【C++】—— 模板进阶
1 非类型模板参数
1.1 什么是非类型模板参数
模板参数分为类型和非类型模板参数
类型形参:出现在模板参数列表中,跟在 class 或者 typename 这后的参数类型名称
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用
什么意思呢,我们结合代码来看一下
// 定义一个模板类型的静态数组
template<class T, size_t N>
class array
{
public :
T & operator[](size_t index) { return _array[index]; }
const T& operator[](size_t index)const { return _array[index]; }
size_t size()const { return _size; }
bool empty()const { return 0 == _size; }
private:
T _array[N];
size_t _size;
};
T
T
T 是用
c
l
a
s
s
class
class 或
t
y
p
e
n
a
m
e
typename
typename 定义的,为类型模板参数
N
N
N 是直接用类型(
s
i
z
e
size
size_
t
t
t)定义的,即为非类型模板参数,非类型模板参数可以给缺省值
非类型模板参数有什么用呢?比如我们要定义一个静态的数组/栈
template<size_t N = 10>
class Stack
{
private:
int _a[N];
size_t top;
};
N
N
N 是常量,可以定义数组的大小。为什么是常量呢?因为模版在编译时就实例化了,所以
N
N
N 在编译器时就确定了
1.2 非类型模板参数对比宏的优势
那么它比宏的优点是什么呢?
define N 10
class stack
{
private:
int _a[N];
size_t top;
};
宏是写死的, N N N 只能为 10,比如我想一个栈存 5 个数据,一个存 10 个数据,宏就做不到。而非类型模板参数可以做到
//给了缺省值10,可以不传参
Stack<> s1;
Stack<5> s2;
注:如果非类型模板参数给了缺省值,实例化时依然要加上<>(C++20之后可不加)
当然,其底层本质还是生成了两个类,一个类 N 是 5,另一个 N 是 10。
非类型模板参数只能用于整型,其他任何类型都不行(C++20之后支持浮点数)
整型家族有:
s
i
z
e
size
size_
t
t
t、
i
n
t
int
int、
s
h
o
r
t
short
short、
c
h
a
r
char
char、
b
o
o
l
bool
bool等
1.3 array 简单了解
那非类型模板参数在 STL库 中有什么应用吗?
C++11中提供 array 容器就运用了非类型模板参数

a
r
r
a
y
array
array容器其实就是一个静态数组,这是它的函数接口:
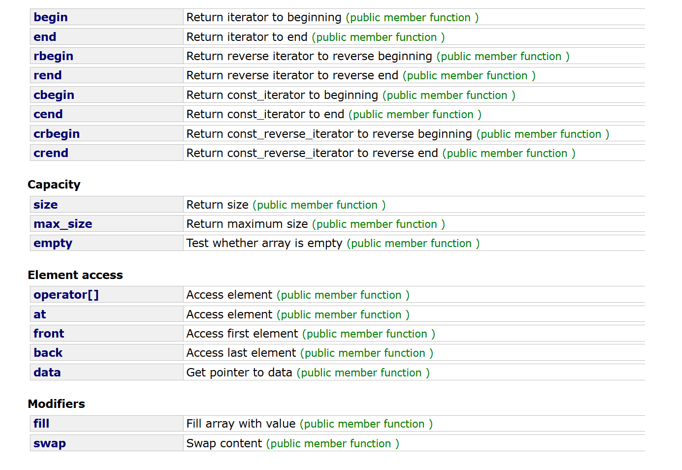
它同样支持迭代器访问等,但它不支持 p u s h push push_ b a c k back back、 i n s e r t insert insert 等,因为它不支持扩容。
那么 array 和静态数组有什么区别呢?
//有什么区别呢?
int arr1[10];
array<int, 10> arr2;
a
r
r
a
y
array
array 与 静态数组 基本没有什么区别,唯一的区别是
a
r
r
a
y
array
array 对越界的检查非常严格
普通静态数组越界读基本检查不出来。
而对于越界写是一种抽查:普通数组一般会在数组末尾给 1~3 个标志位,标志位会给某个值(假设为-1),程序结束后看标志位是否被修改,修改了就能被检查出来,没修改就检查不出。越界访问跳过标志位修改时检查不出的。

但是
a
r
r
a
y
array
array 容器对越界检查就很准,越界读和越界写都能检查出来。
这里因为
a
r
r
a
y
array
array 是自定义类型,它里面重载的 operator[] 中加了
a
s
s
e
r
t
assert
assert断言强制检查。他的机制和静态数组不一样
但是
a
r
r
a
y
array
array 还是比较鸡肋,我为什么不用
v
e
c
t
o
r
vector
vector 呢?
v
e
c
t
o
r
vector
vector 也能检查越界,还能动态增长,
a
r
r
a
y
array
array 唯一优势是它是在栈上开辟空间,
v
e
c
t
o
r
vector
vector 是在堆上,频繁的开辟数组
a
r
r
a
y
array
array 效率略高(栈上开空间栈帧建立的时候一次性就开好了)
2 模板的特化
2.1 引子
现在我们实现了一个函数模板,用于实现比较功能
template<class T>
bool Less(T left, T right)
{
return left < right;
}
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
private:
int _year;
int _month;
int _day;
};
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2024, 1, 1);
Date d2(2023, 1, 1);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
return 0;
}
用来比较 整型 和 日期
D
a
t
e
Date
Date类对象 都是没有问题的
但是传递日期类的地址去,比较结果就出问题了
int main()
{
Date d1(2024, 1, 1);
Date d2(2023, 1, 1);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
}

为什么?因为这里比较的是
d
1
d1
d1 和
d
2
d2
d2 两个地址的大小,不是比较他们的值。
我们可以使用模板的特化来解决这个问题,而模板特化又分为函数模板特化和类模板特化
2.2 函数模板特化
函数模板特化的步骤:
- 必须先有一个基础的函数模板
- 关键字 t e m p l a t e template template 后面接一对空的尖括号<>
- 函数名后面跟一对尖括号<>,尖括号中指定需要特化的类型
- 函数形参表:必须要和模板函数的基础参数类型完全相同,如果不同 ,编译器可能会报一些奇怪的错误
//函数模板 --- 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
//对Less函数模板进行特化
template<>
bool Less<Date*>(Date* left, Date* right)
{
return *left < *right;
}
但除了特化,还能其他方法:直接写一个函数,这种方法更加推荐
bool Less(Date* left, Date* right)
{
return *left < *right;
}
如果有模板和现成的类或函数,优先用现成的。
2.3 函数模板特化的坑
模板的特化其实是很坑的,上面大家可能没有感觉到,我们下面来见识一下。
template<class T>
bool Less(const T& left, const T& right)
{
return left < right;
}
严格来说,比较函数模板形参应该用 const引用 而不是上面的传值传参,万一是自定义类型呢
那这时 D a t e Date Date* 的函数模板特化该怎么写呢?
template<>
bool Less<Date*>(const Date*& left, cosnt Date*& right)
{
return *left < *right;
}
这样写可以吗?
不行!
问题出现在 c o n s t const const
模板中的 const 修饰的是 left 和 right,即引用本身。如果传
D
a
t
e
Date
Date* 类型,那
c
o
n
s
t
const
const 修饰的应该是
D
a
t
e
Date
Date*
但特化中的
c
o
n
s
t
const
const 是在 * 之前,修饰的是指针所指向的内容,而不是
D
a
t
e
Date
Date* 指针本身,相当于修饰 *
l
e
f
t
left
left 和 *
r
i
g
h
t
right
right。如果传
D
a
t
e
Date
Date* 类型,修饰的就是
D
a
t
e
Date
Date
所以要 将
c
o
n
s
t
const
const 放到 * 的后面
template<>
bool Less<Date*>( Date* const& left, Date* const& right)
{
return *left < *right;
}
那如果传
c
o
n
s
t
const
const
D
a
t
e
Date
Date* ,这特化的模板还能用吗?
template<>
bool Less<Date*>( Date* const & left, Date* const& right)
{
return *left < *right;
}
int main()
{
Date d1(2026, 1, 1);
Date d2(2025, 1, 1);
const Date* p1 = &d1;
const Date* p2 = &d2;
cout <<" "<< Less(p1, p2) << endl;
return 0;
}
不能
const Date* 和 Date* 是两个类型。
c
o
n
s
t
const
const
D
a
t
e
Date
Date* 传给
D
a
t
e
Date
Date* 会造成权限放大,无法编译通过
只能再特化一个
c
o
n
s
t
const
const
D
a
t
e
Date
Date* 的函数模板
template<>
bool Less<const Date*>(const Date* const& left, const Date* const& right)
{
return *left < *right;
}
这里的两个const,我们来理一下:前一个 c o n s t const const,是属于 c o n s t const const D a t e Date Date* 类型;后一个 c o n s t const const 是修饰引用对象本身。
可能小伙伴对
c
o
n
s
t
const
const 放在后面有些不习惯
用const修饰普通类型,
c
o
n
s
t
const
const 既可以放在之前也可以放在之后
cosnt int i = 0;
int const j = 1;
引用也是如此(虽然难看了点)
const int& rx = i;
int const& ry = j;
这样写函数模板可能大家更容易理解一点
template<class T>
bool Less(T const & left, T const & right)
{
return left < right;
}
总结:
尽量别用函数模板特化,直接用普通函数不香吗
2.4 类模板的特化
2.4.1 全特化
//原模版
template<class T1, class T2>
class Data
{
public :
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//全特化
template<>
class Data<int, char>
{
public :
Data() { cout << "Data<int, char>" << endl; }
private:
int _d1;
char _d2;
};
int main()
{
Data<int, int> d1;
Data<int, char> d2;
return 0;
}

2.4.2 偏特化(半特化)
偏特化就是只特化一部分参数,比如上述 D a t a Data Data 类,我只特化第二个参数为 d o u b l e double double
template<class T1>
class Data<T1, double>
{
public:
Data() { cout << " Data<T1, double>" << endl; }
private:
int _d1;
char _d2;
};
int main()
{
Data<int, double> d1;
Data<char, double> d2;
return 0;
}

2.4.3 选择
那如果全特化和半特化都符合,编译器走谁呢?
template<>
class Data<int, char>
{
public :
Data() { cout << " Data<int, char>" << endl; }
private:
int _d1;
char _d2;
};
template<class T1>
class Data<T1, char>
{
public:
Data() { cout << " Data<T1, char>" << endl; }
private:
int _d1;
char _d2;
};
int main()
{
Data<int, char> d1;
return 0;
}

走全特化
我们可以认为编译器是个懒狗。半特化的 T1 还要自己推导,烦死了,直接用全特化多香。
2.4.4 偏特化的妙用
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public :
Data() { cout << "Data<T1*, T2*>" << endl; }
private:
T1 _d1;
T2 _d2;
};
如果传的类型是指针,就调用这个偏特化,任意类型的指针!
int main()
{
Data<int*, char*> d1;
Data<int*, int*> d2;
return 0;
}

还可以引用特化
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public :
Data() { cout << " Data<T1&, T2&>" << endl; }
private:
T1 _d1;
T2 _d2;
};
int main()
{
Data<int&, char&> d1;
Data<int&, int&*> d2;
return 0;
}

指针和引用混在一起特化也可以
template <typename T1, typename T2>
class Data <T1&, T2*>
{
public :
Data() { cout << " Data<T1&, T2*>" << endl; }
private:
T1 _d1;
T2 _d2;
};
int main()
{
Data<int&, char*> d1;
Data<int&, int*> d2;
return 0;
}

应用:
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
template<class T>
class Less<T*>
{
public:
bool operator()( T* const& x, T* const& y) const
{
return *x < *y;
}
};
int main()
{
int a = 1;
int b = 0;
int* pa = &a;
int* pb = &b;
double c = 1.0;
double d = 2.0;
cout << Less<int>()(a, b) << endl;
cout << Less<int*>()(pa, pb) << endl;
cout << Less<double*>()(&c, &d) << endl;
return 0;
}
如果不用半特化,还要全特化出
i
n
t
int
int* 和
d
o
u
b
l
e
double
double* 两个全特化,可见半特化还是很好用的。
3 模板分离编译
3.1 什么是分离编译
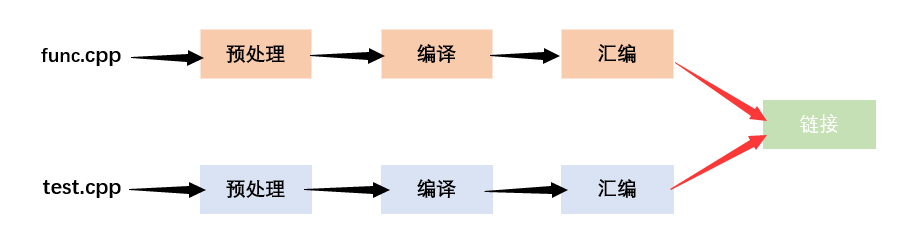
一个程序(项目)往往由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
3.2 模板的分离编译
但是,模板不支持分离编译
//func.h
#pragma once
#include<iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
void fun(const int& left, const int& right);
//func.cpp
#define _CRT_SECURE_NO_WARNINGS
#include"func.h"
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
void fun(const int& left, const int& right)
{
cout << " fun(const int& left, const int& right)" << endl;
}
//test.cpp
int main()
{
Add(1, 2);
fun(3, 4);
return 0;
}

可以看到,编译无法通过
3.3 为什么模板不支持分离编译
为什么模板不支持分离编译呢?要想理解这个问题,需对编译与链接有一些了解,详情大家可移步至:【C语言】 —— 编译和链接
我们简单回忆一下:
预处理
- 头文件的展开、宏替换、条件编译、去掉注释
- 生成
.i文件
经过预处理后, f u n c func func. h h h 文件就在 f u n c func func. c p p cpp cpp 和 t e s t test test. c p p cpp cpp 文件展开
编译
- 检查语法,生成汇编代码(报的语法错误就是这一阶段报出的)
- 生成
.s文件
汇编
- 汇编代码转换成二进制机器码(CPU只认识 0 和 1),生成符号表
- 生成
.o/.obj目标文件
链接
- 将目标文件合并在一起生成可执行程序,并且把需要的函数地址等链接上
- 生成
.exe可执行程序
模板不能分离编译问题就出在 链接 这一步上:
对 func.cpp 文件,在预处理时,
f
u
n
c
.
h
func.h
func.h 文件已经展开
//func.cpp
//func.h 已展开
/*******************************************
#include<iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
void fun(const int& left, const int& right);
********************************************/
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
void fun(const int& left, const int& right)
{
cout << " fun(const int& left, const int& right)" << endl;
}
编译阶段:
A d d Add Add 和 f u n c func func 都有其声明和定义, f u n c func func 可以被编译成具体的汇编指令,因为 f u n c func func 的所有东西都是确定的。但 A d d Add Add 不会生成具体的指令,因为 A d d Add Add 是个模版,不知道模版参数 T T T 是什么,只知道它声明了
对 t e s t . c p p test.cpp test.cpp 文件,在预处理时, f u n c . h func.h func.h 文件已经展开
//test.cpp
//func.h 已展开
/*******************************************
#include<iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
void fun(const int& left, const int& right);
********************************************/
int main()
{
Add(1, 2);
fun(3, 4);
return 0;
}
编译阶段:
t
e
s
t
.
c
p
p
test.cpp
test.cpp 中只有
A
d
d
Add
Add 和
f
u
n
c
func
func 的声明,但符合语法,依然让他们过了。但是没有
A
d
d
Add
Add 和
f
u
n
c
func
func 的地址:call Add(?)、call func(?),因为没有他们的定义。他们的定义可能在其他文件,那什么时候去找呢?在链接阶段。
这里需要注意:在链接之前,各个文件都是相互独立的,互不影响
链接的时候,除了将两个文件合并在一起,还有一个很重要的事情:找地址。之前我只有声明没有地址,到了编译阶段我就可以用函数名去找地址了(在符号表找)
f u n c func func 去找地址,找到了;但是 A d d Add Add 去找,找不到。
为什么找不到呢?
因为在
f
u
n
c
.
o
func.o
func.o 文件中,
A
d
d
Add
Add 还没有实例化。
A
d
d
Add
Add 实例化的方法在
t
e
s
t
.
o
test.o
test.o 文件中,但此时两文件并没有交集。
f
u
n
c
func
func文件 中有定义和声明,但不知道T实例化成什么;
t
e
s
t
test
test文件 中有声明、知道实例化方法,但没有定义。
3.4 实现分离编译的方法
其实模板也不是完全不能实现分离编译,还是有方法的:显式实例化
//func.h
#include<iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right);
void fun(const int& left, const int& right);
//显式实例化
//为与特化进行区分,template后不需加尖括号<>
template
int Add(const int& left, const int& right);
但上述只显示实例化了 i n t int int, d o u b l e double double类型调用要再次显示实例化成 d o u b l e double double,因此不推荐这种方法
模板最好的解决方案是在同一个文件(.h)中进行声明和定义
为什么
.
h
.h
.h 中同时进行声明和定义没问题呢?因为在预处理后
.
c
p
p
.cpp
.cpp 将
.
h
.h
.h 文件展开,就同时有了模版的声明、定义和实例化方式。在编译阶段就能直接将模板实例化成对应的函数,这样就有其地址,不会失败了。
4 模板总结
【优点】
- 模板复用了代码,
节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生- 增强了代码的
灵活性
【缺陷】
- 模板会导致
代码膨胀问题,也会导致编译时间变长- 出现模板编译错误时,
错误信息非常凌乱,不易定位错误
好啦,本期关于模板进阶的知识就介绍到这里啦,希望本期博客能对你有所帮助。同时,如果有错误的地方请多多指正,让我们在 C++ 的学习路上一起进步!