学习完PointNet,当然要学习PointNet++了。
1、简介
PointNet++是pointnet的升级版本,在pointnet中,是将所有点的特征聚合到点云的全局特征中,但是,并没有捕获点间关系的特征。pointnet++就是来解决这个问题。捕获点间关系的特征,聚合到点云的全局特征中。论文地址
2、网络结构
在网络结构之前,要先好好看下pointnet++是怎么捕获局部特征的,pointnet++捕获局部特征分为三个部分,采样层,分组层跟一个迷你的pointnet层。
采样层:用FPS采样,先随机选一个点,选择离这个点距离最远的点加入点集,继续迭代,直到选出需要的个数为止。
分组层:采用Ball query分组算法,给定一个点,把这个点周围一定半径的点囊括进来,预先设置给定半径内点的个数上限k。
迷你pointnet层:用pointnet提取这个小分组里面点的特征,聚合成这片分组的点云的全局特征,以这小片点云的全局特征作为整片点云的局部特征。
部分点云中存在稀疏问题,比如车载激光雷达产生的点云,距离激光雷达的距离比较近的点云比较密集,距离激光雷达距离远的点云比较稀疏,密集的点云跟稀疏的点云之间的提取到的特征应该会存在差异。
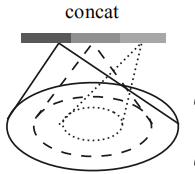
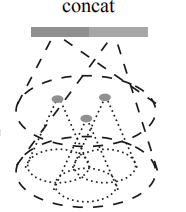
在pointnet++中,运用两种方法解决这个问题,MSG和MRG。
MSG:应用不同尺度的分组层来获取多尺度,不同尺度的特征被连接起来形成一个多尺度的特征。
MRG:由两个向量组成,一个就是抽象层提取的局部特征,另一个用单层的pointnet直接处理原始数据得到特征,在点云密集时候左边的向量更可靠一些,在点云稀疏时候,右边的向量更可靠一些。
具体的详细网络结构,论文中并没有给出,只有看代码时候自己看了。。。
3、代码学习
同样是在github上找大佬们的代码进行学习,依然准备用pytorch框架,大佬链接。
这位大佬用的训练数据集是ModelNet的数据集,刚去看了下,有1.6个G。准备把代码改改,还是继续用shapenet的数据集,一是已经下了一个数据集了,二是也便于和pointnet有个比较直观的比较。

看这运行比较简单,直接运行train_cls.py就没了。
from data_utils.ModelNetDataLoader import ModelNetDataLoader
import argparse
import numpy as np
import os
import torch
import datetime
import logging
from pathlib import Path
from tqdm import tqdm
import sys
import provider
import importlib
import shutil
引入库,有两个本地库,from data_utils.ModelNetDataLoader import ModelNetDataLoader,刚好看到data_utils中有个ShapeNetDataLoader.py的文件,改成from data_utils.ShapeNetDataLoader import PartNormalDataset,还有一个import provider。先继续往下看吧,遇到本地库时候再去看本地库,感觉这样可能更容易理解一点。
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))
提取当前目录到BASE_DIR中,把models的目录临时添加到sys.path中,在jupyter中,把__file__用单引号引起来。
接下来是设置超参数。
def parse_args():
'''PARAMETERS'''
parser = argparse.ArgumentParser('PointNet')
parser.add_argument('--batch_size', type=int, default=24, help='batch size in training [default: 24]')
parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')
parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training [default: 200]')
parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training [default: 0.001]')
parser.add_argument('--gpu', type=str, default='0', help='specify gpu device [default: 0]')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number [default: 1024]')
parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training [default: Adam]')
parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate [default: 1e-4]')
parser.add_argument('--normal', action='store_true', default=False, help='Whether to use normal information [default: False]')
return parser.parse_args()
在jupyter中,把最后一行的return parser.parse_args()改成return parser.parse_args([])
接下来是主函数,但是主函数有点多,分为几块吧,一块一块说。需要传入的参数就是parse_args()函数生成的超参数。
这一个很小很小的函数,只是为了把str输入到logger中,把str打印出来。
def log_string(str):
logger.info(str)
print(str)
选用args.gpu中的gpu来训练。默认的是用0gpu,多gpu的可以改下,其他跟我一样就一块gpu的就不用管这个事情。
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
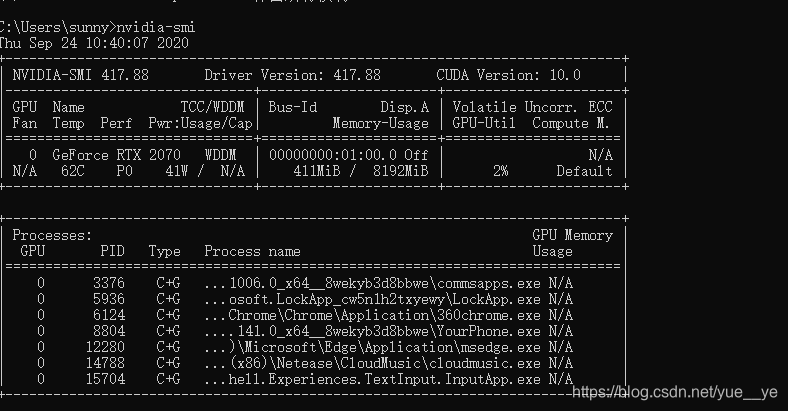
用win+r,cmd,输入nvidia-smi就能查看gpu信息。
接下来创建目录。timestr获取当前时间,在当前目录下创建一个名为log的文件夹,再在文件夹log下创建一个名为part_seg的文件夹,再在part_seg文件夹下创建一个timestr文件夹或者是我们自己定义名字的文件夹,在刚创建的文件夹下再创建一个名为checkpoints的文件夹和一个名为logs的文件夹。。创建了挺多的文件夹的。。
'''CREATE DIR'''
timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
experiment_dir = Path('./log/')
experiment_dir.mkdir(exist_ok=True)
experiment_dir = experiment_dir.joinpath('classification')
experiment_dir.mkdir(exist_ok=True)
if args.log_dir is None:
experiment_dir = experiment_dir.joinpath(timestr)
else:
experiment_dir = experiment_dir.joinpath(args.log_dir)
experiment_dir.mkdir(exist_ok=True)
checkpoints_dir = experiment_dir.joinpath('checkpoints/')
checkpoints_dir.mkdir(exist_ok=True)
log_dir = experiment_dir.joinpath('logs/')
log_dir.mkdir(exist_ok=True)
创建并记录日志
'''LOG'''
args = parse_args()
logger = logging.getLogger("Model")
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
log_string('PARAMETER ...')
log_string(args)
接下来就是加载数据这里面数据目录地址改成自己的数据目录地址。
'''DATA LOADING'''
log_string('Load dataset ...')
DATA_PATH = 'data/modelnet40_normal_resampled/'
TRAIN_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='train',
normal_channel=args.normal)
TEST_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='test',
normal_channel=args.normal)
trainDataLoader = torch.utils.data.DataLoader(TRAIN_DATASET, batch_size=args.batch_size, shuffle=True, num_workers=4)
testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size, shuffle=False, num_workers=4)
需要建立数据了,我们是准备用shapenet的数据集。先看看data_utils中的ShapeNetDataLoader.py文件。等会再来看看怎么建立数据。
在ShapeNetDataLoader.py文件中,引入库没啥本地库。
import os
import json
import warnings
import numpy as np
from torch.utils.data import Dataset
warnings.filterwarnings('ignore')
在这个文件中最主要的部分就是PartNormalDataset这个类,看了半天,感觉也没啥值得说的,跟pointnet里面的加载数据部分都差不多。
class PartNormalDataset(Dataset):
def __init__(self,root = './data/shapenetcore_partanno_segmentation_benchmark_v0_normal', npoints=2500, split='train', class_choice=None, normal_channel=False):
self.npoints = npoints
self.root = root
self.catfile = os.path.join(self.root, 'synsetoffset2category.txt')
self.cat = {}
self.normal_channel = normal_channel
with open(self.catfile, 'r') as f:
for line in f:
ls = line.strip().split()
self.cat[ls[0]] = ls[1]
self.cat = {k: v for k, v in self.cat.items()}
self.classes_original = dict(zip(self.cat, range(len(self.cat))))
if not class_choice is None:
self.cat = {k:v for k,v in self.cat.items() if k in class_choice}
# print(self.cat)
self.meta = {}
with open(os.path.join(self.root, 'train_test_split', 'shuffled_train_file_list.json'), 'r') as f:
train_ids = set([str(d.split('/')[2]) for d in json.load(f)])
with open(os.path.join(self.root, 'train_test_split', 'shuffled_val_file_list.json'), 'r') as f:
val_ids = set([str(d.split('/')[2]) for d in json.load(f)])
with open(os.path.join(self.root, 'train_test_split', 'shuffled_test_file_list.json'), 'r') as f:
test_ids = set([str(d.split('/')[2]) for d in json.load(f)])
for item in self.cat:
# print('category', item)
self.meta[item] = []
dir_point = os.path.join(self.root, self.cat[item])
fns = sorted(os.listdir(dir_point))
# print(fns[0][0:-4])
if split == 'trainval':
fns = [fn for fn in fns if ((fn[0:-4] in train_ids) or (fn[0:-4] in val_ids))]
elif split == 'train':
fns = [fn for fn in fns if fn[0:-4] in train_ids]
elif split == 'val':
fns = [fn for fn in fns if fn[0:-4] in val_ids]
elif split == 'test':
fns = [fn for fn in fns if fn[0:-4] in test_ids]
else:
print('Unknown split: %s. Exiting..' % (split))
exit(-1)
# print(os.path.basename(fns))
for fn in fns:
token = (os.path.splitext(os.path.basename(fn))[0])
self.meta[item].append(os.path.join(dir_point, token + '.txt'))
self.datapath = []
for item in self.cat:
for fn in self.meta[item]:
self.datapath.append((item, fn))
self.classes = {}
for i in self.cat.keys():
self.classes[i] = self.classes_original[i]
# Mapping from category ('Chair') to a list of int [10,11,12,13] as segmentation labels
self.seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],
'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],
'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],
'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
# for cat in sorted(self.seg_classes.keys()):
# print(cat, self.seg_classes[cat])
self.cache = {} # from index to (point_set, cls, seg) tuple
self.cache_size = 20000
继续跳回原处。把加载数据部分代码改成:
'''DATA LOADING'''
DATA_PATH = 'D:\\test\\shapenetcore_partanno_segmentation_benchmark_v0\\'
TRAIN_DATASET = ShapeNetDataset(root=DATA_PATH, npoints=args.num_point, split='train',classification=True)
TEST_DATASET = ShapeNetDataset(root=DATA_PATH, npoints=args.num_point, split='test',classification=True)
trainDataLoader = torch.utils.data.DataLoader(TRAIN_DATASET, batch_size=args.batch_size, shuffle=True, num_workers=4)
testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size, shuffle=False, num_workers=4)
突然发现PartNormalDataset这个类还跟我想象的不一样,有点问题,所以,我就把类,换成了,用pointnet时候的那个dataset.py文件,导入这个文件。
把dataset.py文件复制粘贴在data_utils下,至于dataset.py文件在哪里,请看我的学习记录。
from data_utils.dataset import ShapeNetDataset
接下来就是模型加载部分。
'''MODEL LOADING'''
num_class = 40
MODEL = importlib.import_module(args.model)
shutil.copy('./models/%s.py' % args.model, str(experiment_dir))
shutil.copy('./models/pointnet_util.py', str(experiment_dir))
classifier = MODEL.get_model(num_class,normal_channel=args.normal).cuda()
criterion = MODEL.get_loss().cuda()
try:
checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
start_epoch = checkpoint['epoch']
classifier.load_state_dict(checkpoint['model_state_dict'])
log_string('Use pretrain model')
except:
log_string('No existing model, starting training from scratch...')
start_epoch = 0
if args.optimizer == 'Adam':
optimizer = torch.optim.Adam(
classifier.parameters(),
lr=args.learning_rate,
betas=(0.9, 0.999),
eps=1e-08,
weight_decay=args.decay_rate
)
else:
optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
global_epoch = 0
global_step = 0
best_instance_acc = 0.0
best_class_acc = 0.0
mean_correct = []
差点忘了,还有测试函数:
def test(model, loader, num_class=40):
mean_correct = []
class_acc = np.zeros((num_class,3))
for j, data in tqdm(enumerate(loader), total=len(loader)):
points, target = data
target = target[:, 0]
points = points.transpose(2, 1)
points, target = points.cuda(), target.cuda()
classifier = model.eval()
pred, _ = classifier(points)
pred_choice = pred.data.max(1)[1]
for cat in np.unique(target.cpu()):
classacc = pred_choice[target==cat].eq(target[target==cat].long().data).cpu().sum()
class_acc[cat,0]+= classacc.item()/float(points[target==cat].size()[0])
class_acc[cat,1]+=1
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item()/float(points.size()[0]))
class_acc[:,2] = class_acc[:,0]/ class_acc[:,1]
class_acc = np.mean(class_acc[:,2])
instance_acc = np.mean(mean_correct)
return instance_acc, class_acc
接下来就是训练:
'''TRANING'''
logger.info('Start training...')
for epoch in range(start_epoch,args.epoch):
log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
scheduler.step()
for batch_id, data in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):
points, target = data
points = points.data.numpy()
points = provider.random_point_dropout(points)
points[:,:, 0:3] = provider.random_scale_point_cloud(points[:,:, 0:3])
points[:,:, 0:3] = provider.shift_point_cloud(points[:,:, 0:3])
points = torch.Tensor(points)
target = target[:, 0]
points = points.transpose(2, 1)
points, target = points.cuda(), target.cuda()
optimizer.zero_grad()
classifier = classifier.train()
pred, trans_feat = classifier(points)
loss = criterion(pred, target.long(), trans_feat)
pred_choice = pred.data.max(1)[1]
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0]))
loss.backward()
optimizer.step()
global_step += 1
train_instance_acc = np.mean(mean_correct)
log_string('Train Instance Accuracy: %f' % train_instance_acc)
with torch.no_grad():
instance_acc, class_acc = test(classifier.eval(), testDataLoader)
if (instance_acc >= best_instance_acc):
best_instance_acc = instance_acc
best_epoch = epoch + 1
if (class_acc >= best_class_acc):
best_class_acc = class_acc
log_string('Test Instance Accuracy: %f, Class Accuracy: %f'% (instance_acc, class_acc))
log_string('Best Instance Accuracy: %f, Class Accuracy: %f'% (best_instance_acc, best_class_acc))
if (instance_acc >= best_instance_acc):
logger.info('Save model...')
savepath = str(checkpoints_dir) + '/best_model.pth'
log_string('Saving at %s'% savepath)
state = {
'epoch': best_epoch,
'instance_acc': instance_acc,
'class_acc': class_acc,
'model_state_dict': classifier.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
torch.save(state, savepath)
global_epoch += 1
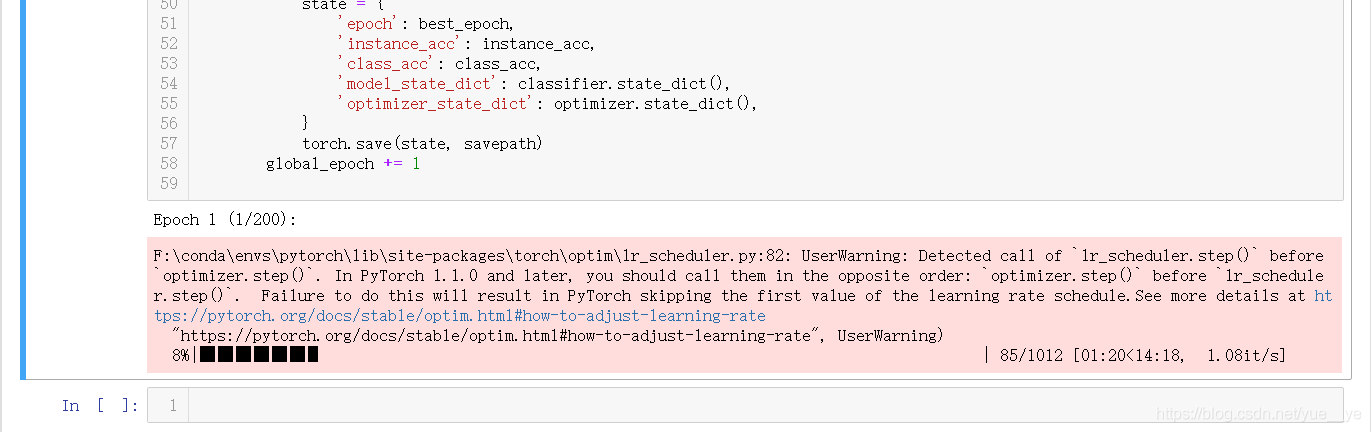
跑一下试试
准确度98.3%,挺高的。pointnet我记得是97.9%.
吐了,吐了,一下子想起来,用的模型是用的Pointnet的模型,不是pointnet++的模型。忘了改参数了。在参数设置那块改成(16的batch_size出现内存报错,我就设置成12了):

def parse_args():
'''PARAMETERS'''
parser = argparse.ArgumentParser('PointNet')
parser.add_argument('--batch_size', type=int, default=12, help='batch size in training [default: 12]')
parser.add_argument('--model', default='pointnet2_cls_msg', help='model name [default: pointnet2_cls_msg]')
parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training [default: 200]')
parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training [default: 0.001]')
parser.add_argument('--gpu', type=str, default='0', help='specify gpu device [default: 0]')
parser.add_argument('--num_point', type=int, default=2048, help='Point Number [default: 2048]')
parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training [default: Adam]')
parser.add_argument('--log_dir', type=str, default='pointnet2_cls_msg', help='experiment root')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate [default: 1e-4]')
parser.add_argument('--normal', action='store_true', default=False, help='Whether to use normal information [default: False]')
return parser.parse_args([])
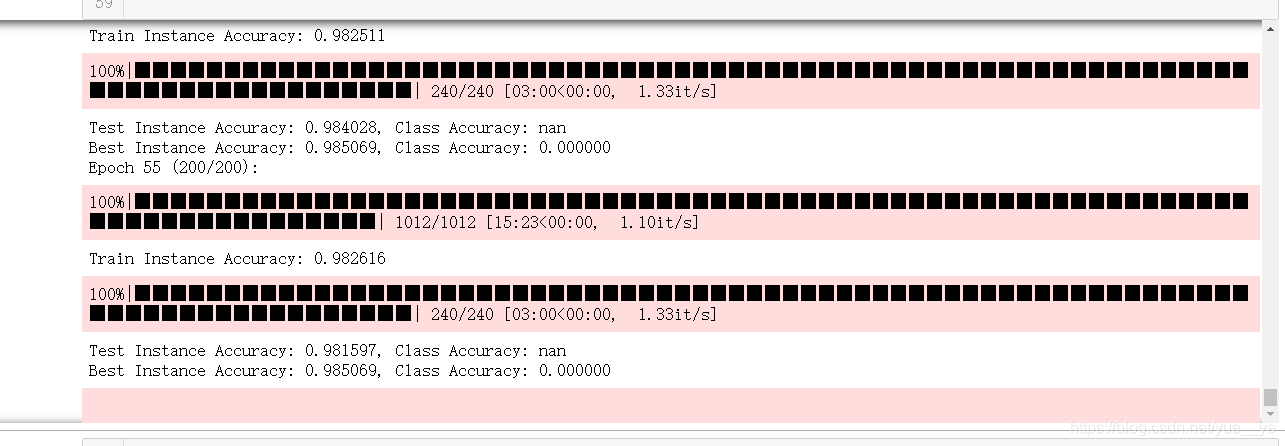
继续跑着。
跑了几天,终于跑出结果来了,期间还断电。是要比pointnet要更好点。
接下来准备用pointnet++跑segmatic kitti的数据集,分割下地面点看看,因为比较好奇pointnet++跟gndnet谁更好点。接下来的东西就放在学习记录二里面吧。