欢迎关注『youcans动手学模型』系列
本专栏内容和资源同步到 GitHub/youcans
【YOLO 项目实战】(10)YOLO8 环境配置与推理检测
【YOLO 项目实战】(11)YOLO8 数据集与模型训练
【YOLO 项目实战】(12)红外/可见光多模态目标检测
【YOLO 项目实战】(13)红外/可见光多模态后端融合
【YOLO 项目实战】(13)红外/可见光多模态后端融合
本文讨论可见光图像和红外图像的后端融合方法,用不同模态数据分别训练得到各自的分类器,再对各个分类器的输出进行融合。由于融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加,因此可能获得更好的结果。
1. 基于可见光/红外的多模态图像融合
同时使用可见光图像和红外图像进行训练,需要修改 YOLO 模型的网络结构,进行图像融合。目前,多模态数据融合主要有三种方式:前端融合(early-fusion)或数据端融合(data-level fusion)、后端融合(late-fusion)或决策端融合(decision-level fusion)和中间融合(intermediate-fusion)。
-
前端融合,是指将多个独立的数据集融合成一个单一的特征向量,然后输入到机器学习模型进行分类。
前端融合在本质上没有改变模型结构,方法简单易行。但往往无法充分利用多个模态数据间的互补性,且原始数据通常包含大量的冗余信息。因此,多模态前端融合方法常常与特征提取方法相结合以剔除冗余信息,如主成分分析(PCA)、最大相关最小冗余算法(mRMR)、自动解码器(Autoencoders)等。 -
后端融合,则是用不同模态数据分别训练得到各自的分类器,再对各个分类器的输出进行融合。
由于融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加,因此可能获得更好的结果。常见的后端融合方式包括最大值融合(max-fusion)、平均值融合(averaged-fusion)、 贝叶斯规则融合(Bayes’rule based)和集成学习(ensemble learning)等。 -
中间融合,是指将不同的模态数据先转化为高维特征表达,再于模型的中间层进行融合。
中间融合首先利用神经网络将原始数据转化成高维 特征表达,然后获取不同模态数据在高维空间上的共性。其优势是可以灵活的选择融合位置。
本文讨论后端融合,用不同模态数据分别训练得到各自的分类器,再对各个分类器的输出进行融合。由于融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加,因此可能获得更好的结果。
2. 红外/可见光目标检测数据集
红外/可见光目标检测数据集包含两个模态的数据:可见光(RGB)图像和红外(IR)图像。
空间与时间上的对齐是多光谱图像数据集构建中的重要问题,时间上对齐指需尽量在同一时刻获取红外及可见光图像,空间上的对齐指获取得到的图像需尽量在每个像素上对应同一物体。注意有的数据集已经对红外/可见光图像进行了配准,可以直接进行融合。有些数据集则没有进行对齐。
LLVIP 数据集 (Low-Light Vision Infrared-Paired)
LLVIP 是一个用于低光视觉的可见红外配对数据集。LLVIP 数据集提供的可见光图像和红外图像,已经在空间和时间上对齐,不需要再做配准处理。
该数据集包括 24个黑暗场景、2个白天场景,共 30976张图像(15488对),其中12025对用于训练,3463对用于测试。
数据集对"行人"类别进行了标记,包含 41579 个’person’标签,其中train标签33648个,test标签7931个。同一对可见光和红外图像共享相同的标签,具有相同的名称。其中110423.xml为空白标签。
参考论文:LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
下载地址:LLVIP-Github,LLVIP-百度飞桨,paperscode
本文从 LLVIP 可见红外配对数据集中选择了 800对图像,用于模型训练。
将 LLVIP800 数据集保存在项目的指定路径 datasets 下,并严格按下面的格式组织样本图片和标签。
- yolov8
- datasets
- LLVIP800
- image
- test
- train
- val
- images
- test
- train
- val
- labels
- test
- train
- val
- dataLLVIP800.yaml
- ultralytics
- yolov8n.pt
其中,images 保存的是可见光图片,image 保存的是红外图片,labels 是标注的标签(可见光/红外公用)。
注意 images/train 和 image/train 目录下的可见光图片和红外图片的文件名必须完全相同,否则在图像融合时会出错。同样地,test 和 val 目录下的可见光图片和红外图片的文件名也必须完全相同。
每个标签文件(.txt)包含一行或多行数据,每一行代表一个物体的标签,格式如下:
<class_index> <x_center> <y_center> <width> <height>
其中:
<class_index> 是物体类别的索引;
<x_center> 是物体中心点相对于图像宽度的比例位置;
<y_center> 是物体中心点相对于图像高度的比例位置;
是物体宽度相对于图像宽度的比例;
是物体高度相对于图像高度的比例。
3. 基于可见光/红外的多模态模型训练
3.1 红外可见光后端融合模块
为了实现红外可见光后端融合,需要在 block.py 中添加一个输入映射模块 IN 和一个注意力模块Multiin。
文件目录 “.\ultralytics\nn\modules” 下的文件定义模型中的组成构建,
.\ultralytics\nn\modules
__init__.py: 表明此目录是Python包。
block.py: 包含定义神经网络中的基础块,如残差块或瓶颈块。
conv.py: 包含卷积层相关的实现。
head.py: 定义网络的头部,用于预测。
transformer.py: 包含Transformer模型相关的实现。
utils.py: 提供构建神经网络时可能用到的辅助函数。
YOLO 基础模块
其中,block.py 包含定义神经网络中的基础块,如残差块或瓶颈块。
# Ultralytics YOLO 🚀, AGPL-3.0 license
"""Block modules."""
import torch
import torch.nn as nn
import torch.nn.functional as F
from .conv import Conv, DWConv, GhostConv, LightConv, RepConv
from .transformer import TransformerBlock
__all__ = ('DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3', 'C2f', 'C3x', 'C3TR', 'C3Ghost',
'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'RepC3', 'ResNetLayer')
class DFL(nn.Module):
...
输入映射模块 IN
为了实现 红外/可见光 图像的融合,在 block.py 中添加一个输入映射模块 IN。
# Ultralytics YOLO 🚀, AGPL-3.0 license
"""Block modules."""
class IN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
输入分组模块 Multiin
为了实现红外可见光后端融合,在 block.py 中添加一个输入分组模块 Multiin。
# Ultralytics YOLO 🚀, AGPL-3.0 license
"""Block modules."""
class Multiin(nn.Module): # stereo attention block
def __init__(self, out=1):
super().__init__()
self.out = out
def forward(self, x):
x1, x2 = x[:, :3, :, :], x[:, 3:, :, :]
if self.out == 1:
x = x1
else:
x = x2
return x
3.2 红外可见光后端融合模块
task.py 文件位于 “.\ultralytics\nn” 目录,用于对网络结构 model.yaml 文件进行解码。
红外可见光后端融合模型修改了 YOLOv8 的网络结构,对于 tasks.py 也要进行适应性修改。主要是在 “def parse_model(d, ch, verbose=True)” 函数添加:
elif m is Multiin:
c2 = ch[f]//2
修改后的完整程序如下:
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
"""Parse a YOLO model.yaml dictionary into a PyTorch model."""
import ast
# Args
max_channels = float('inf')
nc, act, scales = (d.get(x) for x in ('nc', 'activation', 'scales'))
depth, width, kpt_shape = (d.get(x, 1.0) for x in ('depth_multiple', 'width_multiple', 'kpt_shape'))
if scales:
scale = d.get('scale')
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
depth, width, max_channels = scales[scale]
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:
LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
ch = [ch]
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3, MF):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 1
elif m is Multiin:
c2 = ch[f]//2
elif m is AIFI:
args = [ch[f], *args]
elif m in (HGStem, HGBlock):
c1, cm, c2 = ch[f], args[0], args[1]
args = [c1, cm, c2, *args[2:]]
if m is HGBlock:
args.insert(4, n) # number of repeats
n = 1
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in (Detect, Segment, Pose, OBB):
args.append([ch[x] for x in f])
if m is Segment:
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f])
else:
c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
3.3 多模态 YOLO 模型的数据集配置文件(dataset.yaml)
YOLO 模型训练时,要调用数据集配置文件( .yaml),指定数据集的路径和分类类别。
根据 LLVIP800 Dataset 数据集配置文件 dataLLVIP800.yaml ,编写本项目的数据集配置文件,保存在默认路径 “./ultralytics/cfg/datasets/dataLLVIP800.yaml”。
程序在运行时,会分别读取 images/train 和 image/train 目录下的图像文件。因此,数据集必须严格按照 1.2 节的数据集结构进行组织,而且 images/train 和 image/train 目录下的可见光图片和红外图片的文件名必须完全相同,否则在图像融合时会出错。同样地,test 和 val 目录下的可见光图片和红外图片的文件名也必须完全相同。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# LLVIP800 dataset
# parent
# ├── ultralytics
# └── datasets
# └── LLVIP800
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: LLVIP800 # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
names:
0: person
3.4 多模态 YOLO 模型的配置文件(model.yaml)
YOLO 模型训练时,要调用模型配置文件( .yaml),指定 YOLO 模型的结构。YOLOv8 默认的模型配置文件是 “ultralytics/cfg/models/v8/yolov8.yaml”。
使用可见光和红外图像进行模型训练时,需要修改 YOLO 模型配置文件,将输入图像的通道数设为 6,表示使用红外/可见光融合图像作为输入图像。另外,使用了 IN 模块和 Multiin 模块,这两个模块内容详见后文。
后端融合的多模态 YOLO 模型的配置文件保存在 “ultralytics/cfg/models/v8/yolov8-BackendFusion.yaml”,具体内容如下。
# Parameters
ch: 6
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, IN, []] # 0
- [-1, 1, Multiin, [1]] # 1
- [-2, 1, Multiin, [2]] # 2
- [-2, 1, Conv, [32, 3, 2]] # 3-P1/2
- [-2, 1, Conv, [32, 3, 2]]
- [-2, 1, Conv, [64, 3, 2]] # 5-P2/4
- [-2, 1, Conv, [64, 3, 2]]
- [-2, 3, C2f, [64, True]] # 7
- [-2, 3, C2f, [64, True]]
- [-2, 1, Conv, [128, 3, 2]] # 9-P3/8
- [-2, 1, Conv, [128, 3, 2]]
- [-2, 6, C2f, [128, True]] # 11
- [-2, 6, C2f, [128, True]]
- [ -2, 1, Conv, [ 256, 3, 2 ] ] # 13-P4/16
- [ -2, 1, Conv, [ 256, 3, 2 ] ]
- [ -2, 6, C2f, [ 256, True ] ] # 15
- [ -2, 6, C2f, [ 256, True ] ]
- [ -2, 1, Conv, [ 512, 3, 2 ] ] # 17-P5/32
- [ -2, 1, Conv, [ 512, 3, 2 ] ]
- [ -2, 3, C2f, [ 512, True ] ] # 19
- [ -2, 3, C2f, [ 512, True ] ]
- [-2, 1, SPPF, [512, 5]] # 21
- [-2, 1, SPPF, [512, 5]] # 22
# YOLOv8.0n head
head:
- [-2, 1, nn.Upsample, [None, 2, 'nearest']]
- [-2, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-2, 15], 1, Concat, [1]] # cat backbone P4
- [[-2, 16], 1, Concat, [1]] # cat backbone P4
- [-2, 3, C2f, [512]] # 27
- [-2, 3, C2f, [512]] # 28
- [-2, 1, nn.Upsample, [None, 2, 'nearest']]
- [-2, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-2, 9], 1, Concat, [1]] # cat backbone P3
- [[-2, 10], 1, Concat, [1]] # cat backbone P3
- [-2, 3, C2f, [256]] # 33 (P3/8-small)
- [-2, 3, C2f, [256]] # 34 (P3/8-small)
- [-2, 1, Conv, [256, 3, 2]]
- [-2, 1, Conv, [256, 3, 2]]
- [[-2, 27], 1, Concat, [1]] # cat head P4
- [[-2, 28], 1, Concat, [1]] # cat head P4
- [-2, 3, C2f, [512]] # 39 (P4/16-medium)
- [-2, 3, C2f, [512]] # 40 (P4/16-medium)
- [-2, 1, Conv, [512, 3, 2]]
- [-2, 1, Conv, [512, 3, 2]]
- [[-2, 21], 1, Concat, [1]] # cat backbone P5
- [[-2, 22], 1, Concat, [1]] # cat backbone P5
- [-2, 3, C2f, [1024]] # 45 (P5/32-large)
- [-2, 3, C2f, [1024]] # 46 (P5/32-large)
- [[33, 34, 39, 40, 45, 46], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.5 多模态 YOLO 模型的训练配置文件(default.yaml)
YOLO 模型训练时,要调用训练配置文件(default.yaml),指定默认训练设置和超参数。YOLOv8 默认的训练配置文件是 “ultralytics/cfg/default.yaml”。
使用可见光和红外图像进行模型训练时,需要修改 YOLO 模型训练配置文件,将输入图像的通道数设为 6,表示使用红外/可见光融合图像作为输入图像。配置文件的其它部分内容也不变。
修改后端融合的多模态 YOLO 模型训练配置文件 “ultralytics/cfg/default.yaml”,具体内容如下。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: detect # (str) YOLO task, i.e. detect, segment, classify, pose
mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark
ch: 6 # (int) input channels
# Train settings -------------------------------------------------------------------------------------------------------
model: # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
...
4. 红外/可见光后端融合模型的训练
YOLOv8 提供了 Python 接口的调用方式。它提供了加载和运行模型以及处理模型输出的函数。该界面设计易于使用,以便用户可以在他们的项目中快速实现目标检测。
使用 LLVIP800 数据集进行红外/可见光后端融合模型训练的 Python 参考例程如下。
注意:
(1)使用红外/可见光后端融合模型配置文件 “ultralytics/cfg/models/v8/yolov8-BackendFusion.yaml”。其中通道数 ch=6,即 RGB 通道+红外通道。
(2)训练数据集的配置文件路径为 “./ultralytics/cfg/datasets/dataLLVIP800.yaml”。
(3)训练好的模型及训练日志保存在 “./runs/detect/train” 目录下。
from ultralytics import YOLO
if __name__ == '__main__':
# 训练
# model = YOLO(r"ultralytics/cfg/models/v8/yolov8-FrontendFusion.yaml")
model = YOLO(r"ultralytics/cfg/models/v8/yolov8-BackendFusion.yaml")
# 用指定数据集训练模型
model.train(data=r"ultralytics/cfg/datasets/dataLLVIP800.yaml", # 指定训练数据集的配置文件路径
cache=False, # 是否缓存数据集以加快后续训练速度
imgsz=640, # 指定训练时使用的图像尺寸
epochs=100, # 设置训练的总轮数为 100轮
batch=16, # 设置每个训练批次的大小为16
close_mosaic=10, # 设置在训练的最后 10 轮中关闭 Mosaic 数据增强
workers=4, # 设置用于数据加载的线程数为4
device='0', # 指定使用的 GPU 设备
optimizer='SGD' # 设置优化器为SGD(随机梯度下降)
)
# 验证
# model = YOLO(r"yolov8n_BFbest.pt")
# model.val(data=r"ultralytics/cfg/datasets/mydata.yaml",batch=1)
# # 检测
# model = YOLO(r"yolov8n_BFbest.pt")
# model.predict(source=r"datasets/LLVIP800/images/val", save=True) # RGB 图片路径
在 PyCharm 编译并运行程序,就实现对 LLVIP800 数据集进行模型训练,并将训练结果保存到 “./runs/detect/train/”。
C:\Users\Administrator\.conda\envs\yolo8\python.exe C:\Python\PythonProjects\YOLOv8_MMF2\YOLOv8BackendFusion01.py
WARNING ⚠️ no model scale passed. Assuming scale='n'.
from n params module arguments
0 -1 1 0 ultralytics.nn.modules.block.IN []
1 -1 1 0 ultralytics.nn.modules.block.Multiin [1]
2 -2 1 0 ultralytics.nn.modules.block.Multiin [2]
3 -2 1 232 ultralytics.nn.modules.conv.Conv [3, 8, 3, 2]
4 -2 1 232 ultralytics.nn.modules.conv.Conv [3, 8, 3, 2]
5 -2 1 1184 ultralytics.nn.modules.conv.Conv [8, 16, 3, 2]
6 -2 1 1184 ultralytics.nn.modules.conv.Conv [8, 16, 3, 2]
7 -2 1 1888 ultralytics.nn.modules.block.C2f [16, 16, 1, True]
8 -2 1 1888 ultralytics.nn.modules.block.C2f [16, 16, 1, True]
9 -2 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
10 -2 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
11 -2 2 12544 ultralytics.nn.modules.block.C2f [32, 32, 2, True]
12 -2 2 12544 ultralytics.nn.modules.block.C2f [32, 32, 2, True]
13 -2 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
14 -2 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
15 -2 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
16 -2 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
17 -2 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
18 -2 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
19 -2 1 115456 ultralytics.nn.modules.block.C2f [128, 128, 1, True]
20 -2 1 115456 ultralytics.nn.modules.block.C2f [128, 128, 1, True]
21 -2 1 41344 ultralytics.nn.modules.block.SPPF [128, 128, 5]
22 -2 1 41344 ultralytics.nn.modules.block.SPPF [128, 128, 5]
23 -2 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
24 -2 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
25 [-2, 15] 1 0 ultralytics.nn.modules.conv.Concat [1]
26 [-2, 16] 1 0 ultralytics.nn.modules.conv.Concat [1]
27 -2 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
28 -2 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
29 -2 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
30 -2 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
31 [-2, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
32 [-2, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
33 -2 1 35200 ultralytics.nn.modules.block.C2f [160, 64, 1]
34 -2 1 35200 ultralytics.nn.modules.block.C2f [160, 64, 1]
35 -2 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
36 -2 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
37 [-2, 27] 1 0 ultralytics.nn.modules.conv.Concat [1]
38 [-2, 28] 1 0 ultralytics.nn.modules.conv.Concat [1]
39 -2 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
40 -2 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
41 -2 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
42 -2 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
43 [-2, 21] 1 0 ultralytics.nn.modules.conv.Concat [1]
44 [-2, 22] 1 0 ultralytics.nn.modules.conv.Concat [1]
45 -2 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1]
46 -2 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1]
47[33, 34, 39, 40, 45, 46] 1 1502998 ultralytics.nn.modules.head.Detect [1, [64, 64, 128, 128, 256, 256]]
YOLOv8-BackendFusion summary: 445 layers, 3997030 parameters, 3997014 gradients
train: Scanning C:\Python\PythonProjects\YOLOv8\datasets\LLVIP800\labels\train.cache... 751 images, 0 backgrounds, 0 corrupt: 100%|██████████| 751/751 [00:00<?, ?it/s]
val: Scanning C:\Python\PythonProjects\YOLOv8\datasets\LLVIP800\labels\val.cache... 432 images, 0 backgrounds, 0 corrupt: 100%|██████████| 432/432 [00:00<?, ?it/s]
Plotting labels to runs\detect\train5\labels.jpg...
optimizer: SGD(lr=0.01, momentum=0.937) with parameter groups 114 weight(decay=0.0), 127 weight(decay=0.0005), 126 bias(decay=0.0)
100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 3.38G 4.191 4.441 4.229 97 640: 100%|██████████| 47/47 [00:11<00:00, 4.24it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 14/14 [00:03<00:00, 4.34it/s]
all 432 944 9.26e-05 0.0127 4.92e-05 9.28e-06
0%| | 0/47 [00:00<?, ?it/s]
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 3.42G 1.266 0.6907 1.523 36 640: 100%|██████████| 47/47 [00:08<00:00, 5.30it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 14/14 [00:02<00:00, 5.51it/s]
all 432 944 0.855 0.714 0.808 0.459
100 epochs completed in 0.357 hours.
Optimizer stripped from runs\detect\train2\weights\last.pt, 8.4MB
Optimizer stripped from runs\detect\train2\weights\best.pt, 8.4MB
Validating runs\detect\train2\weights\best.pt...
Ultralytics YOLOv7.0.112 🚀 Python-3.8.20 torch-2.4.1+cu121 CUDA:0 (NVIDIA GeForce RTX 3060, 12288MiB)
YOLOv8-BackendFusion summary (fused): 331 layers, 3989142 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 14/14 [00:03<00:00, 4.27it/s]
all 432 944 0.864 0.761 0.853 0.502
Speed: 0.5ms preprocess, 2.6ms inference, 0.0ms loss, 0.8ms postprocess per image
Results saved to runs\detect\train2
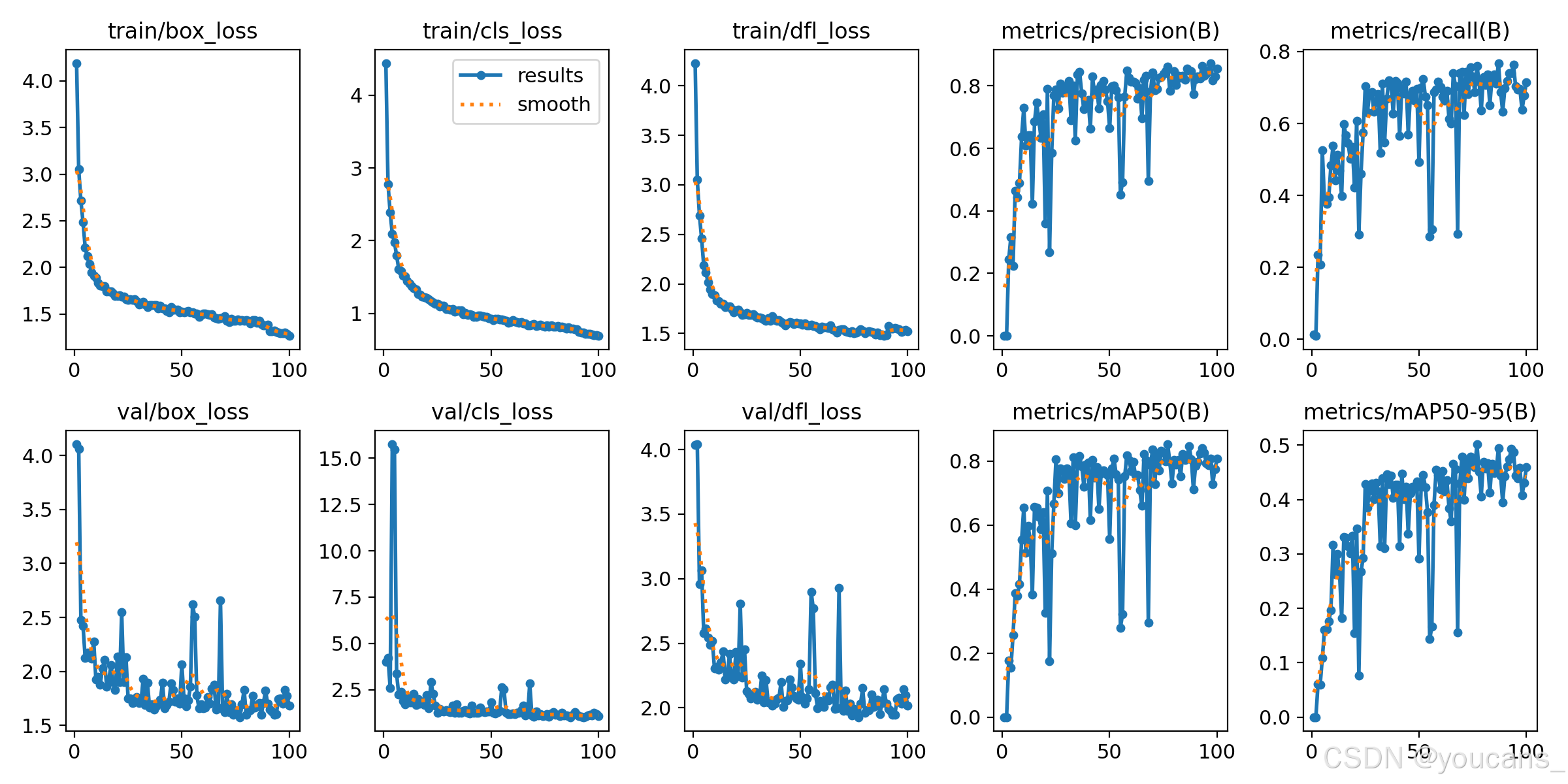
经过 100 轮遍历训练,训练过程及结果文件保存在目录 “runs\detect\train2”,如下图所示:

5. 模型推理
detect.py 程序使用PyTorch加载预训练的YOLOv8 模型。程序解析从命令行传入的参数,这些参数包括输入文件的路径(可以是图像、视频或目录)、预训练模型的路径、输出文件的路径、置信度阈值等。
将训练的模型 “runs\detect\train2\best.pt” 保存到项目的根目录,另存为 “yolov8n_BFbest.pt”。读取指定路径的图片,结果默认保存到 runs/detect 文件夹中。
使用预训练模型 “yolov8n_BFbest.pt” 进行推理的 Python 程序如下。
from ultralytics import YOLO
if __name__ == '__main__':
# 训练
# model = YOLO(r"ultralytics/cfg/models/v8/yolov8-FrontendFusion.yaml")
model = YOLO(r"ultralytics/cfg/models/v8/yolov8-BackendFusion.yaml")
# 检测
model = YOLO(r"yolov8n_BFbest.pt")
model.predict(source=r"datasets/LLVIP800/images/val", save=True) # RGB 图片路径
运行程序,就实现对指定图像文件的检测,并将检测结果保存到文件夹 “./runs/detect/predict”。
C:\Users\Administrator\.conda\envs\yolo8\python.exe C:\Python\PythonProjects\YOLOv8_MMF2\YOLOv8BFtest01.py
image 1/432 C:\Python\PythonProjects\YOLOv8_MMF2\datasets\LLVIP800\images\val\190008.jpg: 512x640 6 persons, 56.0ms
...
image 432/432 C:\Python\PythonProjects\YOLOv8_MMF2\datasets\LLVIP800\images\val\260529.jpg: 512x640 3 persons, 21.0ms
Speed: 8.6ms preprocess, 21.0ms inference, 1.4ms postprocess per image at shape (1, 6, 512, 640)
Results saved to runs\detect\predict2

【本节完】
版权声明:
欢迎关注『youcans动手学模型』系列
转发请注明原文链接:
【YOLO 项目实战】(13)红外/可见光多模态后端融合
Copyright 2025 youcans
Crated:2025-01-23