总目录
一、 凸优化基础(Convex Optimization basics)
二、 一阶梯度方法(First-order methods)
- 梯度下降(Gradient Descent)
- 次梯度(Subgradients)
- 近端梯度法(Proximal Gradient Descent)
- 随机梯度下降(Stochastic gradient descent)
三、对偶
- 线性规划中的对偶(Duality in linear programs)
- 凸优化中的对偶(Duality in General Programs)
- KKT条件(Karush-Kuhn-Tucker Conditions)
- 对偶的应用及拓展(Duality Uses and Correspondences)
- 对偶方法(Dual Methods)
- 交替方向乘子法(Alternating Direction Method of Multipliers)
Introduction
上一节我们提到了强对偶,即原问题的最优值与对偶问题的最优值相等。下面我们需要解决怎样找到优化问题的最优解。而KKT条件就是最优解需要满足的条件。
KKT条件
给定一个一般性的优化问题:
min
x
f
(
x
)
s
u
b
j
e
c
t
t
o
h
i
(
x
)
≤
0
,
i
=
1
,
.
.
.
,
m
l
i
(
x
)
=
0
,
j
=
1
,
.
.
.
,
r
\begin{aligned} \min_{x}\quad &f(x)\\ {\rm subject\ to}\quad &h_i(x)\leq 0,\ i=1,...,m\\ &l_i(x)=0,\ j=1,...,r \end{aligned}
xminsubject tof(x)hi(x)≤0, i=1,...,mli(x)=0, j=1,...,r
KKT条件(Karush-Kuhn-Tucker conditions or KKT conditions)定义为:
- 稳定性条件: 0 ∈ ∂ x ( f ( x ) + ∑ i = 1 m u i h i ( x ) + ∑ j = 1 r v j l j ( x ) ) 0\in\partial_x(f(x)+\sum^m_{i=1}u_ih_i(x)+\sum^r_{j=1}v_jl_j(x)) 0∈∂x(f(x)+i=1∑muihi(x)+j=1∑rvjlj(x))
- 互补松弛性: u i ⋅ h i ( x ) = 0 f o r a l l i u_i\cdot h_i(x)=0\quad {\rm for\ all}\ i ui⋅hi(x)=0for all i
- 原问题可行域: h i ( x ) ≤ 0 , l i ( x ) = 0 f o r a l l i , j h_i(x)\leq 0, l_i(x)=0\quad {\rm for\ all\ }i,j hi(x)≤0,li(x)=0for all i,j
- 对偶问题可行域: u i ≥ 0 f o r a l l i u_i\geq 0\quad {\rm for\ all\ } i ui≥0for all i
充分性与必要性说明
必要性
假设
x
∗
x^*
x∗和
u
∗
,
v
∗
u^*,v^*
u∗,v∗分别是原问题和对偶问题的最优解,且原问题和对偶问题的对偶间隙为0(即强对偶)。那么:
f
(
x
∗
)
=
g
(
u
∗
,
v
∗
)
=
min
x
f
(
x
)
+
∑
i
=
1
m
u
i
∗
h
i
(
x
)
+
∑
j
=
1
r
v
j
∗
l
j
(
x
)
≤
f
(
x
∗
)
+
∑
i
=
1
m
u
i
∗
h
i
(
x
∗
)
+
∑
j
=
1
r
v
j
∗
l
j
(
x
∗
)
≤
f
(
x
∗
)
\begin{aligned} f(x^*)&=g(u^*,v^*)\\ &=\min_x f(x)+\sum^m_{i=1}u^*_ih_i(x)+\sum^r_{j=1}v^*_jl_j(x)\\ &\leq f(x^*)+\sum^m_{i=1}u^*_ih_i(x^*)+\sum^r_{j=1}v^*_jl_j(x^*)\\ &\leq f(x^*) \end{aligned}
f(x∗)=g(u∗,v∗)=xminf(x)+i=1∑mui∗hi(x)+j=1∑rvj∗lj(x)≤f(x∗)+i=1∑mui∗hi(x∗)+j=1∑rvj∗lj(x∗)≤f(x∗)
即所有不等式都可以取等号。因此,我们可以得到:
- 点 x ∗ x^* x∗最小化 L ( x , u ∗ , v ∗ ) L(x,u^*,v^*) L(x,u∗,v∗),那么 L ( x , u ∗ , v ∗ ) L(x,u^*,v^*) L(x,u∗,v∗)在 x = x ∗ x=x^* x=x∗处的次微分一定包含0——即稳定性条件。
- ∑ i = 1 m u i ∗ h i ( x ∗ ) = 0 \sum^m_{i=1}u^*_ih_i(x^*)=0 ∑i=1mui∗hi(x∗)=0——即互补松弛性
必要性:如果 x ∗ x^* x∗和 u ∗ , v ∗ u^*,v^* u∗,v∗分别是原问题与对偶问题的解,且对偶间隙为0,那么 x ∗ , u ∗ , v ∗ x^*,u^*,v^* x∗,u∗,v∗满足KKT条件。
充分性
如果存在
x
∗
,
u
∗
,
v
∗
x^*,u^*,v^*
x∗,u∗,v∗满足KKT条件,那么
g
(
u
∗
,
v
∗
)
=
f
(
x
∗
)
+
∑
i
=
1
m
u
i
∗
h
i
(
x
∗
)
+
∑
j
=
1
r
v
j
∗
l
j
(
x
∗
)
=
f
(
x
∗
)
\begin{aligned} g(u^*,v^*)&=f(x^*)+\sum^m_{i=1}u^*_ih_i(x^*)+\sum^r_{j=1}v^*_jl_j(x^*)\\ &= f(x^*) \end{aligned}
g(u∗,v∗)=f(x∗)+i=1∑mui∗hi(x∗)+j=1∑rvj∗lj(x∗)=f(x∗)
因此,对偶间隙为0,所以
x
∗
x^*
x∗和
u
∗
,
v
∗
u^*,v^*
u∗,v∗分别是原问题与对偶问题的解。
充分性:如果
x
∗
,
u
∗
,
v
∗
x^*,u^*,v^*
x∗,u∗,v∗满足KKT条件,那么
x
∗
x^*
x∗和
u
∗
,
v
∗
u^*,v^*
u∗,v∗分别是原问题与对偶问题的解
总结
综上所述,KKT条件等价于对偶间隙为0:
- 总是充分的
- 在强对偶条件下是必要的
那么我们可以得到:如果一个问题有强对偶性,那么
x
∗
,
u
∗
,
v
∗
x^*,u^*,v^*
x∗,u∗,v∗满足KKT条件与
x
∗
x^*
x∗和
u
∗
,
v
∗
u^*,v^*
u∗,v∗分别是原问题与对偶问题的解是等价的。
可以看出,对于无约束优化问题,KKT条件就是次梯度最优化条件。对于一般性凸优化问题,KKT条件是次梯度最优化条件的推广。
例子:支持向量机(SVM)
给定
y
∈
{
−
1
,
1
}
n
y\in \{-1,1\}^n
y∈{−1,1}n,
X
∈
R
n
×
p
X\in R^{n\times p}
X∈Rn×p有行向量
x
1
,
.
.
.
,
x
n
x_1,...,x_n
x1,...,xn,则支持向量机(SVM)定义为:
min
β
,
β
0
,
ξ
1
2
∥
β
∥
2
2
+
C
∑
i
=
1
n
ξ
i
s
u
b
j
e
c
t
t
o
ξ
i
≥
0
,
i
=
1
,
.
.
.
,
n
y
i
(
x
i
T
β
+
β
0
)
≥
1
−
ξ
i
,
i
=
1
,
.
.
.
,
n
\begin{aligned} \min_{\beta,\beta_0,\xi}\quad &\frac{1}{2}\|\beta\|^2_2+C\sum^n_{i=1}\xi_i\\ {\rm subject\ to}\quad & \xi_i\geq 0,\ i=1,...,n\\ &y_i(x_i^T\beta + \beta_0) \geq1-\xi_i,\ i=1,...,n \end{aligned}
β,β0,ξminsubject to21∥β∥22+Ci=1∑nξiξi≥0, i=1,...,nyi(xiTβ+β0)≥1−ξi, i=1,...,n
引入对偶变量
v
,
w
≥
0
v,w\geq 0
v,w≥0。KKT稳定性条件为:
0
=
∑
i
=
1
n
w
i
y
i
,
β
=
∑
i
=
1
n
w
i
y
i
x
i
,
w
=
C
1
−
v
0=\sum^n_{i=1}w_iy_i,\quad \beta=\sum^n_{i=1}w_iy_ix_i, \quad w=C1-v
0=i=1∑nwiyi,β=i=1∑nwiyixi,w=C1−v
互补松弛性:
v
i
ξ
i
=
0
,
w
i
(
1
−
ξ
i
−
y
i
(
x
i
T
β
+
β
0
)
)
=
0
,
i
=
1
,
.
.
.
,
n
v_i\xi_i=0,\quad w_i(1-\xi_i-y_i(x^T_i\beta+\beta_0))=0,\quad i=1,...,n
viξi=0,wi(1−ξi−yi(xiTβ+β0))=0,i=1,...,n
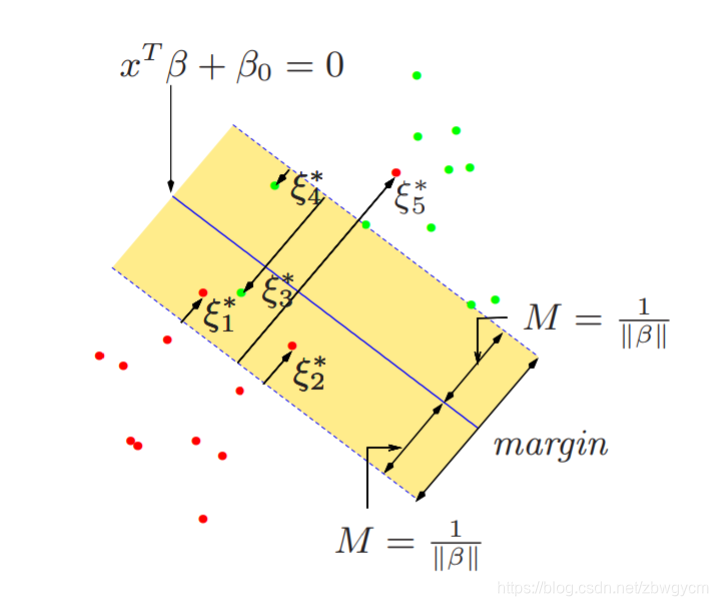
因此,在最优点处我们有 β = ∑ i = 1 n w i y i x i \beta=\sum^n_{i=1}w_iy_ix_i β=∑i=1nwiyixi,且仅当 y i ( x i T β + β 0 ) = 1 − ξ i y_i(x_i^T\beta + \beta_0) =1-\xi_i yi(xiTβ+β0)=1−ξi, w i w_i wi是非零的,这些点 i i i被叫做支持点(support points)
- 对于支持点 i i i,如果 ξ i = 0 \xi_i=0 ξi=0,则 x i x_i xi位于分割边界上,且 w i ∈ ( 0 , C ] w_i\in (0,C] wi∈(0,C];
- 对于支持点
i
i
i,如果
ξ
i
≠
0
\xi_i\neq0
ξi=0,则
x
i
x_i
xi位于分割边界的错误一边,且
w
i
=
C
w_i= C
wi=C;
有约束形式与拉格朗日形式
在统计和机器学习中,我们常常把一个优化问题在其有约束形式(constrained form),即
min
x
f
(
x
)
s
u
b
j
e
c
t
t
o
h
(
x
)
≤
t
\min_x f(x)\quad {\rm subject\ to\quad }h(x)\leq t
xminf(x)subject toh(x)≤t
和拉格朗日形式(Lagrange form),即
min
x
f
(
x
)
+
λ
⋅
h
(
x
)
\min_x f(x)+\lambda\cdot h(x)
xminf(x)+λ⋅h(x)
之间进行互换,并认为这两种形式是等价的。由上面分析可知,假如 f , h f,h f,h都是凸函数,这种等价在 h ( x ) < t h(x)<t h(x)<t时是成立的。
Conclusion
对偶的一个关键性质是,在强对偶条件下,KKT条件是最优解的充要条件,即原问题的解可以通过其对偶问题得到。由于对偶问题一定是凸优化问题,这在对偶问题比原问题更简单时非常有用。