1. 最简单的方法:K≈sqrt(N/2)
2. 拐点法:把聚类结果的F-test值(类间Variance和全局Variance的比值)对聚类个数的曲线画出来,选择图中拐点
3. 基于Information Critieron的方法:如果模型有似然函数(如GMM),用BIC、DIC等决策;即使没有似然函数,如KMean,也可以搞一个假似然出来,例如用GMM等来代替
4. 基于信息论的方法(Jump法),计算一个distortion函数对K值的曲线,选择其中的jump点
5. Silhouette法
6. 交叉验证
7. 特别地,在文本中,如果词频矩阵为m*n维度,其中t个不为0,则K≈m*n/t
8. 核方法:构造Kernal矩阵,对其做eigenvalue decomposition,通过结果统计Compactness,获得Compactness—K曲线,选择拐点
另外,关于何如选择初始点,一般选择data cloud中相聚较远的点,例如SPSS定义了两个规则来寻找这样的点:
首先随机选K个初始点,然后对其余每个点
a) If the case is farther from the centre closest to it than the distance between two most close to each other centres, the case substitutes that centre of the latter two to which it is closer.
b) If the case is farther from the centre 2nd closest to it than the distance between the centre closest to it and the centre closest to this latter one, the case substitutes the centre closest to it.
最近做了一个数据挖掘的项目,挖掘过程中用到了K-means聚类方法,但是由于根据行业经验确定的聚类数过多并且并不一定是我们获取到数据的真实聚类数,所以,我们希望能从数据自身出发去确定真实的聚类数,也就是对数据而言的最佳聚类数。为此,我查阅了大量资料和博客资源,总结出主流的确定聚类数k的方法有以下两类。
1.手肘法
1.1 理论
手肘法的核心指标是SSE(sum of the squared errors,误差平方和),
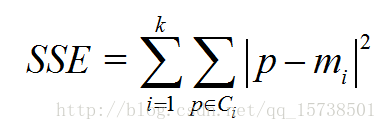
其中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
1.2 实践
我们对预处理后数据.csv 中的数据利用手肘法选取最佳聚类数k。具体做法是让k从1开始取值直到取到你认为合适的上限(一般来说这个上限不会太大,这里我们选取上限为8),对每一个k值进行聚类并且记下对于的SSE,然后画出k和SSE的关系图(毫无疑问是手肘形),最后选取肘部对应的k作为我们的最佳聚类数。python实现如下:
-
import pandas as pd -
from sklearn.cluster import KMeans -
import matplotlib.pyplot as plt -
df_features = pd.read_csv(r'C:\预处理后数据.csv',encoding='gbk') # 读入数据 -
'利用SSE选择k' -
SSE = [] # 存放每次结果的误差平方和 -
for k in range(1,9): -
estimator = KMeans(n_clusters=k) # 构造聚类器 -
estimator.fit(df_features[['R','F','M']]) -
SSE.append(estimator.inertia_) -
X = range(1,9) -
plt.xlabel('k') -
plt.ylabel('SSE') -
plt.plot(X,SSE,'o-') -
plt.show()
画出的k与SSE的关系图如下:
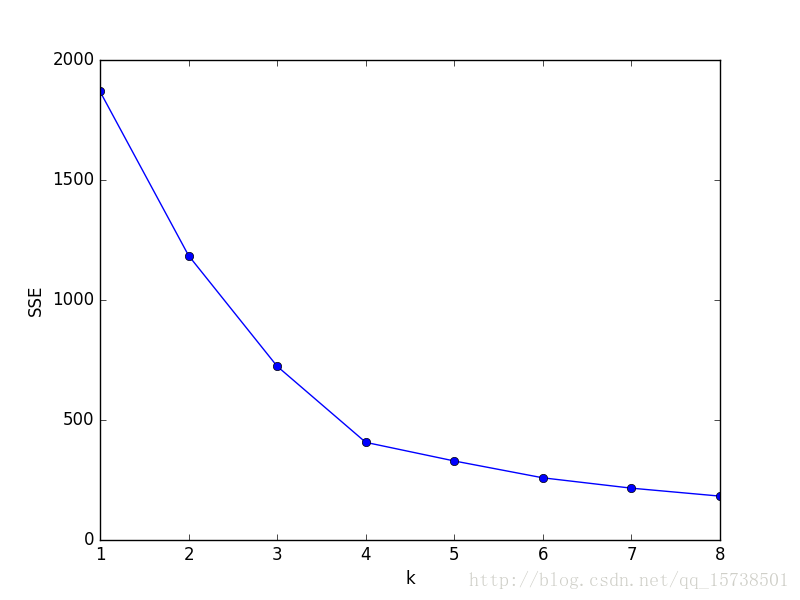
显然,肘部对于的k值为4,故对于这个数据集的聚类而言,最佳聚类数应该选4
2. 轮廓系数法
2.1 理论
该方法的核心指标是轮廓系数(Silhouette Coefficient),某个样本点Xi的轮廓系数定义如下:
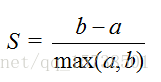
其中,a是Xi与同簇的其他样本的平均距离,称为凝聚度,b是Xi与最近簇中所有样本的平均距离,称为分离度。而最近簇的定义是
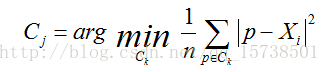
其中p是某个簇Ck中的样本。事实上,简单点讲,就是用Xi到某个簇所有样本平均距离作为衡量该点到该簇的距离后,选择离Xi最近的一个簇作为最近簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。那么,很自然地,平均轮廓系数最大的k便是最佳聚类数。
2.2 实践
我们同样使用2.1中的数据集,同样考虑k等于1到8的情况,对于每个k值进行聚类并且求出相应的轮廓系数,然后做出k和轮廓系数的关系图,选取轮廓系数取值最大的k作为我们最佳聚类系数,python实现如下:
-
import pandas as pd -
from sklearn.cluster import KMeans -
from sklearn.metrics import silhouette_score -
import matplotlib.pyplot as plt -
df_features = pd.read_csv(r'C:\Users\61087\Desktop\项目\爬虫数据\预处理后数据.csv',encoding='gbk') -
Scores = [] # 存放轮廓系数 -
for k in range(2,9): -
estimator = KMeans(n_clusters=k) # 构造聚类器 -
estimator.fit(df_features[['R','F','M']]) -
Scores.append(silhouette_score(df_features[['R','F','M']],estimator.labels_,metric='euclidean')) -
X = range(2,9) -
plt.xlabel('k') -
plt.ylabel('轮廓系数') -
plt.plot(X,Scores,'o-') -
plt.show()
得到聚类数k与轮廓系数的关系图:

可以看到,轮廓系数最大的k值是2,这表示我们的最佳聚类数为2。但是,值得注意的是,从k和SSE的手肘图可以看出,当k取2时,SSE还非常大,所以这是一个不太合理的聚类数,我们退而求其次,考虑轮廓系数第二大的k值4,这时候SSE已经处于一个较低的水平,因此最佳聚类系数应该取4而不是2。
但是,讲道理,k=2时轮廓系数最大,聚类效果应该非常好,那为什么SSE会这么大呢?在我看来,原因在于轮廓系数考虑了分离度b,也就是样本与最近簇中所有样本的平均距离。为什么这么说,因为从定义上看,轮廓系数大,不一定是凝聚度a(样本与同簇的其他样本的平均距离)小,而可能是b和a都很大的情况下b相对a大得多,这么一来,a是有可能取得比较大的。a一大,样本与同簇的其他样本的平均距离就大,簇的紧凑程度就弱,那么簇内样本离质心的距离也大,从而导致SSE较大。所以,虽然轮廓系数引入了分离度b而限制了聚类划分的程度,但是同样会引来最优结果的SSE比较大的问题,这一点也是值得注意的。
总结
从以上两个例子可以看出,轮廓系数法确定出的最优k值不一定是最优的,有时候还需要根据SSE去辅助选取,这样一来相对手肘法就显得有点累赘。因此,如果没有特殊情况的话,我还是建议首先考虑用手肘法。