学习目标:
python—爬虫工具的使用
学习内容:
1、fiddler连接手机
2、scrapy项目部署到scrapyd
3、scrapy和gerapy部署网络爬虫
1、fiddler连接手机
1、安装fiddler软件,然后点击Tools—>>>Options
获取所有的进程信息:
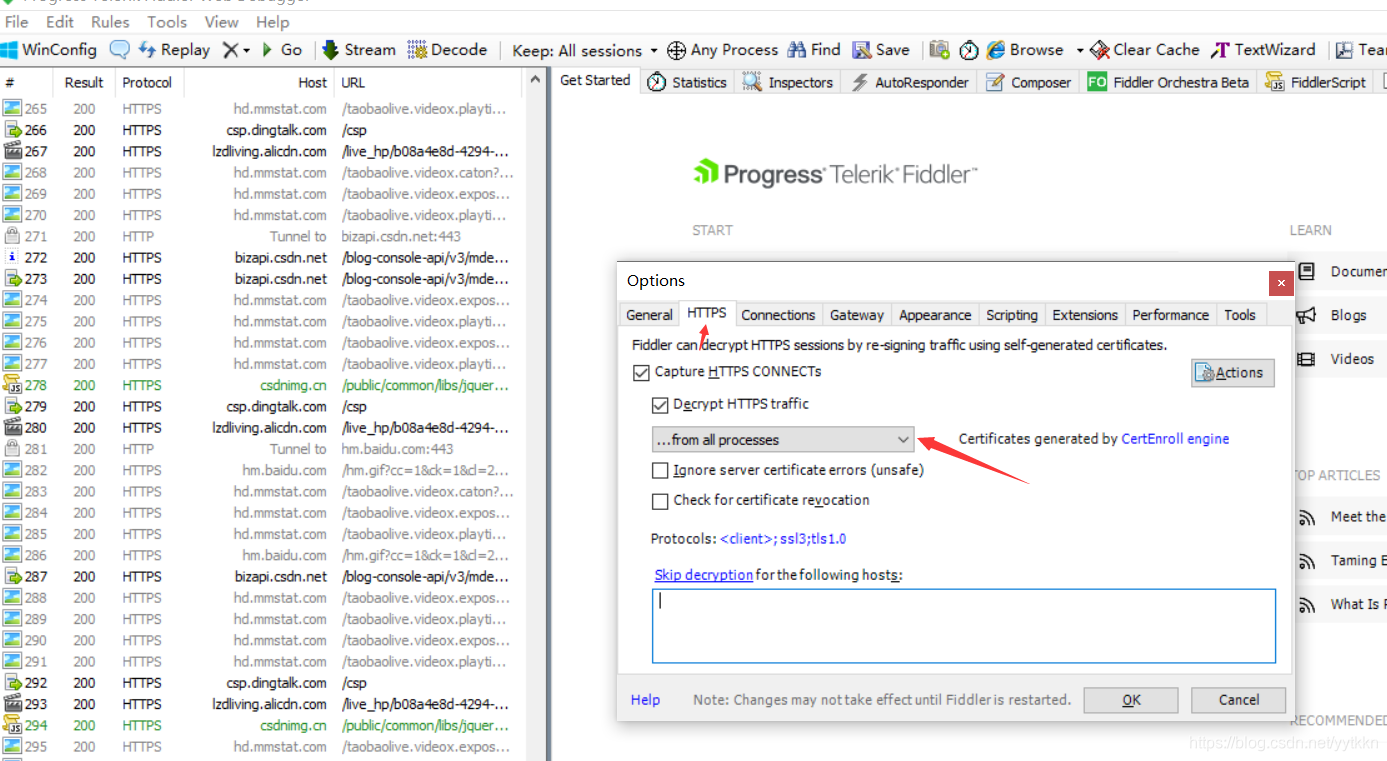
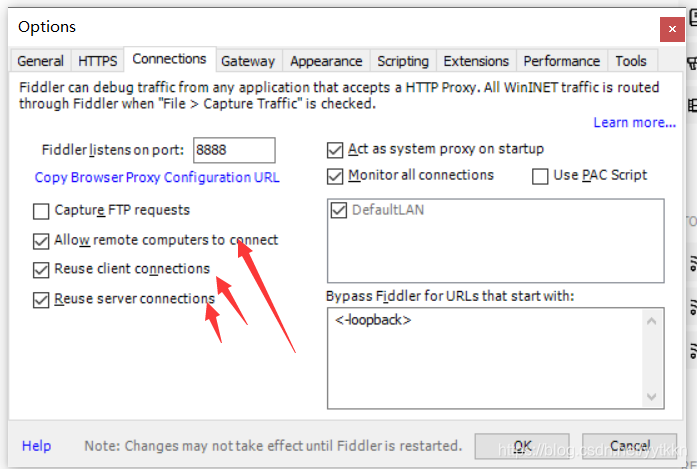
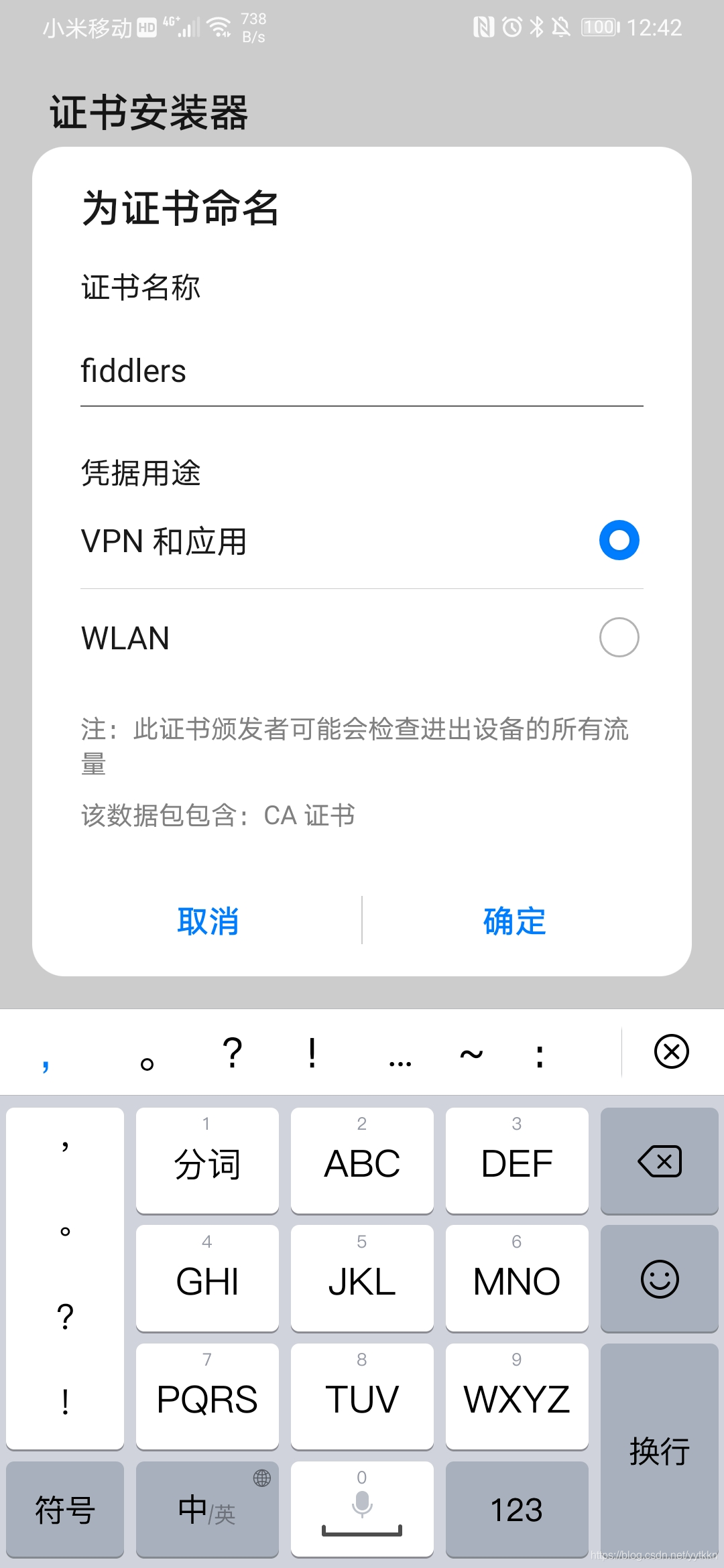
2、获取手机端的证书
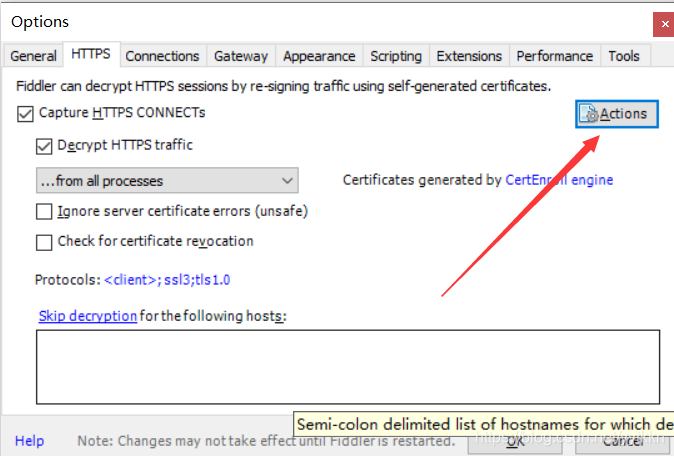
点击Actions—>>>Export Root Certificate to Desktop将手机证书下载到桌面,需要将这个证书弄到手机端安装好
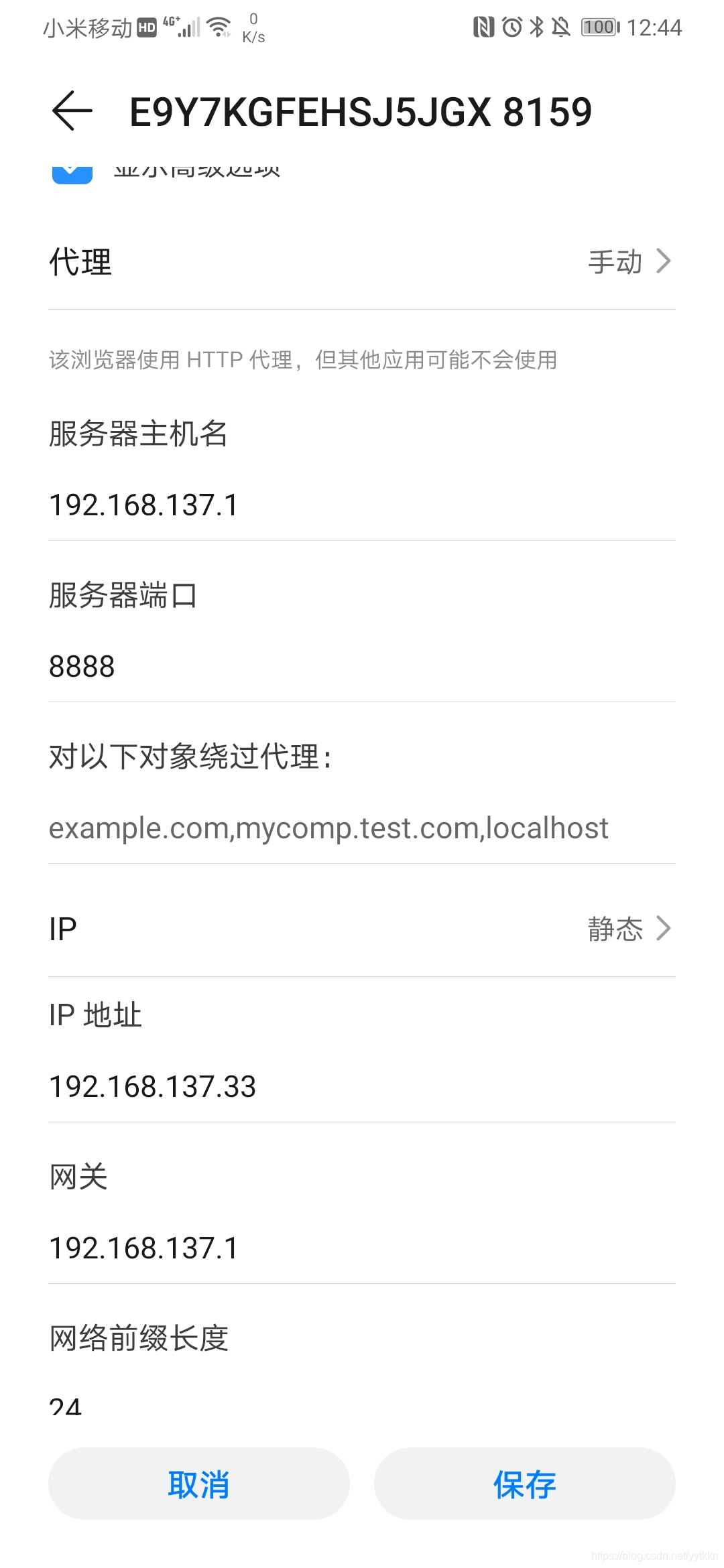
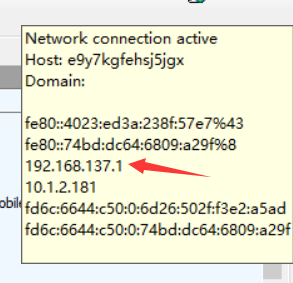
3、电脑打开热点用手机连上电脑,手动配置手机的代理为电脑的ip地址(同时是fiddler使用的ip),以及手机的ip地址使手机和电脑在同一网段
4、完成以上配置就可以用电脑查看手机访问的网页源码了
2、scrapy项目部署到scrapyd
1、首先保证电脑有python和pip
- 在电脑上cmd输入以下命令安装相应的包:
pip install scrapyd
pip install scrapyd-client
- 安装完成后,在cmd中启动命令:
scrapyd
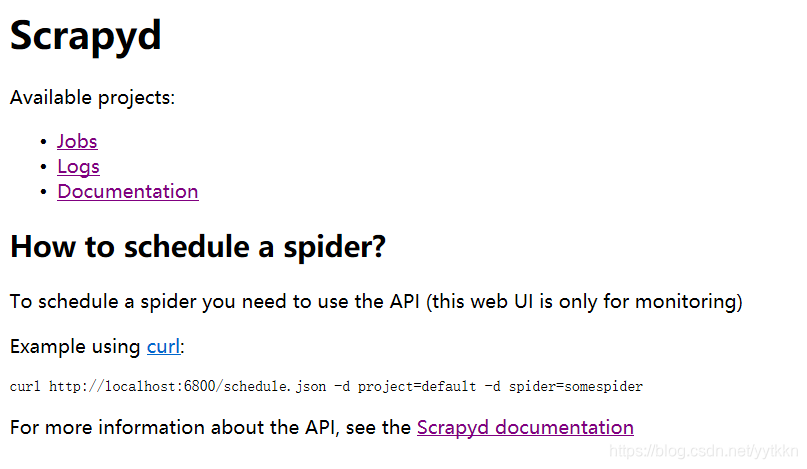
在浏览器中输入:http://localhost:6800/,如果出现下面界面则表示启动成功
2、选择自己的一个scrapy项目
- 打开scrapy项目,有个scrapy.cfg文件,按如下进行配置:
[settings]
default = dingdian.settings
# target名
[deploy:dingdian]
# 服务器地址
url = http://127.0.0.1:6800/
# 项目名
project = dingdian
- 找到python环境下的scrapy-deploy文件复制到与scrapy.cfg文件同一目录,同时在文件夹中创建如图所示的文件scrapy-deploy.bat:
scrapy-deploy.bat:

@echo off
# python的路径
F:\pycharm\anaconda\python.exe
# 文件的路径
F:\pycharm\anaconda\envs\scrapy\Scripts\scrapyd-deploy %*
- 然后在cmd中输入:
python scrapyd-deploy –l:查看是否扫描到项目
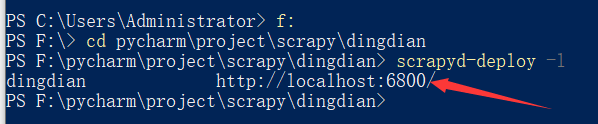
- 出现上面所示的结果表示已经扫描到了爬虫,接下来就是编译爬虫:
scrapyd-deploy 部署名 -p 项目名
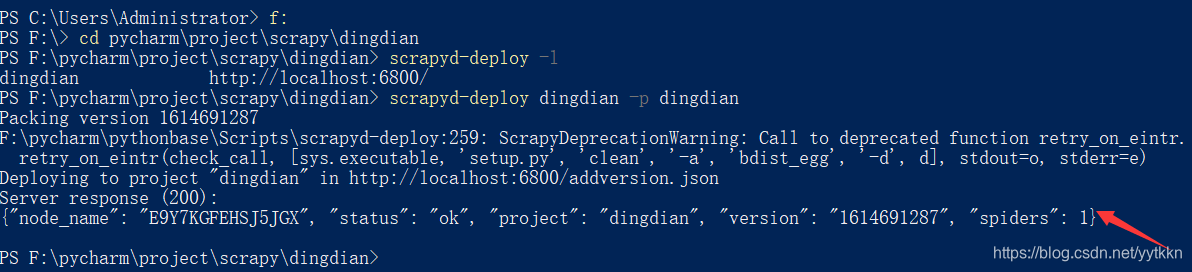
- 最后部署爬虫到scrapyd网页上:
curl http://localhost:6800/schedule.json -d project=项目名 -d spider=爬虫名

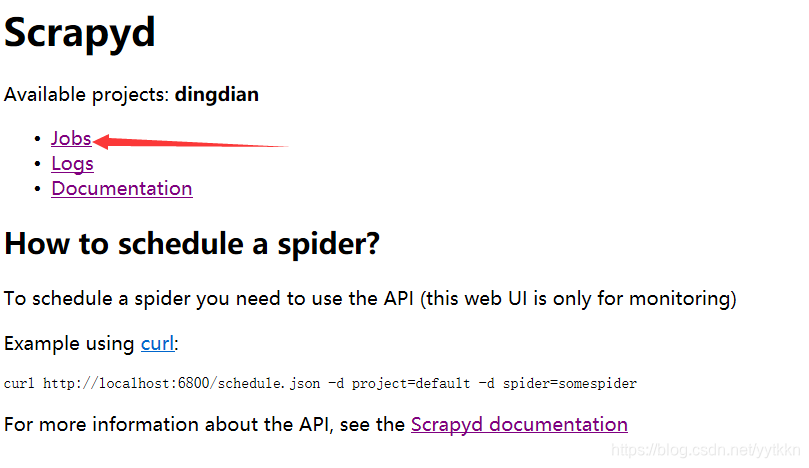
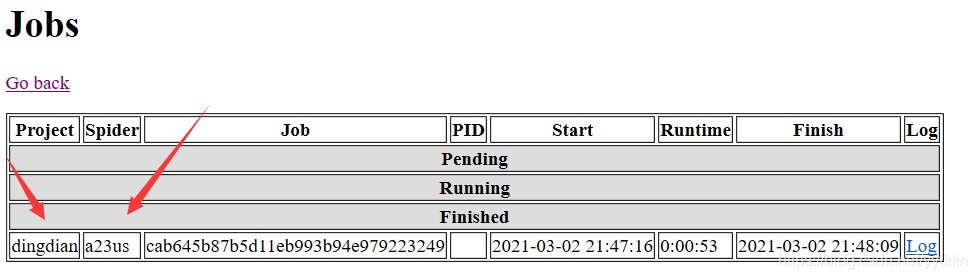
3、查看部署是否成功
在浏览器输入网址:http://localhost:6800
3、scrapy和gerapy部署网络爬虫
- Gerapy可视化的爬虫管理框架,使用时需要将Scrapyd启动,挂在后台,在上面的srapyd配置完成之后,就可才以部署gerapy,gerapy基于Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发
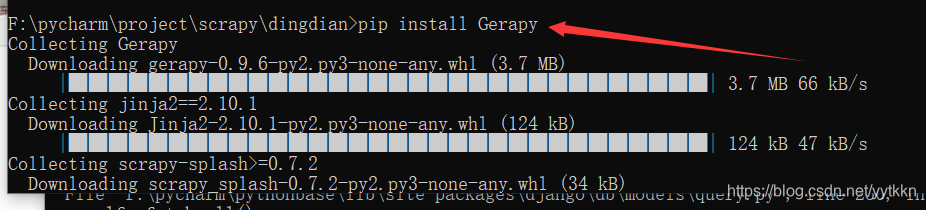
1、首先安装gerapy,然后配置相关信息
- 安装输入:pip install gerapy
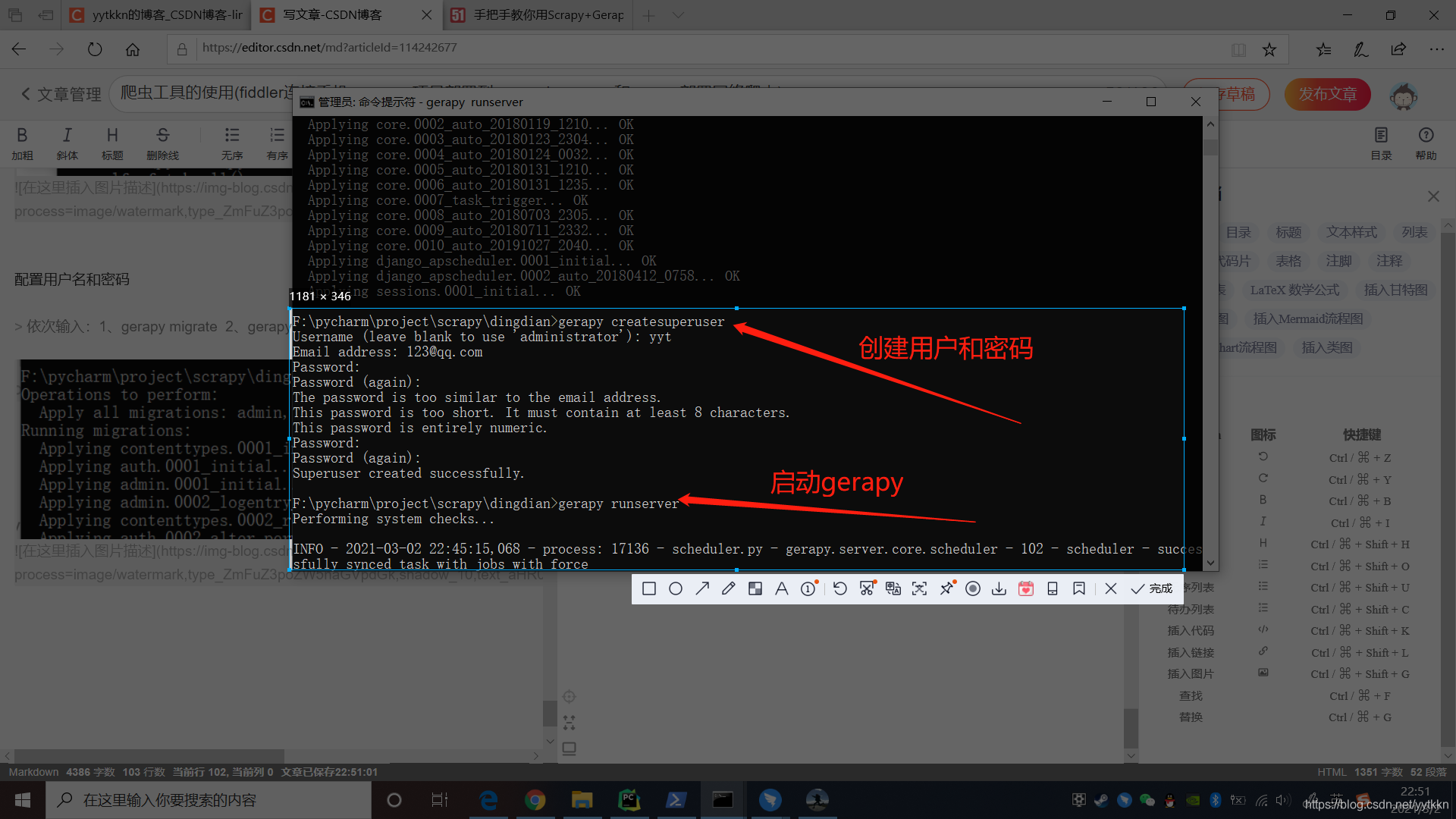
配置用户名和密码
依次输入:1、gerapy migrate 2、gerapy createsuperuser

2、输入网址打开gerapy
- 输入创建的用户名和密码


2、在gerapy可以根据自己的需求进行爬虫的管理
创建主机,创建爬虫,然后创建项目关联主机和爬虫