前言
在当今数据驱动的时代,大数据的概念已经深入人心。随着信息技术的快速发展,企业和组织面临着海量数据的挑战。这些数据不仅体量庞大,而且种类繁多,包括结构化数据、半结构化数据和非结构化数据。如何有效地处理、分析和利用这些数据,成为了各行各业亟待解决的问题。
MapReduce是一种编程模型和处理框架,旨在简化大规模数据集的处理。它通过将任务分解为小的、可并行执行的子任务,极大地提高了数据处理的效率。MapReduce的核心思想是将数据处理分为两个阶段:Map阶段和Reduce阶段。在Map阶段,输入数据被分解成键值对并进行处理;在Reduce阶段,这些中间结果被汇总和整理,生成最终的输出。
本篇文章将详细介绍如何创建一个简单的MapReduce项目,并使用MapReduce编程模型实现一个基本的词频统计功能。
一、创建mapreduce-demo项目
1. 在idea上创建maven项目
打开idea新建项目,如下图。
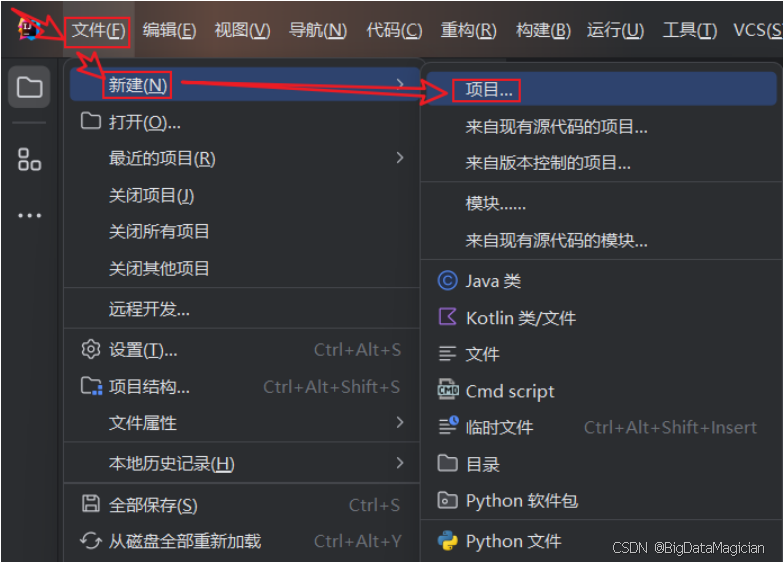
选择Java项目,输入项目名称,选择构建系统为Maven,选择JDK为1.8,然后点击创建。
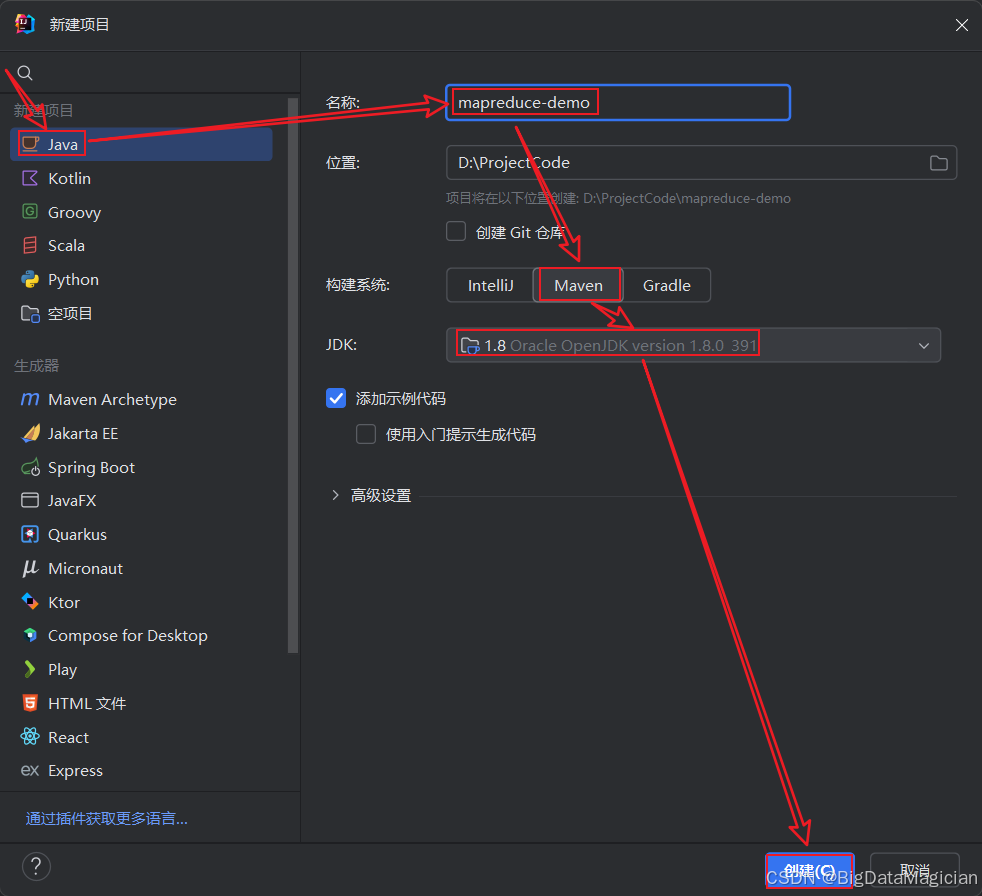
2. 导入hadoop相关依赖
在pom.xml文件中添加hadoop相关依赖,并添加maven-jar-plugin插件。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>mapreduce-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<!--<mainClass>org.example.Main</mainClass>-->
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
二、MapReduce编程
1. 相关介绍
1.1 驱动类(Driver Class)
1.1.1 驱动类的定义
在 MapReduce 框架中,驱动类是应用程序的入口点,负责配置和启动一个 MapReduce 作业。它是连接用户编写的业务逻辑(即 Mapper 和 Reducer)与 Hadoop 分布式计算框架之间的桥梁。通过驱动类,用户可以指定作业的各种参数,如输入输出路径、Mapper 和 Reducer 类型等,并最终提交作业给 Hadoop 执行。
1.1.2 驱动类的功能
- 配置作业:设置作业的基本属性,包括作业名称、输入格式、输出格式、Mapper 类、Reducer 类等。
- 指定键值对类型:定义 Mapper 输出的键值对类型以及 Reducer 输出的键值对类型,确保数据流的一致性。
- 初始化作业:创建一个新的
Job实例,并对其进行必要的配置。 - 设置输入输出路径:指明作业将要处理的数据源位置(输入路径)以及结果应该存储的位置(输出路径)。需要注意的是,输出路径必须不存在,以防止覆盖已有数据。
- 添加额外资源:如果需要,可以添加其他资源文件(如配置文件、字典等),以便 Mapper 或 Reducer 可以访问这些资源。
- 提交作业并监控执行状态:将配置好的作业提交给 Hadoop 集群,并等待其完成。在此期间,驱动类还可以用来获取作业的状态更新,例如进度百分比或错误信息。
- 结束程序:根据作业的执行结果,正确地终止 Java 程序。通常会使用
System.exit()方法,并传入适当的退出代码来表示作业是否成功完成。
1.1.3 驱动类的作用
- 作业配置中心:作为 MapReduce 作业的主要配置入口,驱动类集中管理了所有与作业相关的设置,使得整个应用易于维护和调整。
- 简化分布式计算:它隐藏了底层复杂的分布式计算细节,让用户只需关注业务逻辑实现,而不需要关心如何具体分配任务到集群节点上运行。
- 促进代码复用:由于驱动类分离了配置逻辑与业务逻辑,因此可以在不同的项目中重用相同的 Mapper 和 Reducer 类,只需要修改驱动类中的配置即可适应新的需求。
- 提供反馈机制:通过监听作业状态变化,驱动类可以为用户提供实时反馈,帮助他们了解作业进展或者诊断问题所在。
1.2 Mapper
1.2.1 Mapper 的定义
在 MapReduce 框架中,Mapper 是处理阶段的第一步。它的主要任务是将输入数据转换成一系列的键值对(key-value pairs),这些键值对被称为中间结果或中间输出。Mapper 对每个输入分片(split)独立地执行映射操作,这意味着它可以并行处理多个输入分片以加速整个作业的完成。
1.2.2 Mapper 的功能
-
输入分割:Hadoop 将输入文件分割成多个逻辑上的分片(splits),每个 Mapper 实例负责处理一个这样的分片。分片的大小和数量可以根据配置参数以及输入文件的特性来调整。
-
读取输入:Mapper 通过
RecordReader类从分片中读取记录。默认情况下,TextInputFormat使用LineRecordReader来逐行读取文本文件,但也可以根据需要自定义InputFormat和RecordReader来处理其他格式的数据。 -
转换与处理:对于每一个从分片中读取到的记录,Mapper 都会调用一次
map方法。开发者需要在这个方法内部实现具体的业务逻辑,比如解析文本、计算统计信息等。通常,map方法会对输入的键值对进行某种形式的转换,并输出新的键值对作为中间结果。 -
输出中间结果:Mapper 输出的中间键值对会被写入内存中的缓冲区。当缓冲区达到一定阈值时,内容会被溢出(spill)到磁盘上,并且在此过程中可能会应用 Combiner 函数来局部汇总数据,以减少后续传输的数据量。
-
分区:Mapper 输出的每个键值对都会被分配给特定的 Reducer。这通常通过哈希函数计算键的哈希值,并根据哈希值决定发送到哪个 Reducer。默认情况下,Hadoop 使用
HashPartitioner,但用户可以自定义 Partitioner 来控制分区逻辑。 -
并行处理:由于每个 Mapper 实例都独立处理一个分片,因此多个 Mapper 可以同时运行,从而充分利用集群资源,加快数据处理速度。
1.2.3 Mapper 的作用
-
数据预处理:Mapper 是对原始数据进行初步解析和转换的地方。它能够将不同格式的数据标准化为键值对的形式,便于后续的归约操作。
-
提高效率:通过并行处理多个输入分片,Mapper 能够显著缩短大型数据集的处理时间。此外,利用 Combiner 函数可以在 Mapper 端本地汇总部分结果,进一步优化性能。
-
灵活定制:Mapper 提供了高度的灵活性,允许开发者根据具体需求编写复杂的映射逻辑。例如,在文本分析任务中,Mapper 可以用来提取单词及其出现次数;在日志处理场景下,它可以用于解析和过滤日志条目。
-
支持多样化输入:除了文本文件外,Mapper 还能处理各种类型的输入源,如数据库表、二进制文件等。这使得 MapReduce 成为了一个非常通用的大数据分析工具。
1.3 Shuffle
Shuffle 是 MapReduce 框架中的一个关键阶段,它发生在 Mapper 和 Reducer 之间。在 Shuffle 阶段,MapReduce 框架执行了一系列操作来准备和传输 Mapper 输出的数据给相应的 Reducer。这个过程对于确保数据正确分区、排序以及有效地分配到 Reducers 来说至关重要。
1.3.1 Shuffle 的定义
Shuffle 是指从 Mapper 输出的中间键值对到 Reducer 输入之间的整个数据处理和传输过程。它不是一个单独的组件或类,而是一系列步骤的集合,这些步骤由 Hadoop 自动管理。
1.3.2 Shuffle 的功能
-
Partitioning(分区):
Mapper 输出的每个键值对都会被分配给特定的 Reducer。这通常通过哈希函数计算键的哈希值,并根据哈希值决定发送到哪个 Reducer。默认情况下,Hadoop 使用HashPartitioner,但用户可以自定义 Partitioner。 -
Sorting(排序):
在将数据发送给 Reducers 之前,框架会按照键对所有的中间键值对进行排序。排序保证了 Reducer 收到的数据是按键有序的,这对于很多算法来说非常重要。在 Hadoop 的 MapReduce 框架中,默认的排序机制是基于字典顺序(lexicographical order)对键进行排序。这意味着对于文本类型的键(如
Text类型),排序将按照字符的 ASCII 或 Unicode 值进行。对于数值类型的键(例如IntWritable,LongWritable等),则会根据其数值大小进行自然排序。默认情况下,Hadoop 使用的是
org.apache.hadoop.io.WritableComparator来提供比较逻辑。对于每种WritableComparable类型,都有一个对应的WritableComparator实现,它知道如何比较特定类型的数据。比如,对于IntWritable类型,使用的是IntWritable.Comparator;对于Text类型,则使用Text.Comparator。如果你希望改变默认的排序行为,你可以通过自定义 Comparator 来实现。这可以通过设置 Job 配置中的
mapreduce.job.output.key.comparator.class属性来完成。你只需要创建一个实现了RawComparator接口的类,并在此类中定义你自己的比较逻辑。 -
Grouping(分组):
排序后的键值对会被传递给 Reducer。Reducer 收到的是具有相同键的所有值的迭代器。这意味着,即使有多个相同的键,它们也会被组合在一起(值是列表)传递给同一个 reduce 函数调用。 -
Data Transfer(数据传输):
Mapper 的输出结果会被写入本地磁盘,然后通过网络传输到运行 Reducers 的节点上。为了提高效率,Hadoop 可能会在数据传输的同时进行压缩。 -
Combiner(合并):
Combiner 是一个可选的操作,可以在 Mapper 端局部汇总数据,减少需要传输的数据量。它本质上是一个小规模的 Reducer,其输入输出类型必须与 Reducer 相同。 -
Spill(溢出):
当内存缓冲区达到一定阈值时,Mapper 的输出会写入临时文件(spill 文件)。如果设置了 Combiner,那么在写入 spill 文件之前会先运行 Combiner。所有 spill 文件最终会被合并成一个文件。 -
Merge(合并):
在 Reducer 端接收到来自不同 Mappers 的多个文件后,这些文件会被合并。合并过程中同样会应用排序和可能的 Combiner 操作。
1.3.3 Shuffle 的作用
-
优化数据分布:通过合理的分区策略,Shuffle 确保了数据能够均匀地分布在各个 Reducer 上,避免某些 Reducer 负载过重。
-
提升性能:通过排序和可能的合并操作,Shuffle 减少了 Reducer 需要处理的数据量,提高了作业的整体性能。
-
保证数据顺序:Shuffle 提供了按键排序的功能,这对许多依赖于有序输入的应用程序来说是非常重要的。
-
促进分布式计算:Shuffle 是连接分布式系统中不同节点上的 Mapper 和 Reducer 的桥梁,使得大规模并行处理成为可能。
1.4 Reducer
1.4.1 Reduce 的定义
在 MapReduce 框架中,Reduce 是处理阶段的第二步,紧接在 Map 阶段之后。它的主要任务是对来自 Mapper 输出的中间键值对进行归约(聚合、汇总等)处理,并生成最终的输出结果。每个 Reducer 实例会接收一组具有相同键的值列表,并对其进行处理以产生一个或多个输出。
1.4.2 Reduce 的功能
-
输入处理:Reducer 接收到的是经过 Shuffle 和 Sort 阶段处理后的数据,这些数据是按键排序并且分区好的。每个 Reducer 会收到属于它负责的那一部分键空间的数据。
-
分组:Reducer 输入的键值对会被根据键进行分组,即所有拥有相同键的值会被组合在一起。这意味着对于每一个唯一的键,框架都会调用一次
reduce方法,并传递该键及其相关的值列表给这个方法。 -
逻辑处理:开发者需要在
reduce方法中实现具体的业务逻辑。例如,在单词计数的例子中,reduce方法会对每个单词的所有出现次数进行求和;而在其他应用中,可能涉及更复杂的计算,如平均值、最大值/最小值计算等。 -
输出结果:处理完成后,Reducer 通过调用
context.write()方法将结果写入到 Hadoop 文件系统或其他存储系统中。这些输出构成了整个 MapReduce 作业的最终结果。 -
并行处理:Reducer 可以并行运行多个实例来处理不同的键空间,从而加快整个作业的速度。Hadoop 框架会自动管理 Reducers 的分配和调度。
1.4.3 Reduce 的作用
-
数据聚合:Reduce 是执行数据聚合操作的关键环节,比如求和、计数、平均值计算等。它是从大量分散的数据中提炼出有价值信息的过程。
-
减少冗余:通过将具有相同键的值合并在一起,Reduce 减少了输出中的冗余信息,使得最终结果更加紧凑且易于分析。
-
提高效率:由于 Reducer 可以并行工作,这有助于提升大规模数据集处理的速度和效率。此外,Shuffle 阶段的优化(如 Combiner 的使用)也可以减少传输的数据量,进一步提高性能。
-
确保有序性:默认情况下,Reducer 收到的数据是按键排序的,这对于某些依赖于有序输入的应用来说非常重要。
-
支持复杂运算:虽然 Reduce 的核心是简单的键值对处理,但它也支持更复杂的计算逻辑,如多轮迭代、状态保持等高级特性。
2. MapReduce编程步骤
此处以词频统计为示例来进行分析和编程。
词频统计(Word Count)是数据分析中最基本的任务之一,它涉及到计算文本中每个单词出现的次数。这个任务看似简单,但在处理大规模数据集时变得复杂,尤其是在需要并行化处理以提高效率的情况下。MapReduce 编程模型非常适合用于执行这样的任务,因为它可以有效地将任务分布到多个节点上进行并行处理。
词频统计的意义:
- 文本分析的基础:词频统计是许多高级文本分析任务的基础,如主题建模、情感分析、信息检索等。
- 了解内容特征:通过统计词频,可以快速了解文档或语料库的主要内容和特点,识别出高频词汇。
- 辅助决策制定:在商业智能、市场调研等领域,词频可以帮助企业理解消费者反馈、社交媒体趋势等。
2.1 词频统计过程分析
| 阶段 | 输入数据格式 | 输出数据格式 | 说明 |
|---|---|---|---|
| 读取文件 (Input) | 文件系统中的原始数据文件(例如文本文件、二进制文件等) | <key, value>对,其中key为偏移量或行号,value为文件中的一行内容或记录。 | 输入格式类将文件分割成多个split,并为每个split创建一个RecordReader实例来解析数据,产生<key, value>对作为Mapper的输入。 |
| Mapper | <key, value>对 | 中间<key, value>对 | Mapper接收输入<key, value>对并对其进行处理,通常会解析value以提取有用信息,然后输出新的中间<key, value>对。 |
| Partitioning | 中间<key, value>对 | 分区后的中间<key, value>对 | Partitioner根据key确定每条记录应该发送给哪个Reducer。默认情况下是基于hash(key) % numReducers进行分区。 |
| Sorting | 分区后的中间<key, value>对 | 排序后的中间<key, value>对 | 每个Reducer接收到的数据首先按照key排序。这是自动完成的,不需要额外编程。 |
| Grouping | 排序后的中间<key, value>对 | <key, List>对 | 对于每个key,所有关联的value被收集到一个列表中,形成<key, List>对。这是为了准备Reduce函数的输入。 |
| Data Transfer | <key, List>对 | <key, List>对传输至Reducer | 经过分区、排序和分组后的数据通过网络传输给相应的Reducer。此过程中可能会应用Combiner来减少传输的数据量。 |
| Combiner (可选) | <key, List>对 | <key, List>对 | 如果配置了Combiner,它会在Mapper节点本地对相同key的value列表进行初步聚合操作,以减少需要传输的数据量。Combiner的逻辑与Reducer类似,但作用范围仅限于单个Mapper节点。 |
| Spill to Disk | 内存缓冲区中的<key, value>对 | 磁盘上的临时文件 | 当内存中的数据达到一定阈值时,数据会被溢写(spill)到磁盘上,形成临时文件。这些文件在Reducer之前会被合并。 |
| Merge | 磁盘上的多个临时文件 | 合并后的临时文件 | 在Reducer端,来自不同Mapper的spilled文件被合并成一个有序的输入流供Reducer使用。这个过程也包括合并具有相同key的记录。 |
| Reduce | <key, List>对 | 最终的<key, value>对 | Reducer接收来自所有Mapper的已分组和排序的数据,对其进行汇总计算,并输出最终结果。 |
| 输出文件 (Output) | 最终的<key, value>对 | 文件系统中的输出文件 | 输出格式类负责将Reducer产生的<key, value>对写入文件系统,通常是HDFS。每一轮Reduce任务的结果会被写入一个单独的输出文件。 |
假设有一个文件wordcount.txt,内容如下:
Big Data is a term that describes the large volumes of data – both structured and unstructured – that inundate businesses on a day-to-day basis.
使用示例文本文件wordcount.txt作为输入,来详细说明MapReduce程序在词频统计任务中的各个阶段数据变化。
| 阶段 | 输入数据格式 | 输出数据格式 | 示例数据 |
|---|---|---|---|
| 读取文件 (Input) | 文件系统中的原始数据文件 | <key, value>对,其中key为偏移量或行号,value为文件中的一行内容或记录。 | <0, "Big Data is a term that describes the large volumes of data – both structured and unstructured – that inundate businesses on a day-to-day basis."> |
| Mapper | <key, value>对 | 中间<key, value>对 | ("Big", 1), ("Data", 1), ("is", 1), ("a", 1), ("term", 1), ("that", 1), ("describes", 1), ("the", 1), ("large", 1), ("volumes", 1), ("of", 1), ("data", 1), ("–", 1), ("both", 1), ("structured", 1), ("and", 1), ("unstructured", 1), ("inundate", 1), ("businesses", 1), ("on", 1), ("a", 1), ("day-to-day", 1), ("basis.", 1) |
| Partitioning | 中间<key, value>对 | 分区后的中间<key, value>对 | 假设有两个Reducer,分区后:Reducer 1: ("a", 1), ("and", 1), ("basis.", 1), ... Reducer 2: ("Big", 1), ("Data", 1), ("describes", 1), ... (基于hash(key) % numReducers) |
| Sorting | 分区后的中间<key, value>对 | 排序后的中间<key, value>对 | 每个Reducer接收到的数据按key排序:Reducer 1: ("a", 1), ("and", 1), ("basis.", 1), ... Reducer 2: ("Big", 1), ("Data", 1), ("describes", 1), ... |
| Grouping | 排序后的中间<key, value>对 | <key, List>对 | Reducer 1: ("a", [1, 1]), ("and", [1]), ... Reducer 2: ("Big", [1]), ("Data", [1, 1]), ... |
| Data Transfer | <key, List>对 | <key, List>对传输至Reducer | Reducer 1接收("a", [1, 1]), ("and", [1]), ... Reducer 2接收("Big", [1]), ("Data", [1, 1]), ... |
| Combiner (可选) | <key, List>对 | <key, List>对 | 如果配置了Combiner,在Mapper节点本地聚合相同key的value列表,以减少传输数据量。例如,对于"Data",可以在Mapper端先累加得到("Data", 2),然后发送给Reducer。 |
| Spill to Disk | 内存缓冲区中的<key, value>对 | 磁盘上的临时文件 | 当内存中的数据达到一定阈值时,溢写到磁盘形成临时文件。例如,("a", [1, 1])会被写入磁盘。 |
| Merge | 磁盘上的多个临时文件 | 合并后的临时文件 | 在Reducer端合并来自不同Mapper的spilled文件。例如,所有包含"a"的记录被合并成一个有序的输入流供Reducer使用。 |
| Reduce | <key, List>对 | 最终的<key, value>对 | Reducer计算总和:("a", 2), ("and", 1), ("basis.", 1), ..., ("Big", 1), ("Data", 2), ... |
| 输出文件 (Output) | 最终的<key, value>对 | 文件系统中的输出文件 | 输出文件可能如下:a 2and 1basis. 1...Big 1Data 2... |
2.2 词频统计编程
2.2.1 编写Mapper类
package org.example.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 把值转为字符串
String line = value.toString();
// 使用Java的spilt方法分割值,\\s+:表示匹配一个或多个空格
String[] words = line.split("\\s+");
for (String w : words) {
if (!w.isEmpty()) {
// write会把键值对写入下一个阶段,输出中间键值对
context.write(new Text(w.toLowerCase()), new IntWritable(1));
}
}
}
}
2.2.2 编写Reducer类
package org.example.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable iw : values) {
int value = iw.get();
count += value;
}
context.write(key, new IntWritable(count));
}
}
2.2.3 编写驱动类
package org.example.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.mapreduce.lib.partition.KeyFieldBasedComparator;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 获取hadoop配置对象,在Linux上执行程序的时候,会自动加载hadoop配置
Configuration conf = new Configuration();
// 获取一个Job对象,作业,工作,任务,通过作业对象设置
Job job = Job.getInstance(conf, "WordCount");
// 定义驱动类(拥有主方法和设置job对象的类)
job.setJarByClass(WordCountDriver.class);
// 1. 设置hdfs的文件输入目录路径
FileInputFormat.setInputPaths(job, new Path("/input/wordcount"));
// 2. 使用 InputFormat(默认使用TextInputFormat,键是每行数据开始位置,值每行数据的内容) 进行输入初始化处理,将文件内容处理为初始键值对
job.setInputFormatClass(TextInputFormat.class);
// 3. 自定义map()方法处理初始键值对,生成中间键值对
job.setMapperClass(WordCountMapper.class);
// 4. shuffle过程:分区(Partitioner)、排序(Sort)、合并(Combiner)
// 分区(Partitioner):默认使用hash分区,也可以自定义分区规则
job.setPartitionerClass(HashPartitioner.class);
// 排序(Sort):字符串默认按字典排序,数字默认从小到大排序,也可以自定义排序规则
job.setSortComparatorClass(KeyFieldBasedComparator.class);
// 合并(Combiner):没有默认的合并组件,相当于一个特殊reducer
// job.setCombinerClass();
// 5. 自定义reduce()方法处理新的中间键值对,生成最终键值对
job.setReducerClass(WordCountReducer.class);
// 6. 设置hdfs的文件输出目录路径(输出的目录路径在hdfs上不能存在,否则会报文件已存在错误)
String outputDir = "/output/wordcount";
FileOutputFormat.setOutputPath(job, new Path(outputDir));
// 7. 使用 OutputFormat(默认使用TextOutputFormat,会自动把数据保存到hdfs上)进行数据输出处理,把数据保存到hdfs上
job.setOutputFormatClass(TextOutputFormat.class);
// 设置map任务后的中间键值对类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终(reduce任务)输出键值对的类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
// 根据hadoop配置获取文件系统对象,如果输出目录存在则删除
FileSystem fs = FileSystem.get(conf);
Path outputPath = new Path(outputDir);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
fs.close();
// 提交作业,并等待运行完成后,退出
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
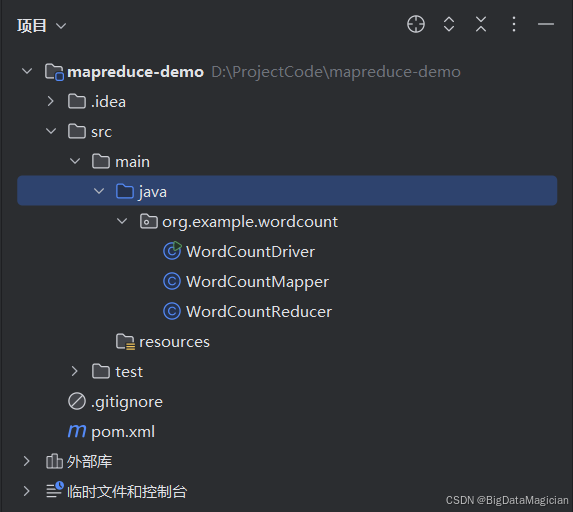
2.2.4 项目结构
项目结构如下图所示:
2.2.5 打包运行
打包:
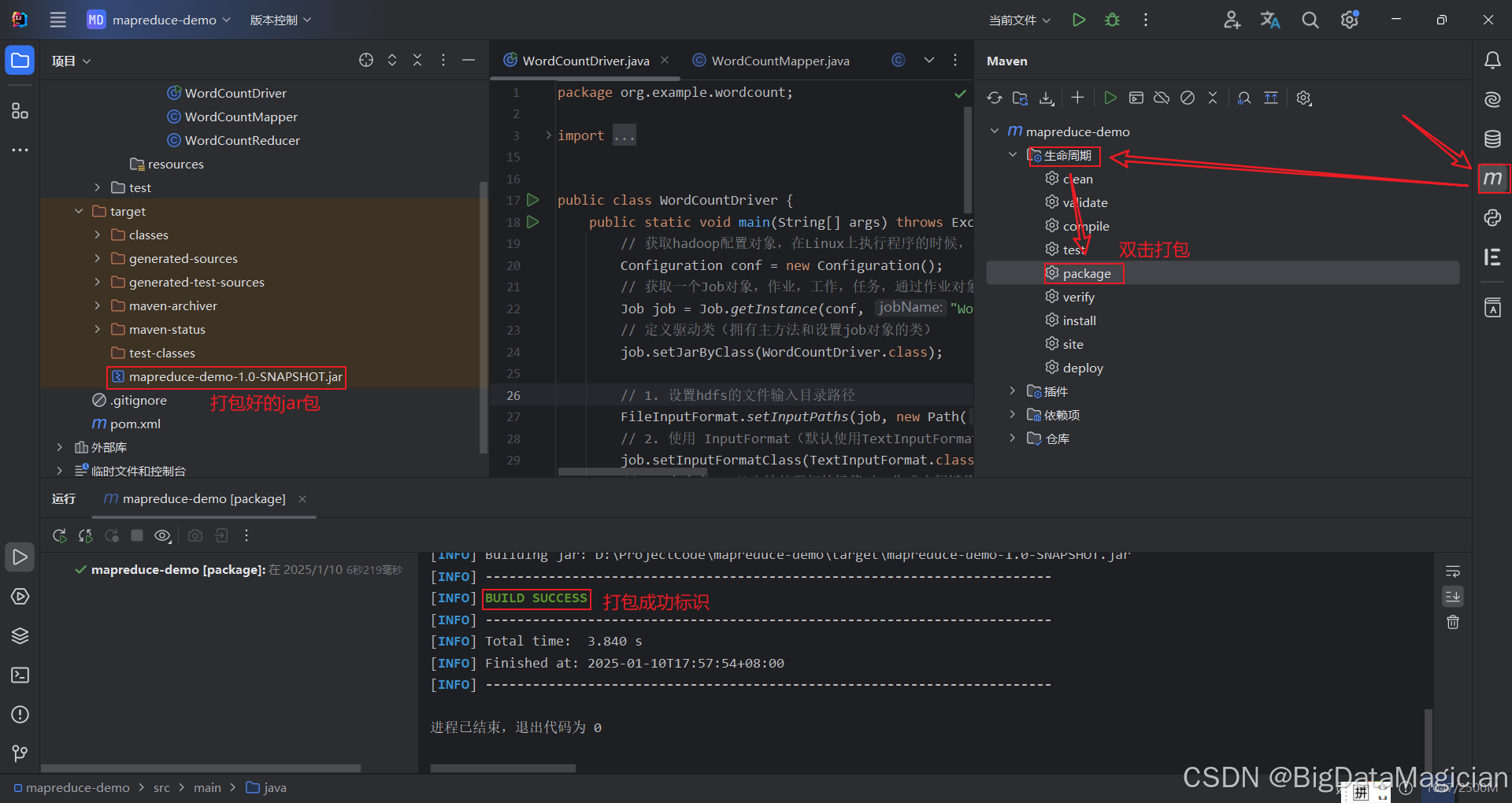
把数据文件wordcount.txt上传到hdfs的/input/wordcount目录下。
echo 'Big Data is a term that describes the large volumes of data – both structured and unstructured – that inundate businesses on a day-to-day basis.' > /tmp/wordcount.txt
hdfs dfs -mkdir -p /input/wordcount
hdfs dfs -put /tmp/wordcount.txt /input/wordcount
把jar包上传到Linux的/tmp目录下。
运行jar包:
hadoop jar /tmp/mapreduce-demo-1.0-SNAPSHOT.jar org.example.wordcount.WordCountDriver
如下图所示:
查看输出结果:
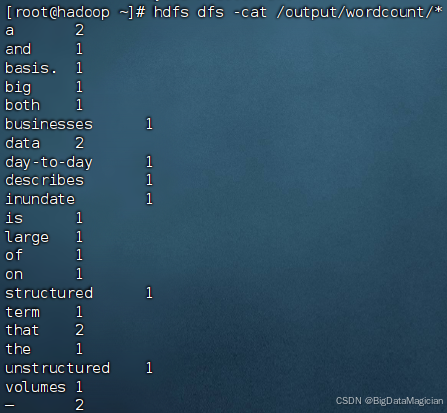
hdfs dfs -cat /output/wordcount/*
如下图所示: