DQL:(Data Query Language)数据查询语言
目录
1、连接mysql
mysql -u 用户名 -p 密码
提示:密码写在命令是可视的;不写密码直接回车密码是加密不可视的。
注:
- 以下命令都是在mysql命令行执行的
mysql命令不见分号不执行,分号代表这一条命令的结束,没有分号直接回车也是一条命令。- 如果写错命令,可以使用
\c结束命令,该条命令不会被执行。 - mysql命令不区分大小写。
2、 查看MySQL数据库的版本号
select version();
3、退出mysql
exit
4、查看数据库
show databases;
5、创建数据库
create database 数据库名;
6、使用数据库
use 数据库名;
7、查看当前使用的是哪个数据库
select database();
8、执行sql文件
source sql文件路径;
9、数据查询语言(DQL-Data Query Language)
1. 查询一个字段
select 字段名 from 表名;
2. 查询两个或多个字段
多个字段使用逗号,隔开
select 字段1,字段2,字段n from 表名;
3. 查询所有字段
-
方式一:
select * from 表名;缺点:可读性较差,效率较低,实际开发不建议使用。
-
方式二:
select 字段1,字段2,...,字段n from 表名;缺点:麻烦,但是工作中推荐。
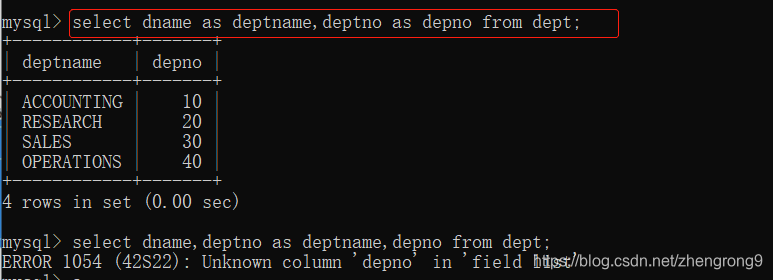
4. 给查询的字段取别名
select 字段 as 别名 from 表名;
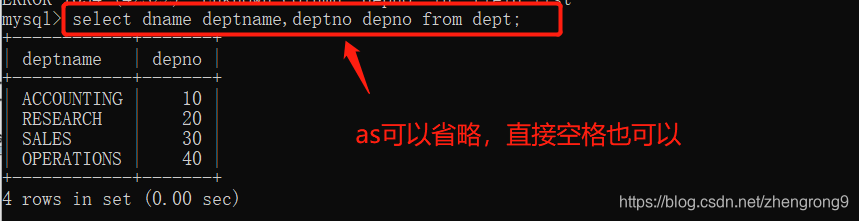
注:使用as关键字给列取别名,只是修改显示的查询结果列名,并不会修改原表列名。
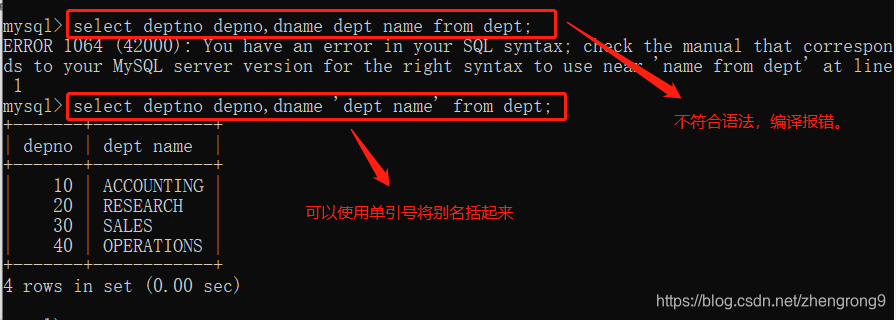
问:如果使用空格的方式取别名,别名里有空格,怎么办?
答:将别名用引号括起来
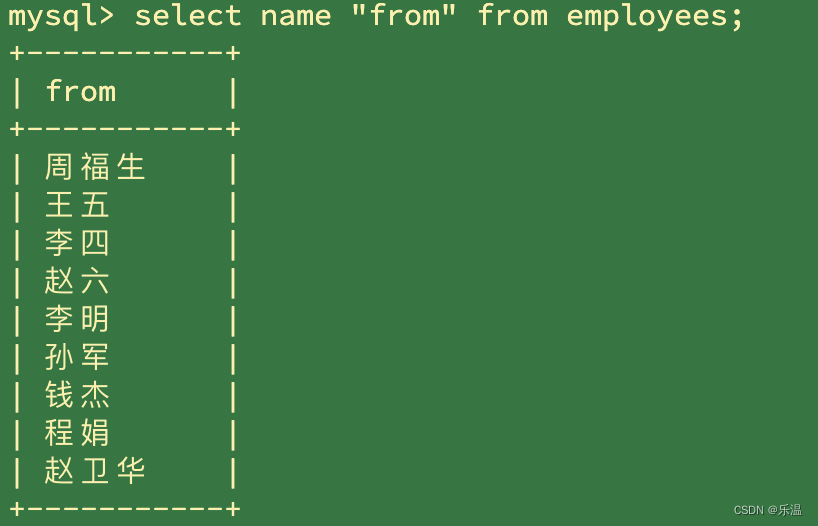
注:不可以使用数据库关键字作为别名,如果非要使用需要用引号括起来。
5. 条件查询
select 字段1,字段2,... from 表名 where 条件;
| 符号 | 含义 |
|---|---|
| = | 等于 |
| <> 或 != | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| between … and … | 两个值之间。闭区间,相当于 >= and <=。 |
| is null | 是否为空,只返回条件为True的数据。is not null是否不为空。 |
| not | 非,主要与is或in连用 |
| and | 且,返回满足所有条件的数据。 |
| or | 或,返回满足某一条件的数据。 |
| in | 包含,相当于多个or。 |
| like | 模糊查询。%匹配任意个字符,_匹配一个字符。 |
注:
- and的优先级高于or,可以使用小括号
()调整优先级。 - 模糊查询中,
%和_是关键字,具有特殊含义,不能直接使用,需要使用反斜杠\进行转义,将其转成普通字符。
6. 排序
select 查询字段1,查询字段2,... from 表名 order by 排序字段1,排序字段2,...;
说明:
- 查询字段即为查询结果显示的字段,要查询多个就写多个字段名,排序字段是通过该字段进行排序,只要是该表存在的字段即可,不一定会在结果中显示出来。
- 默认为升序
asc,降序为desc,排序方式写在字段名的后面。 - 按照多个字段进行排序,先按照前面的字段排,如果数据一样再按照后面的字段进行排序。
- 如果存在where子句,order by必须放到where语句的后面。
也可以通过字段位置进行排序
select ename,sal from emp order by 2;
说明:
- 2表示第2列,按照 查询结果 的第二列(sal)进行排序。
7. 数据处理函数
数据处理函数又被称为单行处理函数。特点是输入一行输出一行,处理后表格行数不变。
lower:将数据中的字母全部转成小写字母
mysql> select lower(ename) from emp;
+--------------+
| lower(ename) |
+--------------+
| smith |
| allen |
| ward |
| james |
| ford |
| miller |
+--------------+
upper:将数据中的字母全部转成大写字母
mysql> select upper(name) from stu;
+-------------+
| upper(name) |
+-------------+
| ZHANGSAN |
| LISI |
| WANGWU |
| MICHEL_MIKE |
+-------------+
4 rows in set (0.00 sec)
substr(str,start,len):截取子串
说明:
str:要进行截取操作的字段名。
start:起始位置,从哪里开始截取。从1开始。
len:截取的长度。
mysql> select substr(w,1,3) as day from week;
+------+
| day |
+------+
| Mon |
| Tue |
| Wed |
| Thu |
| Fri |
| Sat |
| Sun |
+------+
7 rows in set (0.00 sec)
concat(s1,s2,s3,...):字符串拼接
mysql> select concat(upper(substr(name,1,1)),substr(name,2,length(name)-1)) as sname from stu;//首字母大写
+-------------+
| sname |
+-------------+
| Zhangsan |
| Lisi |
| Wangwu |
| Michel_mike |
+-------------+
4 rows in set (0.00 sec)
trim:去除字符串首尾的空格
mysql> select * from emp where ename=trim(' K ING');
Empty set (0.00 sec)
mysql> select * from emp where ename=trim(' KING ');
+-------+-------+-----------+------+------------+---------+------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+-------+-----------+------+------------+---------+------+--------+
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
+-------+-------+-----------+------+------------+---------+------+--------+
1 row in set (0.00 sec)
str_to_date:将字符串转化成日期- date_format:格式化日期,将日期转化为具有特定格式的字符串
str_to_date 与 date_format使用方法 - format:设置千分位,对数字进行格式化
round(num,int):四舍五入
说明:
num:数据,可以是字段名。如果是数据的话,将会得到一列相同的数据。
int:需要保留的小数位数,0–个位,1–保留一位小数,-1–十位,-2–百位,以此类推。
mysql> select round(123.456,1) as cases from stu;
+-------+
| cases |
+-------+
| 123.5 |
| 123.5 |
| 123.5 |
| 123.5 |
+-------+
4 rows in set (0.00 sec)
- rand(): 生成随机数。
mysql> select round(rand()*100,0) from stu;
+---------------------+
| round(rand()*100,0) |
+---------------------+
| 73 |
| 63 |
| 95 |
| 87 |
+---------------------+
4 rows in set (0.00 sec)
ifnull(数据,被当做什么值):将NULL转换成一个具体值
ifnull是空处理函数,专门用来处理空值的。
注:在所有数据当中,只要有NULL参与的数学运算,最终结果就是NULL。如下例:
mysql> select ename,sal,comm,sal+comm as salcomm from emp;
+--------+---------+---------+---------+
| ename | sal | comm | salcomm |
+--------+---------+---------+---------+
| SMITH | 800.00 | NULL | NULL |
| ALLEN | 1600.00 | 300.00 | 1900.00 |
| WARD | 1250.00 | 500.00 | 1750.00 |
| JONES | 2975.00 | NULL | NULL |
| MARTIN | 1250.00 | 1400.00 | 2650.00 |
| BLAKE | 2850.00 | NULL | NULL |
| CLARK | 2450.00 | NULL | NULL |
| SCOTT | 3000.00 | NULL | NULL |
| KING | 5000.00 | NULL | NULL |
| TURNER | 1500.00 | 0.00 | 1500.00 |
| ADAMS | 1100.00 | NULL | NULL |
| JAMES | 950.00 | NULL | NULL |
| FORD | 3000.00 | NULL | NULL |
| MILLER | 1300.00 | NULL | NULL |
+--------+---------+---------+---------+
14 rows in set (0.00 sec)
从以上例子可以看出当NULL参与运算时,结果仍旧是NULL,存在问题,所以需要ifnull函数对NULL进行处理。
mysql> select ename,sal,comm,sal+ifnull(comm,0) as salcomm from emp;
+--------+---------+---------+---------+
| ename | sal | comm | salcomm |
+--------+---------+---------+---------+
| SMITH | 800.00 | NULL | 800.00 |
| ALLEN | 1600.00 | 300.00 | 1900.00 |
| WARD | 1250.00 | 500.00 | 1750.00 |
| JONES | 2975.00 | NULL | 2975.00 |
| MARTIN | 1250.00 | 1400.00 | 2650.00 |
| BLAKE | 2850.00 | NULL | 2850.00 |
| CLARK | 2450.00 | NULL | 2450.00 |
| SCOTT | 3000.00 | NULL | 3000.00 |
| KING | 5000.00 | NULL | 5000.00 |
| TURNER | 1500.00 | 0.00 | 1500.00 |
| ADAMS | 1100.00 | NULL | 1100.00 |
| JAMES | 950.00 | NULL | 950.00 |
| FORD | 3000.00 | NULL | 3000.00 |
| MILLER | 1300.00 | NULL | 1300.00 |
+--------+---------+---------+---------+
14 rows in set (0.00 sec)
case .. when .. then .. when .. then .. else ..end:当什么时候怎么做,当什么时候怎么做,其他情况怎么办。
案例:当员工职位为MANAGER时,工资上调10%;当员工职位为SALESMAN时,工资上调30%。
mysql> select ename,job,(case job
-> when job='MANAGER' then sal*1.1
-> when job='SALESMAN' then sal*1.3
-> else sal end) as newsal
-> from emp;
+--------+-----------+---------+
| ename | job | newsal |
+--------+-----------+---------+
| SMITH | CLERK | 880.00 |
| ALLEN | SALESMAN | 1760.00 |
| WARD | SALESMAN | 1375.00 |
| JONES | MANAGER | 3867.50 |
| MARTIN | SALESMAN | 1375.00 |
| BLAKE | MANAGER | 3705.00 |
| CLARK | MANAGER | 3185.00 |
| SCOTT | ANALYST | 3300.00 |
| KING | PRESIDENT | 5500.00 |
| TURNER | SALESMAN | 1650.00 |
| ADAMS | CLERK | 1210.00 |
| JAMES | CLERK | 1045.00 |
| FORD | ANALYST | 3300.00 |
| MILLER | CLERK | 1430.00 |
+--------+-----------+---------+
14 rows in set, 14 warnings (0.00 sec)
8. 聚合查询
分组函数又被称为多行处理函数,特点是输入多行,输出一行,处理后表格行数减少。
| 函数 | 含义 |
|---|---|
| count | 计数 |
| sum | 求和 |
| avg | 平均值 |
| max | 最大值 |
| min | 最小值 |
注:
- 分组函数在使用时需要先进行分组,然后才能用。如果没有进行分组,整张表默认为一组。
- 分组函数自动忽略NULL,不需要提前对NULL进行处理。
- count(具体字段)和count(*)的区别?
count(具体字段):表示统计该字段下所有不为NULL的数据总数。
count(*):统计表的总行数,只要有一行有一个数据就计数。 - 分组函数不能直接使用在where子句中。 因为where执行的时候还没有分组,而分组函数使用之前要先分组。
- 所有的分组函数可以组合使用。
9. 分组查询
select 字段 from 表名 group by 分组字段 having 条件;
- having子句既可以包含聚合函数作用的字段,也可以包含普通的标量字段。
- where子句是过滤行,having子句是过滤分组。
- having必须和group by连用。有having必须有group by,有group by不一定要有having。
mysql> select job,count(ename) from emp group by job;
+-----------+--------------+
| job | count(ename) |
+-----------+--------------+
| CLERK | 4 |
| SALESMAN | 4 |
| MANAGER | 3 |
| ANALYST | 2 |
| PRESIDENT | 1 |
+-----------+--------------+
5 rows in set (0.00 sec)
注:
在一条select语句中如果有group by语句的话,select后面只能跟参加分组的字段和分组函数(可以有多个),其他的字段不能跟。虽然不会报错,但是毫无意义,且在Oracle会中报错。
总结
关键字语句书写顺序
select … from … where … group by … having … order by …
语句执行顺序
- from
- where
- group by
- having
- select
- order by
练习案例
案例1 找出“每个部门不同岗位的”最高薪资?
mysql> select ename,deptno,job,max(sal) from emp group by deptno,job;
+--------+--------+-----------+----------+
| ename | deptno | job | max(sal) |
+--------+--------+-----------+----------+
| SMITH | 20 | CLERK | 1100.00 |
| ALLEN | 30 | SALESMAN | 1600.00 |
| JONES | 20 | MANAGER | 2975.00 |
| BLAKE | 30 | MANAGER | 2850.00 |
| CLARK | 10 | MANAGER | 2450.00 |
| SCOTT | 20 | ANALYST | 3000.00 |
| KING | 10 | PRESIDENT | 5000.00 |
| JAMES | 30 | CLERK | 950.00 |
| MILLER | 10 | CLERK | 1300.00 |
+--------+--------+-----------+----------+
9 rows in set (0.00 sec)
案例2 找出每个部门的最高薪资,要求显示最高薪资大于3000的?
mysql> select deptno,max(sal) from emp group by deptno having max(sal)>3000;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
+--------+----------+
1 row in set (0.00 sec)
mysql> select deptno,max(sal) from emp where sal>3000 group by deptno;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
+--------+----------+
1 row in set (0.00 sec)
结论:where和having,优先选择where,where不能解决的再用having。
案例3 找出每个岗位的平均薪资,要求降序显示除MANAGER岗位以外平均薪资大于1500的。
mysql> select job,avg(sal) avgsal from emp where job != 'MANAGER' group by job having avg(sal)>1500 order by avgsal desc;
+-----------+-------------+
| job | avgsal |
+-----------+-------------+
| PRESIDENT | 5000.000000 |
| ANALYST | 3000.000000 |
+-----------+-------------+
2 rows in set (0.00 sec)