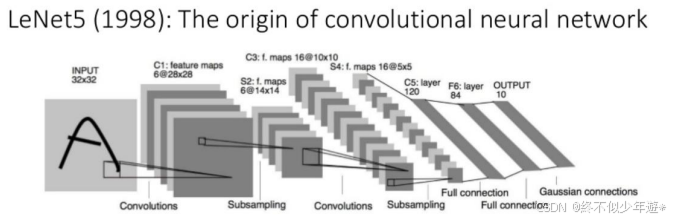
LeNet
7层网络(里程碑)
概述
定义:LeNet是第一个成功应用于手写数字识别的卷积神经网络(Convolutional Neural Network, CNN)架构,由Yann LeCun及其团队在20世纪90年代开发。
意义:LeNet的成功证明了卷积神经网络在处理图像识别任务中的有效性,并为后续深度学习模型的发展奠定了基础。它的出现标志着深度学习从理论研究走向实际应用的重要转折点。
网络结构
输入层:接收32x32像素的灰度图像。
第一卷积层(C1):使用6个5x5的卷积核进行卷积操作,输出尺寸为28x28的特征图。
第一池化层(S2):对C1的输出进行2x2的平均池化,输出尺寸减半至14x14。
第二卷积层(C3):使用16个5x5的卷积核,输出尺寸为10x10的特征图。
第二池化层(S4):再次进行2x2的平均池化,输出尺寸减半至5x5。
第一全连接层(C5):将S4的输出展开为一维向量,连接到120个神经元。
第三全连接层(F6):连接到84个神经元。
输出层:使用softmax函数输出10个类别的概率,对应于数字0到9。
为什么叫LeNet5?
除去两层池化,有5层网络需要计算参数,两层卷积层、两层全连接层和一个输出层
原始的输入层是一副二维(32*32)图片
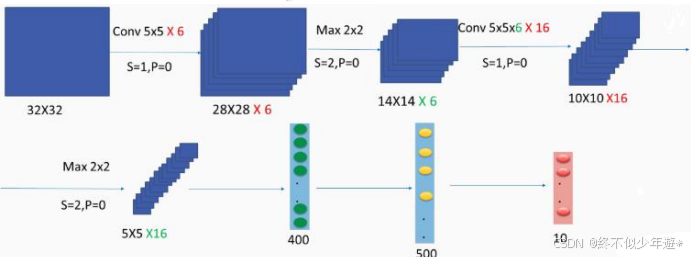
使用6个卷积核,池化模式是VALID,因为在第一层卷积过程中行和列到28后,32-29=4,不足再卷积一次,舍弃,就从原始输入卷积到28--32得到卷积后的第28行、列
第二层池化时选择了2*2的最大卷积方式,面积缩小2*2倍
优点
LeNet的网络结构相对简单,参数较少
特征提取能力强:通过多层卷积和池化层,LeNet能够有效提取图像中的特征,对平移、旋转等图像变换具有一定的鲁棒性
可扩展性强,也可以应用到其他的一些图像识别中
稀疏连接矩阵:通过局部感受野和参数共享减少了模型的参数数量,降低了过拟合的风险。
平均池化:用于下采样,减少数据的空间尺寸,同时保留重要信息。
Sigmoid激活函数:在早期的版本中使用Sigmoid函数作为激活函数,后来的版本中引入了tanh激活函数以提高训练效率。
小参数量:整个网络的参数少于1百万,使得即使在当时的硬件条件下也能较快地进行训练。
缺点
训练速度慢
硬件 算力不足
全连接层 参数较多
存在梯度消失 -- 神经元死亡问题
当时缺乏数据
只能处理较小的图像(如32x32像素),对于大尺寸图像需要将其缩小再输入模型进行处理,这可能会导致信息的丢失
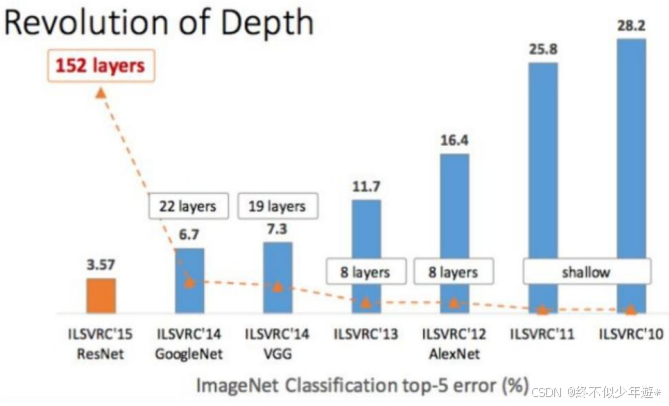
top-5 error 随着神经网络参数参数的加深,非线性变化越多,使误差得到一定降低
Alexnet
8层网络
AlexNet是2012年由Alex Krizhevsky等人提出的一种深度卷积神经网络,它在ImageNet大规模视觉识别挑战赛(ILSVRC)上取得了显著的成绩。
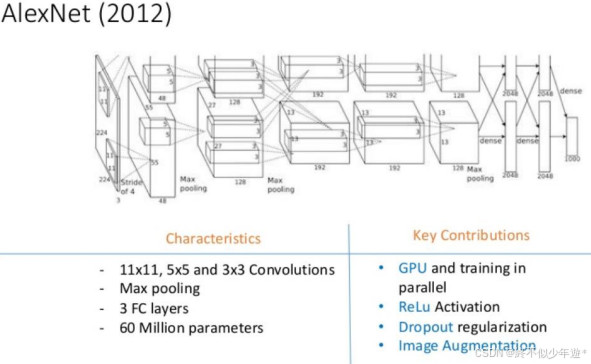
结构特点
层数:AlexNet包含8个学习层,其中5个是卷积层,3个是全连接层(FC)。
卷积核大小:前两个卷积层的卷积核大小为11x11,后三个为5x5,最后一个为3x3。
池化操作:在每个卷积层之后都进行了最大池化操作。
参数量:整个网络有60百万个参数。
关键技术
GPU并行计算:AlexNet首次展示了使用GPU进行大规模并行(单卡多机训练)训练的有效性,大大提高了训练速度。
ReLU激活函数:引入了Rectified Linear Unit(ReLU)作为非线性激活函数,解决了Sigmoid激活函数可能导致的梯度消失问题。
Dropout正则化:通过随机丢弃部分神经元来防止过拟合,增强了模型的泛化能力。
数据增强:通过对输入图像进行随机裁剪、旋转等操作来增加训练数据的多样性,提高模型对不同场景的适应性。
参数达6千万,容易过拟合,所以使用了正则化的策略
Dense层在神经网络中指的是全连接层(Fully Connected Layer),也被称为密集层(也是FC)
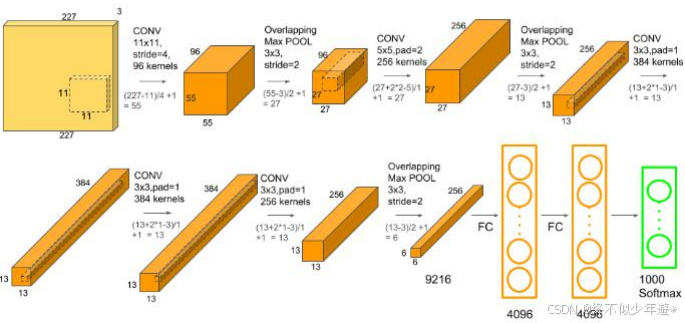
一条线 96个11*11的卷积核
随着GPU计算能力的增强,开始用单块GPU跑Alexnet网络,步长为3*3,S=3有重叠的池化,会更加平滑
池化时,步长为2**n次时,下一层的图像面积缩小2**n**2,为偶数时缩小程度为(S-1)**2,公式是(side-S)//2+1
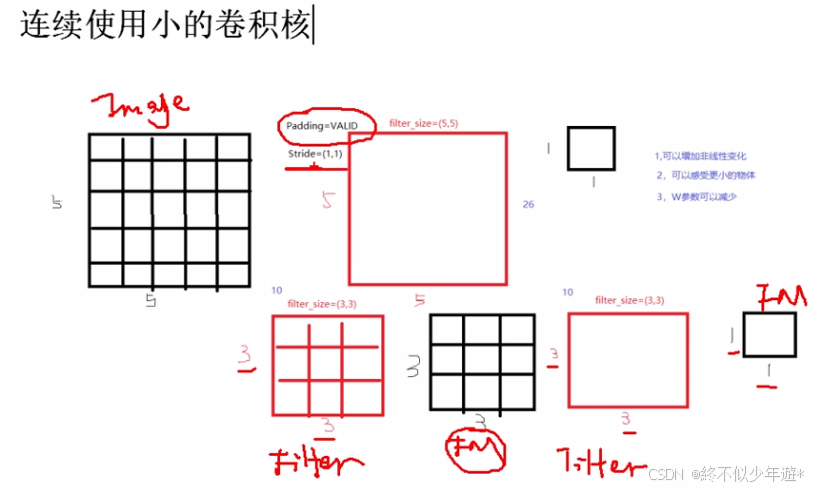
连续使用小的卷积核的好处
可以连续卷积(使用小的卷积核)后再做池化,对比之下使用5*5的卷积核处理5*5的图片和使用3*3的卷积核处理5*5的图片,后者连续使用了两次卷积过程,得到的结果都是1*1的future map
5*5的卷积核需要计算的参数:5*5+1=26
连续两次3*3的卷积核需要计算的参数:(3*3+1)*2=20
训练参数减少了,多一次卷积可以提取更高阶的特征,多了一次非线性变换
可以感受更小的物体
Dropout
在深度学习中,dropout最流行的正则化技术,它被证明非常成功,即使在顶尖水准的神经网络中也可以带来 1%到 2%的准确度提升,这可能乍听起来不是特别多,但是如果模型已经有了 95%的准确率,获得 2%的准确率提升意味着降低错误率大概 40%,即从 5%的错误率降低到 3%的错误率!
在每一次训练 step 中,每个神经元,包括输入神经元,但是不包括输出神经元,有一个概率神经元被临时的丢掉,意味着它将被忽视在整个这次训练 step 中,但是有可能下次再被激活。如果这一轮训练前向传播时,部分神经元被dropout,也就是权重调为0,该次反向传播BP时,对应的神经元也不会参与链式求导。因为每轮的训练随机dropout,所以这次被dropout的神经元在下一轮次的训练时也可能恢复活性。
每一轮的dropout是:
for epoch in epochs:
for bateh in batehs:
每轮的step,前向传播、反向传播中进行
超参数 p 叫做 dropout rate,一般设置 50%,在训练之后,神经元不会再被 dropout,也就是model应用到测试集上时恢复每个神经元的活性,那么dropout过程可以看成是对随机的神经元进行‘特训’
举个例子:公司每天投掷硬币只要一半的员工上班,或许带来的公司收入更高?公司或许因为这个被迫调整组织结构,也许某个员工一人会进行多个任务,而不是像平时受制于一俩个员工的缺席,这里的员工类比到神经元,公司则类比神经网络
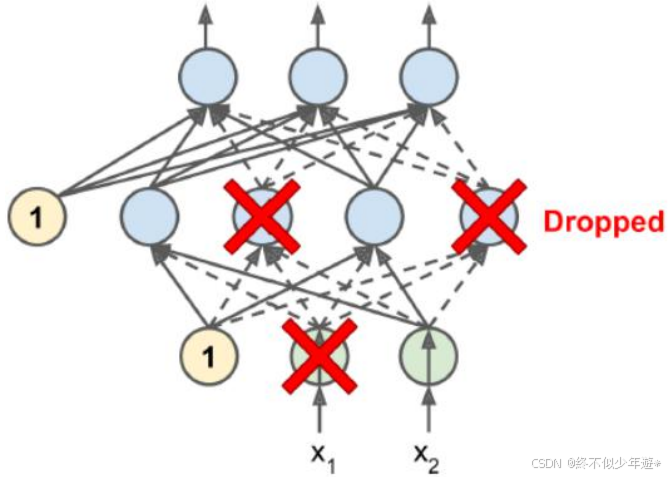
输入层开始就可以进行dropout,丢数据就是丢特征
在机器学习、深度学习中、随机并不是坏事,是一个很重要的概念!
dropout思想有点像随机森林,一棵大树拆分成多棵小树,对比大树,小树更不容易过拟合,但是小树的预测可能不够准确,可以集成足够多的小树来提升性能
为什么dropout更多的使用在全连接层?
全连接层的参数多,随机的意义更大
VGG16
网络中需要计算参数的有16层,卷积层+全连接层
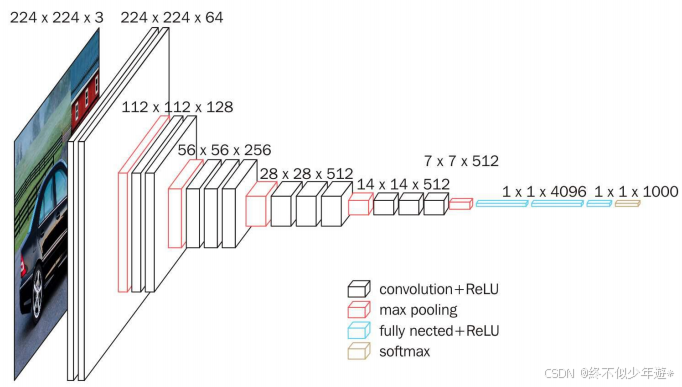
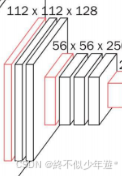
这里不太准确,池化并不改变通道数,第一次池化后应该为112*112*64
特点:
参数减少:使用3x3卷积核相比5x5或7x7卷积核,可以显著减少参数数量。例如,一个3x3卷积层有32=932=9个参数,而5x5卷积层有52=2552=25个参数,7x7卷积层有72=4972=49个参数。这意味着在保持相同感受野的情况下,3x3卷积可以更有效地利用参数。
非线性激活:VGG网络在每个卷积层之后使用ReLU激活函数,这增加了网络的非线性能力,有助于捕捉更复杂的特征。
网络深度:VGG网络通过堆叠多个卷积层来增加网络的深度,这有助于提高模型的性能。深度网络可以学习到更加抽象和复杂的特征表示。
模块化设计:VGG网络的设计非常模块化,通常由多个卷积层、池化层和全连接层组成。这种模块化设计使得网络易于理解和实现。
性能提升:尽管VGG网络的参数数量较多(如表中所示,E配置有140M参数),但由于其深度和有效的参数利用,它在图像识别任务上表现出色。
1*1的卷积核如何降维
在单通道图像上,通过设置S步长,比如3*3的图像
1 1 1
1 1 1 S=(2,2) 得到的结果就是2*2的fm
1 1 1
在多通道图像上,则设置卷积核的个数,通过提取的通道数来降维
卷积核如何替代全连接
filter个数设置原本全连接层的参数数量
全连接用卷积替换的好处
一开始输入的图像大小可变
Inception
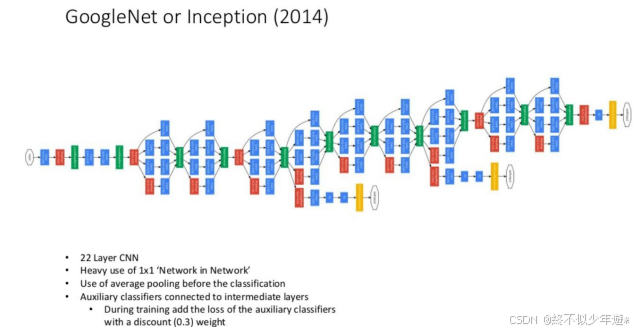
Inception概述
定义与目的:Inception结构是一种高效的特征表达方式,旨在通过增加网络深度和宽度来提升模型性能,同时减少参数数量和计算复杂度。
设计哲学:基于稀疏性高的相关性单元聚集在图像局部区域的思想,通过构建“基础神经元”结构来实现高效计算。
为什么要使用Inception
挑战与解决方案:直接增加网络深度和宽度会导致参数过多和过拟合问题,而Inception结构通过模块化设计有效解决了这一问题。
NiN的启发:Network In Network (NIN)的结构为Inception提供了灵感,尤其是1×1卷积核的使用,显著降低了参数量并提高了非线性表达能力。
Inception v1
结构特点:原始Inception结构和GoogLeNet中的Inception v1结构对比,后者通过引入1×1卷积核减少了计算量。
计算量优化:通过在高维卷积前使用1×1卷积核进行信息压缩,大幅降低了计算量。
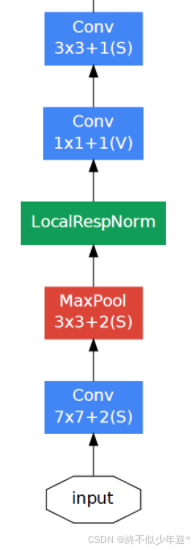
Inception v1 网络结构
|
|-- 输入层
| |-- 尺寸: 224x224x3
| |-- 卷积层: 7x7, 64 filters, stride=2
| |-- 池化层: 3x3 max pool, stride=2
|
|-- Inception模块1
| |-- 1x1卷积: 64 filters
| |-- 3x3卷积: 192 filters
| |-- 5x5卷积: 48 filters
| |-- 3x3卷积: 64 filters
| |-- 最大池化: 3x3, stride=1
|
|-- Inception模块2
| |-- 1x1卷积: 128 filters
| |-- 3x3卷积: 320 filters
| |-- 5x5卷积: 80 filters
| |-- 3x3卷积: 128 filters
| |-- 最大池化: 3x3, stride=1
|
|-- Inception模块3
| |-- 1x1卷积: 256 filters
| |-- 3x3卷积: 640 filters
| |-- 5x5卷积: 160 filters
| |-- 3x3卷积: 256 filters
| |-- 最大池化: 3x3, stride=1
|
|-- 全连接层
|-- 展平层
|-- Dropout层 (可选)
|-- Dense层: 输出节点数根据任务而定
核心是block模块的重复,类似电影《盗梦空间》那样,一层一层的进入更深的梦境中,同时每一层梦境间也有相互的联系,更深层次的梦境时间和人物属性基于其上一层梦境,醒的条件正常情况也是像递归那样,从深层的梦境开始醒
输入及较浅的网络层:
后续多次调用到这个block
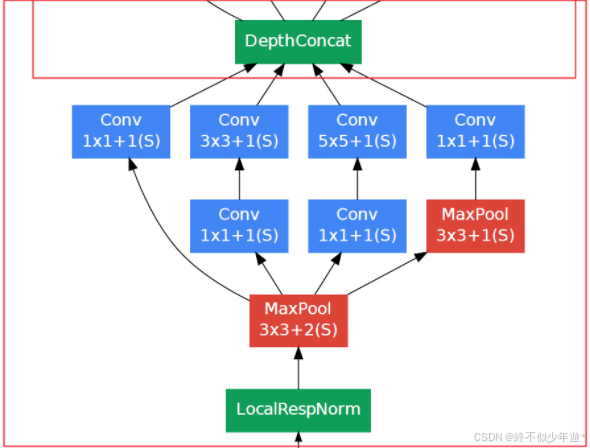
图片引用来源及鸣谢:loveliuzz-CSDN博客
Inception v2
Batch Normalization的应用:为了加速训练过程并解决Internal Covariate Shift问题,Google提出了批规范化(Batch Normalization)。
小卷积核替代大卷积核:将5×5卷积核替换为两个3×3卷积核,既保持了感受野范围又减少了参数量。
Inception v2中很重要的一个点是提到了Batch Normalization
Normalization
常用的 Normalization 方法主要有:Batch Normalization(BN,2015 年)、Layer
Normalization(LN,2016 年)、Instance Normalization(IN,2017 年)、Group
Normalization(GN,2018 年)。它们都是从激活函数的输入来考虑、做文章的,以不同
的方式对激活函数的输入进行 Norm 的。
需要注意的是标准化会改变原数据的期望、方差,即改变了原数据的分布,对于需要保留原数据分布的情况下不适用
我们将输入的 feature map shape 记为[N, C, H, W],其中 N 表示 batch size,即 N
个样本;C 表示通道数;H、W 分别表示特征图的高度、宽度。这几个方法主要的区别就是
在:
1. BN 是在 batch 上,对 N、H、W 做归一化,而保留通道 C 的维度。BN 对较小的batch size 效果不好。BN 适用于固定深度的前向神经网络,如 CNN,不适用于RNN;
2. LN 在通道方向上,对 C、H、W 归一化,主要对 RNN 效果明显;
3. IN 在图像像素上,对 H、W 做归一化,用在风格化迁移;
- GN 将 channel 分组,然后再做归一化。
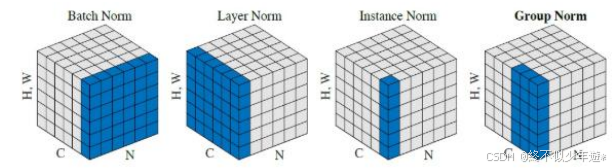
(每个子图表示一个特征图,其中 N 为批量,C 为通道,(H,W)为特征图的高度和宽度。
通过蓝色部分的值来计算均值和方差,从而进行归一化。)
如果把特征图 比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 有 W 个字符。
1. BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第 1 本书第 36 页,第 2本书第 36 页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
2. LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
3. IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每
页书的“平均字”,求标准差时也是同理。
4. GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,求每个小册子的“平均字”和字的“标准差”。
Batch Normalization Layer
后续称Batch Normalization为BN
Batch Normalization 是一种巧妙而粗暴的方法来削弱 bad initialization 的影响,其基本思想是:If you want it, just make it!
我们想要的是在非线性 activation 之前,输出值应该有比较好的分布(例如高斯分布),以便于 back propagation 时计算 gradient,更新 weight。随机初始化,无 Batch Normalization:
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01
......
fc = tf.nn.relu(fc)
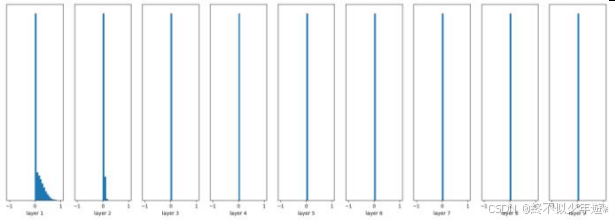
随机初始化,有 Batch Normalization:
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01
......
fc = tf.contrib.layers.batch_norm(fc, center=True, scale=True, \
is_training=True)
fc = tf.nn.relu(fc)
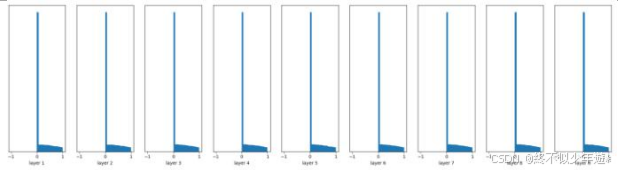
很容易看到,Batch Normalization 的效果非常好
方差越小,提取特征后的浮动也会一定程度的缩小
为什么要进行 BN
(1)在深度神经网络训练的过程中,通常以输入网络的每一个 mini-batch 进行训练,这样每个 batch 具有不同的分布,使模型训练起来特别困难。
(2)Internal Covariate Shift (ICS) 问题:在训练的过程中,激活函数会改变各层数据的
分布,随着网络的加深,这种改变(差异)会越来越大,使模型训练起来特别困难,收敛速度很慢,会出现梯度消失的问题。 (收敛速度很慢 -- 模型训练时迭代的次数会增加 -- 在神经网络中激活函数对于网络层数很深的模型都难以避免梯度消失的问题)
BN 的主要思想
针对每个神经元,使数据在进入激活函数之前,沿着通道计算每个 batch 的均值、方
差,‘强迫’数据保持均值为 0,方差为 1 的正态分布,避免发生梯度消失。具体来说,就
是把第 1 个样本的第 1 个通道,加上第 2 个样本第 1 个通道 ...... 加上第 N 个样本第 1 个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第 1 个通道平均值的数字,而不是一个 H×W 的矩阵)。求通
道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。
BN 的使用位置
全连接层或卷积操作之后,激活函数之前。
BN 算法过程
Batch Normalization 将输出值强行做一次 Gaussian Normalization 和线性变换:Batch Normalization 中所有的操作都是平滑可导,这使得 back propagation 可以有
效运行并学到相应的参数γ,β。需要注意的一点是 Batch Normalization 在 training 和
testing 时行为有所差别。Training 时μB 和σB 由当前 batch 计算得出;在 Testing 时μB
和σB 应使用 Training 时保存的均值或类似的经过处理的值,而不是由当前 batch 计算。
加入缩放和平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特
征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数。
BN 的作用
(1)允许较大的学习率
(2)减弱对初始化的强依赖性
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似 Dropout)
BN 存在的问题
(1)每次是在一个 batch 上计算均值、方差,如果 batch size 太小,则计算的均值、方差
不足以代表整个数据分布。
(2)batch size 太大:会超过内存容量;需要跑更多的 epoch,导致总训练时间变长;会
直接固定梯度下降的方向,导致很难更新。
Inception v3
深度网络设计原则:论文提出了深度网络设计的通用原则,并对Inception结构进行了修改。
卷积分解:通过分解卷积操作,进一步减少了参数量并加深了网络的非线性表达能力。
ResNet

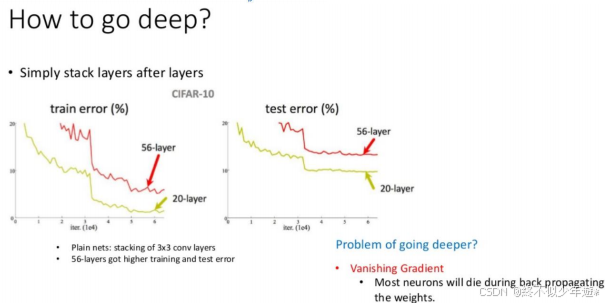
背景与动机
梯度消失问题:随着网络层数的增加,传统的深层神经网络在训练过程中容易出现梯度消失或爆炸的问题,导致模型难以训练。
残差学习:为了解决这一问题,ResNet通过引入残差学习框架,允许网络直接学习输入与输出之间的残差,而不是未参照的目标函数。
核心思想
残差块:ResNet的核心是残差块,它允许网络学习恒等映射,即当输入和输出相同时,网络可以直接学习这种映射关系。
跳跃连接:残差块中的跳跃连接(shortcut connections)使得网络可以直接将输入传递到输出,绕过了一些层,从而缓解了梯度消失问题。
网络结构
基本残差块:由两个卷积层组成,第一个卷积层后接Batch Normalization和ReLU激活函数,第二个卷积层后同样接Batch Normalization。跳跃连接绕过这两个卷积层,将输入直接加到第二个卷积层的输出上。
瓶颈残差块:在更深的网络中,为了减少参数数量,ResNet使用瓶颈结构,即在3x3卷积层前后各添加一个1x1卷积层来减少和恢复特征图的维度。
变体与改进
ResNet变体:根据网络深度和宽度的不同,ResNet有多种变体,如ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152等。数字表示网络中卷积层和残差块的数量。
改进版本:后续研究在ResNet的基础上进行了多种改进,如DenseNet通过更密集的连接来增强特征传播,ResNeXt则通过分组卷积来提高计算效率。
广泛应用:ResNet由于其出色的性能和易于训练的特点,在图像分类、目标检测、语义分割等多个领域得到了广泛应用。
DenseNet和Word2Vec后续补充