文章目录
实现SARSA算法和对应的强化学习智能体
- SARSA(State-Action-Reward-State-Action)是一种强化学习算法,主要用于估计给定策略下的最优状态-动作价值函数(QQ 函数)。它是一种在轨策略(on-policy)算法,意味着它使用当前策略来选择动作。
如何实现SARSA算法(状态-行动-奖励-状态-行动)
以及如何使用SARSA开发和训练智能体
SARSA可以应用与无模型种子问题,并对未知马尔科夫决策过程MDP的价值函数进行优化。
前期准备
import numpy as np
import random
实现步骤
使用一个函数实现SARSA学习算法的更新
并使用 ϵ \epsilon ϵ-greedy的探索策略。
两者结合就可以得到一个在给定的强化学习环境中工作的完整智能体。
-
定义一个实现SARSA算法的函数,并用0初始化状态-动作价值
def sarsa(env, max_episodes): grid_action_values = np.zeros((len(env.distinct_states), env.action_space.n)) -
根据环境的配置更新目标状态和炸弹状态的价值
grid_action_values[env.goal_state] = 1 grid_action_values[env.bomb_state] = -1 -
定义折扣因子gamma和学习率超参数 α \alpha α 。同样创建一个别名q表示grid_action_values
gamma = 0.99 # discounting factor alpha = 0.01 # learning rate # q: state-action-value function q = grid_action_values -
实现外部循环
for episode in range(max_episodes): step_num = 1 done = False state = env.reset() action = greedy_policy(q[state], 1) -
实现内循环,其中包括SARSA学习的更新步骤
while not done: next_state, reward, done = env.step(action) step_num += 1 decayed_epsilon = gamma ** step_num # Doesn't have to be gamma next_action = greedy_policy(q[next_state], decayed_epsilon) q[state][action] += alpha * ( reward + gamma * q[next_state][next_action] - q[state][action] ) state = next_state action = next_action- 初始化:选择一个初始状态 S S S 和在该状态下执行的动作 A A A。
- 循环直到结束:
- 执行动作 A A A,观察奖励 R R R 和下一个状态 S ′ S' S′。
- 使用策略选择在状态
S
′
S'
S′ 下要执行的动作
A
′
A'
A′。
在数学语言中,这些步骤可以表示为:
S ′ , R , done = env.step ( A ) step_num + = 1 ϵ = γ step_num A ′ = greedy_policy ( Q ( S ′ ) , ϵ ) S', R, \text{done} = \text{env.step}(A) \\ \text{step\_num} += 1 \\ \epsilon = \gamma^{\text{step\_num}} \\ A' = \text{greedy\_policy}(Q(S'), \epsilon) S′,R,done=env.step(A)step_num+=1ϵ=γstep_numA′=greedy_policy(Q(S′),ϵ)
- 更新 Q 值:
- 更新 Q 值
Q
(
S
,
A
)
Q(S, A)
Q(S,A) 使用以下公式:
Q ( S , A ) ← Q ( S , A ) + α [ R + γ Q ( S ′ , A ′ ) − Q ( S , A ) ] Q(S, A) \leftarrow Q(S, A) + \alpha \left[ R + \gamma Q(S', A') - Q(S, A) \right] Q(S,A)←Q(S,A)+α[R+γQ(S′,A′)−Q(S,A)]
其中: - α \alpha α 是学习率。
- γ \gamma γ 是折扣因子。
- Q ( S ′ , A ′ ) Q(S', A') Q(S′,A′) 是在状态 S ′ S' S′ 下执行动作 A ′ A' A′ 的 Q 值。
- 更新 Q 值
Q
(
S
,
A
)
Q(S, A)
Q(S,A) 使用以下公式:
- 转移到下一个状态和动作:
- 将当前状态 S S S 更新为下一个状态 S ′ S' S′。
- 将当前动作
A
A
A 更新为下一个动作
A
′
A'
A′。
在数学语言中,这些步骤可以表示为:
S = S ′ A = A ′ S = S' \\ A = A' S=S′A=A′
- 重复步骤 2-4,直到达到终止状态(
done为 True)。
-
在SARSA的最后一步,可视化状态-动作价值函数
visualize_grid_action_values(grid_action_values) -
实现智能体要使用的 ϵ \epsilon ϵ-greedy策略 greedy_policy()
def greedy_policy(q_values, epsilon): """Epsilon-greedy policy """ if random.random() >= epsilon: return np.argmax(q_values) else: return random.randint(0, 3)if random.random() >= epsilon::这里,random.random()生成一个0到1之间的随机浮点数。如果这个随机数大于或等于epsilon,那么执行if分支中的代码。return np.argmax(q_values):如果条件为真,函数返回q_values数组中最大值的索引。这个索引代表了具有最高Q值的动作,也就是我们基于当前知识认为的最佳动作。
else::如果random.random()生成的随机数小于epsilon,则执行else分支中的代码。return random.randint(0, 3):在这种情况下,函数返回一个从0到3(包含0和3)的随机整数,代表随机选择的动作。这表明在 epsilon-greedy 策略中,有一定概率(由epsilon决定)我们会选择一个随机动作而不是最佳动作,以鼓励探索环境。
-
实现__main__函数并运行SARSA算法
if __name__ == "__main__": max_episodes = 4000 env = GridworldV2Env(step_cost=-0.1, max_ep_length=30) sarsa(env, max_episodes)
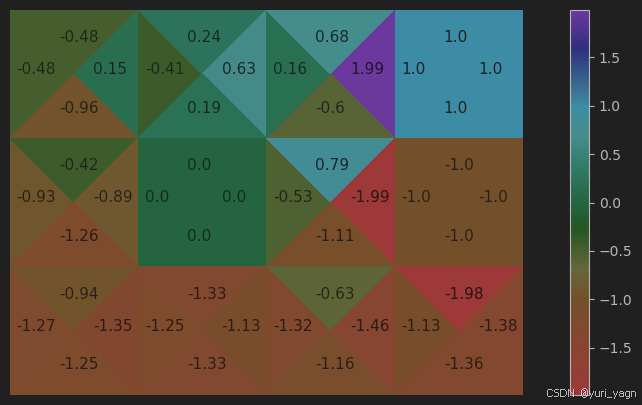
工作原理
SARSA是一种基于时序差分学习的在轨策略(on-policy)控制算法。
本节使用SARSA算法估计最优状态-动作价值。SARSA算法与Q学习非常相似。
在每次迭代中,SARSA算法都会根据当前的状态和动作来更新价值表,目标是找到每个状态下的最优策略。通过这种方式,算法可以学习如何在给定的环境中取得最佳的行动策略。
总结一下,SARSA 算法的核心在于它在更新 Q 值时考虑了下一个状态 S ′ S' S′ 和下一个动作 A ′ A' A′,而不是像 Q-Learning 那样考虑在下一个状态 S ′ S' S′ 下所有可能动作的最大 Q 值。这使得 SARSA 是一种同策略(on-policy)方法,因为它使用当前策略来选择下一个动作 A ′ A' A′。
Initialize
Q
(
s
,
a
)
,
∀
s
∈
S
,
a
∈
A
(
s
)
Q(s,a),\forall s\in\mathcal{S},a\in\mathcal{A}(s)
Q(s,a),∀s∈S,a∈A(s), arbitrarily, and
Q
(
t
e
r
m
i
n
a
l
−
s
t
a
t
e
,
⋅
)
=
0
Q(terminal-state,\cdot)=0
Q(terminal−state,⋅)=0
Repeat (for each episode):
Initialize
S
\operatorname{Initialize}S
InitializeS
Choose
A
A
A from
S
S
S using policy derived from
Q
Q
Q (e.g.,
ϵ
\epsilon
ϵ-greedy)
Repeat (for each step of episode):
T
a
k
e
a
c
t
i
o
n
A
,
o
b
s
e
r
v
e
R
,
S
′
{\mathrm{Take~action~}A,{\mathrm{~observe~}}R,S^{\prime}}
Take action A, observe R,S′
Choose
A
′
A^\prime
A′ from
S
′
S^\prime
S′ using policy derived from
Q
Q
Q (e.g.,
ϵ
\epsilon
ϵ-greedy)
Q
(
S
,
A
)
←
Q
(
S
,
A
)
+
α
[
R
+
γ
Q
(
S
′
,
A
′
)
−
Q
(
S
,
A
)
]
Q(S,A)\leftarrow Q(S,A)+\alpha\left[R+\gamma Q(S^{\prime},A^{\prime})-Q(S,A)\right]
Q(S,A)←Q(S,A)+α[R+γQ(S′,A′)−Q(S,A)]
S
˙
←
S
′
;
\dot{S} \leftarrow S^{\prime };
S˙←S′;
A
←
A
′
;
A\leftarrow A^{\prime };
A←A′; until
S
S
S is terminal
初始化
- Q ( s , a ) Q(s,a) Q(s,a) 初始化:对于所有状态 s s s 和在状态 s s s 下可采取的动作 a a a, Q Q Q 函数被任意初始化。 Q Q Q 函数表示在特定状态 s s s 下采取动作 a a a 的期望回报。
- 终端状态 Q Q Q 值:对于终端状态,所有动作的 Q Q Q 值设为0,因为终端状态之后没有进一步的奖励。
算法流程
-
重复(每个剧集):
- 对于每个剧集(episode),算法会进行以下步骤。
- 初始化状态 S S S:选择一个初始状态 S S S。
-
选择动作 A A A:
- 根据当前的 Q Q Q 函数(例如使用 ϵ \epsilon ϵ-贪婪策略)从状态 S S S 中选择一个动作 A A A。
-
重复(每个剧集的每一步):
- 采取动作并观察:执行动作 A A A,观察获得的奖励 R R R 和下一个状态 S ′ S' S′。
- 选择下一个动作 A ′ A' A′:在新的状态 S ′ S' S′ 下,使用基于 Q Q Q 函数的策略(如 ϵ \epsilon ϵ-贪婪)选择下一个动作 A ′ A' A′。
-
更新 Q Q Q 函数:
-
使用以下公式更新 Q Q Q 函数:
Q ( S , A ) ← Q ( S , A ) + α [ R + γ Q ( S ′ , A ′ ) − Q ( S , A ) ] Q(S,A) \leftarrow Q(S,A) + \alpha \left[ R + \gamma Q(S',A') - Q(S,A) \right] Q(S,A)←Q(S,A)+α[R+γQ(S′,A′)−Q(S,A)] -
其中, α \alpha α 是学习率, γ \gamma γ 是折扣因子。
-
-
更新状态和动作:
- 将 S ′ S' S′ 更新为新的当前状态 S S S。
- 将 A ′ A' A′ 更新为新的当前动作 A A A。
- 这个过程一直重复,直到 S S S 成为终端状态。
构建基于Q学习的智能体
Q 学习可以应用于无模型的强化学习问题。它支持离轨(off-policy)学习,为使用其他策略或其他智能体收集经验的问题提供了实用的解决方案。
本节将构造一个可工作的强化学习智能体,使用Q学习算法生成状态-价值函数
前期准备
impoet numpy as np
import random
实现步骤
用一个函数实现Q学习算法,并使用 ϵ \epsilon ϵ-greedy的探索策略。
-
定义一个实现Q学习算法的函数,并用0初始化状态-动作价值
def q_learning(env, max_episodes): grid_action_values = np.zeros((len(env.distinct_states), env.action_space.n)) -
根据环境的配置更新目标状态和炸弹状态的值
grid_action_values[env.goal_state] = 1 grid_action_values[env.bomb_state] = -1 -
定义折扣因子gamma 和学习率超参数 alpha 。同样创建一个别名q表示grid_action_values
gamma = 0.99 # discounting factor alpha = 0.01 # learning rate # q: state-action-value function q = grid_action_values -
实现外部循环
for episode in range(max_episodes): step_num = 1 done = False state = env.reset() -
实现内循环,其中包括Q学习的更新。此外对 ϵ \epsilon ϵ-greedy策略使用 ϵ \epsilon ϵ进行衰减
while not done: decayed_epsilon = 1 * gamma ** step_num # Doesn't have to be gamma action = greedy_policy(q[state], decayed_epsilon) next_state, reward, done = env.step(action) # Q-Learning update grid_action_values[state][action] += alpha * ( reward + gamma * max(q[next_state]) - q[state][action] ) step_num += 1 state = next_state在 Q-Learning 算法中,Q 值的更新可以用以下数学公式表示:
设 Q ( s , a ) Q(s, a) Q(s,a) 表示在状态 s s s 下执行动作 a a a 的 Q 值。在时间步 t t t 时,智能体观察到状态 S t S_t St,执行动作 A t A_t At,然后到达新状态 S t + 1 S_{t+1} St+1 并获得奖励 R t + 1 R_{t+1} Rt+1。Q 值的更新公式为:
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a ′ Q ( S t + 1 , a ′ ) − Q ( S t , A t ) ] Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \max_{a'} Q(S_{t+1}, a') - Q(S_t, A_t)] Q(St,At)←Q(St,At)+α[Rt+1+γmaxa′Q(St+1,a′)−Q(St,At)]
其中:- α \alpha α 是学习率,取值在 0 到 1 之间,决定了新信息对旧信息的覆盖程度。
- γ \gamma γ 是折扣因子,取值在 0 到 1 之间,用于平衡即时奖励和未来奖励。
- max a ′ Q ( S t + 1 , a ′ ) \max_{a'} Q(S_{t+1}, a') maxa′Q(St+1,a′) 表示在状态 S t + 1 S_{t+1} St+1 下所有可能动作的 Q 值中的最大值。
-
R
t
+
1
R_{t+1}
Rt+1 是在时间步
t
+
1
t+1
t+1 收到的奖励。
这个公式表示,Q 值的更新等于当前 Q 值加上一个学习率 α \alpha α 乘以奖励 R t + 1 R_{t+1} Rt+1 和折扣后的未来最大 Q 值 γ max a ′ Q ( S t + 1 , a ′ ) \gamma \max_{a'} Q(S_{t+1}, a') γmaxa′Q(St+1,a′) 与当前 Q 值 Q ( S t , A t ) Q(S_t, A_t) Q(St,At) 之差。这个差值称为 TD 误差(Temporal-Difference error),它衡量了基于当前估计的 Q 值和基于实际经验的新估计之间的差异。
-
最后一步,对状态-动作价值函数进行可视化
visualize_grid_action_values(grid_action_values) -
实现智能体要使用的 ϵ \epsilon ϵ-greedy策略
def greedy_policy(q_values, epsilon): """Epsilon-greedy policy """ if random.random() >= epsilon: return np.argmax(q_values) else: return random.randint(0, 3) -
实现__main__函数,并运行Q学习算法
if __name__ == "__main__": max_episodes = 4000 env = GridworldV2Env(step_cost=-0.1, max_ep_length=30) q_learning(env, max_episodes)
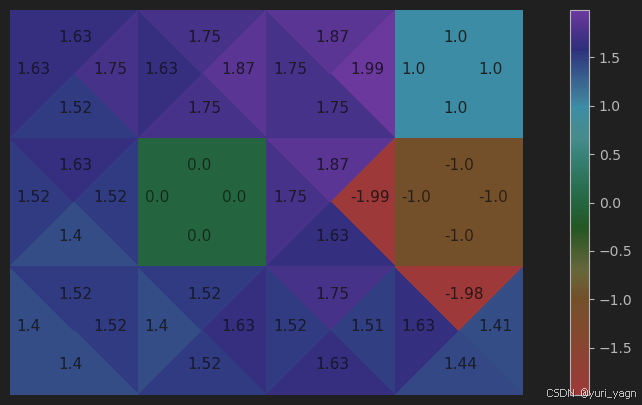
工作原理
Q学习算法中涉及Q值的更新,总结为: Q [ s , a ] = Q [ s , a ] + λ ∗ ( r + γ ∗ m a x a ′ ( Q [ s ′ , a ′ ] ) − Q [ s , a ] ) Q[s,a]=Q[s,a]+\lambda*(r+\gamma*max_{a^{\prime}}(Q[s^{\prime},a^{\prime}])-Q[s,a]) Q[s,a]=Q[s,a]+λ∗(r+γ∗maxa′(Q[s′,a′])−Q[s,a])
Q [ s , a ] Q[s,a] Q[s,a] 是当前状态s和动作q的Q函数值
m a x a ′ ( Q [ s ′ , a ′ ] ) max_{a^{\prime}}(Q[s^{\prime},a^{\prime}]) maxa′(Q[s′,a′]) 用于从下一步可能的Q值中选择最大值
两者的主要区别
- 策略依赖性:SARSA 使用当前策略来选择下一个动作,而 Q 学习不依赖当前策略来更新 Q 值。
- 探索与利用:SARSA 的探索和利用是同步进行的,而 Q 学习在更新时完全依赖于最大 Q 值,可能会更倾向于探索。
- 稳定性:SARSA 更稳定,因为它直接依赖于当前策略。Q 学习可能会因为其贪婪性质而在某些情况下导致不稳定的学习过程。
SARSA算法比Q学习算法具有更好的收敛性,因此它更适合在线学习或再真实系统上学习。
Q学习更适合于模拟环境或真实系统上资源(如时间/金钱)不太昂贵的情况下训练。
SARSA 算法的收敛性:
- 同策略更新:SARSA 使用当前策略来选择下一个动作,这意味着它的更新是基于当前策略的动作后果。因此,它的学习过程与实际策略紧密相关,导致学习过程更加稳定。
- 逐步学习:SARSA 在每个时间步都进行学习,而不是只依赖于最终的奖励。这种逐步的学习方式有助于避免由于过分依赖未来奖励估计而产生的潜在不稳定性和偏差。
- 避免过估计:由于 SARSA 在更新 Q 值时考虑了下一个动作的 Q 值,而不是最大 Q 值,它不太可能产生过估计(overestimation)问题,这在 Q 学习中是一个常见问题。
SARSA 适合在线学习和真实系统:
- 在线学习:在线学习要求算法能够从实时数据中快速且稳定地学习。SARSA 的稳定收敛性使其更适合于这种场景,因为它能够确保策略的持续改进而不会出现剧烈波动。
- 真实系统:在真实系统中,错误的决策可能带来严重的后果。SARSA 的稳定性有助于减少这种风险,因为它不太可能因为过度探索而导致灾难性的决策。
Q 学习算法的适用性:
- 探索性:Q 学习算法通过在每个时间步选择最大化未来奖励的动作来进行学习,这可能导致算法进行更多的探索。这种探索性在资源充足的情况下是有益的,因为它有助于快速发现最优策略。
- 模拟环境:在模拟环境中,错误的决策不会带来实际损失,因此 Q 学习的探索性可以被充分利用,以快速找到最优解。
- 资源成本:Q 学习可能需要更多的迭代和探索来达到收敛,这在时间和计算资源上可能比较昂贵。在资源受限的情况下,Q 学习可能不是最佳选择。