stream一旦被终止操作后不能再使用,因为已经关闭,除非创建新的stream。
一、四种创建Stream方式
1. Collection 提供了两个方法 stream() 与 parallelStream()
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream();//获取一个顺序流
Stream<String> stringStream = list.parallelStream(); //获取一个并行流
2. 通过 Arrays 中的 stream() 获取一个数组流
Integer[] nums = new Integer[0];
Stream<Integer> stream1 = Arrays.stream(nums);
3. 通过 Stream 类中静态方法 of()
Stream<String> stream2 = Stream.of("a", "b", "c");
4. 创建无限流
4.1 迭代
可以通过迭代器获取遍历集合的下标数
Stream<Integer> iterate = Stream.iterate(0, (x) -> x + 1);
iterate.limit(11).forEach(System.out::println);
List<String> list= Arrays.asList("a", "b", "c", "d", "e");
String s = Stream.iterate(0,x->x+1).limit(list.size()).map(i -> StrUtil.concat(true, "{", StrUtil.toString(i), "}")).collect(Collectors.joining(","));
System.out.println(s);
{0},{1},{2},{3},{4}
4.2 生成
Stream<Double> generate = Stream.generate(Math::random);
generate.limit(10).forEach(System.out::println);
二、常用的API
中间操作
筛选与切片
filter——接收 Lambda , 从流中排除某些元素。
limit——截断流,使其元素不超过给定数量。
skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
distinct——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
peek 跟forEach类似,主要返回的事流,用于调式或者中间处理,不常用,常用在debug模式调式用。与map类似,peek有没有返回值,map有返回值,peek用Consumer作为参数,map是用Function作为参数。
filter:过滤条件
@Test
public void test01() {
Stream<Employee> stream = emps.stream()
.filter((e) -> e.getAge() > 35);
stream.forEach(System.out::println);
System.out.println(emps.size());
}
limit:获取查询数据的前几个,会短路
//limit
@Test
public void test03() {
emps.stream()
.filter(e->e.getAge()>30)
.limit(2)
.forEach(System.out::println);
}
}
skip:去除了前n个元素
@Test
public void test04() {
emps.stream()
.filter(e->e.getAge()>30)
.skip(1)
.forEach(System.out::println);
}
distinct:去除重复
@Test
public void test05() {
emps.stream()
.distinct()
.forEach(System.out::println);
}
peek:
Stream<Person> persons = Stream.of(a, b, c);
persons.peek(person -> person.setName(person.getName().toUpperCase()))
.forEach(System.out::println);
}
映射
map——接收 Lambda , 将元素转换成其他形式或提取信息。接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
map:
//map
@Test
public void test06() {
List<String> list = Arrays.asList("aaa","bbb","ccc","ddd");
list.stream()
.map(str -> str.toUpperCase())
.forEach(System.out::println);
emps.stream()
.map(item -> item.getName())
.forEach(System.out::println);
System.out.println("-------------------------");
Stream<Stream<Character>> stream = list.stream()
.map(item-> this.filterCharacter(item));
stream.forEach(item->{
item.forEach(System.out::println);
});
}
flatMap
@Test
public void test07() {
//类似集合中add和addAll
//add是将整个集合加入 ,addALl是将集合每个元素加入
List<String> list = Arrays.asList("aaa","bbb","ccc","ddd");
list.stream()
.flatMap(item->this.filterCharacter(item))
.forEach(System.out::println);
}
public Stream<Character> filterCharacter(String str) {
List<Character> charList = new ArrayList<>();
char[] list = str.toCharArray();
for(Character c : list) {
charList.add(c);
}
return charList.stream();
}
sorted()——自然排序
sorted(Comparator com)——定制排序
comparing( Function<? super T, ? extends U> keyExtractor): 这种是比较器
// 第一个参数是比较器,第二个参数就是比较key,比如想要用升序还是降序之类的可以单独处理或者用reversed都可以达到效果
comparing( Function<? super T, ? extends U> keyExtractor, Comparator<? super U> keyComparator)
另外如果需求变成如下,按照姓名顺序->年龄倒序->积分顺序的次序来排序,Java8也十分容易,comparing比较器提供了重载方法,可以自定义某条属性的排序,例子如下
.sorted(Comparator.comparing((FibereProjectExportResponse project) -> StrUtil.isNotBlank(project.getUpdateTime()) ? DateUtil.parse(project.getUpdateTime(), DatePattern.NORM_DATETIME_PATTERN) : null, Comparator.nullsFirst(DateTime::compareTo)).reversed())
@Test
public void traditionCombinationCompareInJava8(){
users.sort(comparing(User::getName)
.thenComparing(User::getAge, (o1, o2) -> o2 - o1)
.thenComparing(User::getCredits));
}
sorted:
直接sorted排序要求被排序的对象重写equals和hashcode方法

@Test
public void test09() {
emps.stream()
.map(e-> e.getName())
.sorted()
.forEach(System.out::println);
System.out.println("------------------------");
emps.stream()
.sorted((x,y) -> {
if(x.getAge() == (y.getAge())) {
return x.getName().compareTo(y.getName());
}else {
return Integer.compare(x.getAge(),y.getAge());
}
}).forEach(System.out::println);
System.out.println("-------------------");
// 还可以通过方法引用进一步的简化,这里使用Comparator下的comparingInt进行排序,使用User::getAge获得年龄,默认从小到大正向排序
//按照年龄从小到大排序
emps.stream()
.sorted(Comparator.comparingInt(Employee::getAge))
.forEach(System.out::println);
System.out.println("-------------------");
//按照年龄从大到小排序
emps.stream()
.sorted(Comparator.comparingInt(Employee::getAge).reversed())
.forEach(System.out::println);
//在这里我们使用比较器的thenComparing实现链式调用
System.out.println("******************");
// 按照姓名,年龄顺序依次排序,也就是多条件组合排序
emps.stream()
.sorted(Comparator.comparing(Employee::getName).thenComparing(Employee::getAge))
.forEach(System.out::println);
System.out.println("******************");
emps.stream()
.sorted(Comparator.comparing(Employee::getName)
.thenComparing(Comparator.comparing(Employee::getAge).reversed()))
.forEach(System.out::println);
}
终止操作
allMatch——检查是否匹配所有元素
anyMatch——检查是否至少匹配一个元素
noneMatch——检查是否没有匹配的元素
findFirst——返回第一个元素
findAny——返回当前流中的任意元素
count——返回流中元素的总个数
max——返回流中最大值
min——返回流中最小值
foreach-- 遍历: 循环中使用return相当于普通循环中的continue效果一样
归约
reduce(T identity, BinaryOperator) / reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。
collect——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
@Test
public void test10(){
//allMatch——检查是否匹配所有元素
boolean b = empList.stream()
.allMatch(item -> item.getStatus().equals(Employee.Status.BUSY));
System.out.println(b);
// anyMatch——检查是否至少匹配一个元素
boolean b1 = empList.stream()
.anyMatch(e -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b1);
// noneMatch——检查是否没有匹配的元素
boolean b2 = empList.stream()
.noneMatch(e -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b2);
// findFirst——返回第一个元素
Optional<Employee> first = empList.stream().findFirst();
Employee employee = first.get();
System.out.println(employee);
// findAny——返回当前流中的任意元素
Employee employee1 = empList.parallelStream()
.findAny()
.orElse(null);
System.out.println(employee1);
// count——返回流中元素的总个数
long count = empList.stream()
.count();
System.out.println(count);
// max——返回流中最大值
Employee employee2 = empList.stream()
.max(Comparator.comparingDouble(Employee::getSalary)).orElse(null);
System.out.println(employee2);
// min——返回流中最小值
Employee employee3 = empList.stream()
.min(Comparator.comparingDouble(Employee::getSalary)).orElse(null);
System.out.println(employee3);
}
reduce
@Test
public void test12() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer reduce = list.stream()
.reduce(0, (x, y) -> x + y);
System.out.println(reduce);
/*********************************/
Optional<Double> reduce1 = empList.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println("工资总和:"+reduce1);
}
collect
可以分组分区,join类似sql操作
@Test
public void test13() {
List<String> list = empList.stream()
.map(Employee::getName)
.collect(Collectors.toList());
System.out.println(list);
Set<String> collect = empList.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
collect.forEach(System.out::print);
System.out.println("-----------------------------------");
HashSet<String> collect1 = empList.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
System.out.println(collect1);
}
@Test
public void test14() {
//总数
Long collect = empList.stream()
.collect(Collectors.counting());
System.out.println(collect);
//平均工资
Double collect1 = empList.stream()
.collect(Collectors.averagingDouble(Employee::getSalary));
System.out.println(collect1);
//工资共和
Double collect2 = empList.stream()
.collect(Collectors.summingDouble(Employee::getSalary));
System.out.println(collect2);
//最大值
Optional<Employee> collect3 = empList.stream()
.collect(Collectors.maxBy((x, y) -> Double.compare(x.getSalary(), y.getSalary())));
System.out.println(collect3.get());
//最小值
Optional<Double> collect4 = empList.stream()
.map(Employee::getSalary)
.collect(Collectors.minBy(Double::compare));
System.out.println(collect4.get());
}
//分组
@Test
public void test15() {
//按照状态分组
Map<Employee.Status, List<Employee>> collect = empList.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(collect);
}
//多级分组
@Test
public void test16() {
Map<Employee.Status, Map<String, List<Employee>>> collect = empList.stream()
.collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e1) -> {
if (((Employee) e1).getAge() <= 30) {
return "青年";
} else if (((Employee) e1).getAge() < 50) {
return "中年";
} else {
return "老年";
}
})));
}
//分区 满足条件一个区,不满足条件一个区 可以多级分区
@Test
public void test17() {
Map<Boolean, List<Employee>> collect = empList.stream()
.collect(Collectors.partitioningBy((e) -> e.getSalary() > 5000));
System.out.println(collect);
// {false=[Employee [id=103, name=王五, age=28, salary=3333.33, status=VOCATION]],
// true=[Employee [id=102, name=李四, age=79, salary=6666.66, status=BUSY], Employee [id=101, name=张三, age=18, salary=9999.99, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=BUSY], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE], Employee [id=105, name=田七, age=38, salary=5555.55, status=BUSY]]}
}
@Test
public void test18() {
//聚合函数用法: eg : 求工资的最高值,最低值,总和,平均值
DoubleSummaryStatistics collect = empList.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
double average = collect.getAverage();
double max = collect.getMax();
double sum = collect.getSum();
System.out.println(average);
System.out.println(max);
System.out.println(sum);
}
@Test
public void test19() {
String collect = empList.stream()
.map(Employee::getName)
.collect(Collectors.joining());
System.out.println(collect);
//join 添加连接符
String collec1t = empList.stream()
.map(Employee::getName)
.collect(Collectors.joining(","));
System.out.println(collec1t);
//添加前缀和后缀
String collect2 = empList.stream()
.map(Employee::getName)
.collect(Collectors.joining(",","****","----"));
System.out.println(collect2);
}
去重数据
List<String> collect = list.stream().collect(Collectors.groupingBy(t -> t.getProjectNo() + "^" + t.getContractNo(), Collectors.counting()))
.entrySet()
.stream()
.filter(entry -> entry.getValue() > 1)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
过滤去重先用collectingAndThen 返回treeSet,然后再二次加工处理排序返回,将空的放在最后。
- Comparator.nullsLast(DateTime::compareTo)
- Collectors.collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher)
projectLists = fiberProjectListList.stream()
.filter(fiberProjectList -> fiberProjectList.getSaleAttrId() != null && fiberProjectList.getSaleAttrId().compareTo(item.getSaleAttrId()) == 0)
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(FiberProjectList::getRid))),
k -> k.stream()
.sorted(Comparator.comparing(p -> StrUtil.isNotBlank(p.getUpdateTime()) ?
DateUtil.parse(p.getUpdateTime(), DatePattern.NORM_DATETIME_PATTERN) :
null,
Comparator.nullsLast(DateTime::compareTo)))
.collect(Collectors.toList())));
toMap
## Collectors.toMap 有三个重载方法:
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper);
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction);
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier);
参数含义分别是:
keyMapper:Key 的映射函数
valueMapper:Value 的映射函数
mergeFunction:当 Key 冲突时,调用的合并方法
mapSupplier:Map 构造器,在需要返回特定的 Map 时使用
collectingAndThen
此方法是在进行归纳动作结束之后,对归纳的结果进行二次处理。
//对集合的结果进行去重
List<User> list = userList.stream()
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getUserId))), ArrayList::new));
System.out.println(list);
List<PrintBiddingInquiryRequest> arrayList = list.stream().
collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(o -> o.getReviewBatch() + ";" + o.getReviewSerial()))), ArrayList::new));
arrayList.forEach(System.out::println);
//查找工资最高的员工的姓名
String userName = userList.stream()
.collect(Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparing(User::getSalary)),(Optional<User> user) -> user.map(User::getUserName).orElse(null)));
System.out.println(userName);
groupingBy
先根据id分组,在根据age分组,最后根据分数分组
Map<Integer, Map<Integer, Map<Integer, List<Apple>>>> collect = appleList.stream().collect(Collectors.groupingBy(Apple::getId, Collectors.groupingBy(Apple::getAge, Collectors.groupingBy(Apple::getStore))));
System.out.println(collect);
结果

List<Apple> appleList = Arrays.asList(
new Apple(1, 22, 88),
new Apple(1, 21, 88),
new Apple(1, 22, 80),
new Apple(1, 21, 89),
new Apple(1, 23, 87),
new Apple(1, 23, 87),
new Apple(2, 22, 87),
new Apple(2, 23, 87),
new Apple(2, 24, 87),
new Apple(2, 22, 88),
new Apple(2, 23, 89),
new Apple(2, 24, 86));
Map<Integer, Apple> appleMap = appleList.stream().collect(Collectors.toMap(Apple::getId, a -> a, (k1, k2) -> k1));
System.out.println(appleMap);
List<Map<String, Object>> arrayList = appleList.stream().collect(ArrayList::new, (list, p) -> {
Map<String, Object> map = new HashMap<>();
map.put("id", p.getId());
map.put("age", p.getAge());
list.add(map);
}, List::addAll);
System.out.println(arrayList);
System.out.println();
Map<Integer, Map<Integer, Map<Integer, List<Apple>>>> collect = appleList.stream().collect(Collectors.groupingBy(Apple::getId, Collectors.groupingBy(Apple::getAge, Collectors.groupingBy(Apple::getStore))));
System.out.println(collect);
HashMap<Integer, Long> hashMap = appleList.stream().collect(Collectors.groupingBy(Apple::getId, HashMap::new, Collectors.counting()));
System.out.println(hashMap);
结果
{1=LambdaTest.Apple(id=1, age=22, store=88), 2=LambdaTest.Apple(id=2, age=22, store=87)}
[{id=1, age=22}, {id=1, age=21}, {id=1, age=22}, {id=1, age=21}, {id=1, age=23}, {id=1, age=23}, {id=2, age=22}, {id=2, age=23}, {id=2, age=24}, {id=2, age=22}, {id=2, age=23}, {id=2, age=24}]
{1={21={88=[LambdaTest.Apple(id=1, age=21, store=88)], 89=[LambdaTest.Apple(id=1, age=21, store=89)]}, 22={80=[LambdaTest.Apple(id=1, age=22, store=80)], 88=[LambdaTest.Apple(id=1, age=22, store=88)]}, 23={87=[LambdaTest.Apple(id=1, age=23, store=87), LambdaTest.Apple(id=1, age=23, store=87)]}}, 2={22={87=[LambdaTest.Apple(id=2, age=22, store=87)], 88=[LambdaTest.Apple(id=2, age=22, store=88)]}, 23={87=[LambdaTest.Apple(id=2, age=23, store=87)], 89=[LambdaTest.Apple(id=2, age=23, store=89)]}, 24={86=[LambdaTest.Apple(id=2, age=24, store=86)], 87=[LambdaTest.Apple(id=2, age=24, store=87)]}}}
{1=6, 2=6}
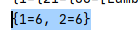
Set<Map.Entry<String, List<ReviewPlanFormData>>> set =
pt.stream()
.sorted(Comparator.comparing(ReviewPlanFormData::getReviewSerial))
.collect(Collectors.groupingBy(ReviewPlanFormData::getReviewBatch, ()->new TreeMap<>(Comparator.comparing(a->a)), Collectors.toList())).entrySet();
if
Collectors.mapping()
@Data
static class UserRoleResp{
public UserRoleResp(Integer userId, String roleName) {
this.userId = userId;
this.roleName = roleName;
}
private Integer userId;
private String roleName;
}
@Data
static class UserRoleVo {
public UserRoleVo(Integer userId, List<String> roleNameList) {
this.userId = userId;
this.roleNameList = roleNameList;
}
private Integer userId;
private List<String> roleNameList;
}
@Test
public void test4() {
List<UserRoleResp> userRoleRespList = new ArrayList<>();
userRoleRespList.add(new UserRoleResp(1, "质检"));
userRoleRespList.add(new UserRoleResp(1, "开发"));
userRoleRespList.add(new UserRoleResp(1, "测试"));
userRoleRespList.add(new UserRoleResp(1, "项目经理"));
userRoleRespList.add(new UserRoleResp(2, "班主任"));
userRoleRespList.add(new UserRoleResp(2, "司机"));
userRoleRespList.add(new UserRoleResp(2, "修理工"));
userRoleRespList.add(new UserRoleResp(2, "销售"));
userRoleRespList.add(new UserRoleResp(2, "广告"));
List<UserRoleVo> collect = userRoleRespList.stream().collect(Collectors.collectingAndThen(Collectors.groupingBy(UserRoleResp::getUserId, Collectors.mapping(UserRoleResp::getRoleName, Collectors.toList())), map -> map.entrySet().stream().map(en -> new UserRoleVo(en.getKey(), en.getValue())).collect(Collectors.toList())));
System.out.println(collect);
}
三、Optional 容器类
Optional.of(T t) : 创建一个 Optional 实例
Optional.empty() : 创建一个空的 Optional 实例
Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则创建空实例
isPresent() : 判断是否包含值
orElse(T t) : 如果调用对象包含值,返回该值,否则返回t
orElseGet(Supplier s) :如果调用对象包含值,返回该值,否则返回 s 获取的值
map(Function f): 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty()
flatMap(Function mapper):与 map 类似,要求返回值必须是Optional
例子:
//创建Optional of不能传入null
@Test
public void test01() {
Optional<Employee> employee = Optional.of(new Employee());
System.out.println(employee.get());//Employee [id=0, name=null, age=0, salary=0.0, status=null]
}
// empty 创建空的对象
@Test
public void test02() {
Optional<Object> empty = Optional.empty();
System.out.println(empty.get());//java.util.NoSuchElementException: No value present
}
// ofNullable 既可以创建对象也可以创建空的
@Test
public void test03() {
Optional<Employee> employee = Optional.ofNullable(new Employee());
System.out.println(employee.get());//Employee [id=0, name=null, age=0, salary=0.0, status=null]
Optional<Object> o = Optional.ofNullable(null);
System.out.println(o.get());//java.util.NoSuchElementException: No value present
}
// isPresent() : 判断是否包含值 是否为null
@Test
public void test04() {
Optional<Employee> optional = Optional.ofNullable(new Employee());
if(!optional.isPresent()) {
Employee employee1 = optional.get();
System.out.println(employee1);
}else {
System.out.println("没有值");
}
}
// orElse
@Test
public void test05() {
Optional<Employee> optional = Optional.ofNullable(null);
System.out.println("9999999999999999999999");
//如果 optional 中为null那么就有个默认值,如果是空的或者有值就不走orElse
Employee employee = optional.orElse(new Employee("臧三", 33));
System.out.println(employee);
}
// orElseGet
@Test
public void test06() {
Optional<Employee> optional = Optional.ofNullable(null);
Employee employee = optional.orElseGet(Employee::new);
System.out.println(employee);
}
// map(Function f): 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty()
@Test
public void test07() {
Optional<Employee> optional = Optional.ofNullable(new Employee("臧三", 33));
Optional<String> s = optional.map(e -> e.getName());
System.out.println(s.get());
}
// * flatMap(Function mapper):与 map 类似,
// 要求返回值必须是Optional
@Test
public void test08() {
Optional<Employee> optional = Optional.ofNullable(new Employee("臧三", 33));
Optional<String> s = optional.flatMap(e -> {
return Optional.of(e.getName());
});
System.out.println(s.get());
}
//避免空指针异常
@Test
public void test09() {
Optional<NewMan> o = Optional.ofNullable(null);
String godnessName = getGodnessName(o);
System.out.println(godnessName);
}
public String getGodnessName(Optional<NewMan> man) {
return man.orElse(new NewMan())
.getGodness()
.orElse(new Godness("藏"
)).getName();
}
四、java8接口默认方法和静态方法
Java 8中允许接口中包含具有具体实现的方法,该方法称为
“默认方法”,默认方法使用 default 关键字修饰。
interface MyFun<T> {
T fun(int a) ;
default String getName() {
return "hello java8";
}
static void method1() {
System.out.println("我是一个静态方法");
}
}
接口默认方法的”类优先”原则
若一个接口中定义了一个默认方法,而另外一个父类或接口中
又定义了一个同名的方法时
** 1选择父类中的方法。如果一个父类提供了具体的实现,那么
接口中具有相同名称和参数的默认方法会被忽略。
**2 接口冲突。如果一个父接口提供一个默认方法,而另一个接
口也提供了一个具有相同名称和参数列表的方法(不管方法
是否是默认方法),那么必须覆盖该方法来解决冲突