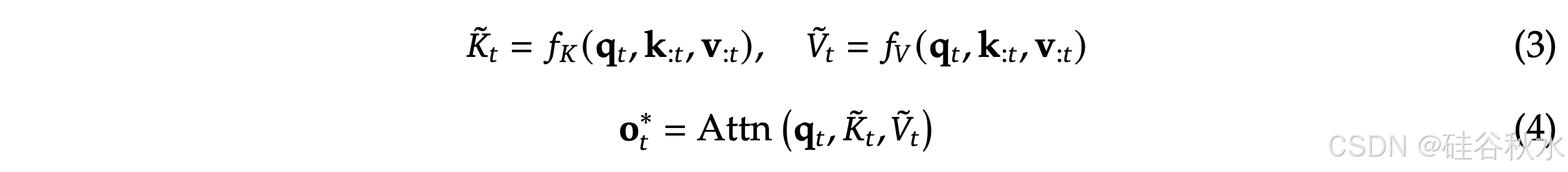
可以设计各种映射策略来获得不同类别的 𝐾 ̃𝑐_t 和 𝑉 ̃^𝑐_t,并将它们组合在注意计算如下:
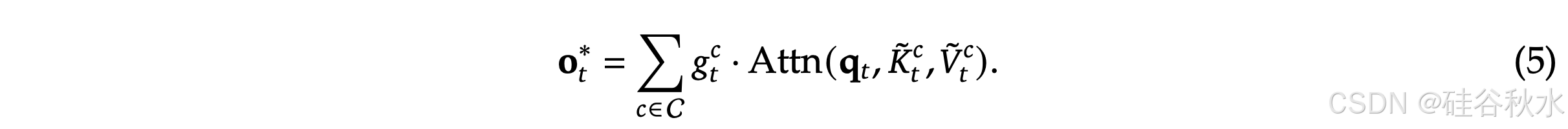
NSA 有三种映射策略 C = {cmp, slc, win},分别表示K和V的压缩、选择和滑动窗。𝑔_𝑡^𝑐 ∈ [0, 1] 是对应策略 𝑐 的门控分数,通过 MLP 和 S 形激活从输入特征中得出。让 𝑁_𝑡 表示重映射的 K/V 总数:
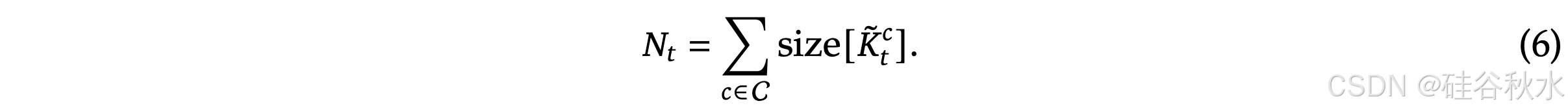
其中 𝑁𝑡 ≪ 𝑡 保持高稀疏比。
算法设计如下。
Token 压缩
通过将连续的 K 或 V 块聚合到块级表示中,获得捕获整个块信息的压缩 K 和 V。正式地,压缩 K 表示定义为:
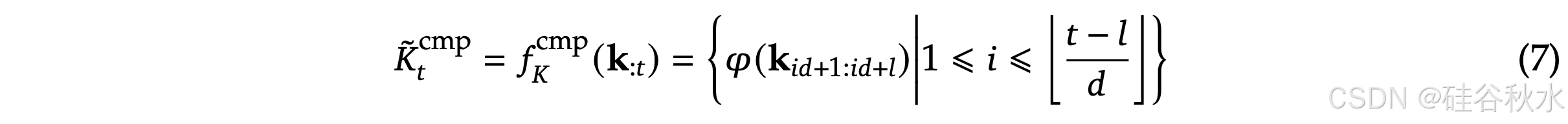
其中 𝑙 是块长度,𝑑 是相邻块之间的滑动步幅,𝜑 是具有块内位置编码的可学习 MLP,用于将块中的 K 映射到单个压缩 K。𝐾 ̃_𝑡cmp 是由压缩 K 组成的张量。通常采用 𝑑 < 𝑙 来缓解信息碎片化。压缩 V 表示 𝑉 ̃_t^cmp 具有类似的公式。压缩表示可捕获粗粒度的高级语义信息并减轻注意的计算负担。
Token 选择
仅使用压缩的 K 和 V 可能会丢失重要的细粒度信息,这促使有选择地保留单个 K 和 V。
分块选择。选择策略在空间连续块中处理 K 和 V 序列,其动机有两个关键因素:硬件效率考虑和注意分数的固有分布模式。分块选择对于在现代 GPU 上实现高效计算至关重要。这是因为与基于索引的随机读取相比,现代 GPU 架构在连续块访问方面表现出更高的吞吐量。此外,分块计算可以最佳地利用张量核(Tensor Cores)。这种架构特性已将分块内存访问和计算确立为高性能注意实现的基本原则,例如 FlashAttention 的基于块设计。分块选择遵循注意分数的固有分布模式。先前的研究(Jiang,2024)表明注意分数通常表现出空间连续性,这表明相邻的 K 往往具有相似的重要性级别。
为了实现分块选择,首先将K、V序列划分为选择块。为了确定对注意计算最重要的块,需要为每个块分配重要性分数。
重要性分数计算。计算块重要性分数可能会带来很大的开销。幸运的是,压缩 token 的注意计算,会产生中间注意分数,可以利用这些分数来得出选择块重要性分数,公式如下:
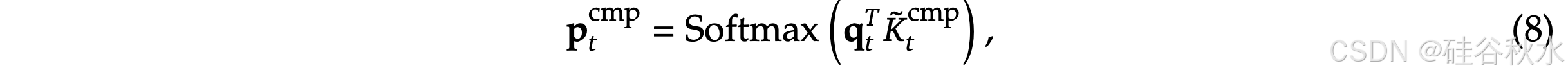
当压缩块和选择块共享相同的分块方案时,即 𝑙′ = 𝑙 = 𝑑,可以直接通过 p_tslc = p_tcmp 获得选择块重要性分数 p_t^slc。对于分块方案不同的情况,根据选择块的空间关系推导出重要性分数。给定 𝑑 | 𝑙 和 𝑑 | 𝑙′,有:
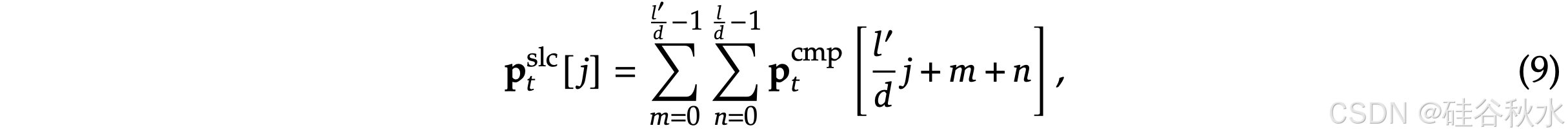
对于采用 GQA 或 MQA 的模型,其中 KV 缓存在查询头之间共享,必须确保这些头之间的块选择一致,以最大限度地减少解码期间的 KV 缓存加载。组中各个头之间的共享重要性分数正式定义为:
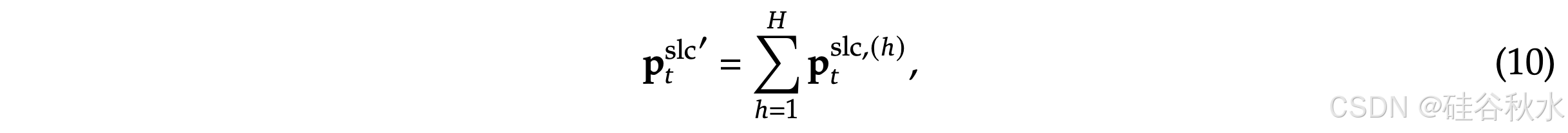
这种聚合可确保同一组内各个头的块选择一致。
Top-𝑛 块选择。获得选择块重要性分数后,按块重要性分数排序保留 top-𝑛 稀疏块内的 tokens,公式如下:
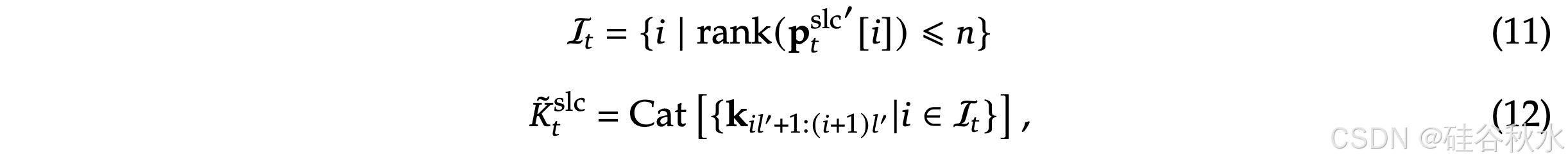
滑动窗
在注意机制中,局部模式通常适应得更快,并且可以主导学习过程,从而可能阻止模型有效地从压缩和选择 token 中学习。为了解决这个问题,引入一个专用的滑动窗分支,该分支明确处理局部上下文,允许其他分支(压缩和选择)专注于学习各自的特征,而不会被局部模式所捷径。具体来说,在窗口 𝑤 中维护最近的 tokens 𝐾 ̃_t^win = k_𝑡−𝑤:𝑡, 𝑉 ̃_t^win = v_𝑡−𝑤:𝑡,并将不同信息源(压缩 tokens 和选择 tokens、滑动窗)的注意计算,隔离到单独的分支中。然后通过学习门控机制聚合这些分支输出。为了进一步防止在边际计算开销下跨注意分支进行捷径学习,为三个分支提供独立的 K 和 V。这种架构设计,通过防止局部和远程模式识别之间的梯度干扰,实现稳定的学习,同时将开销降至最低。
在获得所有三类 K 和 V(𝐾 ̃_tcmp,𝑉 ̃_tcmp;𝐾 ̃_tslc,𝑉 ̃_tslc;𝐾 ̃_twin,𝑉 ̃_t^win)后,按照公式(5)计算最终的注意输出。和前述的压缩、选择和滑动窗口机制一起,构成 NSA 的完整算法框架。
下面谈内核设计。
为了在训练和预填充期间实现 FlashAttention 级别加速,在 Triton 上实现硬件对齐的稀疏注意内核。鉴于 MHA 占用大量内存且解码效率低下,专注于遵循当前最先进 LLM 的共享 KV 缓存架构,如 GQA 和 MQA。虽然压缩和滑动窗注意计算与现有的 FlashAttention-2 内核很容易兼容,但引入专门用于稀疏选择注意的内核设计。
如果遵循 FlashAttention 将时间连续的查询块加载到 SRAM 中的策略,则会导致内存访问效率低下,因为块内的查询可能需要不相交的 KV 块。为了解决这个问题,关键优化在于不同的查询分组策略:对于查询序列上的每个位置,将 GQA 组内的所有查询头(它们共享相同的稀疏 KV 块)加载到 SRAM 中。如图说明前向传递的实现。
提出的内核架构具有以下主要特点:
以组为中心的数据加载。对每个内循环,加载位置 𝑡 的组中所有头查询 𝑄 及其共享的稀疏 K/V 块索引 I_𝑡 。
共享 KV 获取。在内循环中,按顺序将索引为 I 的连续键/值块加载到 SRAM 中作为 𝐾、𝑉,以最小化内存加载,其中 𝐵_𝑘 是满足 𝐵_𝑘|𝑙′ 的内核块大小。
网格外循环。由于内循环长度(与选定的块数 𝑛 成比例)对于不同的查询块几乎相同,将查询/输出循环放在 Triton 的网格调度器(grid scheduler)中以简化和优化内核。
通过 (1) 通过分组共享消除冗余的 KV 迁移,以及 (2) 在 GPU 流式多处理器之间平衡计算工作负载,该设计实现近乎最佳的算术强度。
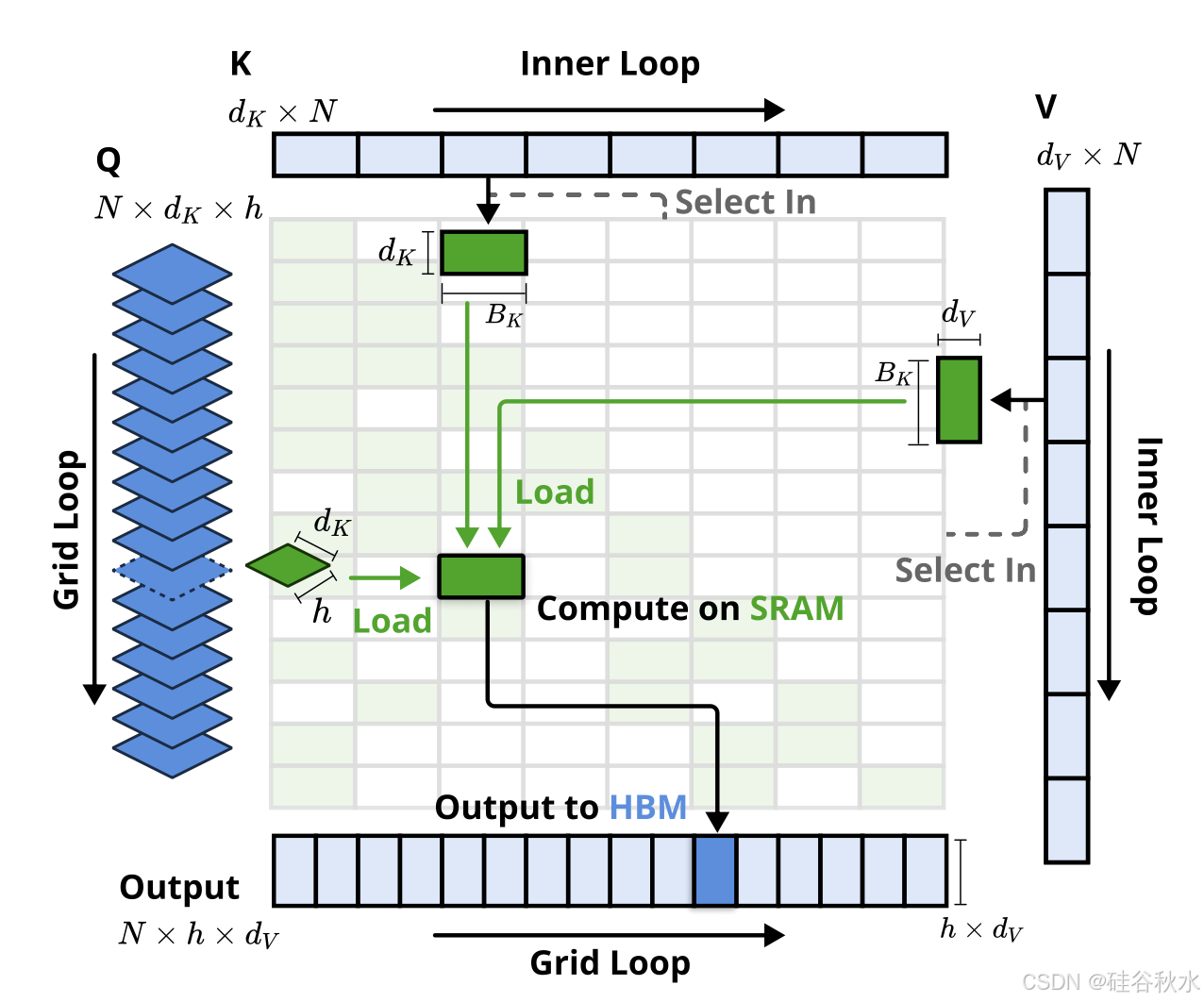
预训练设置。按照最先进 LLM 中的常见做法,实验采用结合分组查询注意 (GQA) 和混合专家 (MoE) 的主干,具有 27B 总参数和 3B 活动参数。该模型由 30 层组成,隐藏维度为 2560。对于 GQA,将组数设置为 4,总共有 64 个注意头。对于每个头,Q、K 和 V 的隐藏维度分别配置为 𝑑_𝑞 = 𝑑_𝑘 = 192,𝑑_𝑣 = 128。对于 MoE,利用 DeepSeekMoE(Dai,2024;DeepSeek-AI,2024)结构,其中有 72 位路由专家和 2 位共享专家,并将 top-k 专家设置为 6。为了确保训练稳定性,第一层的 MoE 被 SwiGLU 形式的 MLP 取代。 所提出的架构在计算成本和模型性能之间实现有效的权衡。对于 NSA,设置压缩块大小 𝑙 = 32、滑动步幅 𝑑 = 16、选定块大小 𝑙′ = 64、选定块数 𝑛 = 16(包括固定激活 1 个初始块和 2 个局部块)和滑动窗口大小 𝑤 = 512。全注意模型和稀疏注意模型均在 8k 长度文本的 270B 个 tokens 上进行预训练,然后使用 YaRN(Peng et al., 2024)在 32k 长度文本上进行继续训练和监督微调,以实现长上下文自适应。两种模型都经过训练以完全收敛,以确保公平比较。
如图所示,NSA 和全注意基线的预训练损失曲线,呈现稳定而平滑的下降趋势,NSA 的表现始终优于全注意模型。
在 8-GPU A100 系统上评估 NSA 相对于全注意的计算效率。在效率分析中,还将模型配置为 GQA 组 𝑔 = 4、每组头 h = 16、Q/K 维度 𝑑_𝑘 = 192 和 V 维度 𝑑_𝑣 = 128。按照前述的相同设置,NSA 压缩块大小 𝑙 = 32、滑动步幅 𝑑 = 16、选择的块大小 𝑙′ = 64、选择的块数 𝑛 = 16 和滑动窗大小 𝑤 = 512。
替代 Token 选择策略的挑战
在设计 NSA 之前,探索了将现有的稀疏注意方法应用于训练阶段。然而,这些尝试遇到各种挑战,促使设计一种不同的稀疏注意架构:
基于K-聚类的策略。研究基于聚类的策略,如 ClusterKV(Liu,2024)。这些方法将来自同一群的 K 和 V 存储在连续的内存区域中。虽然理论上可用于训练和推理,但它们面临三个重大挑战:(1)动态聚类机制引入的非平凡计算开销;(2)群间不平衡加剧算子优化困难,尤其是在混合专家 (MoE) 系统中,其中倾斜的专家并行 (EP) 组执行时间导致持续的负载不平衡;(3)由于需要强制定期重聚类和块顺序训练协议而产生的实施限制。这些综合因素造成巨大的瓶颈,严重限制它们在实际部署中的有效性。
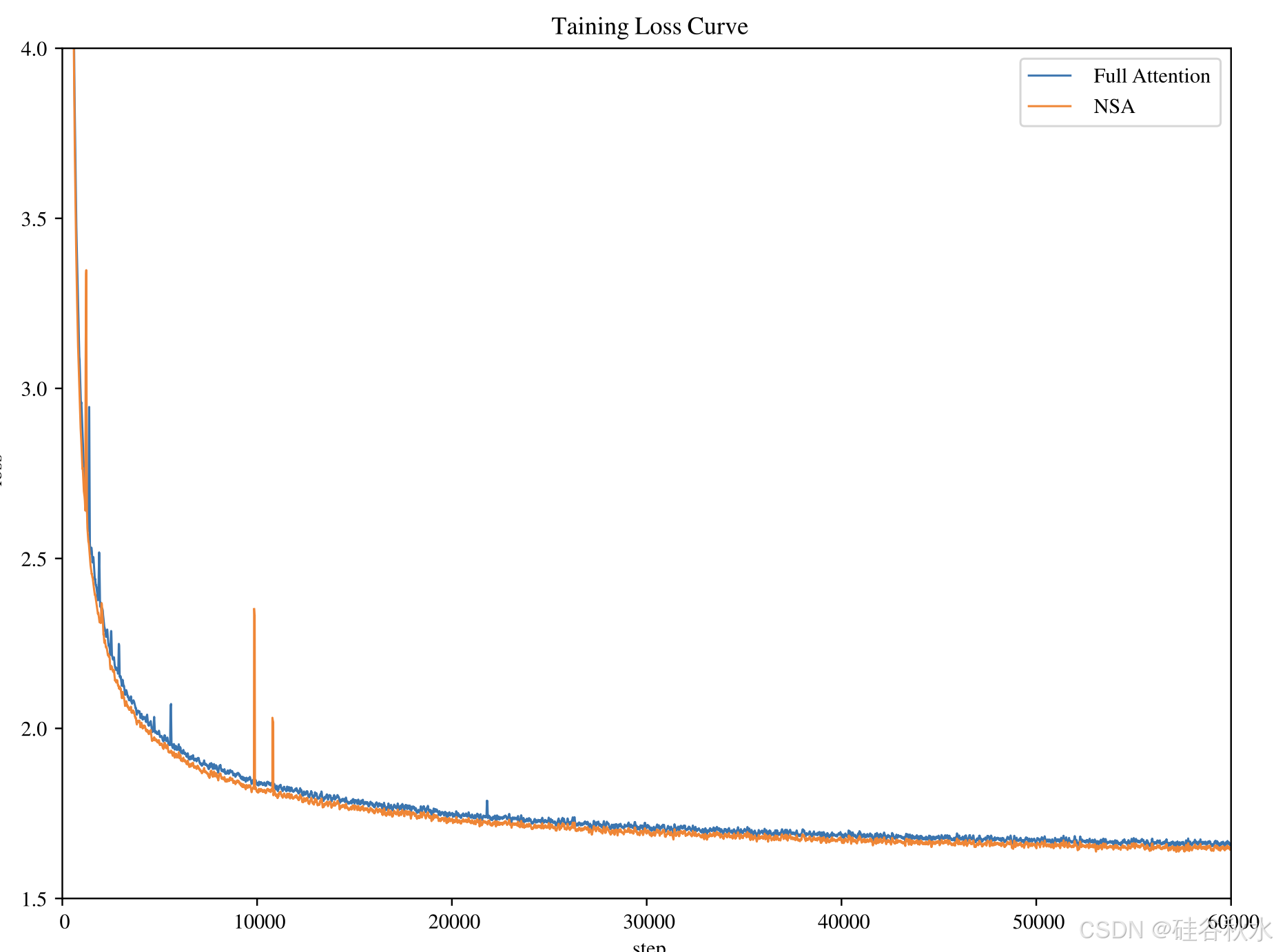
其他分块选择策略。还考虑不同于 NSA 的分块 K-V 选择策略,例如 Quest(Tang,2024)和 InfLLM(Xiao,2024)。这些方法依赖于计算每个块的重要性分数,并根据它们与 𝑞_𝑡 的相似性选择前 𝑛 块。然而,现有的方法面临两个关键问题:(1)由于选择操作不可微,基于神经网络的重要性分数计算依赖于辅助损失,这会增加算子开销并经常降低模型性能;(2)启发式无参数重要性分数计算策略的召回率低,导致性能不佳。在具有相似架构的 3B 参数模型上评估这两种方法,并将它们的损失曲线与 NSA 和全注意进行比较。对于基于辅助损失的选择方法,为每个块引入额外的 Q 和代表性 K 来估计块重要性分数。这些分数由每个块内原始 Q 和 K 之间的平均注意分数监督。对于启发式无参数选择方法,遵循 Quest 的策略,使用 Q 和 K 块坐标最小最大值之间的乘积来实现直接选择,而不引入其他参数。还探索一种冷启动训练方法,其中在过渡到启发式块选择之前,在最初的 1000 步中应用全注意。如图所示,两种方法都表现出较低的损失。
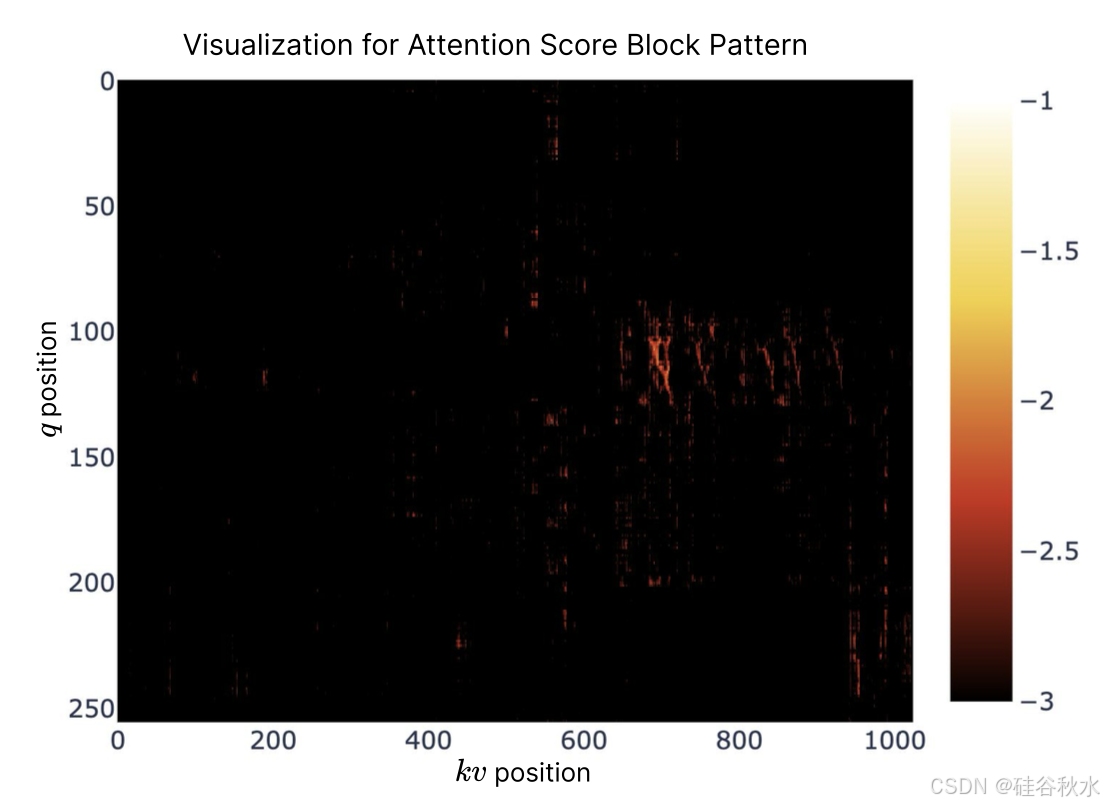
为了探索 Transformer 注意分布中的潜在模式并寻求设计灵感,如图所示可视化预训练的 27B 全注意模型中的注意图。可视化揭示有趣的模式,其中注意得分往往表现出块状聚类特征,而附近的 K 通常显示出相似的注意得分。这一观察启发设计 NSA,表明基于空间连续性选择 K 块可能是一种有前途的方法。块状聚类现象表明序列中相邻的 tokens 可能与 Q tokens 共享某些语义关系,尽管这些关系的确切性质需要进一步研究。这一观察促使探索一种对连续 token 块而不是单个 token 进行操作的稀疏注意机制,旨在提高计算效率并保留高注意模式。