前言
导语
本教使用ChatGPT进行辅助编写,部分知识点根据ChatGPT提供的解释进行归纳总结,如有描述不恰当的地方请合理指出,部分观点参考了UP主 [秋葉aaaki] [青龙圣者] [Mr_日天]。
以下内容是通过本人自身理解并总结编写出的,同时也是初步接触训练模型,主要是以美术视角出发来进行讲解,目的就是可以让不理解训练概念和代码指令的小伙伴更容易上手Lora模型训练。(如有问题欢迎大家一起讨论,知识探索的进步脚步终将永不停止。)
开始前请先阅读以下内容
-
训练开始前请先确认自己电脑的显卡是否为N卡,推荐30系及以上的显卡为最佳。
-
如果显卡不支持可以用任意的云端上面的。
-
本地训练推荐秋叶大佬的一键训练脚本包,是目前最直观和最容易理解的训练方。
-
训练脚本
-
安装批量打标签软件:BooruDataset
-
安装Notepad3文本软件方便看代码指令
本文涉及模型、插件下载请扫描免费获取哦~安装包都放在下方请自取:

为什么要训练Lora模型?
-
节省训练时间:LORA模型的低层模型已经在大规模的基准数据集上训练过了,因此可以利用这些已经学到的特征来加速新的训练过程。
-
提高准确性:使用LORA模型微调,可以在保持低层模型的特征提取能力的同时,针对具体任务进行优化,从而提高模型在特定任务上的准确性。
-
加快创作速度:LORA 模型可以快速生成想法的效果,这些结果可以为创作者提供新的创作灵感,开拓新的设计思路和方向,从而更好地实现自己的设计目标。
-
可迁移性:可迁移性意味着可以在不同任务之间共享底层模型,从而减少重复训练,提高工作效率,使其能够更快速地从一个任务转移到另一个任务。
Lora模型训练流程

lora模型训练节点图
01
训练前期准备
Python安装
安装包在秋叶大佬的一键包里面就有,默认安装路径即可
1.安装python勾选Add PATH,再点Install Now.

2.安装完毕后出现框内提示就点击,没有则不用管。
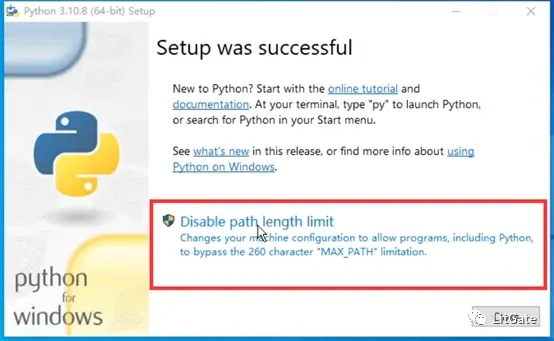
Windows PowerShell设置
1.右键Windows菜单图标打开Windows PowerShell(管理员模式)

2.复制Set-ExecutionPolicy -ExecutionPolicy RemoteSigned进去回车
3.出现下面选择栏按[A]回车
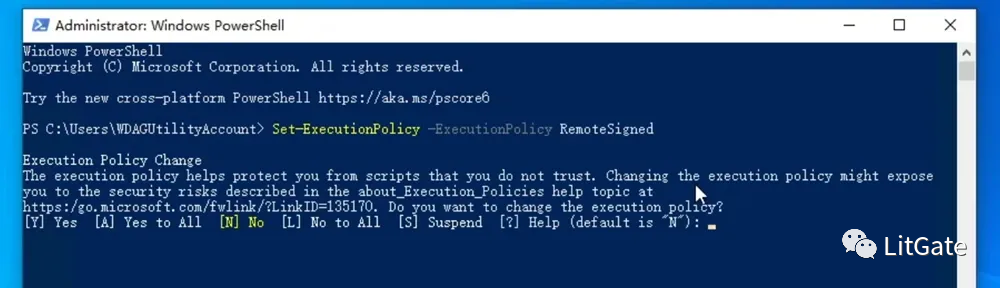
训练脚本更新
1.解压lora-scripts压缩包后,点击强制更新.bat脚本

2.再用鼠标右键install-cn.ps1文件点击PowerShell模式运行,进行环境依赖更新。
02
训练模型相关知识点
*这一节只需要对训练模型的概念进行一个简单的了解即可
在模型训练中需要关注的几个方面
-
全面充分的采集训练素材:例如在角色训练素材中,应该有各种角度、表情、光线等情况下的素材,这样才能确保模型具有较好的泛化性。
-
图像预处理:对训练素材进行分辨率调整、裁切操作,并对训练集进行打标签处理。
-
参数调优:尽可能把训练时长控制在半小时左右,时间过长容易导致过拟合,通过调整等参数控制训练时长。
-
观察学习曲线:通过观察学习曲线来对训练素材、训练参数进行调整。
-
过拟合&欠拟合处理:测试训练好的模型观察过拟合和欠拟合的问题,再进一步通过调整训练素材和正则化等手段来优化。
综上所述,模型训练中需要关注的几个重点,需要结合具体的任务需求和数据特点来进行调整和优化,以达到最优的训练效果。
接下来需要简单了解一下训练模型中的几个概念名词:
-
过拟合&欠拟合
-
泛化性
-
正则化
过拟合&欠拟合

在这个问题上ChatGPT从美术角度给出的解释:

总结:过拟合和欠拟合都是不好的现象,我们需要加以控制,让模型最终得到我们想要的效果。
解决方法:在模型训练中需要不断对训练集、正则化、训练参数、进行调整。过拟合可以尝试减少训练集的素材量,欠拟合就增加训练集的素材量。
泛化性
ChatGPT从美术角度给出的解释:

总结:泛化性不好的模型很难适应其他风格和多样性的创作力。可以通过跑lora模型生图测试来判断泛化性是否良好。
解决办法:跟解决过拟合欠拟合问题一样,从训练集、正则化、训练参数、进行调整。
正则化
ChatGPT从美术角度给出的解释:

总结:正则化是解决过拟合和欠拟合的情况,并提高泛化性的手段。
相当于给模型加一些规则和约束,限制要优化的参数有效防止过拟合,同时也可以让模型更好适应不同情况的表现,提高泛化性。
03
训练集准备工作
训练素材处理
选取角色人物凝光来做本次教程素材(角色素材比较容易学习上手,也能对模型训练有一个初步的全面了解)

如果是角色训练集控制在20-50张图左右,太多会导致过拟合
如果是角色尽可能收集到头像,正视图,侧视图,背面等多角度的无背景素材,增加不同画风的素材可以提高模型应对不同风格的手段,画风训练素材数量可以提高到更多。
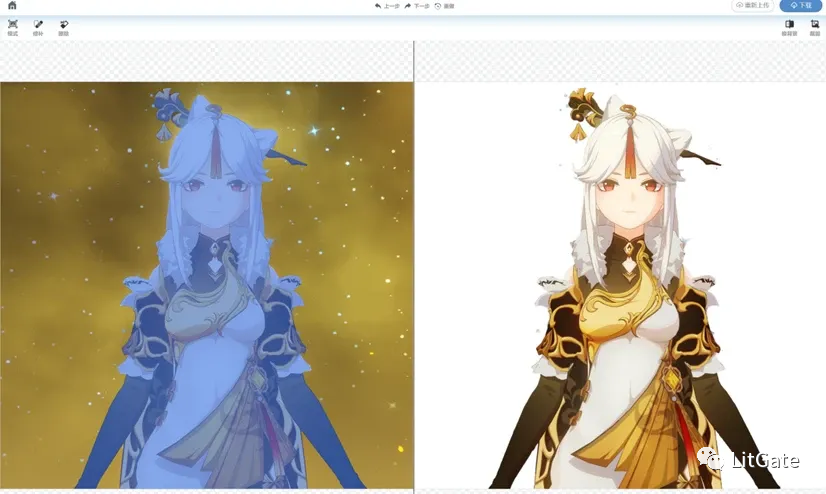
**素材可以少,但是质量一定要高;角色背景最好是白底网站上面可以选择换背景颜色
推荐一个自动扣图的网站:https://pickwant.com/home
图片批量裁切
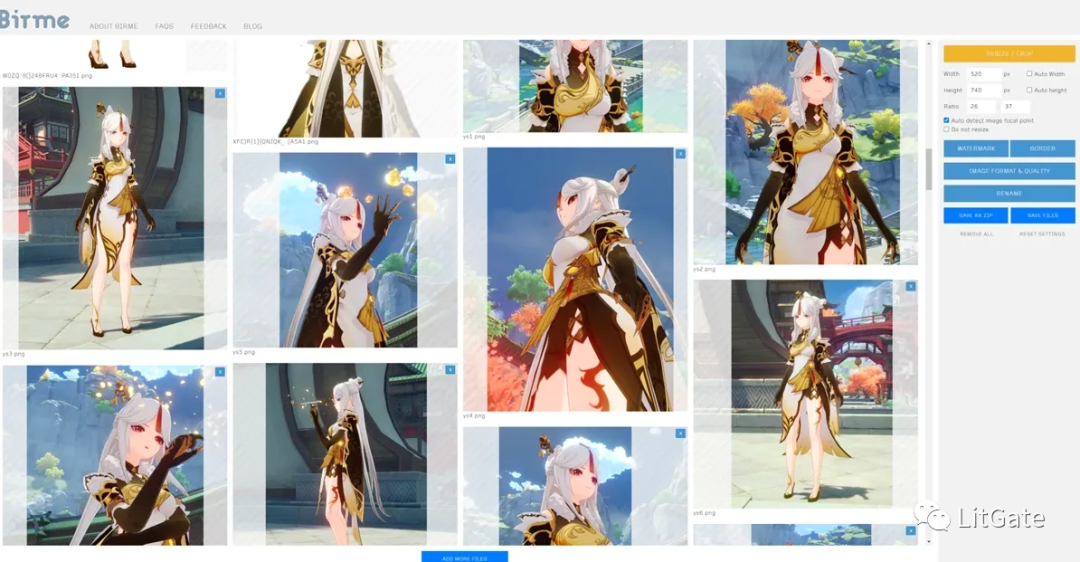
之后利用工具网站把所有图片批量进行统一分辨率裁切
-
分辨率需要是64的倍数
-
分辨率预先处理好基本可以直接扔进AI进行训练不用再做分割处理了
-
尺寸越大越吃显存,可能会出现报错学习卡死等问题
-
地址:https://www.birme.net
图像预处理
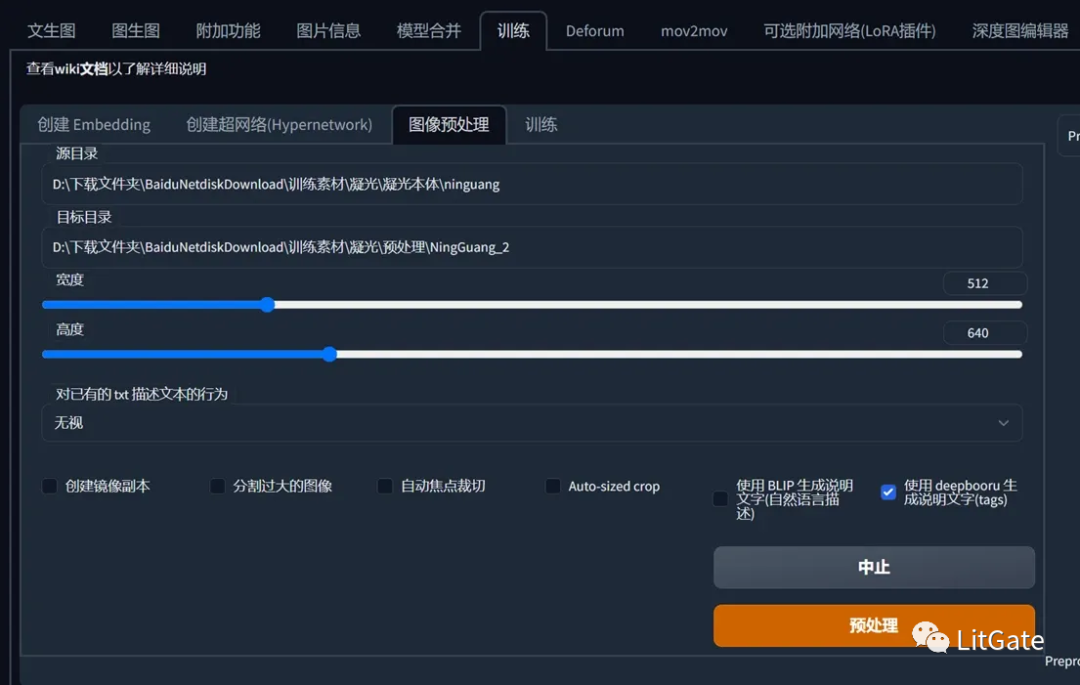
把训练素材文件路径扔到Stable Diffusion的训练模块下图像预处理功能,勾选生成DeepBooru进行生成tags标签。
打标签
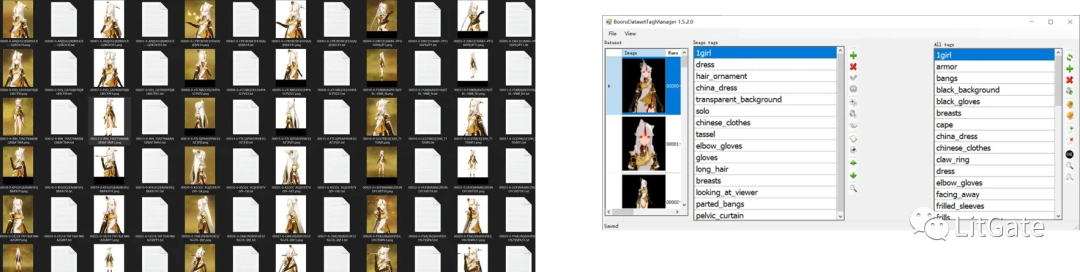
*进入批量打标签软件点击上方File的Load folder后选择处理好的训练集路径。
批量打标签软件BooruDataset基本操作:
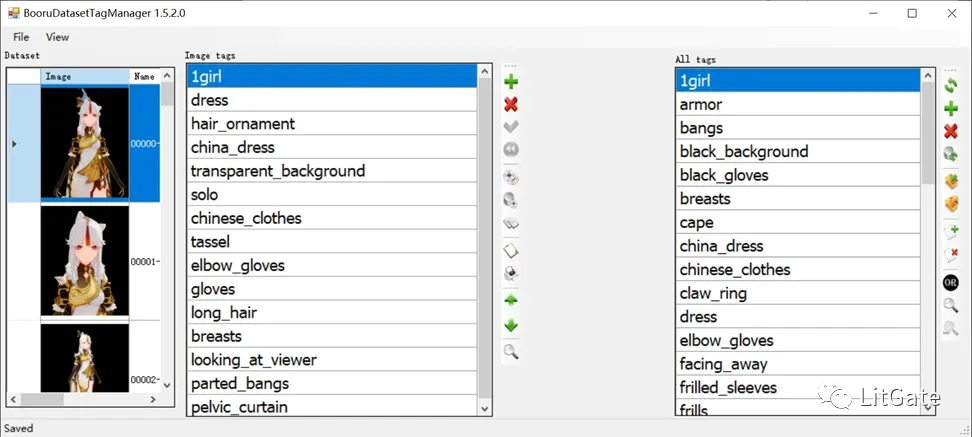
-
点击上方的File–Load folde载入训练素材路径
-
左边一栏是单张编辑右边一栏是批量编辑
-
是增加标签 X是删除标签 ✔是保存
-
最后修改完标签点击File—Save all changes保存全部标签
关于打标签详细解释
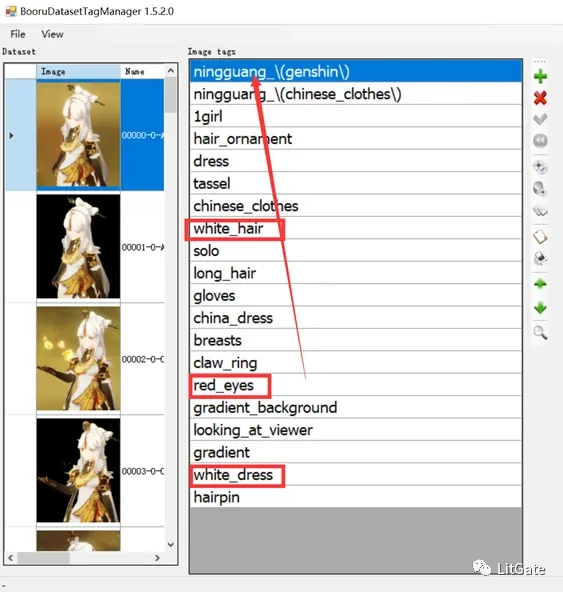
1.整合概念标签
例如,你要训练一名角色,添加名称后,需要删除红框内描述此概念的部分特征标签。
这个操作的含义是将特征都融入到你的lora本身,提高lora模型调用效率,更精准的复原角色的发型发色瞳色等生理特征,同时也减少调用词条的数量。
-
删除的tag会被固化在模型当中
-
同时也为了防止将基础模型中的相同tag引导到你的lora,导致过拟合
-
尽可能添加一个不存在的标签用于调度你训练的lora模型
-
如果是角色建议只删除生理特征标签,保留着装\配饰\装备等
2.如果从泛化性角度出发,可以保留角色特征标签。但是会导致调用困难,需要输入大量的tag用于调用。
两种打标签的方法
1. 保留全部标签:
-
优势:效率快省时省力的训练出模型,拟合度提高,且过拟合出现的情况是最低的。
-
缺陷:风格会变化过大,tag调用比较困难,训练时需要把epoch提高时间成本会被拉长。
2.剔除部分特征标签:
-
优势:整合成少量的触发词tag后,调用方便,更精准还原角色特征。
-
缺陷:容易导致过拟合,泛化性也会降低,如果标签删太多会导致生成的画面非常固化。
训练文件夹结构规范
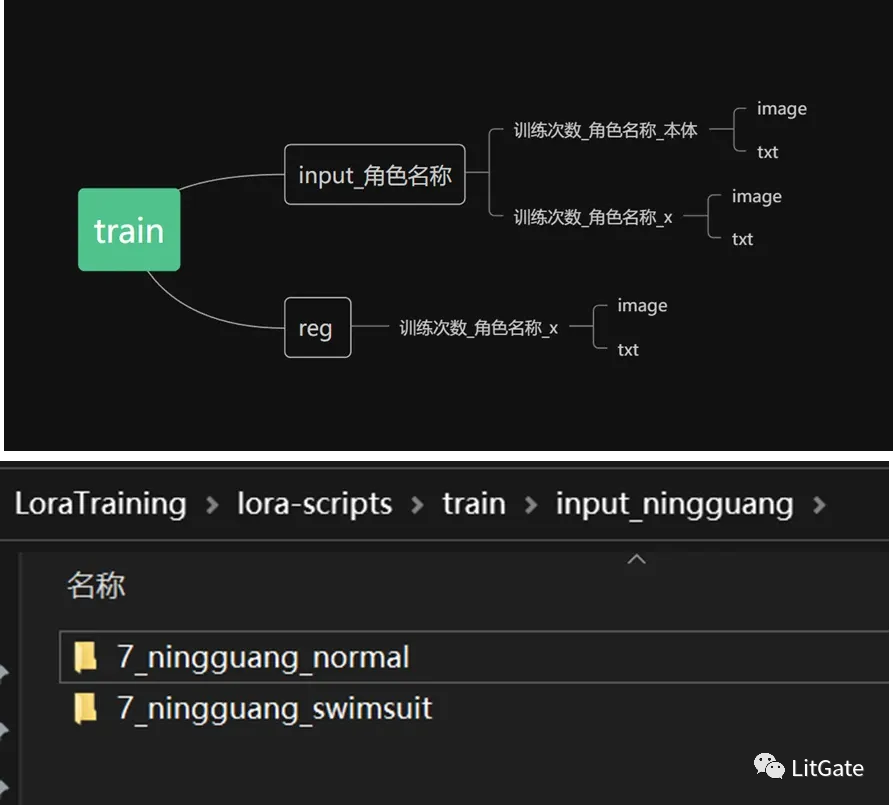
注:这里把概念名称转换成角色名称方便理解,具体概念名称按照需求进行填写,*文件夹命名不能用中文。
-
首先在脚本的LoraTraining目录下新建训练文件夹命名为train
-
如果需要训练多个概念(例如:角色除了本体之外,还要加一个穿着泳装训练素材),这时候就在(input_角色名称)下面再新建一个文件夹,命名写(训练次数_角色名称_泳装)进行文件夹区分。
a.建立步骤
- 在脚本根目录下面建立一个训练文件夹(train)
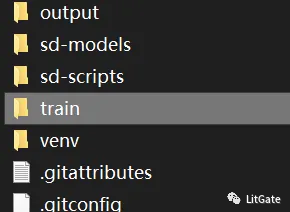
- 在(train)文件夹内建立一个概念文件夹和,一个正则化文件夹(reg),不需要正则化可不建立
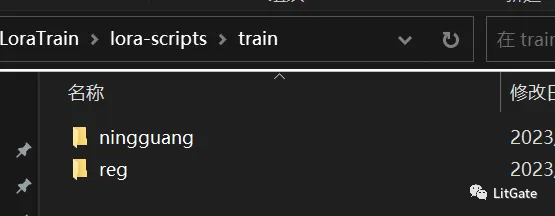
- 在概念文件夹内建立 – 训练素材文件夹(训练素材文件夹前面的需要加“_”你想训练的次数)之后将训练素材放置进去即可。
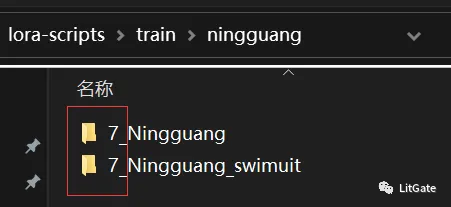
b.正则化文件夹搭建
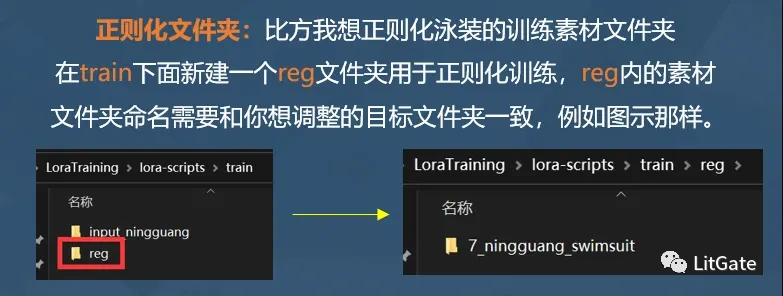
c.正则化素材示意
正则化在深度学习中指的是:给模型加一些规则和约束,限制要优化的参数有效防止过拟合。

正则化素材
【假设我在训练集里面放入了一个泳装角色的训练素材,那么为了防止过拟合的问题,在正则化文件夹内放入一些同样是泳装的图片素材】
可以用SD进行快速生成 *正则化素材不需要生成tag文本文件!!!
正则化素材注意不要过多,不然机器会过多的学习到里面的素材导致跟训练目标角色不一致,*简单来说就是让AI稍微克制一下学习的程度,防止发生过拟合。
在我的理解看来正则化手段是目前控制过拟合问题,最容易理解的一个操作的方法。
04
开始训练
训练脚本讲解
*目前指出的都是常用参数,没有提到的可以不用做修改(如果自己能理解知道怎么去调整也可以,我这里只针对初级快速上手进行讲解。)
在训练脚本根目录下用秋叶提供的文本编辑软件打开train.ps1
具体参数讲解
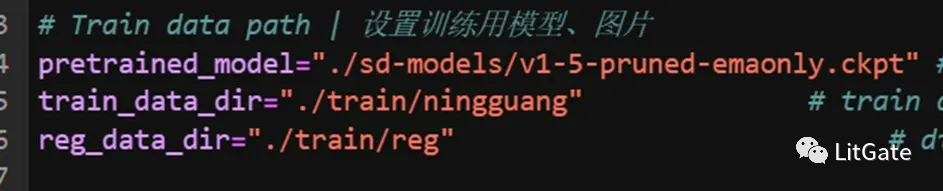
1.训练素材路径设置参数:
-
pretrained_model:底模型路径,底模型一般选择SD 1.5,底模型不能选择过大的完整模型,选择小模型否则内存会爆。
-
train_data_dir:训练素材路径
-
reg_data_dir:正则化素材路径,没有则不用填。
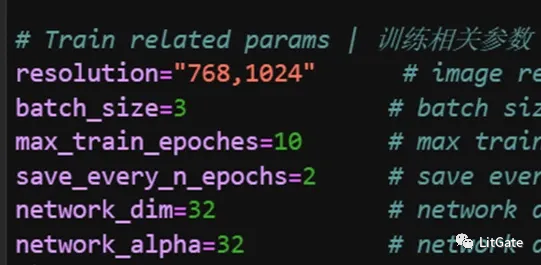
2.训练参数:
-
resolution:图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
-
batch_size:指的是在神经网络训练中,一次性送入模型的样本数。
-
(通俗地说,就像做菜时一次性放入多少食材一样,batch_size决定了一次送入多少样本来训练模型。较大的batch_size可以加速训练,但会占用更多的内存资源)
-
max_train_epoches:最大训练的epoch数,即模型会在整个训练数据集上循环训练这么多次。
-
(假设最大训练epoch为10,即训练过程中将会进行10次完整的训练集循环。这个参数可以根据实际情况进行调整,以达到更好的模型效果)
-
network_dim:常用 4~128,不是越大越好,这个参数如果是训练画风的话可以给高一些,训练角色物件等不需要调整。
3.学习率(learning rate)
学习率是训练神经网络时一个很重要的超参数,控制着权重的更新速度。这个参数越大,权重更新的幅度就越大;反之,越小更新的幅度越小。因此,设置一个合适的学习率可以使得训练过程更加稳定、收敛速度更快。
ChatGPT从美术角度给出的解释:

学习率参数:

*学习率的部分如果不理解可以不做修改
-
lr: 学习率,用来控制模型每次更新参数时的步长大小。
-
unet_lr: 基本跟lr数值一样即可。
-
text_encoder_lr: 文本编码器的学习率。需要通过实践具体情况来测试更改
-
lr_scheduler: 学习率调度策略,用来控制模型学习率的变化方式。这里提供了五种可选的调度策略,分别是:“linear”,“cosine”,“cosine_with_restarts”,“polynomial”,“constant”,“constant_with_warmup”。基本只用“constant_with_warmup”
-
lr_warmup_steps: 热身步数,仅在学习率调度策略为“constant_with_warmup”时需要设置,用来控制模型在训练前逐渐增加学习率的步数。一般不动
-
lr_restart_cycles: 余弦退火重启次数,仅在学习率调度策略为"cosine_with_restarts"时需要设置,用来控制余弦退火的重启次数。一般不动
这个学习率可以类比为我们学习一门技能的速度,如果学习速度过快,我们可能会错过一些细节或者理解不深刻,类似地,如果学习速度过慢,我们可能会浪费时间或者失去耐性。因此,学习率的大小需要根据具体情况进行调整,以获得最佳的学习效果。
拓展内容
黄金学习率计算方法(玄学)
如果想追求品质最好的模型效果可以参考青龙圣者提出的黄金学习率计算方法,
根据可视化学习曲线图我们可以观测到一个最佳的学习率值,
取最高值除3即可得出一个最佳学习率数值然后填到Lr和unet_lr、text_encoder_l对应的参数上,
这是一个玄学方法,感兴趣的可以自己去深入研究,其目的也是能够让模型最终效果更好。

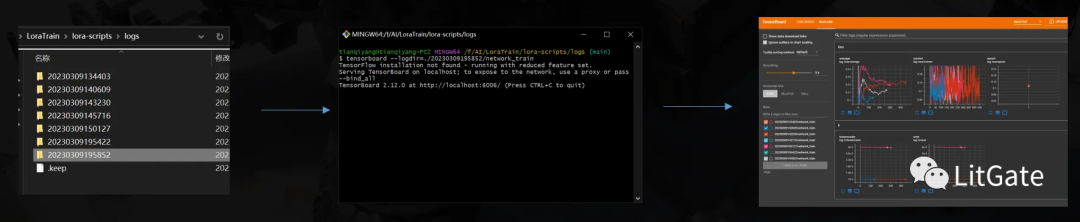
Tensorboard(可视化学习曲线)
首先需要安装GIT: https://git-scm.com/download/win
安装方法:在训练脚本根目录鼠标右键点击Git bash here – 在指令窗口输入 pip install tensorboard 安装依赖
使用方法:首先开始跑第一次训练,跑不跑完都可以,然后找到 LoraTrain\lora-scripts\logs 路径内找到最新时间戳的文件夹名称,在这个文件夹内鼠标右键再次唤出Git bash here指令窗口,输入“tensorboard --logdir=./时间戳/network_train” ,复制出提供的网址到浏览器上即可看到学习曲线图
04
输出设置和优化器设置

-
output_name:模型保存名称
输出的模型名称一定要修改!!!不能默认会报错
-
save_model_as:模型保存格式(一般不动)
优化器设置:
-
use_8bit_adam:开启是1,禁用改为0.
-
use_lion:开启是1,禁用改为0.
(目前效果最好的一个优化器,但如果有正则化素材建议不开。)
开始炼丹
所有参数修改完保存文本文件
最后在脚本根目录下右键选择train.ps1文件—点击PowerShell即可开始跑训练,选择ps1后缀的train文件
05
模型测试
最后从炼丹炉内取最小值的模型为最佳,没有效果再选取最终生成的版本。
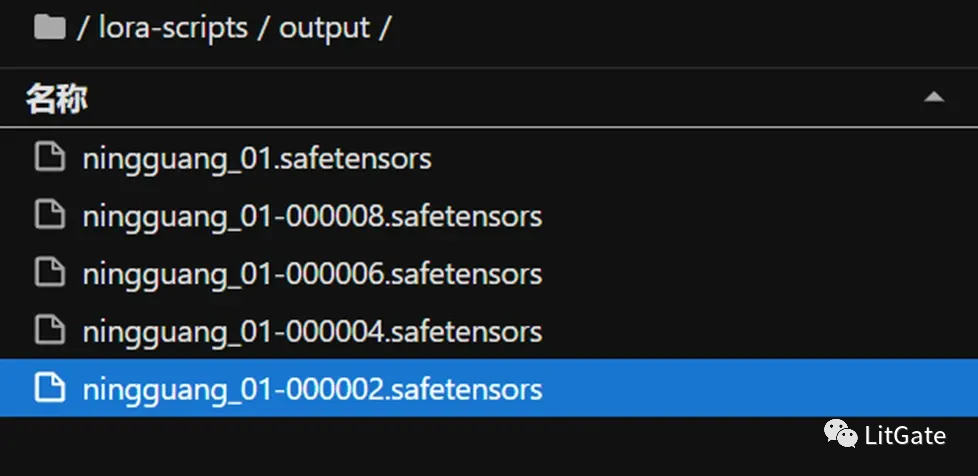
在Output文件夹下取出模型
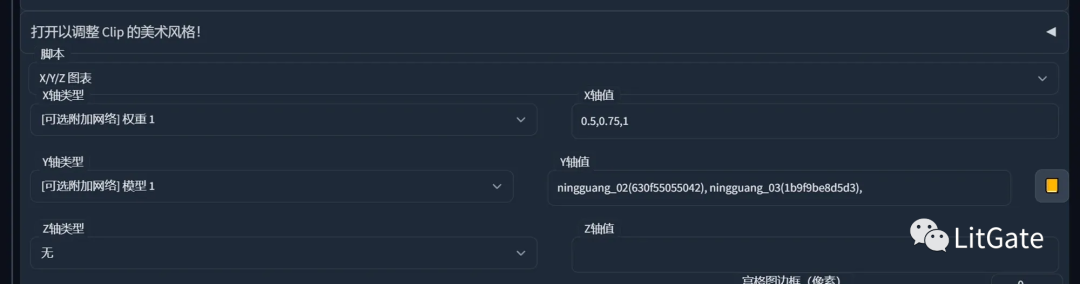
Xyz图表测试
用Stable Diffusion的xyz图表脚本来测试不同权重下Lora的表现

打开美术风格,选择脚本XYZ图表:
-
x轴类型选择[可附加网络]权重1 x轴值:写你想测试的Lora权重即可。
-
Y轴类型选择[可附加网络]模型1 Y轴值:填你想测试的Lora模型名称。
-
Z轴类型选不选都可以。
*没有可选附加网络的请在插件列表里面安装
总结
到这里就结束了~
最后感谢大家观看本次教程,理论都是基础实际效果还是需要实践验证。
第一次写教程(其实更偏学习过程中的总结),写的如果不好请轻喷,如有更好的见解欢迎在评论区讨论,我也还在摸索阶段也在更深入的学习训练模型知识。
成品图分享




对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!

篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!