最新LangChain+GLM4开发AI应用程序系列(三):RAG检索增强生成篇
一、前言
上两篇文章分别介绍了LangChain的快速入门和Agent智能体开发。在LLM的实际应用场景中,经常会需要用到特定领域用户的数据,但这些数据不属于模型训练集的一部分,要实现这一需求,最好的方法是通过检索增强生成(RAG)。在用户提问时,先检索特定的外部数据,把检索结果作为上下文传递给LLM,以便大模型返回更精准的结果。今天我们就带大家了解下在LangChain里RAG的使用,结合智谱AI GLM4大模型开发一个基于特定知识库的智能问答应用。
二、RAG介绍
LangChain中提供了RAG应用程序的所有构建模块。结构图如下:
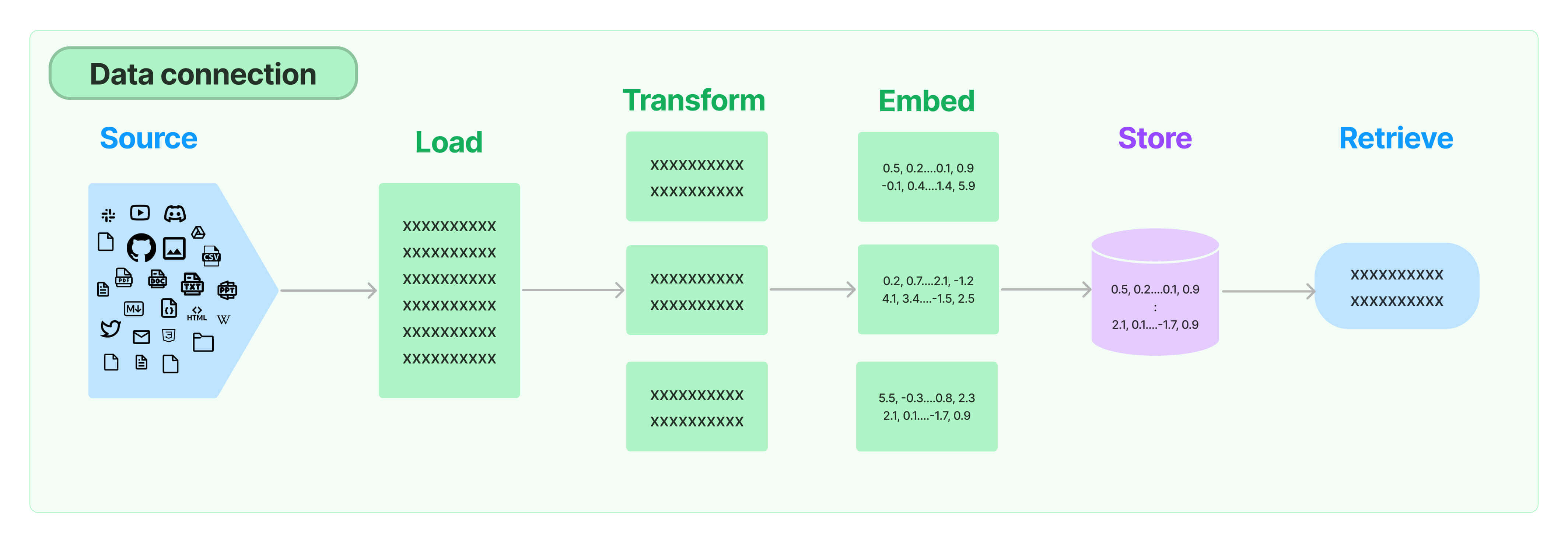
1、文档加载器
文档加载器用来加载各种不同类型的文档。LangChain提供了100 多种不同的文档加载器,可以加载各种类型文档,包括:CSV、HTML、JSON、Markdown、PDF、DOC、XLS、图片、视频、音频等等。具体的文档加载器参考:https://python.langchain.com/docs/integrations/document_loaders/
2、文本分割器
加载文档后,对于长文档,需要分割成更小的块,以适合LLM的上下文窗口。LangChain 有许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。
LangChain 提供了多种不同类型的文本分割器。下表列出了所有这些以及一些特征:
类型:文本分割器的类型
分割依据:此文本拆分器如何拆分文本
添加元数据:此文本拆分器是否添加有关每个块来自何处的元数据。
描述:分离器的描述,包括有关何时使用它的建议。
| 类型 | 分割依据 | 添加元数据 | 描述 |
|---|---|---|---|
| Recursive | 用户定义的字符列表 | 递归地分割文本。递归地分割文本的目的是尝试使相关的文本片段彼此相邻。这是开始分割文本的推荐方法。 | |
| HTML | HTML 特定字符 | ✅ | 根据 HTML 特定字符分割文本。值得注意的是,这添加了有关该块来自何处的相关信息(基于 HTML) |
| Markdown | Markdown 特定字符 | ✅ | 根据 Markdown 特定字符分割文本。值得注意的是,这添加了有关该块来自何处的相关信息(基于 Markdown) |
| Code | 代码(Python、JS)特定字符 | 根据特定于编码语言的字符分割文本。有 15 种不同的语言可供选择。 | |
| Token | Tokens | 基于tokens分割文本。有几种不同的方法来衡量tokens. | |
| Character | 用户定义的字符 | 根据用户定义的字符分割文本。比较简单的方法之一。 | |
| [Experimental] Semantic Chunker | 句子 | 首先对句子进行分割。然后,如果它们在语义上足够相似,则将它们相邻地组合起来。 |
3、嵌入模型
嵌入(Embedding)是一种将单词、短语或整个文档转换为密集向量的技术。每个单词或短语被转换成一组数字,这组数字捕捉了该文本的某些语义特征。
嵌入模型通过将文本转换为计算机可以处理的数值形式(即向量),使得计算机能够理解和处理自然语言。通过嵌入捕获文本的语义,可以快速有效地找到文本的其他相似部分。
LangChain提供了超过25种不同嵌入提供商和方法的集成,可以参考:https://python.langchain.com/docs/integrations/text_embedding
抱脸上有个中文、英文嵌入模型排行榜,可以作为参考,具体还要选适合自己的,比如开源的,对中文支持比较好的等等:https://huggingface.co/spaces/mteb/leaderboard
4、向量数据库
有了嵌入模型对数据的向量化,就需要数据库来支持这些嵌入数据的高效存储和搜索。LangChain提供了50多种不同向量数据库的集成,可以参考:https://python.langchain.com/docs/integrations/vectorstores
目前Milvus评分最高。
三、RAG开发案例
接下来我们实战开发一个基于特定知识库的智能问答应用。还是在Jupyter Notebook环境中执行。
1、创建智谱GLM4大模型对象
首先定义LangChain里智谱大模型的包装类,参考第一篇文章里有,或者从github上下载:https://github.com/taoxibj/docs/blob/main/zhipuai.py
创建大模型对象
# 填写您自己的APIKey
ZHIPUAI_API_KEY = "..."
llm = ChatZhipuAI(
temperature=0.1,
api_key=ZHIPUAI_API_KEY,
model_name="glm-4",
)
2、加载文档
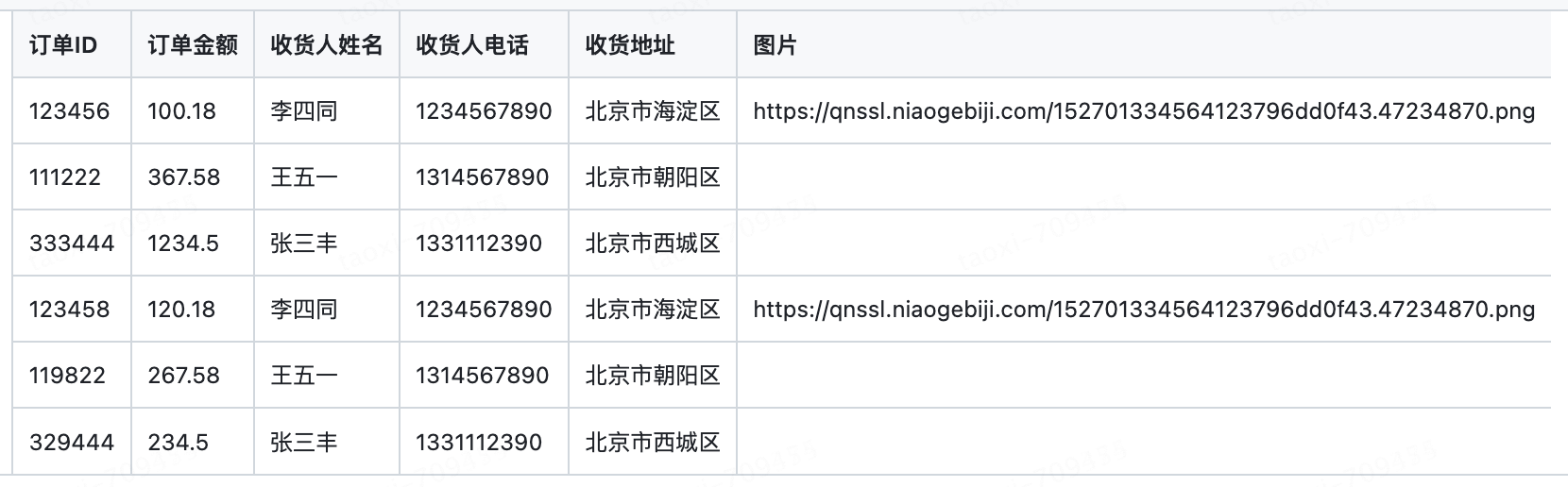
这里特定领域用户的数据来源于一个示例的ordersample.csv文件,这个文件可以从我的github上获取:https://github.com/taoxibj/docs/blob/main/ordersample.csv
文件具体内容如下:
把orersample.csv下载到jupyter notebook当前ipynb文件目录,使用CSV文档加载器,加载文档内容:
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='ordersample.csv')
data = loader.load()
打印加载后的文档内容:
from pprint import pprint
pprint(data)
按一行一个文档,分成了6个文档。
[Document(page_content='\ufeff订单ID: 123456\n订单金额: 100.18\n收货人姓名: 李四同\n收货人电话: 1234567890\n收货地址: 北京市海淀区\n图片: https://qnssl.niaogebiji.com/152701334564123796dd0f43.47234870.png', metadata={'source': 'ordersample.csv', 'row': 0}),
Document(page_content='\ufeff订单ID: 111222\n订单金额: 367.58\n收货人姓名: 王五一\n收货人电话: 1314567890\n收货地址: 北京市朝阳区\n图片: ', metadata={'source': 'ordersample.csv', 'row': 1}),
Document(page_content='\ufeff订单ID: 333444\n订单金额: 1234.5\n收货人姓名: 张三丰\n收货人电话: 1331112390\n收货地址: 北京市西城区\n图片: ', metadata={'source': 'ordersample.csv', 'row': 2}),
Document(page_content='\ufeff订单ID: 123458\n订单金额: 120.18\n收货人姓名: 李四同\n收货人电话: 1234567890\n收货地址: 北京市海淀区\n图片: https://qnssl.niaogebiji.com/152701334564123796dd0f43.47234870.png', metadata={'source': 'ordersample.csv', 'row': 3}),
Document(page_content='\ufeff订单ID: 119822\n订单金额: 267.58\n收货人姓名: 王五一\n收货人电话: 1314567890\n收货地址: 北京市朝阳区\n图片: ', metadata={'source': 'ordersample.csv', 'row': 4}),
Document(page_content='\ufeff订单ID: 329444\n订单金额: 234.5\n收货人姓名: 张三丰\n收货人电话: 1331112390\n收货地址: 北京市西城区\n图片: ', metadata={'source': 'ordersample.csv', 'row': 5})]
3、文本分割
通常可以使用递归字符文本分割器对文档对象进行分割,可以设置分割块字符的大小,和重合字符大小。因为我的文档对象比较小,所以每个文档基本上没有达到要切分的大小阈值,可以尝试把文档内容变多,试下效果。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(data)
可以打印一下分割后块的数量。
len(all_splits)
6
4、向量化存储
接下来我们首先使用嵌入模型对分割后的文档进行向量化,然后存储到向量数据库中。
嵌入模型使用的是bge-large-zh-v1.5,这是BAAI北京智源人工智能研究院开源的,支持中、英文的嵌入模型,在开源嵌入模型中算是效果比较好的一个。
向量数据库使用的是FAISS,是FAIR(Meta人工智能实验室)开源的向量数据库。可以在本地使用,相对轻量些,没有Milvus那么强, 但在本地环境使用也够用了。
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-zh-v1.5"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
bgeEmbeddings = HuggingFaceBgeEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)
from langchain_community.vectorstores import FAISS
vector = FAISS.from_documents(all_splits, bgeEmbeddings)
5、向量库检索
接下来尝试下使用向量库进行检索。
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
retriever.invoke("收货人姓名是张三丰的,有几个订单?金额分别是多少,总共是多少?")
检索结果如下。
[Document(page_content='\ufeff订单ID: 329444\n订单金额: 234.5\n收货人姓名: 张三丰\n收货人电话: 1331112390\n收货地址: 北京市西城区\n图片:', metadata={'source': 'ordersample.csv', 'row': 5, 'start_index': 0}),
Document(page_content='\ufeff订单ID: 333444\n订单金额: 1234.5\n收货人姓名: 张三丰\n收货人电话: 1331112390\n收货地址: 北京市西城区\n图片:', metadata={'source': 'ordersample.csv', 'row': 2, 'start_index': 0}),
Document(page_content='\ufeff订单ID: 123456\n订单金额: 100.18\n收货人姓名: 李四同\n收货人电话: 1234567890\n收货地址: 北京市海淀区\n图片: https://qnssl.niaogebiji.com/152701334564123796dd0f43.47234870.png', metadata={'source': 'ordersample.csv', 'row': 0, 'start_index': 0})]
6、生成问答结果
使用检索链,串联向量库检索和大模型,根据用户的提问,生成问答结果。
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""仅根据所提供的上下文回答以下问题:
<context>
{context}
</context>
问题: {question}""")
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
retriever_chain = (
{"context": retriever , "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
可以开始进行提问。
提问一:
retriever_chain.invoke("订单ID是123456的收货人是谁,电话是多少?")
回答:
'根据所提供的上下文,订单ID为123456的收货人是李四同,电话是1234567890。'
提问二:
retriever_chain.invoke("收货人张三丰有几个订单?金额分别是多少,总共是多少?")
回答:
'收货人张三丰有两个订单。第一个订单的订单ID是329444,金额是234.5元;第二个订单的订单ID是333444,金额是1234.5元。这两个订单的总金额是1469元。'
提问三:
retriever_chain.invoke("收货地址是朝阳区的有哪些订单?")
回答:
'收货地址是朝阳区的订单有:\n\n1. 订单ID: 119822,订单金额: 267.58,收货人姓名: 王五一,收货人电话: 1314567890,收货地址: 北京市朝阳区。\n2. 订单ID: 111222,订单金额: 367.58,收货人姓名: 王五一,收货人电话: 1314567890,收货地址: 北京市朝阳区。\n\n以上两个订单的收货地址均为北京市朝阳区。'
整体的回答结果还算准确。但是也有一些情况,回答的不对的,基本上是向量库检索出的答案有出入造成的问题,所以语料知识的向量化和结构化,还是很重要的。
四、总结
这篇文章首先介绍了在LangChain中使用RAG的重要组成部分,包括文档加载器、文本分割器、嵌入模型、向量数据库,然后通过一个示例演示了LLM如何通过RAG检索增强生成的方式,借助特定领域用户数据,更准确的回答用户的提问。
对于RAG来说,语料的结构化是很重要的,后面也会深入分析一些文档材料如DOC、XLS、PDF的结构化以及如何更好的进行切分来获取更精准的答案。敬请期待。