文章目录
前言
在数据科学的领域,数据分析和可视化是理解和解释数据的重要工具。通过对数据的深入分析,我们能够揭示潜在的趋势、模式和关系,从而为决策提供有力支持。本项目旨在对从1905电影网爬取的电影数据进行全面的数据分析与可视化,帮助我们更好地理解电影行业的动态和特征。
本项目的分析分为几个主要部分:描述性分析、类别分布分析、模式识别分析、时间序列分析和相关性分析。我们将使用Python的Pandas库进行数据处理,并通过SQLAlchemy将分析结果存储到MySQL数据库中。此外,数据可视化将通过图表和图形展示分析结果,使得数据的解读更加直观和易于理解。
一、数据分析
1. 数据分析代码实现
import pandas as pd
from sqlalchemy import create_engine
def get_engine():
# 设置数据库连接信息
db_user = 'root'
db_password = 'zxcvbq'
db_host = '127.0.0.1'
db_port = '3306'
db_name = 'movie1905'
# 创建数据库引擎
return create_engine(f'mysql+pymysql://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}')
def save_df_to_db(dataframe, table_name):
# 设置数据库连接信息
db_user = 'root'
db_password = 'zxcvbq'
db_host = '127.0.0.1' # 或者你的数据库主机地址
db_port = '3306' # MySQL默认端口是3306
db_name = 'movie1905'
# 创建数据库引擎
engine = create_engine(f'mysql+mysqlconnector://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}')
# 将df写入MySQL表
dataframe.to_sql(name=table_name, con=engine, if_exists='replace', index=False)
print("所有csv文件的数据已成功清洗并写入MySQL数据库")
def process_row(row, data_list):
director = row['movie_director']
actors = eval(row['movie_lead_actors'])
for actor in actors:
data_dict = {
'director': director,
'actor': actor
}
data_list.append(data_dict)
if __name__ == '__main__':
# 加载数据到DataFrame
query = "SELECT * FROM movie1905_china"
df = pd.read_sql(query, get_engine())
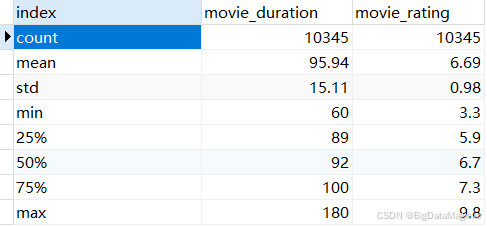
# 描述性分析
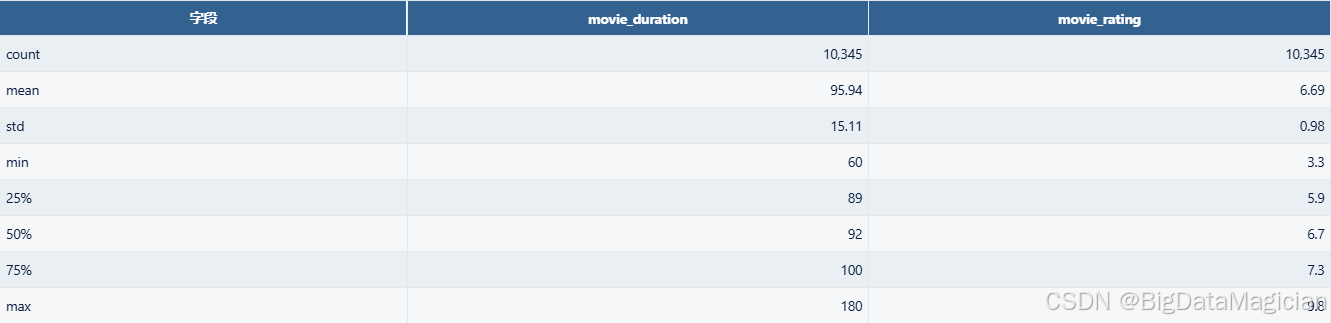
df_describe = df[['movie_duration', 'movie_rating']].describe().round(2)
save_df_to_db(df_describe.reset_index(), 'describe_analysis')
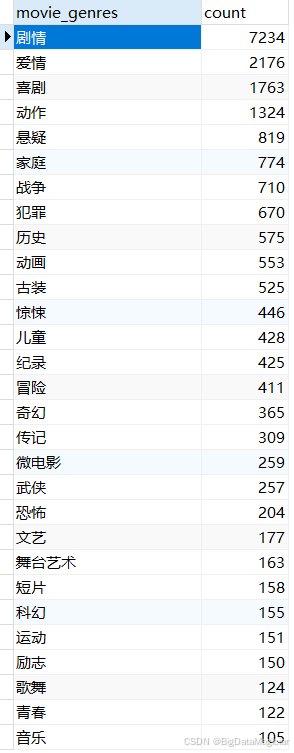
# 类别分布分析
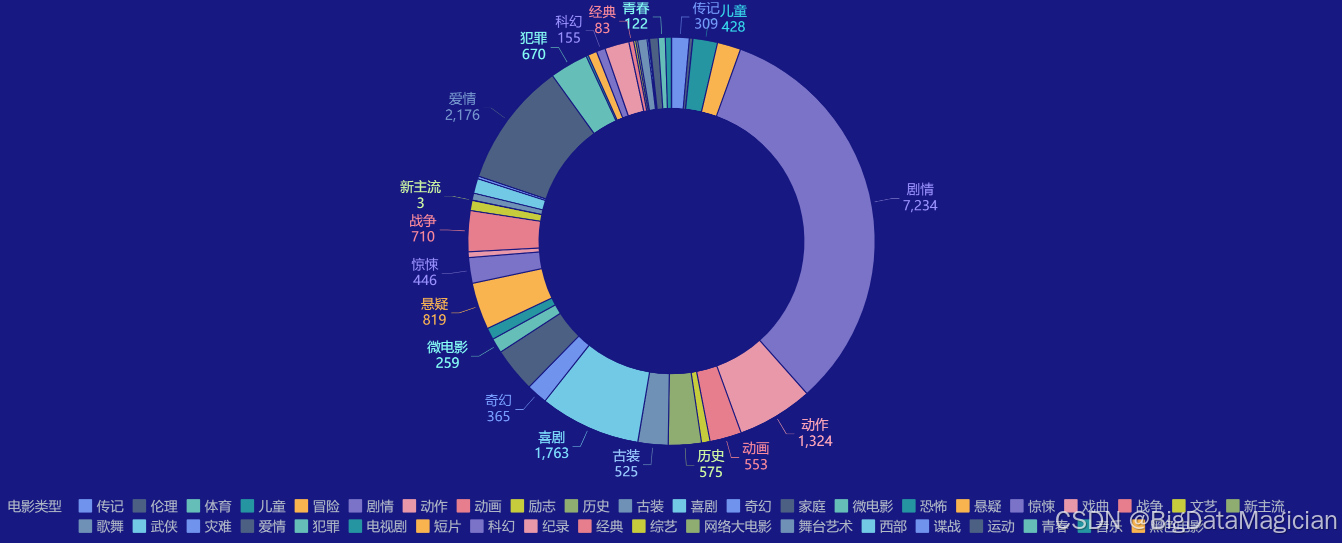
df_category = df['movie_genres'].apply(lambda x: eval(x)).explode().value_counts()
save_df_to_db(df_category.reset_index(), 'category_analysis')
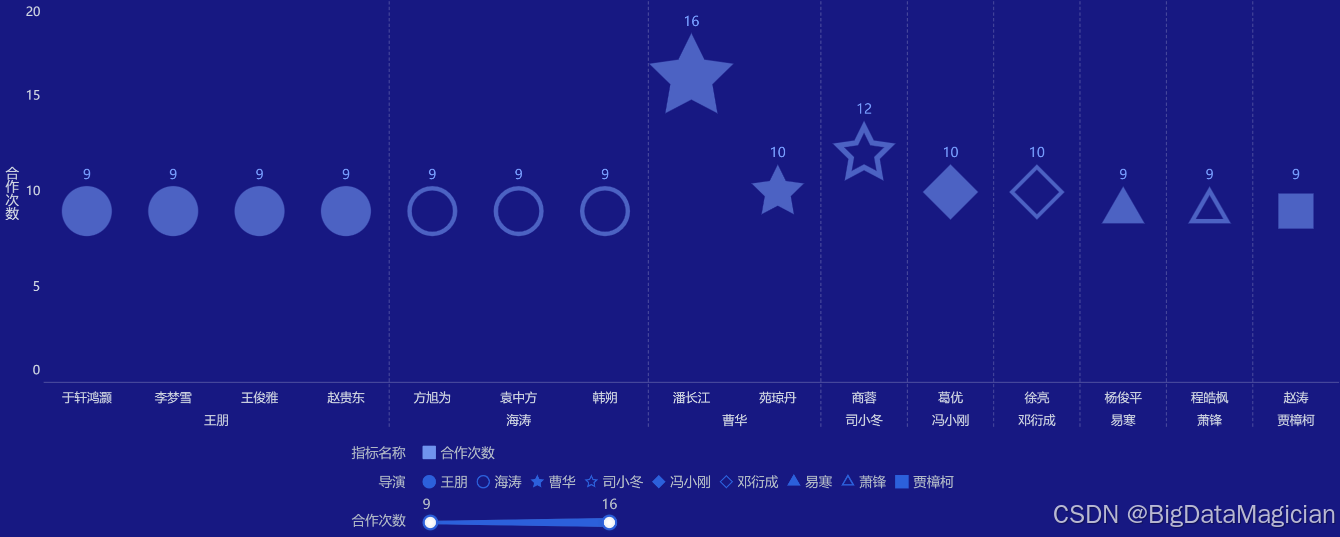
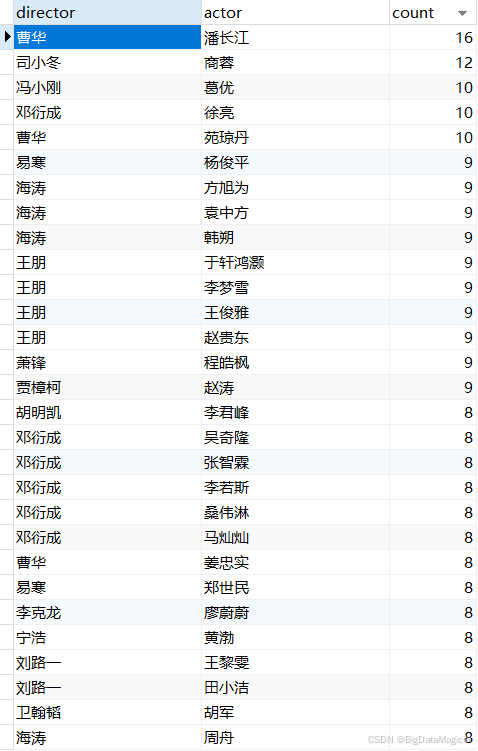
# 模式识别分析
df_copy = df.copy()
df_copy['movie_director'] = df_copy['movie_director'].replace('未知', None)
df_copy.dropna(subset=['movie_director', 'movie_lead_actors'], inplace=True)
df_mode = df_copy[['movie_director', 'movie_lead_actors']]
director_actor_list = []
df_mode.apply(lambda x: process_row(x, director_actor_list), axis=1)
df_director_actor = pd.DataFrame(director_actor_list)
df_schema = df_director_actor.groupby(['director', 'actor']).size().reset_index(name='count')
save_df_to_db(df_schema, 'mode_analysis')
# 时间序列分析
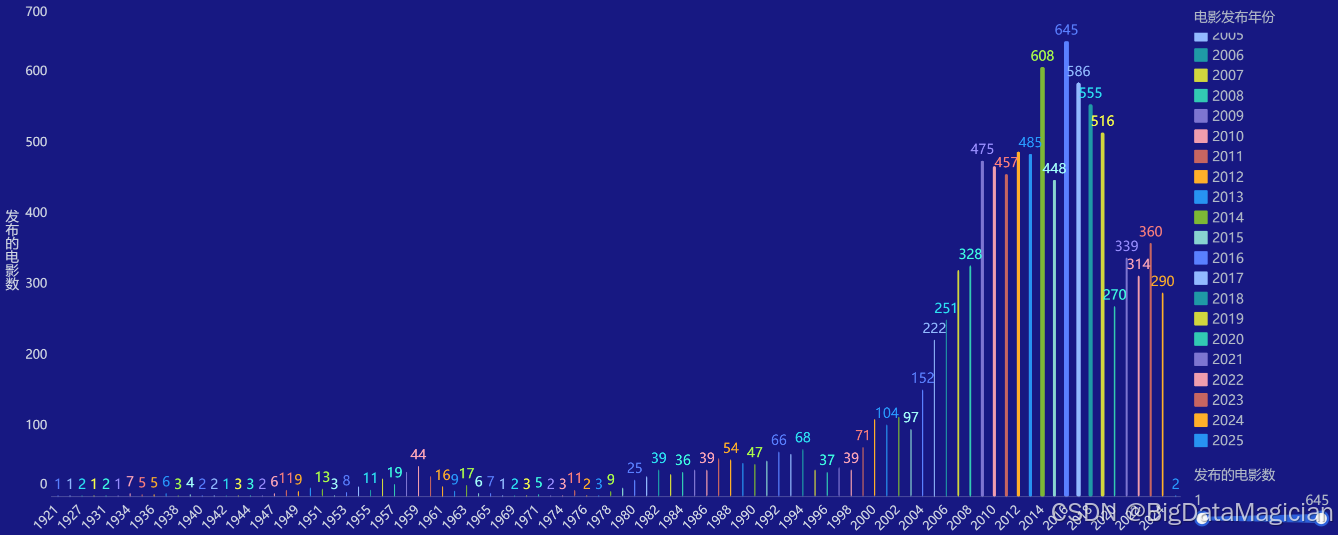
# 每年的电影发布数量
df_release_date = df.rename(columns={'movie_release_date': 'movie_release_year'})
df_year = df_release_date['movie_release_year'].str[0:4].value_counts()
save_df_to_db(df_year.reset_index(), 'year_amount_analysis')
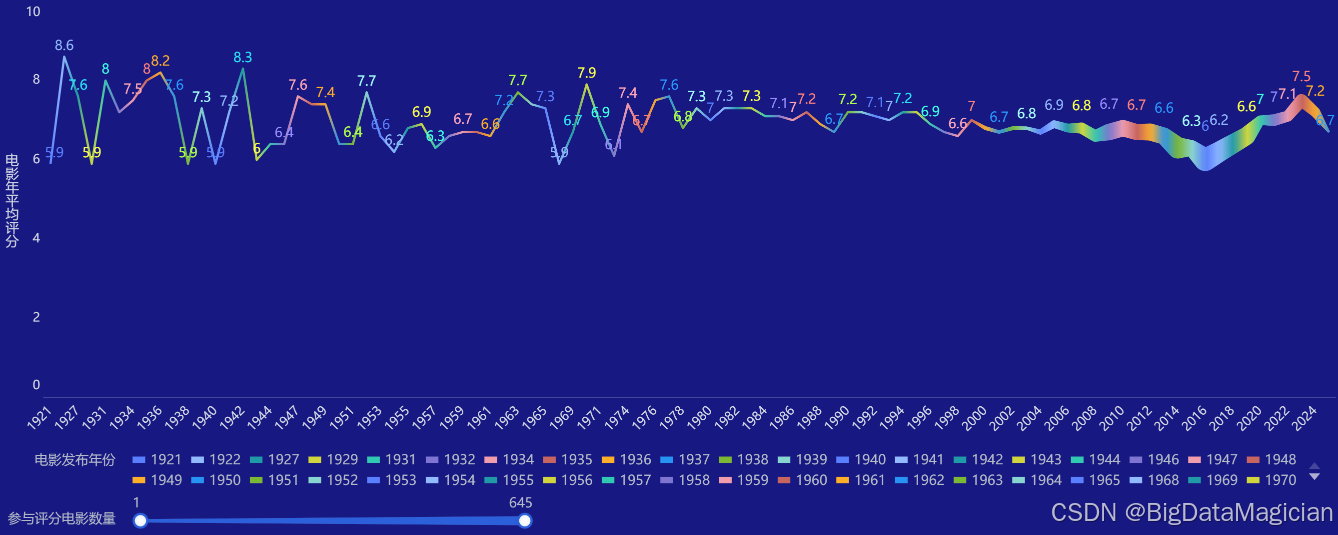
# 按年份的评分趋势
df['movie_year'] = df['movie_release_date'].str[0:4]
year_rating = df.groupby('movie_year')['movie_rating'].agg(['mean', 'count']).round(1)
save_df_to_db(year_rating.reset_index(), 'year_rating_analysis')
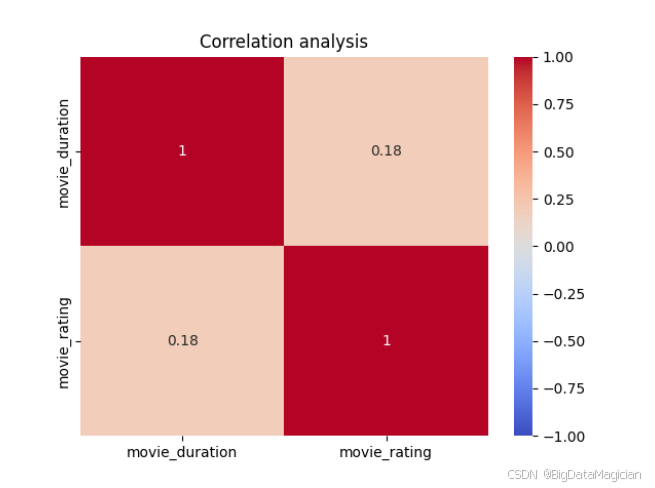
# 相关性分析
df_corr = df[['movie_duration', 'movie_rating']].corr(method='pearson').round(2)
save_df_to_db(df_corr.reset_index(), 'corr_analysis')
2. 分析后的数据截图
2.1 描述性分析结果数据
2.2 类别分布分析结果数据
2.3 模式识别分析结果数据
2.4 时间序列分析结果数据
2.4.1 每年的电影发布数量
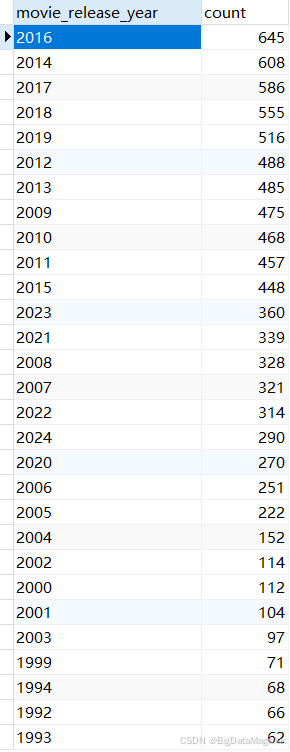
2.4.2 按年份的评分趋势
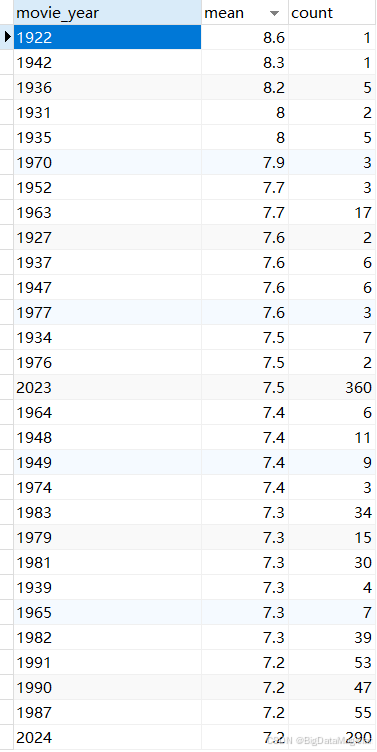
2.5 相关性分析结果数据

二、数据可视化
1. 描述性分析数据可视化
2. 类别分布分析数据可视化