推理
XXX: 本章正在建设中 - 一些部分已经完成,一些刚刚开始,还有许多尚未开始,但已经有足够多的有用部分完成,使其值得阅读。
术语表
-
CLA: 跨层注意力(Cross-Layer Attention)
-
FHE: 全同态加密(Fully Homomorphic Encryption)
-
GQA: 分组查询注意力(Grouped-Query Attention)
-
ITL: 词间延迟(Inter-Token Latency)
-
KV: 键值(Key Value)
-
LPU: 语言处理单元™(Language Processing Unit™)
-
MHA: 多头注意力(Multi-Head Attention)
-
MPC: 安全多方计算(Secure Multi-Party Computation
-
MQA: 多查询注意力(Multi-Query Attention)
-
PPML: 隐私保护机器学习(Privacy-Preserving Machine Learning)
-
QPS: 每秒查询数(Queries Per Second)
-
TPOT: 每个输出token的时间(Time Per Output Token)
-
TTFT: 第一个token的时间(Time to First Token)
参见下面的概念部分获取更多类似术语的条目。
概念
预填充和解码
在进行推理时,有两个阶段:
预填充
预填充:由于提示的所有token都是已知的 - 一次处理完整的提示长度(类似于训练)并缓存中间状态(KV缓存)。由于即使是1k的提示也可以在足够的内存下非常快地处理,因此这一阶段几乎不会增加延迟。
解码
解码:新token的生成是基于所有先前的token(提示和迄今为止生成的任何新token)一次生成一个新token(回归方法)。因此,与预填充不同,这一阶段对生成的延迟贡献最大,因为解码无法并行化。
在线推理与离线推理
当用户实时发送查询时 - 这是在线推理,也称为部署。示例:聊天机器人、搜索引擎、通用REST API。在这种情况下,通常会运行一个推理服务器,并且可能有各种客户端连接到它。
当你有一个包含提示的文件需要进行推理时 - 这是离线推理。示例:基准评估、合成数据生成。在这种情况下,通常不需要推理服务器,推理直接在发送查询的同一程序中运行(客户端和服务器在一个应用程序中)。
基础(Grounding)
这是为预训练模型提供在训练期间不可用的额外信息的过程。例如,输入基础任务(input-grounded-tasks,见下面的任务的第一个)在提示中为模型提供了大量额外信息。非零样本提示在示例中为模型提供基础,改变了默认的模型行为。提示工程的全部内容是使模型在推理期间以某种特定方式来推理。
检索增强生成(RAG)是为模型提供基础的主要技术之一,因为它为推理过程提供了与提示相关的额外数据。目的是使模型比其训练时的大量压缩信息更重视这些信息。
微调到不同的知识领域是另一种基础方法,我们更新模型,使其在一个新的数据集上有基础,这个数据集可能与基础模型训练的原始数据领域完全不同。
基础可以被认为是提供上下文。正如任何人都可以证明的那样,当一个人理解问题的上下文时,回答问题会更容易。模型生成也是如此。上下文越好,生成的输出就越相关。
在多模态使用情况下,图像或视频与文本提示一起提供可以作为基础或上下文。
任务(Tasks)
输入基础任务(Input-grounded tasks)
输入基础任务是那些生成响应主要来自提示的任务,即主要知识包含在提示中。这些包括:
-
翻译
-
摘要
-
文档问答
-
多轮对话
-
代码编辑
-
语音识别(音频转录)
批处理(Batching)
一次处理一个token的解码阶段对加速器来说是非常低效的。将多个查询一起批处理可以提高加速器的利用率,并使一次处理多个请求成为可能。
批处理的最大可能大小取决于在加载模型权重和填充KV缓存后剩余的内存量。
静态批处理(Static batching)
这是最简单直接的批处理方式,前N个查询一起批处理 - 问题在于,如果许多查询已经完成生成,它们将不得不等待最长的查询完成,然后才能返回给调用者 - 大大增加了延迟。
连续批处理或飞行中的批处理(Continuous Batching or In-flight batching)
连续批处理或飞行中的批处理是一个过程,在这个过程中,生成引擎在生成完成后立即删除完成的查询,并用新查询替换它们,而不等待整个批处理完成。因此,批处理中位置0的序列可能正在生成其第10个token,而批处理中位置1的序列可能刚刚开始其第一个token生成,位置3的序列正在生成其最后一个token。
这提高了响应时间,因为不需要一个已经完成的序列立即返回,也不需要一个新的提示等待下一个批处理变得可用。当然,如果所有计算都忙于处理,并且没有新的空闲位置,那么一些请求将不得不等待计算开始处理它们。
分页注意力(Paged Attention)
分页注意力是推理服务器中非常流行的技术,因为它允许非常高效地利用加速器内存,通过接近加速器内存的方式使用分页,从而允许动态内存分配并防止内存碎片。
解码方法(Decoding methods)
主要的解码方法有:贪心解码、束搜索和采样。
(一)贪心解码(Greedy decoding)
贪心解码是模型总是选择概率最高的token。这是最快的解码方法,但它不一定生成最好的结果,因为它可能会选择一个不太理想的token路径,并错过一个很好的未来token序列。
贪心解码的主要问题是创建循环,即相同的句子被一遍又一遍地重复。
(二)束搜索(Beam search)
束搜索通过同时生成多个输出克服了贪心解码的限制,因此,在每个新token上,它遵循概率最高的3个输出(束大小为3),然后丢弃所有但3个子路径(3*3),这些子路径在链中的所有token的总概率最高。最后,选择概率最高的所有token的路径。
这种方法比贪心解码慢,因为它必须生成n倍多的token,并且需要n倍多的内存。
(三)采样(Sampling)
采样引入随机性。
但是,当然,选择随机词不会产生好的结果,所以我们仍然想要贪心解码的确定性,但通过向其添加受控的随机性使其更有趣/更生动。
最常见的采样方法是:
-
Top-K采样方法根据其logit概率选择前k个token,然后随机选择其中一个token。
-
Top-p采样(也称为nucleus采样)类似于Top-K采样,但K对于每个下一个token是可变的,并通过添加前k个token的概率直到达到阈值p来计算。因此,只有模型非常有信心时才会考虑这些预测。
(四)温度(Temperature)
温度是Top-p采样策略的一部分,其值如下:
-
t==0.0:最终选择概率最高的token - 没有随机性 - 与贪心解码相同 - 精确用例。 -
t==1.0: 对采样没有影响 - 这里保留了原始训练分布 - 平衡相关性和多样性用例。 -
0.0<t<1.0: 使logit概率进一步分离,因此越接近0.0随机性越少 - 介于精确和平衡用例之间。 -
t>1.0: 使logit概率更接近,创建大量随机性 - 创造性用例。
为了真正理解影响,温度因子通常在Softmax操作之前或作为其一部分应用到logit概率上。
logits = math.log(probs) / temperature
因此,很容易看出t=1.0没有影响,t=0会使最高logit趋于无穷大(避免除以零),而t<1.0和t>1.0会相应地推开或拉近值 - 因为log。
温度对贪心解码、束搜索和Top-K采样策略没有影响,因为它影响logit概率之间的距离,而所有这些策略都使用基于其顺序的top概率,温度不会改变概率的顺序。而Top-p采样允许更多或更少的竞争者进入基于其总概率的子集,因此,概率越接近(高温)随机性越大。
除了t==0.0和t==0之外,没有硬性规定的值可以复制,您必须为每个用例实验以找到最适合您需求的值 - 尽管您肯定会找到人们在不同用例中提供良好的基线。
指导文本生成(Guided Text Generation)
也称为结构化文本生成和辅助生成。
如果模型可以返回其生成的输出在特定的格式,而不是不受限制的格式,您不希望模型产生无效的格式。例如,如果您希望模型返回一个JSON字典,它应该这样做。
实现这一点的方法是使用指导文本生成。而不是选择概率最高的生成token,该技术使用下一个最佳概率的token,该token适合下一个预期的token子集。为了举例说明:如果您希望模型生成一个JSON字符串列表,如["apples", "oranges"],因此我们期望:
["string", "string", ..., "string"] 123...
第一个生成的token必须是一个[。如果模型得到",例如,而不是[,作为最高概率,而[的概率较低 - 我们选择概率较低的那个,以便它将是[。
然后,下一个生成的token必须是一个". 如果不是,搜索概率较低的token直到找到"并选择它。
第三个token必须是一个有效的字符串(即不是[或")。
以此类推。
基本上,对于每个下一个token,我们需要知道一个允许的token子集,并从该子集中选择概率最高的token。
这是一种非常酷的技术。与其尝试修复生成的输出,这些输出不一定总能匹配预期的格式,我们让模型首先生成正确的输出。
这种方法有几个缺点:
-
它降低了生成速度 - 它必须遵循的格式越复杂,生成token的速度就越慢。根据我对生成速度的测量,我发现一些结构化文本生成库比其他库快得多。
-
它可能会导致模型幻觉。
有多种实现这种技术的方法,截至本文撰写时,两个流行的库是:
-
https://github.com/outlines-dev/outlines
-
https://github.com/noamgat/lm-format-enforcer
您理想的做法是使用已经集成到推理框架(如vLLM)中的实现。
(一)使用指导生成加速推理(Faster inference with guided generation)
也可以使用模式来加速推理。例如,考虑这个简单的“profile”模式:
{ "type": "object", "properties": { "name": { "type": "string"}, "age": { "type": "integer"} }, "required": ["name", "age"] }
由于模式具有特定的键name和age,一旦模型预测到:{"n或{"a,它就不需要进行自回归生成来得到``{“name”: 和{“age”: ,因为这两者都必须导致一个特定的明确结果 - 因此在这里它可以执行预填充而不是解码,并节省一些缓慢的步骤,因为它100%知道接下来的几个token将是ame": 或ge":`。显然,当模式有很多预定的键和短生成值时,这种方法最有利。
推测解码(Speculative decoding)
也称为推测推理或辅助生成。
因为一次生成一个token非常慢,有时可以通过使用一个更小更快的草稿模型来作弊并加速。例如,您的正常推理使用Llama-70B,这会很慢,但我们可以使用Llama-7b作为草稿模型,然后我们可以验证预测是否正确,但一次为所有token执行。
示例:让我们以提示I'm turnin', turnin', turnin', turnin', turnin' around and all that I can see is just为例,现在:
-
使用Llama-7b以自回归方式预测
another lemon tree,在3步中完成,但比Llama-70b快得多。 -
现在使用Llama-70b运行3个提示的批处理:
[...I can see is just] [...I can see is just another] [...I can see is just another lemon]
我缩短了完整的提示以进行演示,...表示其它的prompt部分。我在这里假装每个token都是一个完整的单词。
现在,Llama-70B在一步中生成:
[...I can see is just] another [...I can see is just another] lemon [...I can see is just another lemon] tree
现在可能会有多个结果:
-
如果一切都匹配 - 在3个短步骤和1个长步骤中,我们生成了最终结果,而不是使用3个长步骤。
-
如果只有
another lemon匹配 - 如果我们节省了时间,我们可能会更好。 -
如果没有或很少匹配,我们浪费了一些时间。
显然,如果不止3个token,节省的时间可能会更大。
当有部分不匹配时,我们可以回到草稿模型,并给它所有匹配的token,直到第一个不匹配的token,然后是草稿模型预测的下一个好token,并让它对不匹配的尾部进行新的快速预测。
草稿模型理想情况下应该使用与大模型相同的数据(或至少来自相似分布的数据),并且它的分词器必须与大模型相同。
推测解码在输入导向任务(input-grounded-tasks)中效果最好,例如翻译、摘要、文档问答、多轮对话,因为在这类任务中可能的输出范围要小得多,而草稿模型更有可能匹配大模型。
对于同样的原因,它在贪心解码(greedy-decoding)中效果最好,因为在生成过程中可能的变化最少。如果不是使用贪心解码,您需要将温度(temperature)的值接近0。
这里有一个深入探讨这个主题的好文章:Assisted Generation: a new direction toward low-latency text generation(https://huggingface.co/blog/assisted-generation)。
另一个更简单的方法是使用ngram提示查找解码(https://github.com/apoorvumang/prompt-lookup-decoding),在这种方法中不需要草稿模型,而是搜索提示以生成候选者。在某些情况下,据说可以加快解码速度2倍以上。
隐私保护推理
大多数提供推理服务的公司都会遇到用户隐私需求。用户提交查询时应该是安全的,不会被他人窥探。一个解决方案是本地部署解决方案,即客户端自己运行服务器,这样就没有隐私问题,但这很可能会暴露提供者的知识产权——模型的权重以及可能的代码/算法。因此,需要一个完全加密的生成——即计算是在客户端加密的数据上进行的。
解决这一需求的方案被称为隐私保护机器学习(PPML)。
其中一种解决方案被称为完全同态加密(FHE)。
可以看看一个这样的实现,concrete-ml(https://github.com/zama-ai/concrete-ml),它重写了模型,使客户端能够自己运行部分模型,然后将中间加密的激活发送到服务器执行注意力机制,然后再发送回客户端。因此,提供者保留了部分知识产权——我认为这部分知识产权可以防止客户端窃取完整的知识产权,因为部分权重不足以重建完整的模型。这篇文章(https://huggingface.co/blog/encrypted-llm)有更多详细信息。
还有各种其他方法,例如这篇论文:LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers(https://arxiv.org/abs/2305.18396v3)探讨了基于安全多方计算(MPC)和FHE的定制解决方案,并有一个很好的参考列表。
当前解决方案的问题是巨大的计算开销——这极大地影响了成本和延迟。未来的ASIC解决方案应该能够解决这些问题。
模型并行
当模型无法适应单个加速器或跨多个加速器分割模型甚至即使它适合但勉强时,模型并行技术适用于推理。
大多数情况下,你最有可能只遇到张量并行,其中模型权重在2到8个加速器之间分片。理想情况下,你希望尝试将模型拟合到一个加速器中,因为这样它在生成期间的开销最少。但令人惊讶的是,如果你使用张量并行,你最终可能会获得更高的解码吞吐量——这是因为它使你能够适应更大的批次,也是因为forward调用可能比加速器之间的额外通信更快。当然,你将在这个成本下获得这种加速,因此在某些情况下,使用更多的加速器会获得更好的总吞吐量。所以最好进行实验,在某些情况下,更高的张量并行度将提供更好的总吞吐量,考虑到相同的加速器数量。
footnote: 在我的实验中,TP=1导致最高的TTFT和最低的解码吞吐量,与TP>1相比。所以,如果你被要求使TTFT更快,并且模型满足放得下,使用更小的TP或TP=1。如果你被要求使解码吞吐量更快,如果资源不是问题,则通过更高的TP来实现。
关键推理性能指标
有两种方法可以查看性能指标,一种是系统指标的延迟和吞吐量,另一种是用户体验指标:Time To First Token (TTFT)和Time Per Output Token (TPOT)。让我们看看两者。
系统性能指标
(一)延迟
延迟是指从发送请求到接收到完整响应所花费的时间。
这包括以下时间:
-
接收请求
-
预处理提示(预填充阶段)
-
生成响应的新token(解码阶段)
-
将响应发送回客户端
接收请求和发送响应的时间大致相同,只有小的变化,因为提示和生成响应的长度不同。这些长度变化对总时间的影响应该可以忽略不计。
预填充阶段并行处理所有提示的token,因此在这里提示长度的变化不应该有太大影响,尽管较长的提示会消耗更多的加速器内存并影响总吞吐量。
解码阶段是受生成响应长度影响最大的阶段,因为每个新token都是作为一个单独的步骤生成的。这里响应越长,解码阶段就越长。
如果服务器没有足够的容量一次处理所有当前请求,并且必须排队一些请求,那么排队等待时间会延长延迟时间。
脚注:如果你把道路上的汽车交通考虑在内,延迟是指从A点到B点(例如从家到办公室)所需的时间,包括由于交通信号灯、堵车和法律限制导致的速度限制。
(二)吞吐量
吞吐量衡量推理服务器并行处理多个请求和高效批处理请求的能力。
吞吐量的定义可以是同时可以处理多少请求,但由于有些请求比其他请求处理得快得多,因此在一个长请求期间可以处理多个短请求,所以计算整个系统生成的总token速率是有意义的。
因此,更常见的定义是推理吞吐量是整个系统每秒生成的总token数。
脚注:如果你把道路上的汽车交通考虑在内,吞吐量是指在任何给定时间内通过给定道路的汽车数量。道路车道越多,速度限制越高,吞吐量就越高。但显然有些车辆很短,有些很长,所以需要某种标准化。例如,渡轮计算可以容纳多少米或英尺的车辆,因此长车辆比短车辆支付更多费用。
用户体验指标
虽然可以通过许多特性来评估推理服务器的性能——如功耗、效率和成本,但有人可能会说,由于这些系统是与人类进行交互的,所以最重要的特征都集中在提供流畅用户体验的领域。如果用户体验缓慢且不流畅,用户将转向竞争对手。因此,关键需求是:
(一)第一个Token的时间
第一个Token的时间(TTFT)定义为用户点击提交按钮(或回车)到他们收到第一个单词或部分单词的时间。
希望第一个Token的时间(TTFT)非常短。如今,用户期望任何应用程序的响应时间理想情况下都要快于1秒。因此,用户等待开始接收第一个token的时间越短越好。这对于期望互动的聊天机器人尤为重要。TTFT的长度受许多因素影响,关键因素是预填充阶段的计算(提示的预处理)以及请求在用户请求接收后是否立即处理或是否需要在队列中等待。
重要的是要注意,在没有负载的服务器上,TTFT可能与在负载很重的服务器上非常不同。如果通常服务器在1秒内发送第一个token,如果服务器已经忙于处理所有请求并且有一个队列,除了前几个请求外,有效的TTFT可能会长得多。因此,通常应测量平均TTFT并与基准测试期间发送的并发请求数量一起报告。
这是一个复杂的指标,因为根据提示的大小,时间会有所不同,因此理想情况下你希望将其标准化为提示中的token数量。
(二)每个输出Token的时间
每个输出Token的时间(TPOT)是每个用户的指标。它衡量为给定用户生成新token所需的时间。
希望每个输出Token的时间(TPOT)相对较低,但不必太高。这个时间理想情况下应该接近发送请求的人的阅读速度。例如,如果你服务的是一年级学生,TPOT可以相当低,但受教育程度越高的人,TPOT应该越快,以实现流畅的阅读体验。
根据维基百科,3种阅读类型(https://en.wikipedia.org/wiki/Speed_reading#Types_of_reading),阅读速度以每分钟单词数(WPM)来衡量。
每个单词的平均token数因分词器而异,主要取决于其词汇量和语言。在这里,我们考虑一个英语分词器,大约每个单词1.5个token。现在我们可以将每分钟单词数(WPM)转换为每分钟token数(TPM)。
现在我们只需要除以60得到每秒token数(TPS),并取倒数得到每个输出token的时间(TPOT)。
所以 TPOT = 60 / (WPM*1.5) 以秒为单位
| 读者 | WPM | TPM | TPS | TPOT |
|---|---|---|---|---|
| 发声阅读 | 250 | 375 | 6.25 | 0.16 |
| 听觉阅读 | 450 | 675 | 11.25 | 0.089 |
| 视觉阅读 | 700 | 1050 | 18.75 | 0.057 |
记得将1.5系数更改为你的分词器的实际单词到token的平均比率。例如,截至本文撰写时,OpenAI ChatGPT的50k词汇量大约为每个单词1.3个token,而许多其他LLM有30k词汇量,这导致更高的单词到token比率。
如你所见,TPOT是一个难以跟踪和在脑海中思考的值,因此一旦你知道了目标TPOT,最好将其转换为每秒token数(TPS)并跟踪它。
因此,在这个例子中,如果你的系统可以每个请求持续生成20个token每秒,你的客户将会满意,因为该系统将能够跟上每分钟700个单词的超级快速读者。
当然,也会有用户更喜欢在生成完成后再开始阅读响应。在这种情况下,越快越好。
根据生成的类型,可能适用以下情况:
-
图像 - 一次性生成
-
文本 - 与用户的阅读速度一样快,或者如果他们不喜欢在开始阅读前有移动部分,则一次性生成
-
音频 - 与用户的听力速度一样快
-
视频 - 与用户的观看速度一样快
如果这是一个不与个人用户接口的离线系统,并且只是批量处理请求,这些指标没有区别,但延迟和吞吐量是关键指标。
简化的性能指标
如你所见,上述讨论的指标有很多重叠之处。实际上,我们可以将所有这些指标简化为这两个指标:预填充吞吐量和解码吞吐量 - 以及系统每秒可以处理的并行请求数量。
(一)预填充吞吐量
这是系统预处理提示的速度 - 以每秒token数计算。
假设接收和发送请求的开销可以忽略不计,在没有队列的情况下,传入请求立即被处理,TTFT实际上是提示中的token数量除以预填充token每秒数加上生成第一个token的时间(可以忽略,因为它会非常快)。
如果有队列,那么预填充吞吐量就不够了,因为TTFT可能会长得多,因为必须加上请求在队列中等待的时间。
(二)解码吞吐量
这是系统生成响应token的速度 - 以每秒token数计算。
这同时解决了吞吐量和每个输出Token的时间指标。
响应延迟是提示中的token数量除以预填充吞吐量加上生成的token数量除以解码吞吐量。
更多指标说明
(一)加速器利用率
加速器利用率 - 无论是百分比还是功率测量,都是判断您的设置是否高效使用加速器的良好指标。例如,如果您使用NVIDIA GPU,并通过 -n 0.5 nvidia-smi 命令观察,发现在大量请求轰炸推理服务器的情况下,"gpu util"仅为10%,这通常意味着以下两种情况之一:要么推理服务器效率非常低(例如,花费大量时间在来回复制数据上),要么可能是客户端在接收数据时效率低下(即存在过多的IO阻塞)。
脚注:当我最初使用openai客户端编写一个简单的基准测试时,在低并发情况下运行良好,但在更高并发下,推理服务器的GPU利用率降至6-7%。在我用aiohttp API替换客户端后,利用率上升到了75%。因此,请注意,可能是您的基准测试导致了性能报告不佳,而不是服务器的问题。
这有点类似于使用TFLOPS来衡量训练效率(https://github.com/stas00/ml-engineering/blob/master/training/performance/README.md#tflops-as-a-performance-metric)。
在理想情况下,你希望加速器利用率尽可能高。要注意的是,至少对于NVIDIA GPU,gpug util 不是你认为的那样(https://github.com/stas00/ml-engineering/blob/master/compute/accelerator/nvidia/debug.md#how-to-get-the-real-gpu-utilization-metrics),但如果它报告一个非常低的百分比,足以知道确实存在效率问题。
(二)百分位数
如果你阅读基准测试并遇到像p50、p75、p90、p95和p99百分位数之类的东西 - 这些是统计过滤器,根据结果在某个阈值以下(或以上)的百分比给出结果。即使相同的请求在多次重新运行时也可能需要稍微不同的响应时间。例如,如果95%的时间吞吐量高于某个值,则该值为p95百分位数。这也意味着5%的时间吞吐量低于该相同的阈值。百分比越高,越难实现。
例如,让我们看看一个系统加载报告的部分输出,该报告由k6(https://github.com/grafana/k6)生成:
http_req_duration..: avg=13.74s min=12.54s med=13.81s max=13.83s p(90)=13.79s p(95)=13.83s http_req_receiving.: avg=27.98µs min=15.16µs med=21.6µs max=98.13µs p(90)=44.98µs p(95)=59.2µs http_req_sending...: avg=133.8µs min=20.47µs med=75.39µs max=598.04µs p(90)=327.73µs p(95)=449.65µs
如果我们看报告的第一行总生成时间,如果我们看记录的最小值12.54秒,我们就知道90%的响应时间在12.54到13.79秒之间,95%的响应时间在12.54到13.83秒之间 - 在这种情况下,中位数报告值在p90和p95值之间。
同样的解释适用于报告中的其他行,但这里的关键例证是p90值低于p95值,因为时间正在被测量(越低越好)。
百分位数在异常值不重要时很有用,例如,与其看测量的最慢吞吐量,你可以忽略最差的5%的结果,突然间系统的性能看起来好得多。但在处理用户时必须非常小心这种丢弃不良结果的方法,因为这意味着一些用户会有不好的使用体验。此外,如果你有数百万用户,5%就意味着很多用户。
请参考百分位数(https://en.wikipedia.org/wiki/Percentile)以获得更深入的解释。
加速模型加载时间
在生产环境中提供服务时,可能可以让模型花费时间加载,因为它只发生一次,然后服务器运行数天,因此这个开销在多天内被摊销。但是在进行研究、开发和测试时,推理服务器需要非常快速地开始提供服务。
有时开销只是加载到CPU然后将张量移动到加速器,其他时候还需要将张量分片到多个加速器以执行TP和PP。
为此使用了各种方法 - 大多数涉及某种预共享和缓存,然后直接加载到GPU。
例如:
-
vLLM支持
--load-format标志,可以选择npcache(numpy格式缓存)或使用CoreWeave的Tensorizer(https://github.com/coreweave/tensorizer)的tensorizer选项。(https://docs.vllm.ai/en/latest/serving/tensorizer.html),当然,如果你使用TP>1,你需要预先分片权重(https://docs.vllm.ai/en/latest/getting_started/examples/save_sharded_state.html)。 -
TensorRT-LLM要求用户为每个特定用例构建模型引擎,并在运行时加载预制的分片(除非你使用简化的API,它将在每次服务器启动时动态构建模型引擎)。
基准测试
你可以按照关键推理性能指标中解释的那样编写自己的基准测试,或者使用现有的基准测试。
目前我主要使用预填充吞吐量和解码吞吐量基准测试。第一个基准测试只是测量从发送请求到接收到第一个生成的token之间的每秒token数,第二个基准测试是从接收到第一个生成的token到接收到最后一个生成的token之间的吞吐量。以下是使用openai客户端完成API(https://github.com/openai/openai-python)进行此类测量的相关代码片段:
[... create client, data, etc. ...] prefill_tokens_len = len(prompt) start_time = time.time() decode_text = "" decode_started = False completion = client.completions.create(prompt=prompt, ...) for chunk in completion: if chunk.choices: decode_text += text if not decode_started: decode_started_time = time.time() prefill_time = decode_started_time - start_time decode_started = True end_time = time.time() decode_time = end_time - decode_started_time decode_tokens = tokenizer.encode(decode_text) decode_tokens_len = len(decode_tokens) # tokens/per sec prefill_throughput = prefill_tokens_len / prefill_time decode_throughput = decode_tokens_len / decode_time
这里的prefill_throughput不是很精确,因为客户端只知道它发送请求和接收到第一个token的时间,所以在这个阶段比纯粹的提示预处理多了一些内容,但应该足够接近。
当然,像任何严肃的基准测试一样,你需要多次运行以获得真实的数字,因为单次运行之间的差异可能会很大。
注意:我发现当我使用openAI客户端时,它在多并发请求下扩展性不好,openAI客户端会成为瓶颈,无法测量真实的服务器性能——我还不确定这是我的代码问题还是openAI客户端的问题,或者它与vLLM服务器的交互问题——我正在这里调查 https://github.com/vllm-project/vllm/issues/7935 ——我发现 这个版本(https://github.com/vllm-project/vllm/blob/f842a7aff143a4a1ddc59e1fb57109cb377f5475/benchmarks/backend_request_func.py#L223-L301)的客户端,重写为使用aiohttp,扩展性非常好——所以我改用它。
以下是一些负载测试的良好起点:
-
https://github.com/vllm-project/vllm/blob/main/benchmarks/benchmark_throughput.py - 目前为止我最喜欢的工具
-
https://github.com/grafana/k6 - 用于负载测试以模拟多个并发客户端 - 使用JavaScript客户端。
-
https://github.com/bentoml/llm-bench - 基准测试推理负载(尚不确定是否仅适用于BentoML)
我现在缺少的是一个测量服务器能处理的最高并发量的工具。
模型内存使用情况解析
推理时的内存使用情况与训练(https://github.com/stas00/ml-engineering/tree/master/training/performance#anatomy-of-models-memory-usage)时有很大不同。这里我们有:
-
模型权重
-
KV缓存 - 关键在于不需要为每个新生成的token重新计算过去的token
-
激活内存 - 这是处理的临时内存,取决于批量大小和序列长度
模型权重
-
4字节 * 参数数量(fp32)
-
2字节 * 参数数量(fp16/bf16)
-
1字节 * 参数数量(fp8/int8)
-
0.5字节 * 参数数量(int4)
脚注:在你阅读这篇文章时,更紧凑的格式正在被研究,例如微缩格式(MX)(https://fpga.org/category/microscaling-mx-formats/),也称为块浮点数,其中指数位在张量的多个元素之间共享(MXFP6,MXFP4等)。
示例:Meta-Llama-3.1-8B在bf16格式下需要2(bf16字节)* 8B(参数数量)= 16GB(大约)
KV Caching
在每次生成新token之前重新计算所有之前的KV(Key Value)值会非常昂贵,因此它们被缓存到加速器的内存中。新计算的KV值被附加到现有缓存中。
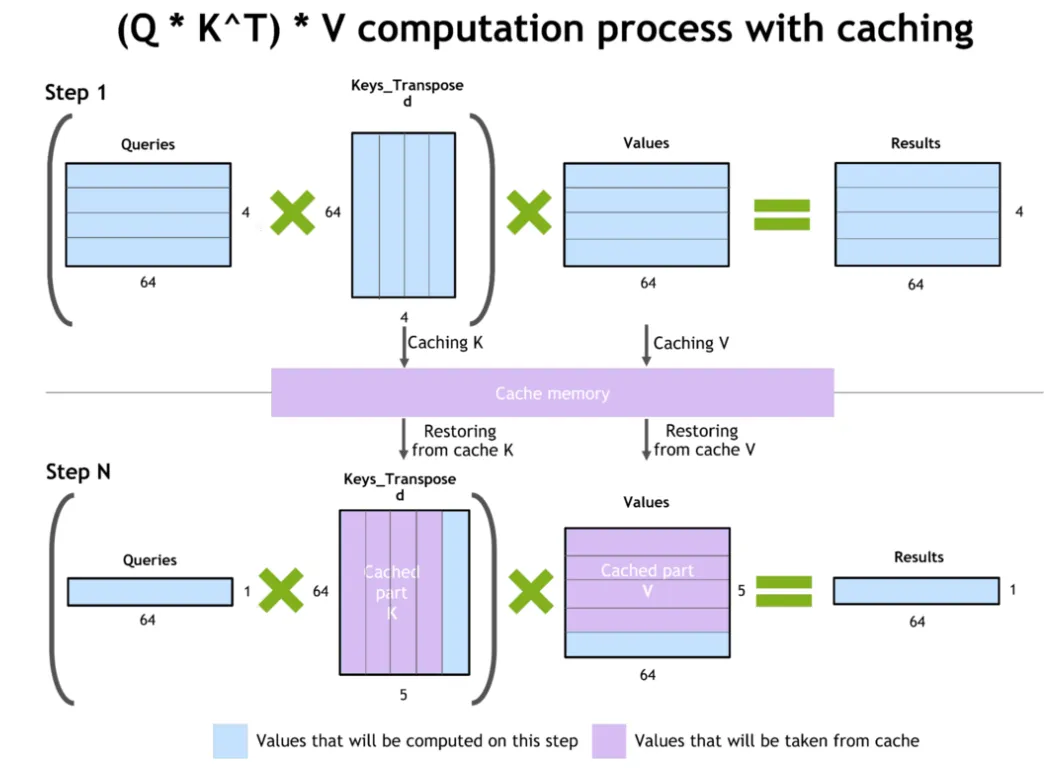
KV缓存大小与输入序列长度和批量大小直接成正比。过去的查询值在注意力机制中不再使用,因此不需要缓存。
一个KV缓存需要dtype_bytes * 2 * num_hidden_layers * hidden_size * num_key_value_heads / num_attention_heads字节
备注:
-
dtype_bytes是每种数据类型字节数:4字节fp32,2字节bf16/fp16等。 -
2表示keys + values,因为它们有2个。 -
num_key_value_heads / num_attention_heads是取决于是否使用多查询注意力(MQA)、分组查询注意力(GQA)或多头注意力(MHA)的因子。对于MHA,它是1,对于MQA,它是1/num_attention_heads,对于GQA,它取决于每组使用的查询数量,即num_key_value_heads / num_attention_heads,这是MHA和MQA的一般情况。
你可以在模型文件夹中的config.json中获取这些维度,或者从等效文件中获取。例如meta-llama/Meta-Llama-3.1-8B(https://huggingface.co/meta-llama/Meta-Llama-3.1-8B/blob/main/config.json)。
示例:
1 token Meta-Llama-3.1-8B in bf16将需要:2 (bf16 bytes) * 2 (keys+values) * 32 (num_hidden_layers) * 4096 (hidden_size) * 8 (num_key_value_heads) / 32 (num_attention_heads) / 10**6 = 0.131MB。这个模型使用GQA,所以它使用vanilla MHA的1/4。
批量大小为1的1024个token将需要0.131*1024 = ~134MB。
批量大小为128的1024个token将需要0.131*1024*128 / 10**3 = ~17.2GB。
如果Meta-Llama-3.1-8B使用MHA,每个token将需要4倍多的内存,如果使用MQA,每个token将需要8倍少的内存。从这张图中很容易看出原因:
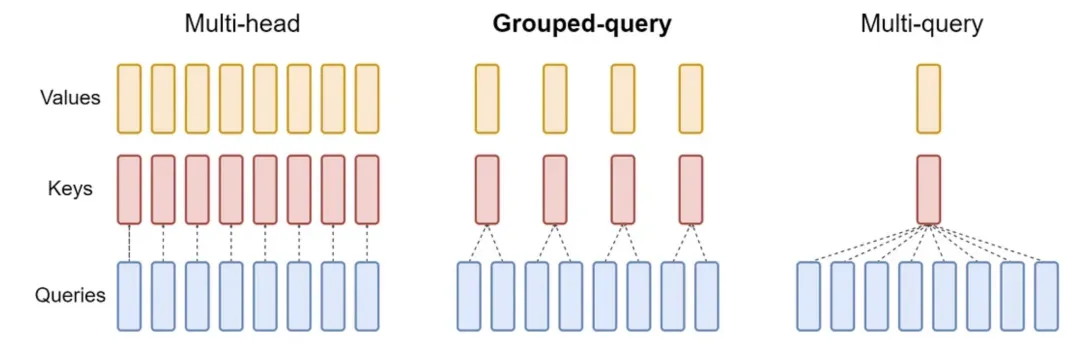
source(https://arxiv.org/abs/2305.13245)
在这种情况下,模型有num_key_value_heads=8和num_attention_heads=32,因此MQA和GQA分别使用32x和4x更少的内存。
KV缓存在保存重计算时对推理性能有重大影响。以下是Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference(https://arxiv.org/abs/2403.09636)中的一段引文:
内存受限和计算受限操作
使用GPU加速器执行的每个操作,例如通用矩阵乘法(GEMM),要么是内存受限的,要么是计算受限的。在前一种情况下,总运行时间主要受高带宽内存(HBM)访问的影响,而在后一种情况下则受实际计算的影响。使用Transformer大语言模型进行自回归生成时,每次前向传递的序列长度为n=1,往往是内存受限的而不是计算受限的。前向传递的大部分时间要么用于处理线性层(在MHSA、前馈和输出词汇投影中),要么用于计算注意力分数和从公式(4)中得出的输出。对于线性层,FLOPS与内存访问的比率随着批量大小的增加而改善,并且随着从HBM检索到的一组层权重执行更多的FLOPS。最终,随着批量大小足够大,线性层变得计算受限。另一方面,在自回归推理期间MHSA层内计算公式(4)时,FLOPS与输入大小的比率保持不变,并且MHSA层无论批量大小如何都是内存受限的。因此,对于这些层,延迟与KV Cache的大小成线性关系。
- 公式(4)是常见的自注意力机制公式
Softmax(Q,K)V
一个更小的KV缓存将导致更快的生成和更高的GPU利用率。因此,各种技术,如gisting、上下文蒸馏、键值淘汰策略、内存压缩、多查询注意力、分组查询注意力、跨层注意力、基于锚点的自注意力、量化等,都是为了实现这一点。
在小批量大小的情况下,您应该检查禁用KV缓存是否能带来更好的整体性能。
推理框架
有许多推理框架,而且每周都有新的框架出现,所以很难将它们全部列出。因此,这里提供了一些可能适合您需求的推理框架的入门列表,但如果这里列出的框架不能满足您的需求,请查看其他框架。
本节力求保持中立,不推荐任何特定的框架,因为即使我能够全部尝试,也无法猜测哪个框架最适合哪个用户/公司。
- vLLM
vLLM(https://github.com/vllm-project/vllm)
- DeepSpeed-FastGen
DeepSpeed-FastGen(https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-fastgen) from the DeepSpeed team(https://github.com/microsoft/DeepSpeed).
- TensorRT-LLM
TensorRT-LLM(https://github.com/NVIDIA/TensorRT-LLM) (also integrated what used to be FasterTransformer)
仅支持NVIDIA GPU。
- TGI
TGI(https://github.com/huggingface/text-generation-inference)
- SGLang
SGLang(https://github.com/sgl-project/sglang)
- OpenPPL
OpenPPL(https://github.com/OpenPPL/ppl.nn)
- LightLLM
LightLLM(https://github.com/ModelTC/lightllm)
- LMDeploy
LMDeploy(https://github.com/InternLM/lmdeploy)
- MLC-LLM
MLC-LLM(https://github.com/mlc-ai/mlc-llm)
如果您的首选推理框架未列出,请提交PR并添加它。
- 特定加速器框架
大多数推理框架显然支持NVIDIA CUDA。一些支持AMD ROCm和Intel Gaudi。
但也有特定加速器的框架:
- Intel Gaudi, MAX等。
https://github.com/intel/intel-extension-for-transformers
如何选择推理框架
要选择最合适的推理框架,您需要回答至少以下问题:
-
该框架是否具有您所需的功能?请小心,有些框架声称支持功能A,但当你尝试使用它时,发现它没有很好地集成或工作非常缓慢。
-
该框架是否有符合您当前和未来需求的宽松许可证?在实践中,我们发现遵循商业使用反对许可证的框架可能会被社区拒绝。例如,HF的TGI试图为商业使用收费,结果适得其反——它的许可证被恢复为原始的Apache 2.0许可证,现在他们试图从被社区排斥中恢复过来。
-
该框架是否有活跃的贡献者社区?访问框架的github仓库,检查它有多少贡献者——如果贡献者很少,我会担心,因为蓬勃发展的框架通常会邀请贡献,这意味着即使核心贡献者没有时间,一些贡献者也可能为您完成。
-
该框架是否有高采用率?github星星通常是一个很好的指标,但有时可以通过聪明的营销策略来炒作。因此,寻求其他信号——例如框架仓库主页上的
Used by计数,这些是真实数字。大量的PR和Issues是另一个标志。然后搜索关于给定框架写了多少篇文章。 -
该框架的维护者对Issues和PRs的响应是否积极?有些框架会忽略许多Issues和PRs。检查未被解决的PR和Issues的数量。高未解决的开放Issues是一个困难的信号——从一方面看,这意味着这是一个受欢迎的项目,从另一方面看,这意味着开发团队和贡献者无法满足其用户的需求。
-
虽然大多数ML推理框架是用Python编写的,但有些不是用Python编写的(例如NVIDIA的TensorRT-LLM是99%的C++,TGI的大部分是用Rust编写的)。如果某些东西不能按您需要的方式工作,并且您已提交Issue,但未得到解决,您是否能够动手修改框架以满足您的需求?
-
您可能会遇到的问题是,有些框架不希望您实现缺失的功能或改进,然后您将不得不维护一个分支,如果您想继续与上游同步,这将非常困难,并给您的开发人员带来很多痛苦。
-
为所需的负载运行某种基准测试,以了解性能是否足够。
-
您是否希望将来选择最佳成本效益的加速器,或者您是否可以接受锁定到特定的供应商?例如,NVIDIA的框架不太可能支持除了NVIDIA之外的其他加速器。同样适用于AMD和Intel。
例如,以下是2024-08-24时vLLM(https://github.com/vllm-project/vllm)的统计数据,这是目前最受欢迎的推理框架之一。
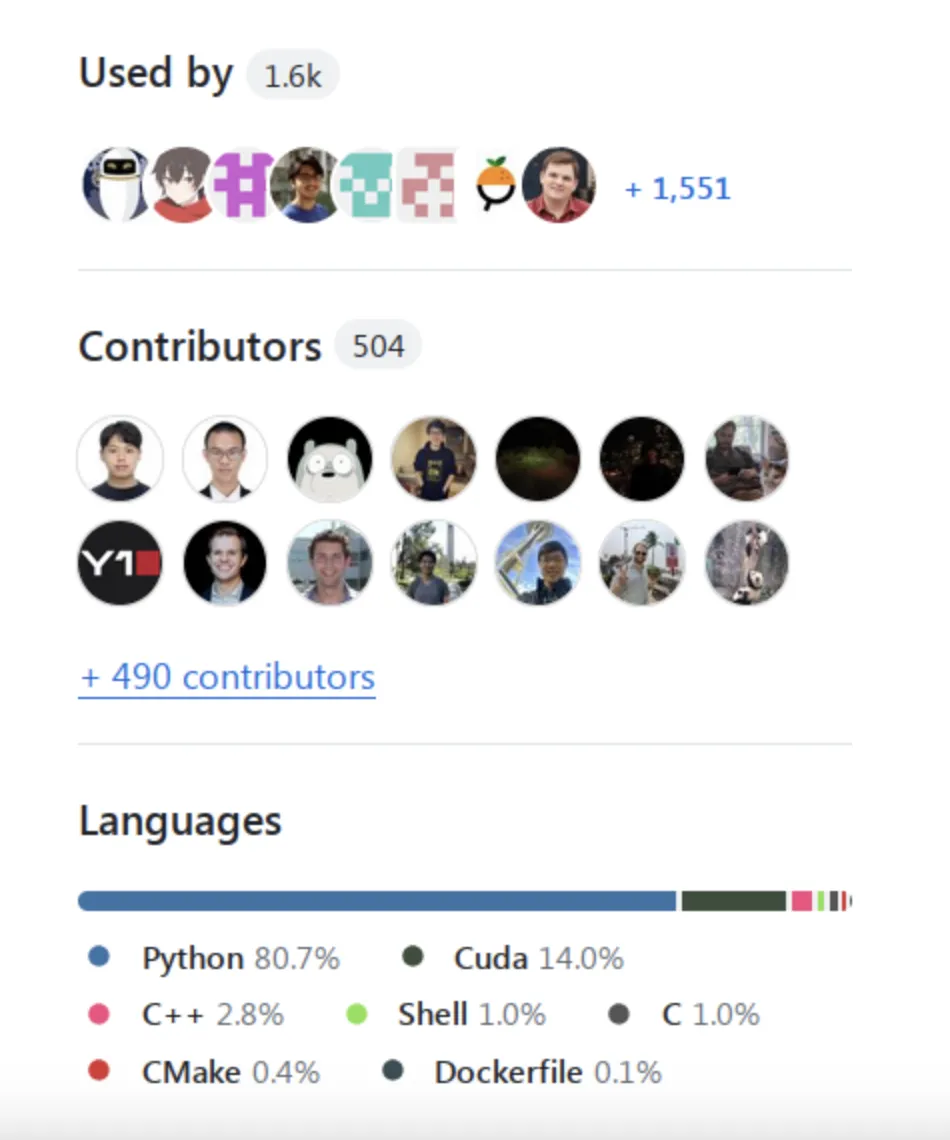
您可以看到它被许多github仓库使用,有许多贡献者,主要用Python编写。因此,应该很容易找到关于您可能考虑的任何推理框架的信息。这只是一个例子,并不是对vLLM的推荐。
推理芯片
除了通用加速器,一些厂商还在开发专门用于推理的ASIC。
Groq
- Groq(https://groq.com/)
资源
- A Survey on Efficient Inference for Large Language Models (2024)(https://arxiv.org/abs/2404.14294)
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!
💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。
路线图很大就不一一展示了 (文末领取)
👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥两本《中国大模型落地应用案例集》 收录了近两年151个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

👉GitHub海量高星开源项目👈
💥收集整理了海量的开源项目,地址、代码、文档等等全都下载共享给大家一起学习!
👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告(持续更新)👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓