25年2月来自 Arizona State U 的论文“A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models”。
深度强化学习 (RL) 已被探索并证实可有效解决机器人、交通、推荐系统等各个领域的决策任务。它从与环境的交互中学习,并使用收集的经验更新策略。然而,由于现实世界数据有限,采取有害行动的后果难以承受,RL 策略的学习主要局限于模拟器中。这种做法保证学习的安全性,但在部署方面不可避免地引入模拟-到-现实的差距,从而导致性能下降和执行风险。人们尝试使用各种技术来解决不同领域的模拟-到-现实问题,尤其是在大型基础或语言模型等新兴技术的时代,这些技术为模拟-到-现实带来启示。这篇综述论文从马尔可夫决策过程的关键要素(状态、动作、转换和奖励)构建模拟-到-现实技术的分类。基于该框架,涵盖从经典到最先进方法的全面文献,包括由基础模型赋能的模拟-到-现实技术,并讨论模拟-到-现实问题不同领域中值得关注的特点。总结使用可访问代码或基准的模拟-到-现实性能的正式评估过程,以及挑战和机遇。
强化学习 (RL) 算法因其良好的顺序决策能力而在多个领域展现出潜力。除了游戏场景外,这些解决方案也越来越接近现实世界的问题,例如机器人控制 [111]、推荐系统 [3, 38]、医疗保健 [76, 241] 和交通 [87, 229] 等。
尽管对基于 RL 的方法进行前沿探索,但在现实世界中部署 RL 学习的策略仍然具有挑战性 [39, 218],尤其是在自动驾驶 [110] 和疾病诊断或慢性治疗 [139] 等高风险场景中。由于模拟器(用于策略学习)和现实(用于策略部署)之间存在差距,即所谓的“模拟-到-现实”差距,这些现实世界的问题很难从 RL 方法中获益。
模拟-到-现实的差距是在策略训练过程中引入的,并在部署执行中被放大。因此,训练有素的强化学习策略会遭受严重的真实世界性能下降。在最坏的情况下,考虑到未见过场景下的不可预测决策,甚至存在潜在的安全隐患。一些研究人员将此归因于模拟环境和现实环境之间的转换差距,并提出从转换动力学 [217] 来解决这一差距的几个方面,例如域随机化和域自适应等。也有文献讨论在感知或执行期间引入的差距,并提出落地学习(grounded learning)的方法 [188]。不同的研究人员正在分别研究特定的领域 [46, 82, 91, 232],一些见解应该统一,而专业则应该在特定域讨论。此外,随着大型基础模型的爆炸式发展 [138, 231],各种有效的方法被提出将基础模型的推理能力整合到下游任务中 [137],其对强化学习方法的模拟-到-现实迁移具有巨大的潜力。
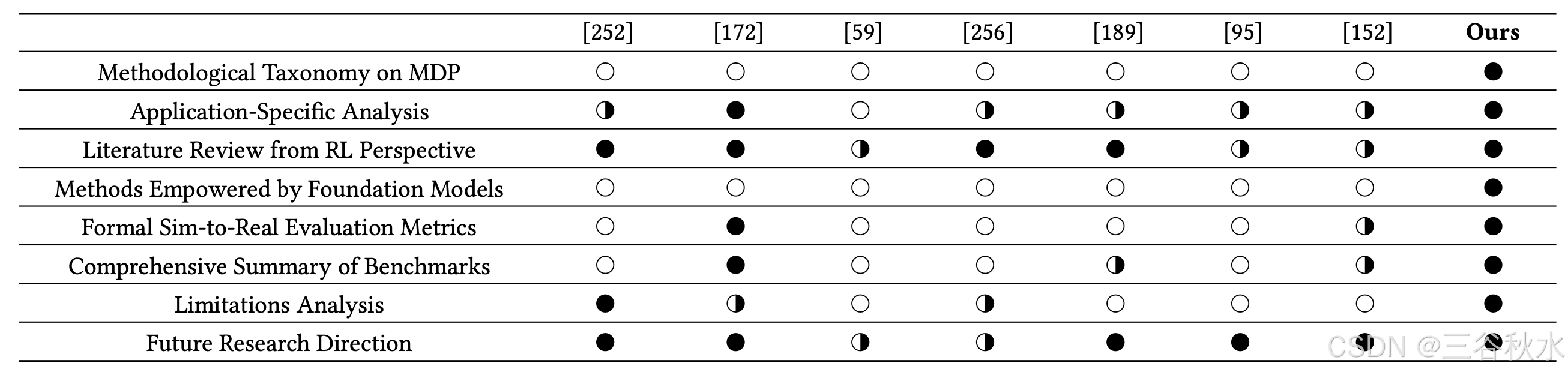
下表是本综述和其他的比较:
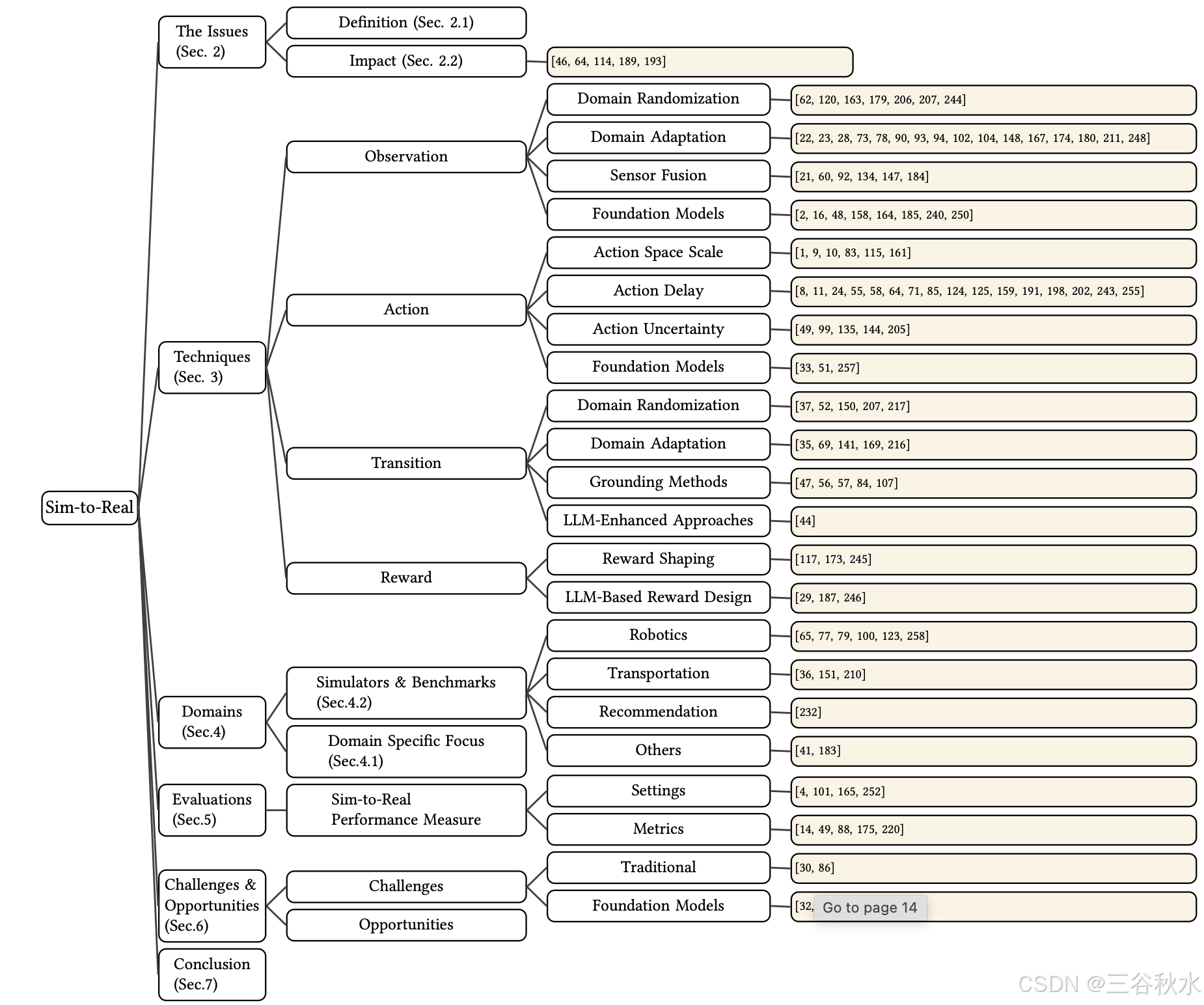
下图是本综述结构:
强化学习是一种特殊的机器学习范式,它使智体能够从环境中的交互中学习决策策略,学习由接收伴随动作而来的反馈(奖励)来指导。为了最大化累积奖励,使用各种学习算法迭代改进策略。
一般来说,上述 RL 学习过程通常在满足形式数学建模的马尔可夫决策过程 (MDP) M 上定义 [70],其中 M = (S, A, T, R, 𝛾)。
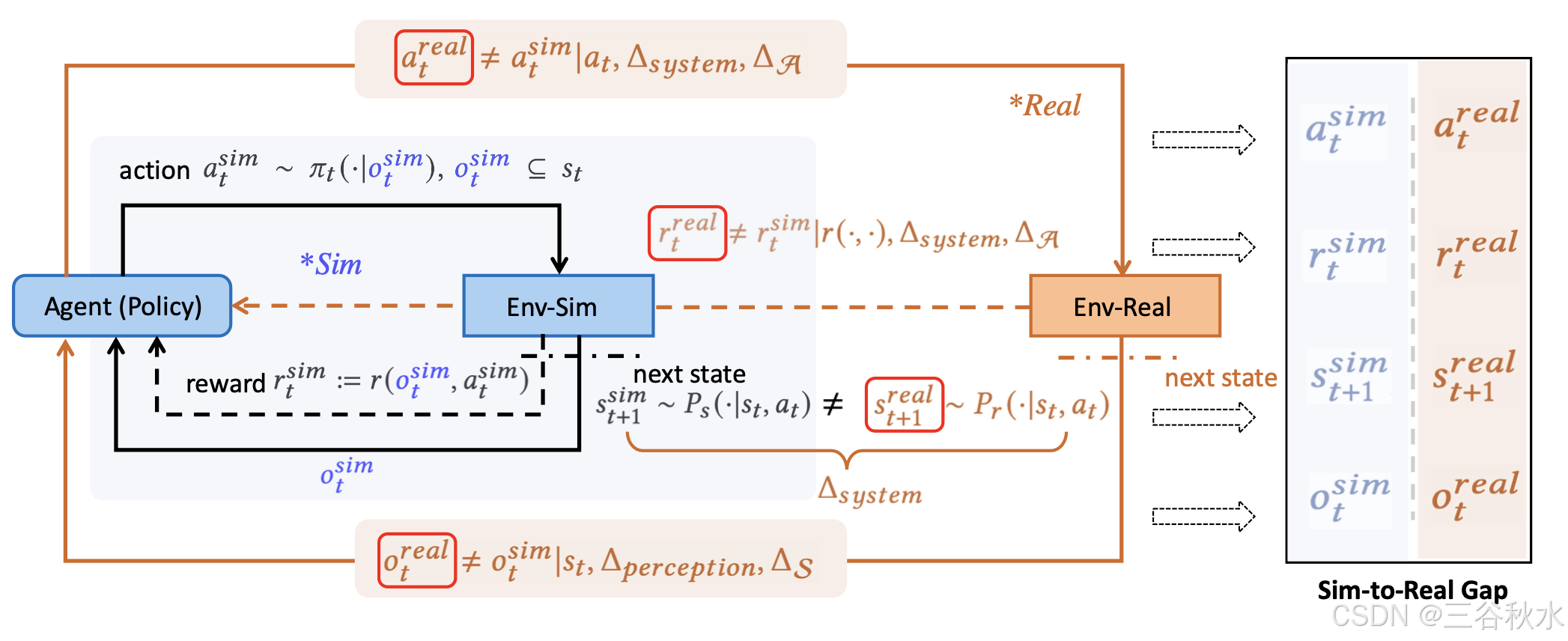
如图所示Sim-to-Real 问题概述。RL 中的四个关键 Sim-to-Real (Sim2Real) 差距,源于模拟环境 (Env-Sim) 和真实环境 (Env-Real) 之间的差异。动作差距 (𝑎^𝑟𝑒𝑎𝑙_t ≠ 𝑎^𝑠𝑖𝑚_t) 源于系统机械状态 Δ_𝑠𝑦𝑠𝑡𝑒𝑚 或动作空间粒度 Δ_A 的差异。奖励差距 (𝑟^𝑟𝑒𝑎𝑙_t ≠ 𝑟^𝑠𝑖𝑚_t) 是由于系统之间的奖励函数不匹配以及动作 Δ_A 的粒度不匹配而产生的。下一状态差距 (𝑠^𝑟𝑒𝑎𝑙_t+1 ≠ 𝑠^𝑠𝑖𝑚_t+1) 反映模拟环境 𝑃_𝑠 (· | 𝑠_𝑡,𝑎_𝑡) 的过渡动态与现实世界动态 𝑃_𝑟 (· | 𝑠_𝑡,𝑎_𝑡 ) 相比的不准确性。最后,观察差距 (𝑜^𝑟𝑒𝑎𝑙_t ≠ 𝑜^𝑠𝑖𝑚_t) 来自不完整的感知模块 Δ_𝑝𝑒𝑟𝑐𝑒𝑝𝑡𝑖𝑜𝑛 或表示不匹配 Δ_S。这些共同定义了 RL 中的 Sim-to-Real 挑战。
观测
弥补强化学习中的模拟到现实 (sim2real) 差距需要解决观测数据的差异,特别是由于摄像头和触觉传感器等传感器模式的变化而产生的差异。如图所示,已经开发出各种策略来缓解这些差异 [155]:
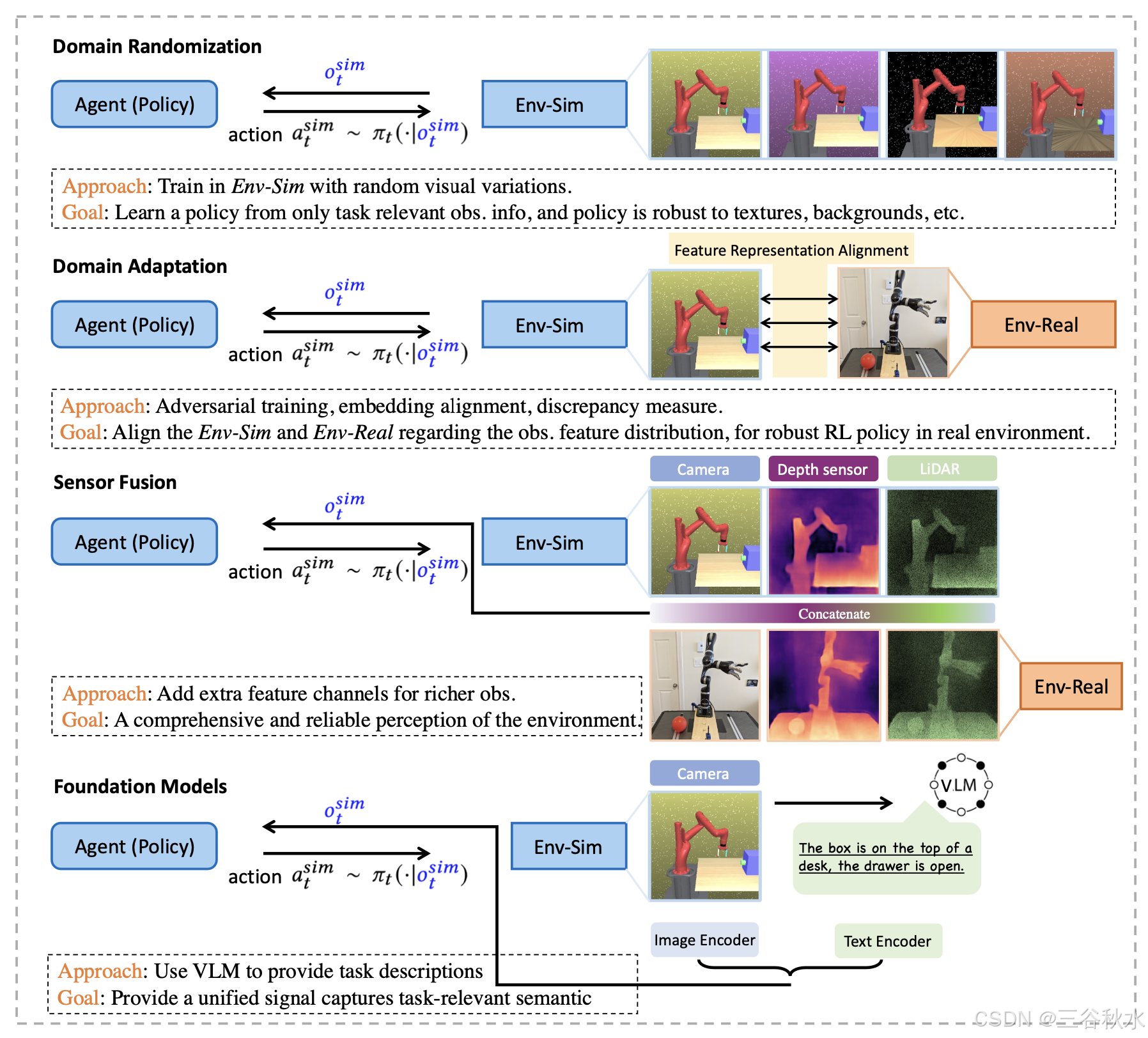
域随机化,通过在模拟环境中引入广泛的变化来增强策略鲁棒性,使智体能够有效地泛化到各种现实世界场景 [207]。
域自适应,通过调整特征分布来弥合模拟域和现实域之间的差距,确保在模拟中训练的策略在现实环境中表现一致 [216]。
传感器融合,集成来自多个传感器的数据,以提供全面可靠的环境感知 [21],从而弥补单个传感器的局限性,多个观察为感知提供更好的基础,从而缓解 Sim-to-Real 问题。
基础模型,通过利用 VLM 提供进一步的任务级描述,并将此类语义信息编码到智体的观察中,从而增加世界描述 [240]。
动作
采取动作是实施任何主动控制政策的关键步骤,并能使环境产生影响。缓解 Sim-to-Real 问题的三个主要动作方面如图所示:
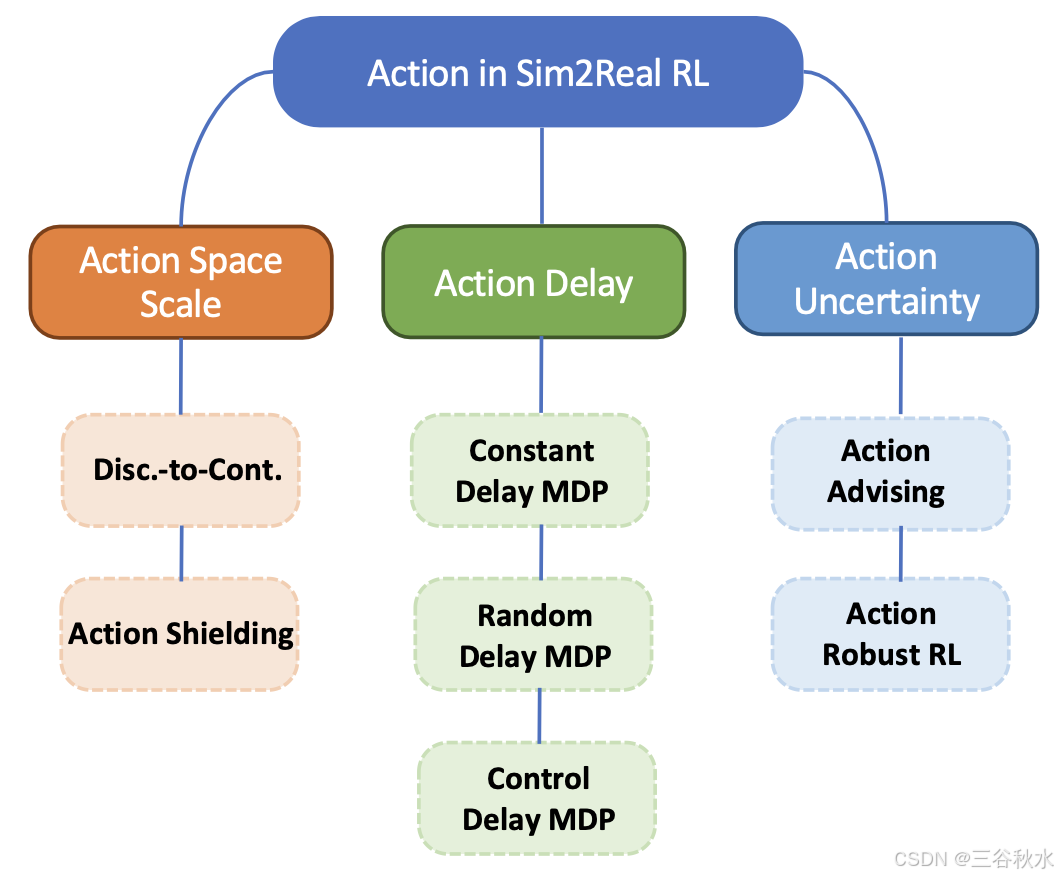
动作空间尺度。动作对环境的影响最为直接。然而,由于模拟器的限制,它们通常会被离散化或简化,以减少保真度的设计工作量。最常见的情况是离散(模拟)到连续(真实)的差距。
动作延迟。模拟器中动作采取的另一种理想化是动作通常会立即发生。然而,在现实世界中,它大多伴随着延迟 [58, 64, 255]。多个领域都在解决延迟动作问题,例如网络管理 [85, 124, 125, 198],它处理实时阻塞或调度的不切实际问题。在能源领域,[8, 202] 在不影响数据及时流动的情况下管理能源。在强化学习方法中考虑此类延迟变量是实际部署前的重要一步。
动作不确定性。采取动作不可避免地会涉及不确定性。即使是经过良好学习的策略也可能遇到未见过的情景,这使得现实世界的决策具有挑战性。结合不确定性量化,为模拟器训练的策略泛化到更广泛的现实世界场景带来了巨大好处。不确定性增强的动作有两个方面:动作建议和动作鲁棒 RL。
基础模型。由于基础模型是在海量语料库上训练的,并且表现出强大的零样本能力,因此它们被用于解决在未见过或罕见场景的行动中普遍性的挑战。
转换
在 Sim-to-Real 挑战中,模拟系统和真实系统之间的转换动态差异,会严重损害策略部署性能,正如探索中所展示的 [46],有四类通过弥合转换动态差距来解决 Sim-to-Real 问题的方法:
域随机化:
域自适应:
落地方法:通过落地动作调整模拟器动态,使其与现实世界动态保持一致。
LLM-增强方法:
总之,解决 Sim-to-Real 中的转换动态差异,需要结合传统方法(例如域随机化、域自适应和基础方法)以及新兴的 LLM 增强策略。这些方法共同增强 RL 策略的稳健性和适应性,从而促进在实际应用中更有效的部署。
奖励
在强化学习 (RL) 中,奖励函数的设计对于有效的策略学习至关重要,尤其是在从模拟环境迁移到真实环境 (Sim-to-Real) 时。为了应对 Sim-to-Real 场景中与奖励函数相关的挑战,人们探索两类主要技术:奖励塑造和基于 LLM 的奖励设计。
奖励塑造技术专注于修改奖励函数,以提供更具信息性和更密集的反馈,从而更有效地引导智体朝着期望的行为发展。这些方法在 Sim-to-Real 环境中特别有用,因为模拟环境和真实环境之间的差异可能会阻碍学习。
大语言模型 (LLM) 的出现为 RL 中的奖励函数设计自动化和优化开辟新途径,特别是对于需要细微奖励结构的复杂任务。这些技术利用 LLM 的生成和推理能力来解决 Sim-to-Real 场景中的奖励设计挑战。
总之,解决 Sim-to-Real 场景中的奖励函数设计挑战既需要奖励塑造等传统技术,也需要利用 LLM 的创新方法。这些方法增强模拟训练与现实世界部署之间的一致性,从而提高 RL 策略的稳健性和有效性。
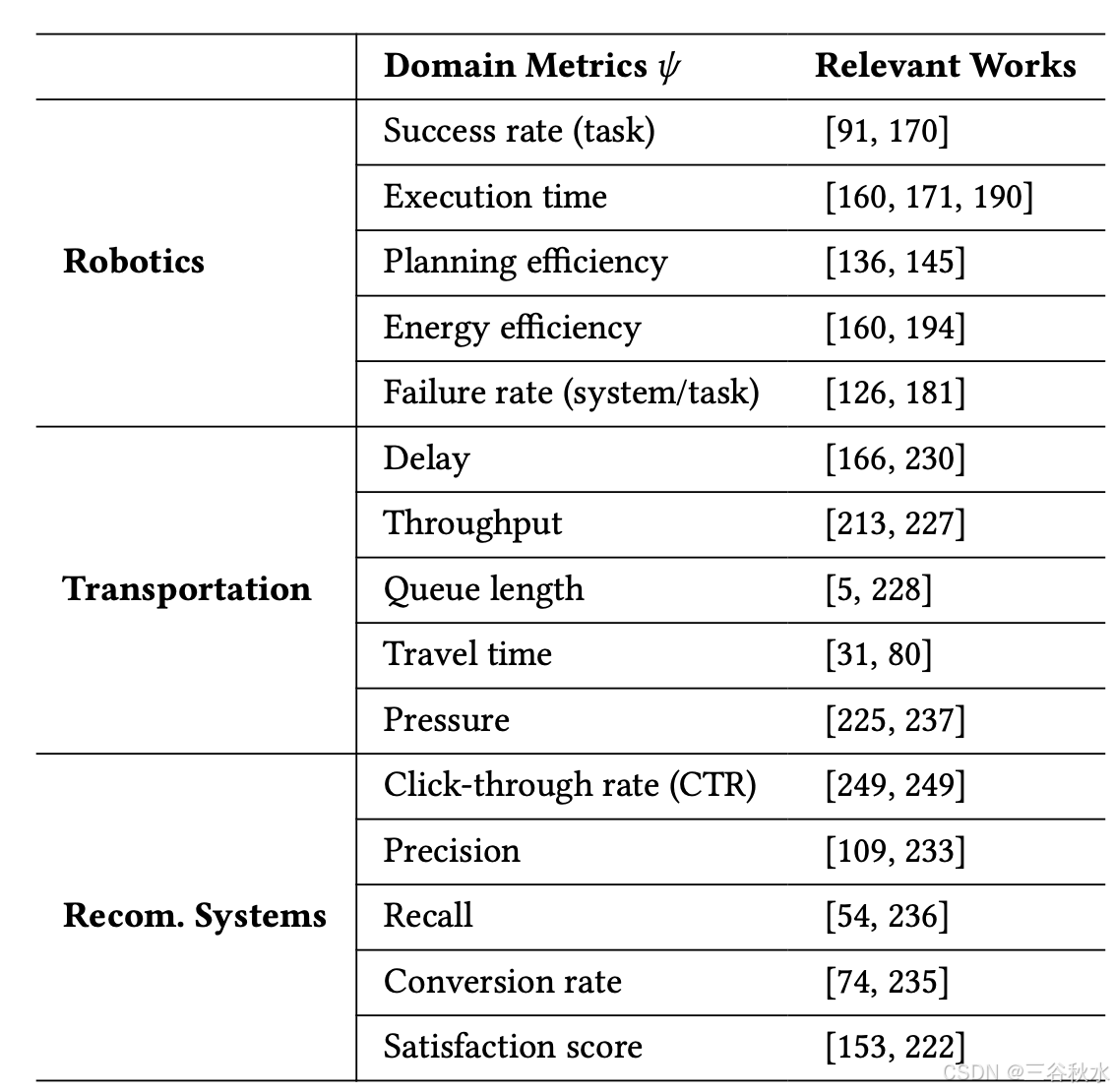
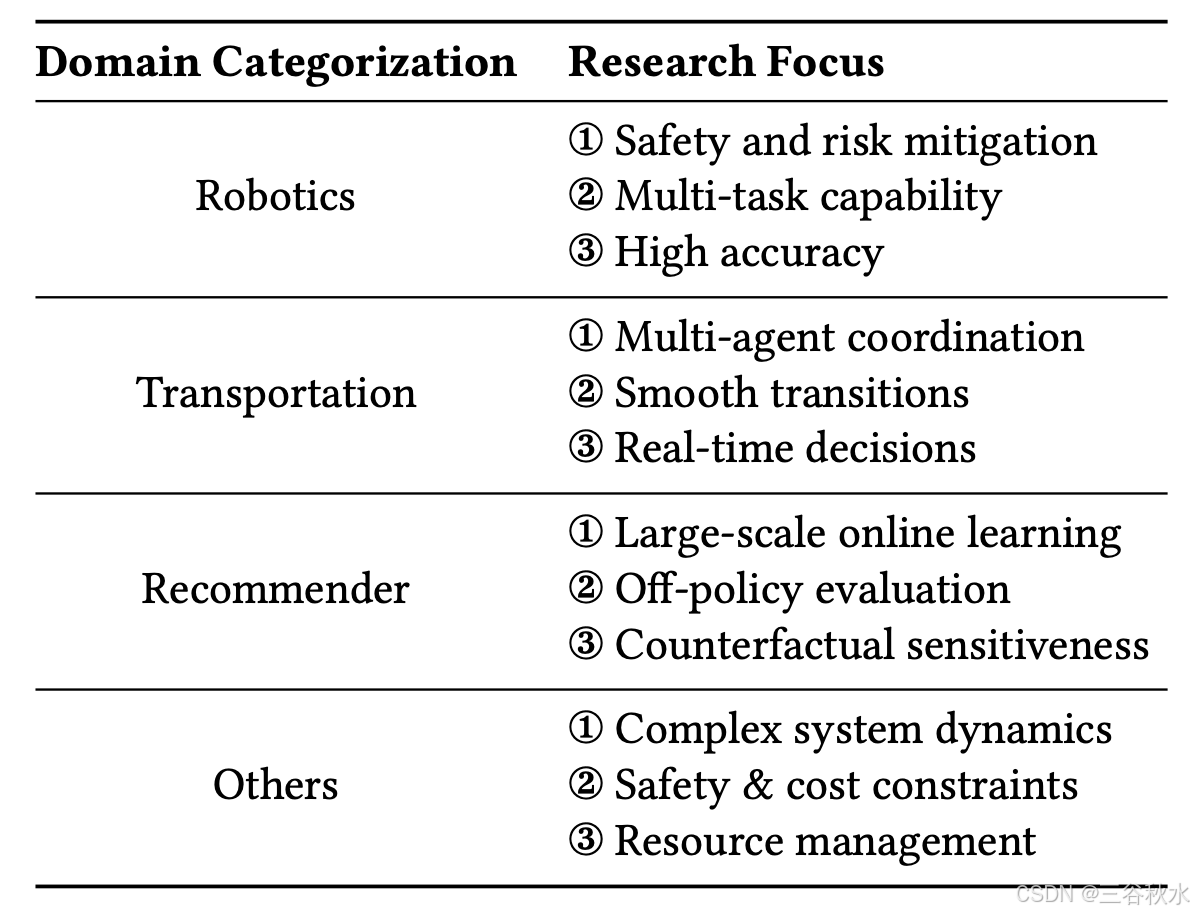
模拟-到-现实迁移是强化学习 (RL) 应用中普遍存在的挑战,每个研究领域都采用专门的模拟器和基准来应对其独特的现实世界复杂性。每个领域的不同研究重点如表所示:
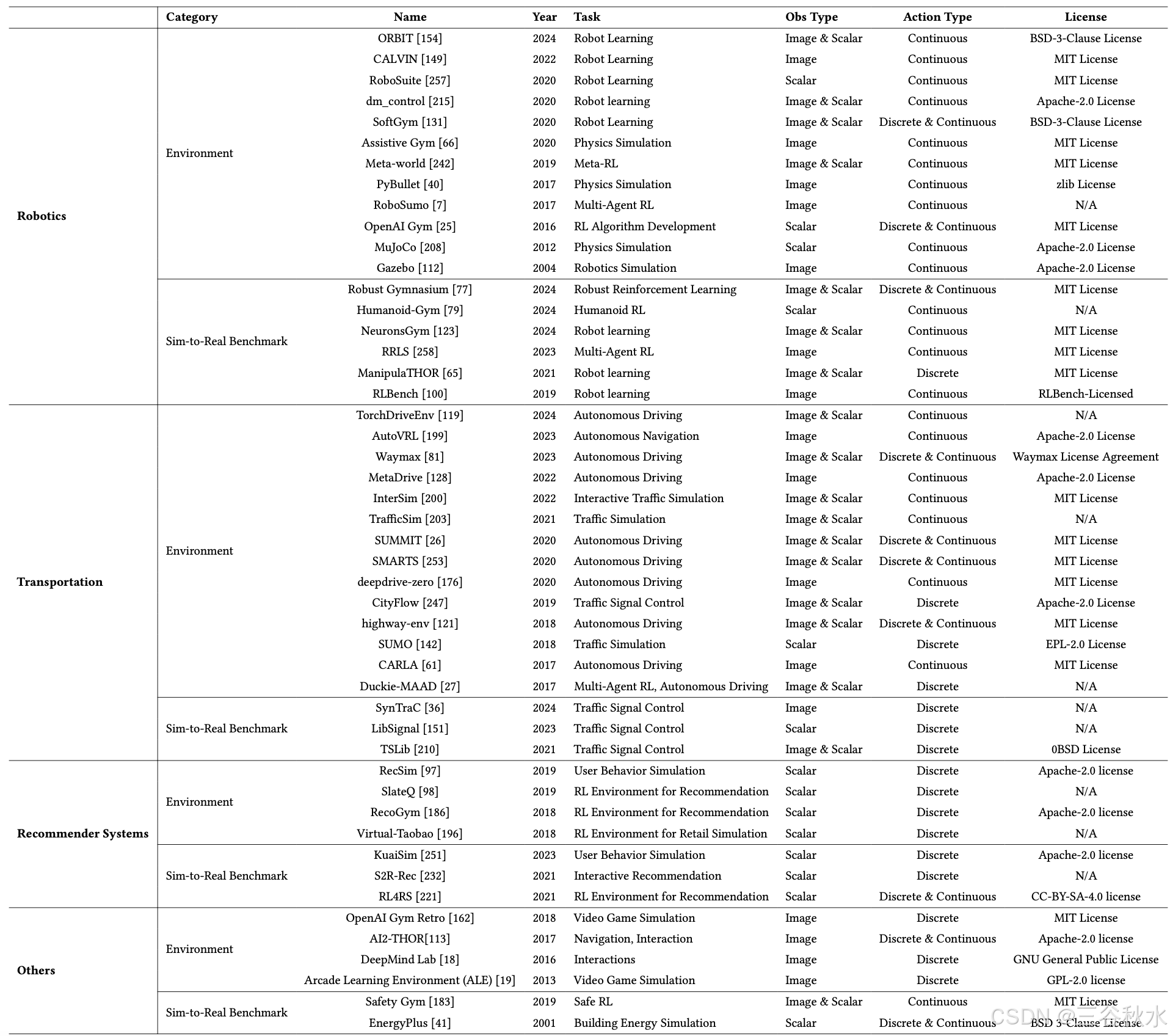
“模拟器”和 Sim-to-Real“基准”如表所示:
三种常见的Sim-to-Real方法评估方法,从成本、安全性、真实感三个维度的比较如图所示:
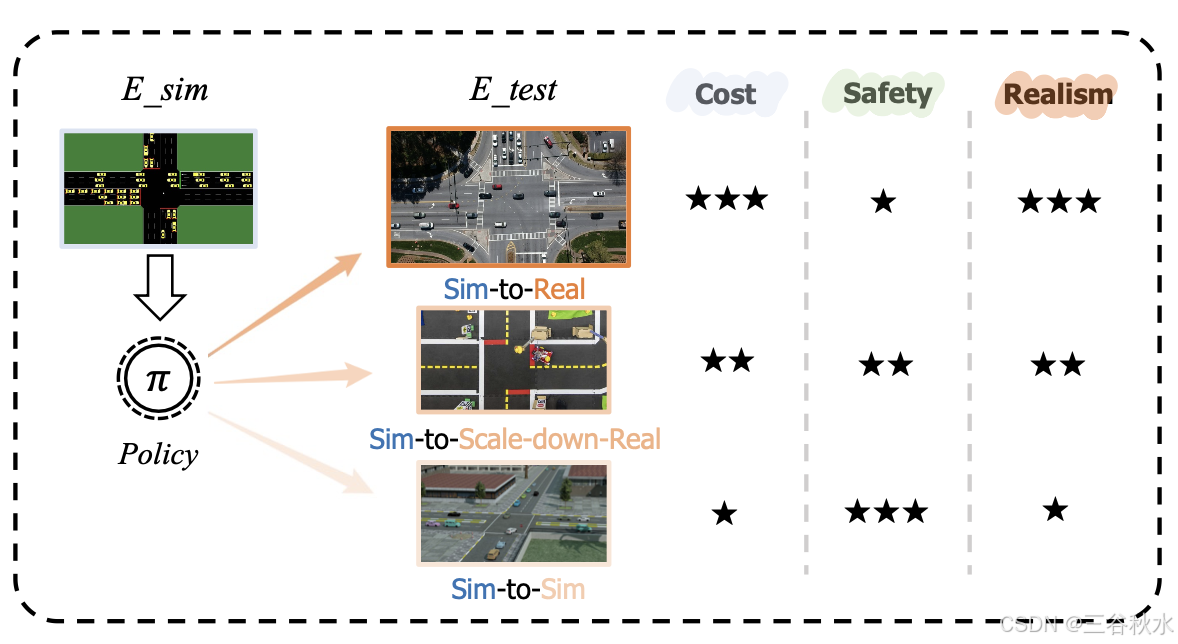
模拟-到-真实环境:模拟-到-真实评估,涉及将模拟中训练的策略直接部署到现实世界的物理系统上。这种设置对于需要现实世界交互的领域至关重要,例如机器人技术和自动驾驶汽车。它可以从真实环境中接收实时的实际反馈,但由于学习策略(尤其是神经网络)的意外行为,它不是大多数验证实验的理想策略。
模拟-到-缩小版真实环境:由于安全、成本和容错方面的考虑,大多数评估配置不会直接在现实世界中发生,而是设计专门的缩小版测试平台来促进这些评估,确保安全性和可靠性。例如,在机器人技术中,配备运动捕捉系统和安全措施的物理测试环境允许对机器人策略进行受控测试 [4]。同样,自动驾驶汽车测试可以利用复制真实驾驶条件的封闭轨道来评估模拟训练 [165]。
模拟-到-模拟设置:由于与真实世界测试相关的高成本和实际挑战,模拟-到-模拟评估通常被用作初步步骤。在这种情况下,在一个模拟环境中训练的策略将在不同的、通常更现实或多样化的模拟中进行测试。这种方法允许研究人员评估强化学习状态在不同条件下的鲁棒性和泛化能力,而无需承担真实世界部署的费用和风险。例如,在训练和测试模拟之间改变物理参数、传感器噪声或环境动态可以深入了解策略如何很好地迁移到现实 [101]。
选择适当的评估设置和指标对于准确评估强化学习中的模拟到现实转移至关重要。模拟-到-模拟评估,即在不同的模拟环境中评估智体,提供一种经济有效的方法来衡量潜在的真实世界表现。另一方面,模拟-到-现实的评估直接评估了智体在实际场景中的表现,从而提供对其适用性的明确见解。将这些评估设置与稳健的指标相结合,可以全面评估智体弥补模拟-到-现实差距的能力。虽然一些研究 [105, 106, 212] 试图用模拟中的表现来预测现实世界的表现,但预测性仍然在很大程度上依赖于特定的指标。
常见的评估测度如下表所示: