本章的目的是开发一个应用程序,使用深度传感器的输出实时检测和跟踪简单的手势。该应用程序将分析每个已捕捉的帧。并执行以下任务。
手部区域分割:通过分析Kinect传感器的深度图输出,在每一帧中提取用户的手部区域,这是通过阈值化、应用一些形态学操作,并找到相连组件来完成。
手形分析:将通过确定轮廓、凸包和凸缺陷来分析分割后的手部区域的形状。
手势识别:将根据手部轮廓的凸缺陷确定伸展手指的数量,并相应地对手势进行分类(没有伸展的手指时,对应的就是拳头;有5根伸展的手指则对应张开的手)
我们先设计一个函数,该函数将从传感器读取一帧并将其转换为所需的格式,然后返回该帧以及一个成功状态,如下所示:
def read_frame(): -> Tuple[bool,np.ndarray]:
该函数包括以下执行步骤
(1)捕获frame,如果未捕捉到帧,则终止函数
frame,timestamp = freenect.sync_get_depth()
if frame is None:
return False,Nonesync_get_depth方法可同时返回深度图和时间戳。默认情况下,深度图为11为格式。传感器的后10位用于描述深度,当第一位等于1时,表示距离估计不成功。
(2)将数据标准化为 8 位精度格式是一个好主意,因为11位格式不适用于cv2.imshow的可视化。我们可能要使用一些不同格式返回不同的传感器
np.clip(depth,0,2**10-1,depth)
depth>>=2- 首先,将
depth数组中的值限制在0到1023的范围内。 - 然后,将
depth数组中的每个值除以4,并将结果存储回depth数组。
(3)最后将图像转化为8位无符号整数数组,并返回结果。
return True,depth.astype(np.uint8)现在,depth图像可以按以下方式可视化。
cv2.imshow("depth",read_frame()[1])使用与OpenNI兼容的传感器
在此应用程序中,为了使用兼容OpenNI的传感器而不是Kinect3D传感器,必须完成以下操作
(1)创建一个视频捕获,以连接到与OpenNI兼容的传感器
device = cv2.cv.CV_CAP_OPENNI
capture = cv2.VideoCapture(device)(2)将输入帧大小更改为标准的视频图形阵列(VGA),分辨率(640*480像素)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH,640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT,480)(3)在前面我们设计了read_frame函数,该函数可使用freenect访问Kinect传感器。为了从视频捕获中读取深度图像,在此必须将read_frame函数修改为以下形式
def read_frame():
if not capture.grab():
return False,None
return capture.retrieve(cv2.CAP_OENNI_DEPTH_MAP)这里我们使用了grab和retrieve而不是方法read方法,原因是当我们需要同步一组摄像头或多头摄像机(如Kinect)时,cv2.VideoCapture的read方法不合适。
当我们需要同步一组摄像头时,可以在某个时刻使用grab方法从多个传感器捕获帧,然后使用retrieve方法检索感兴趣的传感器的数据,例如,在你自己的应用程序中,你可能还需要检索BGR帧,这可以通过将cv2.CAP_OPENNI_BGR_IMAGE传递给retrieve方法来完成。
运行应用程序和主函数例程
chapter2.py脚本负责运行该程序,它首先导入以下模块
import cv2
import numpy as np
from gestures import recognize
from frame_reader import read_framerecognize函数负责识别手势
为了简化手部区域分割任务,可以指示用户将手放在屏幕中央。为了提供视觉帮助
我们创建了draw_helpers函数
def draw_helpers(img_draw:np.ndarray)->None:
#为了正确定位手部,绘制一些辅助线
height,width = img_draw.shape[:2]
color = (0,102,255)
cv2.circle(img_draw,(width//2,height//2), 3,color,2)
cv2.rectangle(img_draw,(width//3,height//3),
(width*2//3,height*2//3),color,2)所有的繁琐的工作都是由main函数完成的,如以下
def main():
for _,frame in iter(read_frame,(False,None)):
#该函数在Kinect(动作捕捉识别器)的灰度帧上进行迭代,并在每次迭代中涵盖以下步骤
#使用recognize函数识别手势,还函数将返回已伸展手指的估计数和带注解的BGR彩色图像
num_fingers,img_draw = recognize(frame)
#在带注解的BGR图像上调用drwa_helpers函数,以便为手的位置提供视觉帮助
draw_helpers(img_draw)
#main函数在带注解的frame上绘制手指的数量,使用cv2.imshow显示结果,并设置终止条件
#如:
#输出图像上已经伸展的手指数
cv2.putText(img_draw,str(num_fingers),(30,30),#在图像上添加文本显示
cv2.FONT_HERSHEY_SIMPLEX , 1,(255,255,255))
cv2.imshow("frame",img_draw)
#按ESC退出
if cv2.waitKey(10) ==27:
break接下来实现recognize函数来跟踪手势
实现跟踪手势
recognize函数将处理从原始灰度图像到已识别手势的整个流程。它将返回手指的数量和帧指示图
(1) 通过分析深度图提取用户的手部区域,并返回手部区域蒙版
def recognize(img_gray:np.ndarray) ->Tuple[int,np.ndarray]:
#划手部区域
segment = segment_arm(img_gray)(2) 在手部区域蒙版上执行contour分析,然后返回在图像中找到的最大轮廓(contour)和任何缺陷(defects)
#找到分段区域的凸包
#并根据该区域找到凸包
contour,defects = find_hull_defects(segment)
(3) 根据找到的轮廓和凸缺陷,检测图像中伸展的手指的数量(num_fingers).然后,使用蒙版(segment)图像作为模板创建指示图像(img_draw),并使用contour和defects点对其进行注释
img_draw = cv2.cvtColor(segment,cv2.COLOR_GRAY2RGB)
num_fingers,img_draw = detect_num_fingers(contour,defects,img_draw)
(4) 返回估计的手指的伸展数(num_fingers)以及包含注解的输出图像(img_draw)
return num_fingers,img_draw接下来将讨论如何完成手部区域的分割
了解手部区域的分割
通过组合有手部的形状和颜色的信息,我们可以自动检测手臂,且设计其不同的复杂程度,当然在恶劣的环境下或当用户戴手套使,使用肤色作为在视觉场景中发现手的决定性特征可能会严重失败。或者可以通过深度图中的形状来识别用户的手
找到图像中心区域最突出的深度
一旦用户将手部大致放置在屏幕中心,我们就可以开始查找与手位于同一深度平面上的所有图像像素:
(1) 确定图像中心区域的最突出深度值,最简单的方法使仅查看中心像素的depth值。
width,height = depth.shape
center_pixel_depth = depth[width/2,height/2](2) 创建一个蒙版,其中深度为center_pixel_depth的所有像素均为白色,而所有其他像素均为黑色
import numpy as np
depth_mask = np.where(depth == center_pixel_depth,255,0).astype(np.uint8)当然这个方法不是很可靠,因为他会受到以下因素的影响
1.你的手不会完全平行于Kinect传感器放置
2.你的手不会平放
3.Kinect传感器的值会有噪声
因此,你的手的不同区域将具有稍微不同的深度值
segment_arm的方法采用的方法稍微好一些,它将查看图像中心的一个小邻域,并确定深度的中值
(1) 找到图像帧的中心区域
def segment_arm(frame: np.ndarray,abs_depth_dev: int =14)->
np.ndarray:
height,width = frame.shape
#找到图像帧的中心区域
center_half = 10 #half_width of 21 is 21/2-1
center = frame[height//2 - center_helf:height//2 + center_half,
width//2 - center_half:width//2 + center_half](2) 确定深度的中值med_val
med_val = np.median(center)(3) 现在可以将med_val与图像中所有像素的深度值比较,并创建一个蒙版,其中深度值在特定范围[med_val-abs_depth_dev,med_val + abs_depth_dev]内所有像素均为白色,而所有其他像素均为黑色。
当然由于某些原因,我们需要将像素绘制为灰色
frame = np.where(abs(frame - med_val) <= abs_depth_dev,
128,0).astype(np.uint8)可以看见分割的蒙版并不平滑,特别是,它在深度传感器无法做出预测的点处还包含小孔,接下来我们将介绍如何应用形态学闭合操作来平滑分段蒙版。

应用形态学闭合操作平滑蒙版
分割的一个常见问题就是会出现小孔,这些小孔可以通过形态学上的开放和闭合来解决,开放时,它会从前景中删除小对象,而闭合时则会删除小孔。
这意味着我们可以通过使用较小的3*3像素内核应用形态学闭合来消除蒙版中很小的黑色区域
kernel = np.ones((3,3),np.uint8)
frame = cv2.morphologyEX(frame,cv2.MORPH_CLOSE,kernel)这行代码使用了 OpenCV 库中的 cv2.morphologyEX 函数来对图像 frame 进行形态学操作,具体来说是闭运算(closing operation)。闭运算是一种常用的图像预处理技术,用于填充前景物体内部的小孔和连接邻近的物体,同时保持物体的总面积大致不变。
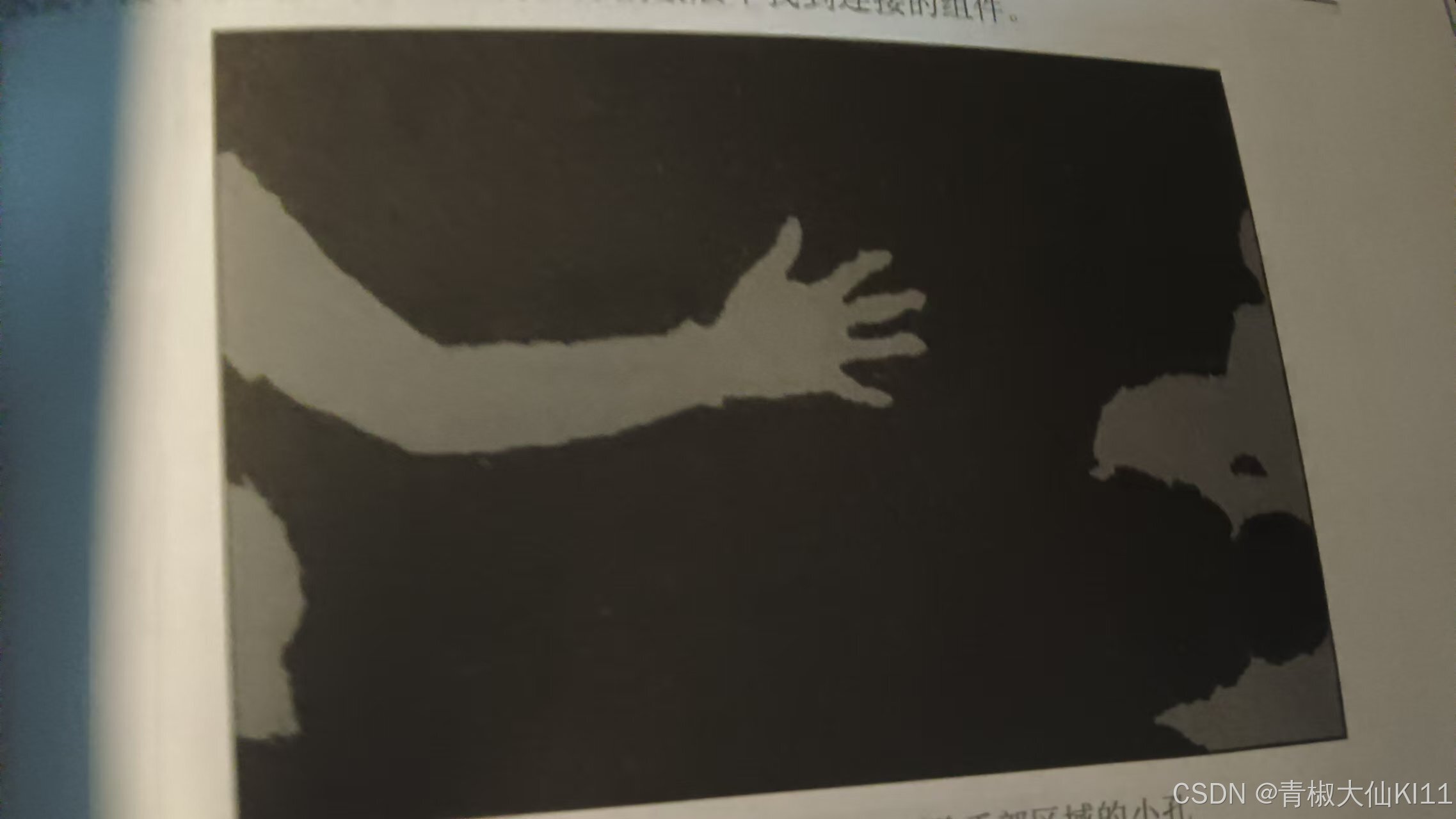
可以看见该蒙版仍然包含不属于手臂的区域,例如左侧似乎出现了膝盖,而右侧可能是一些家具。
这些物体恰好和手臂出现在同一深度层上,如果可能的话,现在可以将深度信息与另一个描述符(手形分类器)结合使用,以剔除所有非皮肤信息。
在分割蒙版中查找连接的组件
我们已经知道中心区域属于手,对于这种情况,我们可以简单地应用cv2.floodfill来查找所有连接在一起的图像区域。
在此之前,我们要确定floodfill填充的种子点属于正确的蒙版区域。这可以这可以通过种子点分配一个分配128灰度值来实现,但是,我们还想确保中心的像素不会·由于任何巧合而位于形态操作无法闭合的空腔内。
因此,我们可以设置一个很小的7*7像素区域,其灰度值为128.
samll_kernel = 3
frame[height // 2 - small_kernel:height // 2 + small_kernel,
width // 2 - small_kernel:width // 2 + small_kernel] = 128
因为洪水填充FloodFilling以及形态学操作具有潜在的危险,因此opencv需要指定一个蒙版,以免洪水淹没整幅图像。此蒙版的宽度和高度必须比原始图像多2个像素,并且必须与cv2.FLOODFILL_MASK_ONLY标志结合使用。
将洪水填充限制在图像的一个很小的区域或特定轮廓可能非常有帮助,这样就不必连接两个本来据不应该连接的相邻区域。
尝试将mask完全设为黑色
mask = np.zeros((height + 2,width + 2),np.uint8)
然后将泛填充应用于中心像素,并将所有连接区域绘制为白色。
flood = frame.copy()
cv2.floodFill(flood,mask,(width // 2,height // 2),255,
flags = 4| (255<<8))到了这里就理解为什么要灰色蒙版了,现在我们有一个蒙版,其中包含白色区域(手臂和手)、灰色区域(除手臂和手之外其他在同一深度平面上的物体或对象)和黑色区域(所有区域),有了这些设置后,我们可以轻松应用一个简单的二进制threshold(阈值) 来仅突出显示预分段深度平面的相关区域。
ret , flooded = cv2.threshold(flood,129,,255,cv2.THRESH_BINARY
#进行二值化处理生成的蒙版将如图

接下来将生成的分割蒙版返回到redognize函数,在其中它将用作find_hull_defects函数的输入,以及用于绘制最终输出图像(img_draw)的画布。
find_hull_defects 函数将用于分析手的形状,以便检测与手相对应的图缺陷。
执行手形分析
确定分割后的手部轮廓
使用cv2.findContours,该函数作用在二进制图像上,并返回被认为是轮廓的一部分的一组点。
由于图像中可能存在多个轮廓,因此可以检索轮廓的整个层次结构。
检测图像中轮廓的凸包缺陷函数
def find_hull_defects(segmnet: np.ndarray) -> Tuple[np.ndarray,np.ndarray]:
contours,hierarchy = cv2.findContours(segment,cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)凸包绘制原理:Graham 扫描法
- 首先选择 y 方向上最低的点作为起始点
p0。 - 然后以
p0为原点,建立极坐标系,做逆时针极坐标扫描,依次添加凸包点p1,p2...pn(排序顺序根据极坐标角度大小)。 - 若当前扫描点与下一个点构成的直线为逆时针转向,且转角大于 180°,则将该点添加到凸包点集合,否则忽略。
我们不知道要寻找哪个轮廓,因此必须要做一个假设来清理轮廓结果。
max_contour = max(contours, key=cv2.contourArea)
我们找到的轮廓可能仍然有太多的角,为了解决该问题,可以用相似的contour近似轮廓,近似值小于轮廓周长的1%
epsilon = 0.01 * cv2.arcLength(max_contour,True)
max_contour = cv2.approxPolyDP(max_contour,epsilon,True)个过程的目的是减少轮廓点的数量,同时保持轮廓的基本结构。
查找轮廓区域的凸包
凸包基本上是轮廓区域的包裹,可以直接从最大轮廓线(max_contour)获得凸包。
hull = cv2.convexHull(max_contour,returnPoints = False)围绕分段的手部区域以黄色线绘制凸包

寻找凸包的凸缺陷
可以通过查看最大轮廓(max_contour)和相应的凸包(hull)来发现这些凸缺陷
defects = cv2.convexityDefects(max_contour,hull)返回最大轮廓和凸包
return max_contour,defects现在我们找到了凸缺陷,接下来需要了解如何使用凸缺陷执行手势识别。
执行手势识别
接下来我们将区分不同凸缺陷情形。
要区分凸缺陷的原因,技巧是查看凸缺陷中距凸包点最远的点与凸缺陷的起点和终点之间的角度。
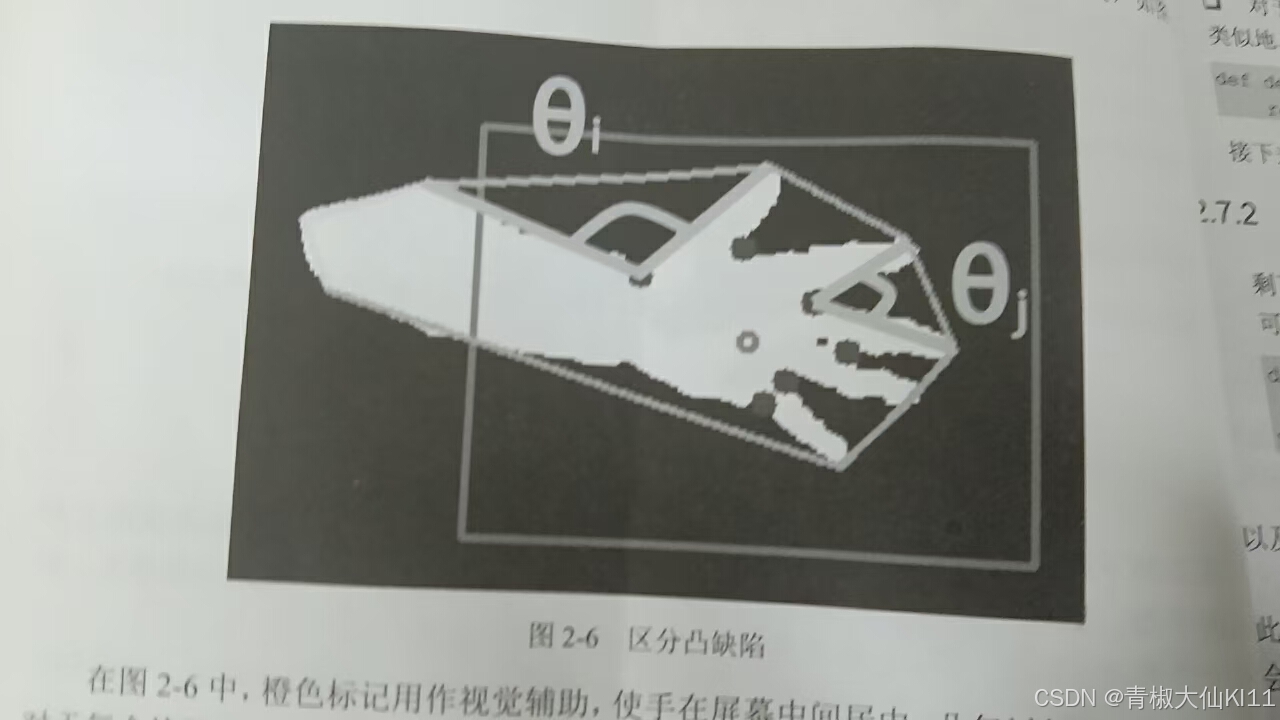
我们需要一个实际函数来计算两个任意值之间的角度
def angle_rad(v1,v2):
return np.arctan2(np.linalg.norm(np.cross(v1,v2)),np.dot(v1,v2))此方法使用叉积来计算角度

计算两个向量v1,v2之间的角度的标准是计算它们的点积,然后将其除以v1的范数和v2的范数,但是此方法有两个缺点:
1.如果v1 的范数或v2的范数为零,则必须手动避免被零除。
2.对于小角度,该方法返回的结果相对不太准确。
类似的我们提供了一个简单的函数来将角度从度转换为弧度
def deg2rad(angle_deg):
return abgle_deg/180.0*np.pi接下来我们将讨论如何根据伸出的手指迭代数量对手势进行分类。
根据伸出的手指数对手势进行分类
剩下要做的是根据伸出的手指实例的数量对手势进行分类
def defect_num_fingers(contour:np.ndarray,defects:np.ndarray,
img_draw:np.ndarray,thresh_deg:float=80.0)->
Tuple[int,np.ndarray]:该函数接受检测到的轮廓,凸缺陷,用于绘图的画布以及可以用作阈值的临界角度,以判断凸缺陷是否由伸出的手指引起。
(1) 关注一下特殊情况,如果没有发现任何凸缺陷,则意味着我们可能在凸包计算过程中犯了一个错误,或者帧中根本没有伸出的手指,因此返回0作为检测到的手指的数量。
if defects is None:
return [0,img_draw](2) 我们还可以进一步拓展这一思路,由于手臂通常比手或拳头更苗条一些。因此可以假定手的几何形状总是会产生至少两个凸缺陷。因此,如果没有其他缺陷,则意味着没有伸展的手指。
if len(defects)<=2:
return [0,img_draw](3) 现在我们已经排除了所有特殊情况,接下来就可以开始计算真手指了。如果有足够数量的缺陷,我们将在每对手指之间发现一个缺陷,因此获得准确的数量(num_finger),我们应该从1开始计数
num_fingers = 1(4) 我们开始遍历所有缺陷,对于每个凸缺陷,我们将提取3个点并绘制其凸包以用可视化
#凸缺陷形状(num_defects,1,4)
for defect in defects[:,0,:]:
#每个凸缺陷都是一个包含4个整数的数组
#前3个分别是起点。终点和最远点的索引
start,end,far = [contour[i][0] for i in defect[:3]]
#绘制凸包
cv2.line(img_draw,tuple(start),tuple(end),(0,255,0),2)(5) 计算从far到start以及从far到end的两条边之间的角度,如果角度小thresh_deg度数,则意味着正在处理的凸缺陷很可能是由伸出的手指引起的。在这种情况下,我们要递增检测到的手指的数量,并用绿色绘制该点。否则就用红色绘制。
#如果角度小于thresh_deg度数
#则凸缺陷属于两根伸出的手指
if angle_rad(start - far,end - far) < deg2rad(thresh_deg):
#手指数递增1
num_fingers += 1
#将点绘制为绿色
cv2.circle(img_draw,tuple(far),5,(0,255,0),-1)
else:
#将点绘制为红色
cv2.circle(img_draw,tuple(far),5,(0,0,255),-1)
(6) 遍历所有凸缺陷
return min(5,num_fingers),img_draw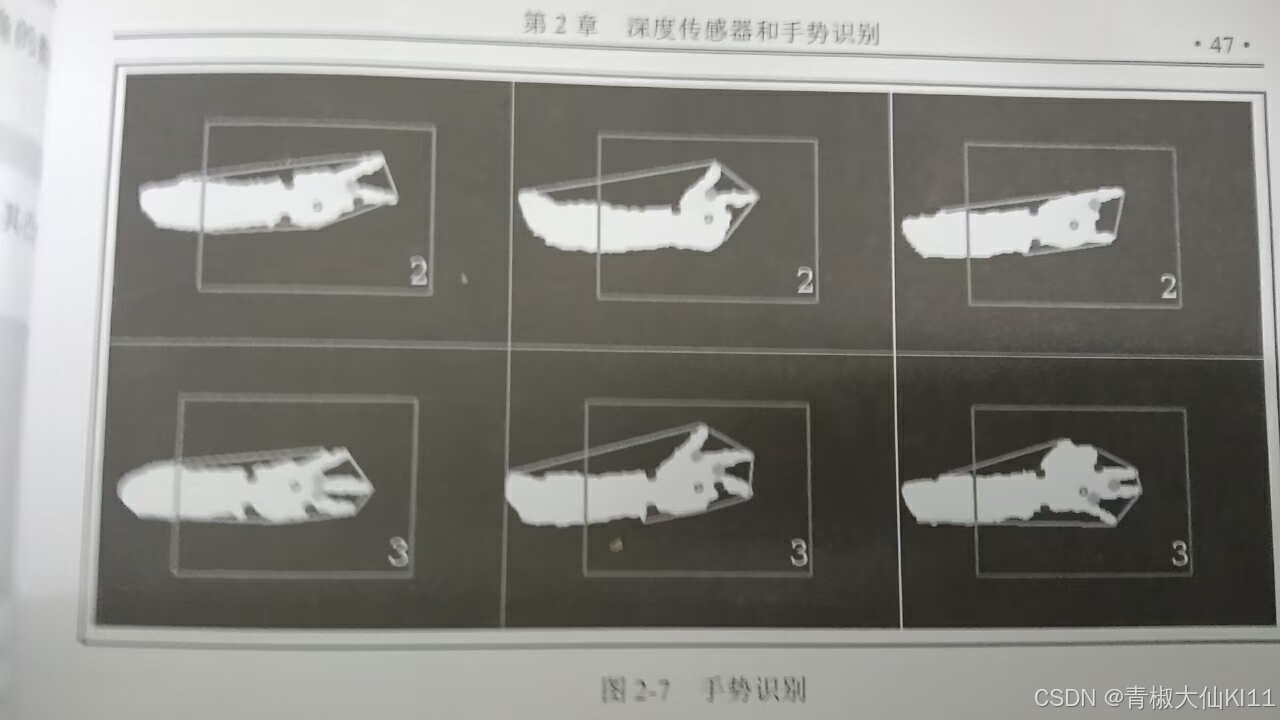
我们的应用程序能够在各种手部形状中检测到正确的伸展手指数量。伸展手指之间的缺陷点可以通过该算法轻松分类,而其他缺陷点则可以成功忽略。