什么是slf4j
所以slffj需要依赖于log4j来实现,使用log4j2而不是log4j是因为Log4j 1.x 在高并发情况下出现死锁导致cpu使用率异常飙升,而Log4j2.0基于LMAX Disruptor的异步日志在多线程环境下性能会远远优于Log4j 1.x和logback(官方数据是10倍以上)。我们需要注意的是 log4j2 已经弃用了.properties 的配置格式。
怎么将log4j转为log4j2
- 如果您希望将Java源文件迁移到SLF4J,请考虑我们的迁移工具,它可以在几分钟内将您的项目迁移到使用SLF4J API。
- 在maven中删除掉log4j1.x 版本的jar包,然后导入log4j2所需jar包
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions> <dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.5</version>
</dependency>- 或者我们也可以使用桥接jar包,apache官网这么说桥接jar包
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
</dependency>现在开始引入slf4j
解决了log4j到log4j2的问题,接下来我们需要引入slf4j,开始导包
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<!--用于与slf4j保持桥接-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</dependency>我们需要注意的是 log4j2 已经不支持.properties,只支持xml,json或者对yml格式的配置文件。配置文件默认位置在src/main/resources下。如需自定义需要再web.xml添加以下代码
<context-param>
<param-name>log4jConfiguration</param-name>
<param-value>/WEB-INF/classes/log4j2.xml</param-value>
</context-param> 接下来是配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<Configuration monitorinterval="10">
<!--线上环境 cicd-->
<properties>
<property name="LOG_HOME">${sys:log.dir}</property>
<property name="projectName">testProject</property>
</properties>
<!--输出源-->
<Appenders>
<!--输出到控制台-->
<Console name="STDOUT" target="SYSTEM_OUT" follow="true">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss sss} %-5p %t %l(%r) %m%n" />
<ThresholdFilter level="info" />
</Console>
<!--输出到文件-->
<RollingFile name="RollingFileDebug" fileName="${LOG_HOME}/${projectName}/${projectName}.111.log"
filePattern="${LOG_HOME}/${projectName}/${projectName}.log.%d{yyyy-MM-dd HH}h">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss sss} %-5p %t %l %m%n " />
<ThresholdFilter level="DEBUG" />
<Policies>
<TimeBasedTriggeringPolicy interval="24" />
</Policies>
<!--按照时间间隔切割文件,切割间隔为 interval 1h-->
<!--<TimeBasedTriggeringPolicy modulate="true" interval="1" />-->
<!--按照文件大小切割文件,切割跨度为3KB ,单位还可以为MB,GB,TB-->
<!--<SizeBasedTriggeringPolicy size="3KB" />-->
<!--同一时刻只允许存在10个文件-->
<!--<DefaultRolloverStrategy max="10"/>-->
</RollingFile>
<RollingFile name="RollingFileError" fileName="${LOG_HOME}/${projectName}/${projectName}.log"
filePattern="${LOG_HOME}/${projectName}/${projectName}.log.%d{yyyy-MM-dd hh-mm}">
<ThresholdFilter level="ERROR" />
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss sss} %-5p %t %l(%r) %m%n" />
<Policies>
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<!--过滤spring跟mmybatis的繁多的DEBUG信息-->
<logger name="org.springframework" level="INFO" />
<logger name="org.mybatis" level="INFO" />
<root level="DEBUG">
<appender-ref ref="STDOUT" />
<appender-ref ref="RollingFileDebug" />
<appender-ref ref="RollingFileError" />
</root>
</Loggers>
</Configuration>配置文件解析
- <configuration >为根标签 有两个属性
- status:用来指定整个日志的打印级别。
monitorinterval用于指定log4j自动重新配置的监测间隔时间,单位是s,最小是5s.
- .Appenders节点,常见的有三种子节点:Console、RollingFile、File.
- Console节点用来指定输出到控制台的输出源(Appender)
name:指定Appender的名称
target:SYSTEM_OUT 或 SYSTEM_ERR
PatternLayout:输出格式 - RollingFile滚动文件,可以通过配置不同的Policies(策略)来根据时间或者文件大小切割文件
name:Appender的名称
fileName:文件地址
filePattern:切割后或者说滚动后新建的文件名称格式
PatternLayout:输出格式
Policies:指定文件滚动策略
TimeBasedTriggeringPolicy:时间触发的策略,interval用来指定多久滚动一次,默认1h,可以通过filePattern(属性)中设置%d{}来改变单位,如filePattern设置符合*%d{yyyy-MM-dd-HH-mm-ss},那么时间单位就是s。modulate是boolean型,说明是否对封存时间进行调制。若modulate=true,则封存时间将以0点为边界进行偏移计算。比如,modulate=true,interval=4hours,那么假设上次封存日志的时间为03:00,则下次封存日志的时间为04:00,之后的封存时间依次为08:00,12:00,16:00。。。。。。。
SizeBasedTriggeringPolicy:文件大小触发的策略,size是峰值,单位可以自定义:KB,MB,GB,TB
DefaultRolloverStrategy:设置同一个文件夹下面最多有几个滚动日志,超过峰值则删除旧的。
- Loggers节点 有两个子节点Root和Logger
- Root用来指定项目的根日志,如果没有单独指定Logger,那么就会默认使用该Root日志输出,level(属性) 是输出级别All-Trace-Debug-Info-Warn-Error-Fatal-OFF依次递增.
<appender_ref ref="">ref是上面Appender的name值,指定日志输出到那个Appender。 - Logger用来单独指定日志形式,比如为指定包下的class单独指定日志级别等。level(属性)为输出级别。name(属性)用来指定该Logger所使用的类或者类所在的包,继承自root节点。AppenderRef(属性)用来指定该Logger输出到哪个Appender,如果没有指定,就默认继承自Root,如果指定了,则在指定的Appender与Root中都会输出,使用additivity=“false”来定义只在子Appender中输出。 <appender_ref ref="">ref是上面Appender的name值,指定日志输出到那个Appender。
过滤器
我们可以通过过滤器进行一些更加精确的设置,比如 timeFilter,threSholdFilter等等, 点击查看。优先级
- 先在Appender中的<ThreSholdFilter>的level中过滤,滤出的信息再去<AppenderRef>的level中过滤,最后才是去<Root>中的level过滤。(由内至外)
- <Logger>是字日志,<Root>是根日志,<Logger>中的信息不设置additivity默认会在<Root>的Appender中打印。
- Logger>中设置addtivity="false",那么该Logger打印的信息不会在<root>中打印。
Log4j异步Appender(参照Apache官方文档)
对于某些高并发的server,高并发下磁盘io消耗相当严重,我们可以使用log4j2异步Appender,通过在单独的线程中执行I / O操作来提高应用程序的性能.。异步记录器是Log4j 2中的一个新增功能。它们的目标是尽快从调用Logger.log返回到应用程序。您可以选择使所有Loggers异步或使用同步和异步Logger的混合。使所有记录器异步将提供最佳性能,同时混合给你更多的灵活性。
优缺点
尽管异步日志记录可以带来显着的性能优势,但在某些情况下,您可能需要选择同步日志记录。本节介绍了一些异步日志记录的权衡。
优点
峰值吞吐量更高。使用异步记录器,您的应用程序可以以6至68倍的同步记录器速率记录消息。
这对偶尔需要记录消息突发的应用程序尤其有意义。异步日志记录可以通过缩短等待时间来防止或抑制延迟峰值,直到可记录下一条消息。如果队列大小配置得足够大以处理突发事件,异步日志记录将有助于防止应用程序在突然增加活动期间落后(尽可能多)。
- 降低日志响应时间延迟。响应时间延迟是Logger.log调用在给定工作负载下返回所需的时间。异步记录器与同步记录器或甚至基于队列的异步appender相比,具有始终更低的延迟。
- 错误处理。如果在日志记录过程中发生问题并抛出异常,则异步记录器或appender不太容易将此问题告知应用程序。这可以通过配置一个ExceptionHandler来部分缓解,但这可能仍然不能涵盖所有情况。因此,如果日志记录是业务逻辑的一部分,例如,如果您使用Log4j作为审计日志记录框架,则我们建议同步记录这些审计消息。(请注意,除了审核跟踪的同步日志记录之外,您仍然可以将它们组合起来并使用异步日志记录进行调试/跟踪日志记录。)
- 在一些罕见的情况下,必须注意可变信息。大多数时候你不需要担心这一点。LOG4将确保这样的日志消息 logger.debug(“我的目标是{}”,myObject的)将使用的状态 myObject的参数在调用的时候logger.debug() 。即使稍后修改了myObject,日志消息也不会改变。异步记录可变对象是安全的,因为 Log4j内置的大多数 消息实现会拍摄参数的快照。但有一些例外: MapMessage 和 StructuredDataMessage 可以通过设计进行修改:在创建消息对象后,字段可以添加到这些消息中。在使用异步记录器或异步appender记录这些消息后,不应修改这些消息; 您可能会也可能不会看到生成的日志输出中的修改。同样,自定义 Message 实现应该在设计时考虑到异步使用,并且可以在构建时对其参数进行快照,或者记录它们的线程安全特性。
- 如果您的应用程序运行在CPU资源稀缺的环境中,例如一台CPU带单核的机器,则启动另一个线程的性能可能不会提高。
- 如果应用程序记录消息的持续速率比潜在的附加程序的最大持续吞吐量更快,则队列将填满,应用程序将以最慢的附加程序的速度结束记录。如果发生这种情况,请考虑选择更快的appender,或者记录更少。如果这两者都不是一个选项,则可以通过同步记录获得更好的吞吐量和更少的延迟峰值。
操作
- 使所有记录器异步
Log4j-2.9及更高版本需要classpath上的disruptor-3.3.4.jar或更高版本。在Log4j-2.9之前,需要disruptor-3.0.0.jar或更高版本。
这是最简单的配置,并提供最佳性能。要使所有记录器异步,请将disruptor jar添加到类路径中,并将系统属性log4j2.contextSelector设置 为org.apache.logging.log4j.core.async.AsyncLoggerContextSelector。
默认情况下,位置不会通过异步记录器传递到I / O线程。如果您的某个布局或自定义过滤器需要位置信息,则需要在所有相关记录器(包括根记录器)的配置中设置“includeLocation = true”。
贴码
<?xml version="1.0" encoding="UTF-8"?>
<!-- Don't forget to set system property
-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
to make all loggers asynchronous. -->
<Configuration status="WARN">
<Appenders>
<!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. -->
<RandomAccessFile name="RandomAccessFile" fileName="async.log" immediateFlush="false" append="false">
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m %ex%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<Root level="info" includeLocation="false">
<AppenderRef ref="RandomAccessFile"/>
</Root>
</Loggers>
</Configuration>当使用AsyncLoggerContextSelector使所有记录器异步时,请确保在配置中使用普通的 <root>和<logger>元素。AsyncLoggerContextSelector将确保所有记录器都是异步的,使用的机制与配置<asyncRoot> 或<asyncLogger>时发生的机制不同。。后面的元素用于与同步记录器混合异步。如果同时使用这两种机制,则最终会有两个后台线程,您的应用程序将日志消息传递给线程A,线程A将消息传递给线程B,线程B最终将消息记录到磁盘。这有效,但中间会有不必要的步骤。
您可以使用几个系统属性来控制异步日志记录子系统的各个方面。其中一些可用于调整日志记录性能。
还可以通过创建名为log4j2.component.properties的文件并在应用程序的类路径中包含此文件来指定以下属性 。
请注意,系统属性在Log4j 2.10.0中被重新命名为更一致的样式。所有旧的属性名称仍支持这里记录。
| 系统属性 | 默认值 | 描述 |
|---|---|---|
| log4j2.asyncLoggerExceptionHandler | 默认处理器 | 实现com.lmax.disruptor.ExceptionHandler 接口的类的完全限定名称。该类需要有一个公共的零参数构造函数。如果指定,则在记录消息时发生异常时将通知此类。 如果未指定,则默认异常处理程序将向标准错误输出流打印消息和堆栈跟踪。 |
| log4j2.asyncLoggerRingBufferSize | 256 * 1024 | 异步日志子系统使用的RingBuffer中的大小(槽数)。使此值足够大以处理活动爆发。最小尺寸为128. RingBuffer将在首次使用时预先分配,并且在系统的使用期限内不会增长或缩小。 当应用程序的记录速度快于底层appender可以跟上足够长的时间以填满队列时,行为将由AsyncQueueFullPolicy确定 。 |
| log4j2.asyncLoggerWaitStrategy | 时间到 | 有效值:阻止,超时,睡眠,收益。 Block是一种为I / O线程等待日志事件使用锁定和条件变量的策略。当吞吐量和低延迟不如CPU资源重要时,可以使用Block。建议用于资源受限/虚拟化环境。 Timeout是Block策略的一种变体,它会周期性地从锁定状态await()调用中唤醒。这确保了如果通知被遗漏,消费者线程不会被卡住,但会以小的延迟时间(默认10ms)恢复。 睡觉是一种最初旋转的策略,然后使用Thread.yield(),并最终停放OS和JVM在I / O线程等待日志事件时允许的最小纳米数量。睡眠是性能和CPU资源之间的良好折中。此策略对应用程序线程的影响非常低,以换取实际获取消息记录的一些额外延迟。 Yield是一种使用Thread.yield()等待初始旋转后的日志事件的策略。良率是性能和CPU资源之间的良好折衷,但可能会使用比休眠更多的CPU,以便更快地将消息记录到磁盘。 |
| log4j2.asyncLoggerThreadNameStrategy | CACHED | 有效值:CACHED,UNCACHED。 默认情况下,AsyncLogger将线程名称缓存在ThreadLocal变量中以提高性能。如果您的应用程序在运行时修改了线程名称(使用Thread.currentThread()。setName())并且您想要查看日志中反映的新线程名称,请指定UNCACHED选项 。 |
| log4j2.clock | SystemClock | 实现org.apache.logging.log4j.core.util.Clock 接口,用于在所有记录器异步时对日志事件进行时间戳记。 CachedClock是一种针对低延迟应用程序的优化,其中时间戳由每毫秒或每1024个日志事件(以先到者为准)在后台线程中更新其内部时间的时钟生成。这会稍微减少日志记录延迟,但会以记录的时间戳中的某些精度为代价。除非记录许多事件,否则在日志时间戳之间可能会看到10-16毫秒的“跳跃”。WEB应用程序警告:使用后台线程可能会导致Web应用程序和OSGi应用程序出现问题,因此不推荐将CachedClock用于此类应用程序。 您还可以指定实现Clock接口的自定义类的完全限定类名称 。 |
即使在底层appender无法跟上日志记录速率和队列填满的情况下,也可以使用少数系统属性来维护应用程序吞吐量。查看系统属性log4j2.asyncQueueFullPolicy和 log4j2.discardThreshold的详细信息 。
- 混合同步和异步记录器
Log4j-2.9及更高版本需要classpath上的disruptor-3.3.4.jar或更高版本。在Log4j-2.9之前,需要disruptor-3.0.0.jar或更高版本。没有必要将系统属性“Log4jContextSelector”设置为任何值。
同步和异步记录器可以配置组合。这样可以在性能略有下降的情况下提供更大的灵活性(与使所有记录器异步)相比。使用<asyncRoot>或<asyncLogger> 配置元素来指定需要异步的记录器。配置只能包含一个根记录器(<root> 或<asyncRoot>元素),但可以组合异步和非异步记录器。例如,包含<asyncLogger>元素的配置文件也可以包含<root>和 < 同步记录器的元素。
默认情况下,位置不会通过异步记录器传递到I / O线程。如果您的某个布局或自定义过滤器需要位置信息,则需要在所有相关记录器(包括根记录器)的配置中设置“includeLocation = true”。
混合异步记录器的配置可能如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!-- No need to set system property "log4j2.contextSelector" to any value
when using <asyncLogger> or <asyncRoot>. -->
<Configuration status="WARN">
<Appenders>
<!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. -->
<RandomAccessFile name="RandomAccessFile" fileName="asyncWithLocation.log"
immediateFlush="false" append="false">
<PatternLayout>
<Pattern>%d %p %class{1.} [%t] %location %m %ex%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<!-- pattern layout actually uses location, so we need to include it -->
<AsyncLogger name="com.foo.Bar" level="trace" includeLocation="true">
<AppenderRef ref="RandomAccessFile"/>
</AsyncLogger>
<Root level="info" includeLocation="true">
<AppenderRef ref="RandomAccessFile"/>
</Root>
</Loggers>
</Configuration>
您可以使用几个系统属性来控制异步日志记录子系统的各个方面。其中一些可用于调整日志记录性能。
还可以通过创建名为log4j2.component.properties的文件并在应用程序的类路径中包含此文件来指定以下属性 。
请注意,系统属性在Log4j 2.10中被重新命名为更一致的样式。所有旧的属性名称仍支持这里记录。
| 系统属性 | 默认值 | 描述 |
|---|---|---|
| log4j2.asyncLoggerConfigExceptionHandler | 默认处理器 | 实现com.lmax.disruptor.ExceptionHandler 接口的类的完全限定名称。该类需要有一个公共的零参数构造函数。如果指定,则在记录消息时发生异常时将通知此类。 如果未指定,则默认异常处理程序将向标准错误输出流打印消息和堆栈跟踪。 |
| log4j2.asyncLoggerConfigRingBufferSize | 256 * 1024 | 异步日志子系统使用的RingBuffer中的大小(槽数)。使此值足够大以处理活动爆发。最小尺寸为128. RingBuffer将在首次使用时预先分配,并且在系统的使用期限内不会增长或缩小。 当应用程序的记录速度快于底层appender可以跟上足够长的时间以填满队列时,行为将由AsyncQueueFullPolicy确定 。 |
| log4j2.asyncLoggerConfigWaitStrategy | 时间到 | 有效值:阻止,超时,睡眠,收益。 Block是一种为I / O线程等待日志事件使用锁定和条件变量的策略。当吞吐量和低延迟不如CPU资源重要时,可以使用Block。建议用于资源受限/虚拟化环境。 Timeout是Block策略的一种变体,它会周期性地从锁定状态await()调用中唤醒。这确保了如果通知被遗漏,消费者线程不会被卡住,但会以小的延迟时间(默认10ms)恢复。 睡觉是一种最初旋转的策略,然后使用Thread.yield(),并最终停放OS和JVM在I / O线程等待日志事件时允许的最小纳米数量。睡眠是性能和CPU资源之间的良好折中。此策略对应用程序线程的影响非常低,以换取实际获取消息记录的一些额外延迟。 Yield是一种使用Thread.yield()等待初始旋转后的日志事件的策略。良率是性能和CPU资源之间的良好折衷,但可能会使用比休眠更多的CPU,以便更快地将消息记录到磁盘。 |
即使在底层appender无法跟上日志记录速率和队列填满的情况下,也可以使用少数系统属性来维护应用程序吞吐量。查看系统属性log4j2.asyncQueueFullPolicy和 log4j2.discardThreshold的详细信息 。
注意:
如果其中一个布局配置了与位置相关的属性(如HTML locationInfo)或其中一个模式%C或$ class, %F或%file, %l或%location, %L或%line, %M或%方法,Log4j将拍摄堆栈的快照,然后走栈跟踪以查找位置信息。
这是一项昂贵的操作:对同步记录仪来说,速度要慢1.3至5倍。同步记录器在进行堆栈快照前尽可能长时间地等待。如果不需要位置,则不会拍摄快照。
但是,异步记录器需要在将日志消息传递给另一个线程之前作出此决定; 该点后的位置信息将会丢失。采用堆栈跟踪快照对异步记录器的性能影响甚至更高:使用位置记录比没有位置记录慢30-100倍。出于这个原因,异步记录器和异步appender默认不包含位置信息。
您可以通过指定includeLocation =“true”来覆盖记录器或异步appender配置中的缺省行为。
记录峰值吞吐量
下图比较了 同步记录器,异步appender(应该是混合异步)和异步记录器(全异步)的吞吐量。这是所有线程的总吞吐量。在使用64个线程的测试中,异步记录器比异步记录器快12倍,比同步记录器快68倍。
异步记录器的吞吐量随着线程数量的增加而增加,而无论执行日志记录的线程数量如何,同步记录器和异步appender都具有或多或少的恒定吞吐量。
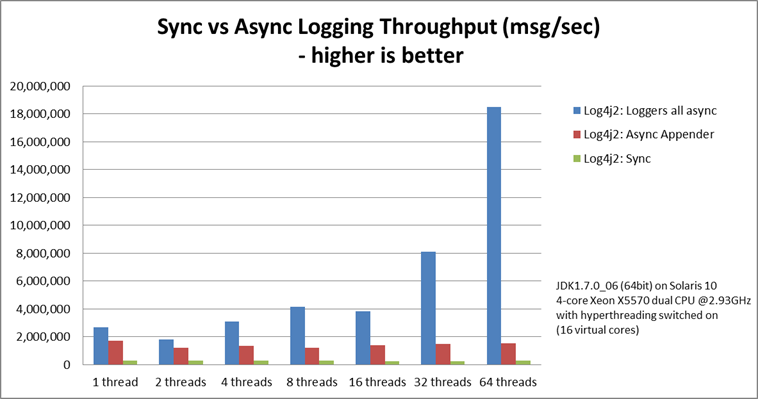
与其他日志记录软件包的异步吞吐量比较
我们还将异步记录器的峰值吞吐量与其他日志记录软件包中提供的同步记录器和异步appender进行了比较,具体来说,log4j-1.2.17和logback-1.0.10具有类似的结果。对于异步appender,当添加更多线程时,所有线程的总日志吞吐量一起保持大致不变。异步记录器可以更有效地利用多线程场景中机器上可用的多个内核。
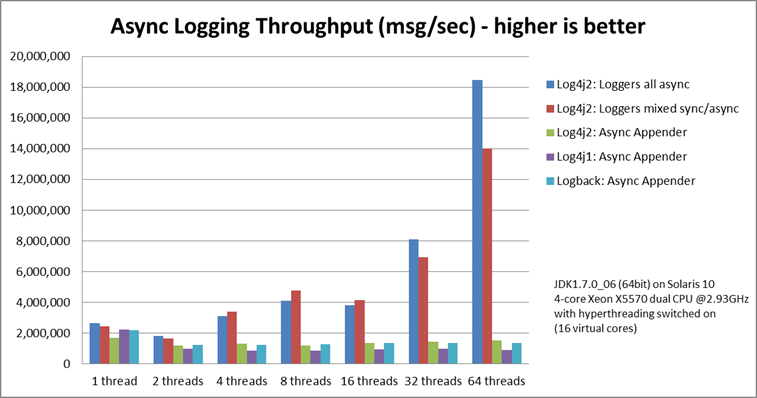
个人原创,转载需经博主同意且标明出处