优质博文:IT-BLOG-CN
一、问题描述
淘宝后台应用从今年某个时间开始docker oom的量突然变多,确定为堆外内存泄露。
后面继续按照上一篇对外内存分析方法的进行排查(jemalloc、pmap、malloc+pmap/maps+NMT+jstack+gdb),但都没有定位到问题。至于为什么没有定位到问题,后面会根据问题的特点进行分析。
至此,回到原点。其实也不是原点,最起码已经确定了是堆外内存off-heap,而不是Native Memory(JVM自身所用内存)泄露。所以你看,很多时候问题排查其实是排除法(苦涩的笑)。
二、排查过程
堆外内存off-heap的泄露,不外乎有以下几个原因:
【1】流没有关闭;
【2】Unsafe.allocateMemory内存没释放;
【3】jni内存没有释放;
其中流没有关闭是最常见的,而2和3出现的概率是比较低的,所以先排查流没有关闭的可能。
2.1 走寻常路
对于流没有关闭导致泄露的定位,一般来说有以下4种方式:
【1】看代码;
【2】用jemalloc分析;
【3】分析堆内存找小尾巴;
2.1.1 看代码
流未关闭的话,一般来说都是因为没有显式地调用close()方法或没有使用try-with-resource的方式管理流。比如下面这段代码就存在流未关闭的情形:
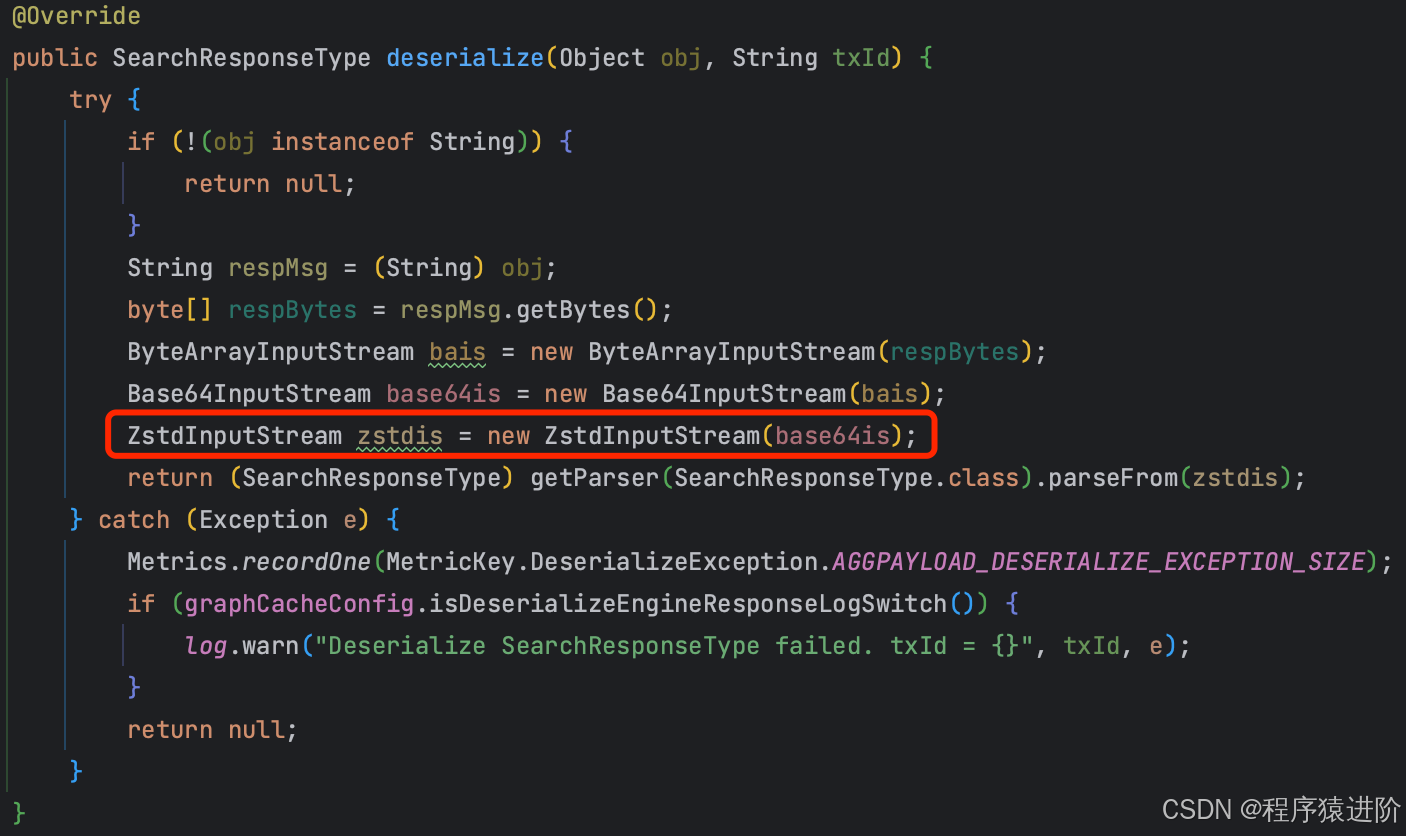
像下面的这段代码,流会被try-with-resource机制去关闭,正常情况下不会出现内存泄露。而存在泄露的应用,恰恰就是用try-with-resource机制去管理流,所以排除这里的嫌疑。
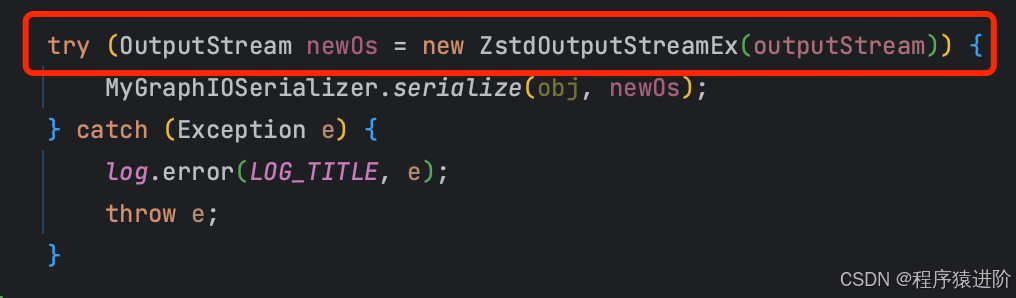
2.1.2 用jemalloc分析
这里用到jemalloc主要是利用它的heap dump以及它的jeprof命令来分析java进程的内存分配情况。注意这里的heap不是jvm堆内存,而是操作系统视角的内存布局,比如heap、stack、BSS、数据段、代码段,这里不是本文的重点,就不展开描述了……
使用jemalloc分析内存分配的过程很多文章都有描述,这里也不展开了,结果是通过jeprof生成的pdf文件,依然没有发现导致流未关闭的场景,只能作罢。
2.1.3 分析堆内存
通过看代码的方式以及jemalloc都没法定位到流未关闭的情形,考虑代码走查难免有遗漏,同时应用使用了大量的第三方组件,第三方组件会不会存在流未关闭的可能呢?但很显然,如果去分析第三方组件的代码会累吐血。联想到流没有关闭的情形,一般会在堆内存里面留一些引用的痕迹,于是开始dump java堆内存。
内存dump下来后,通过MAT查找java.lang.ref.Finalizer、InputStream、OutputStream相关的对象,依然一无所获,这时开始怀疑内存的泄露跟流未关闭没有关系。
2.1.4 内部工具分析
公司内部提供了一个跟踪内存分配的工具,通过扩展malloc方法获取到分配内存的调用线程和内存地址,通过jstack打印线程栈,结合gdb、pmap等方式获取可疑内存段,以定位内存泄露源头。通过这种方式依然没有找到任何线索,同时jstack的方式会导致应用出现短暂的停顿safepoint而影响性能,所以这种方式也放弃了。
2.2 走了弯路
在暂时排除了流未关闭的嫌疑后,这时转向分析直接用Unsafe.allocateMemory分配的内存。有些组件不会基于java.nio.DirectByteBuffer(int cap)申请堆外内存,而是直接用unsafe.allocateMemory方法申请内存,这时候MaxDirectMemorySize是限制不住堆外内存的用量的,当然基于DirectByteBuffer申请的堆外内存,最终也是基于unsafe.allocateMemory方法申请内存,所以这里只要分析unsafe.allocateMemory申请的内存即可。到这里,前面提到的神器async-profiler就粉墨登场了。
async-profiler的安装步骤这里就不介绍了,可以自行安装。安装完毕使用以下脚本就可以分析Unsafe_AllocateMemory0的内存分配情况了。
sudo -u deploy /tmp/async-profiler-2.9-linux-x64/profiler.sh -e Unsafe_AllocateMemory0 -d 1200 -f /tmp/unsafe_alloc-$(pgrep java)-$(date +'%y%m%d%H%M').html $(pgrep java)
这里-e代表要分析的事件,-d代表分析的时长,以秒为单位。生成的结果是一张火焰图,你可以下载下来在浏览器上查看哪块用到了Unsafe_AllocateMemory0来分配内存。
比较悲催的是,通过Unsafe_AllocateMemory0分配的内存比较少,所以这里的嫌疑也被排除了。所以分析Unsafe_AllocateMemory0这一步算是走了弯路。
2.3 柳暗花明
前面所有的手段都用尽之后,已经快一个星期过去了。在前面的手段都用尽之后,尝试分析jni的内存分配情况。其实这时候有点死马当作活马医的味道了。
jni(Java Native Interface),简单说就是Java调用c/c++写的程序,实现更强的功能。c写的程序,要分配内存,一般是通过malloc()方法向操作系统申请内存。在malloc的实现中,一般分配大块内存 128KB会使用mmap分配内存空间。而async-profiler可以通过分析linux perf_event中的perf_event_mmap_page来追踪内存分配情况的。想到这里,便尝试通过下面的命令来追踪系统层面malloc情况:
sudo -u deploy /tmp/async-profiler-2.9-linux-x64/profiler.sh --loop 1h -e malloc -f /tmp/malloc-$(pgrep java)-%t.html $(pgrep java)
这个命令中的–loop参数是能够以1个小时间隔不间断跟踪内存分配情况,如果你想长时间进行问题定位,可以尝试使用一下这个参数,profiler会每隔1个小时生成一个html文件,是不是很方便?
-e malloc就是告诉async-profiler去追踪perf_event_mmap_page的内存分配。
运行了1个小时后,就得到了下面的这个内存分配火焰图:
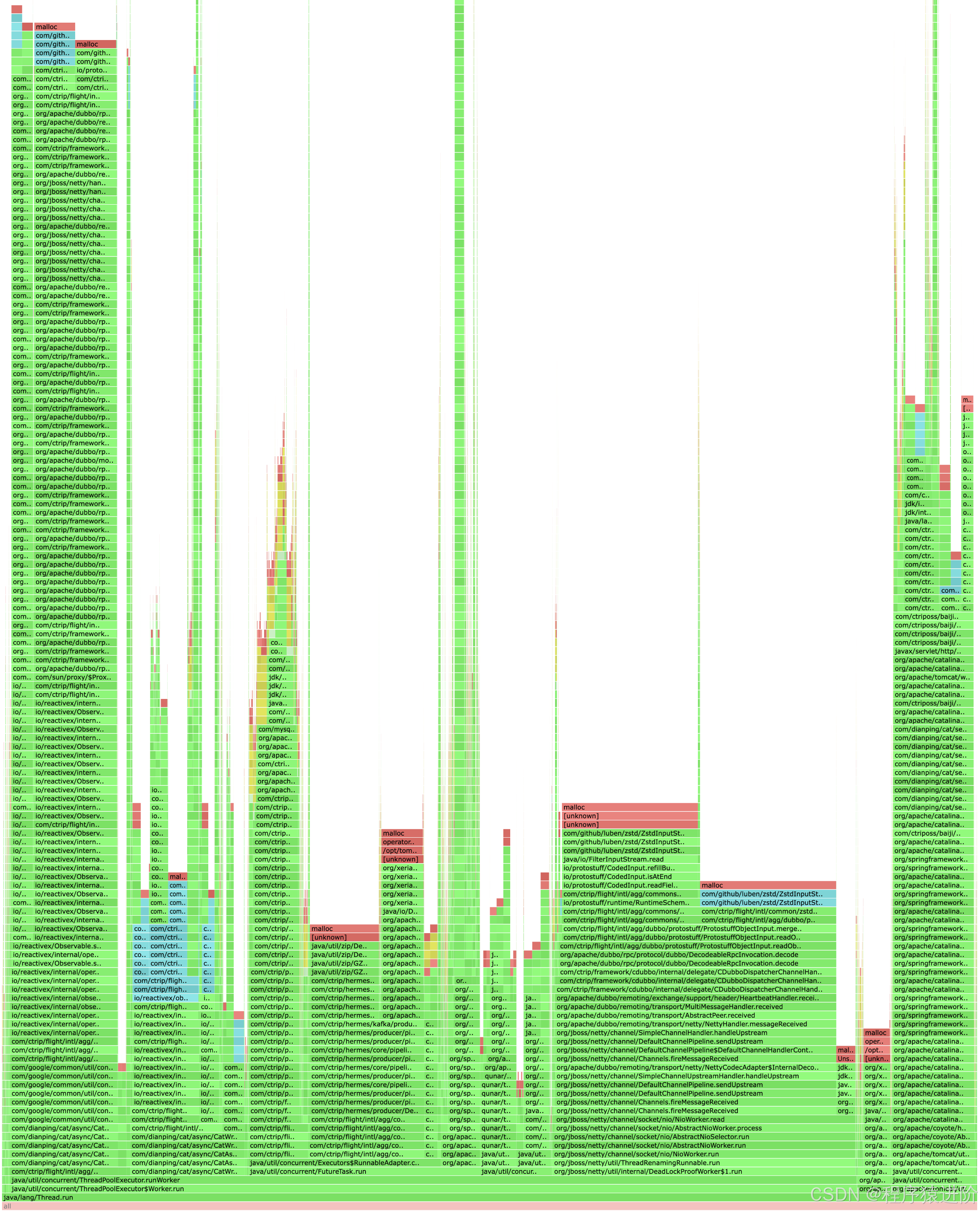
从图中可以看出,zstd-jni这个组件分配了大量的内存。因为在之前我们通过review代码排查流没有关闭的场景时,是看过这段代码的,但当时没有发现什么问题。但从火焰图中看到分配的内存量,总感觉不对劲。这时候忽然想到,能不能从日志中找到什么蛛丝马迹呢?于是开始扒日志,这时,一个broken pipe的异常引起了我的注意:
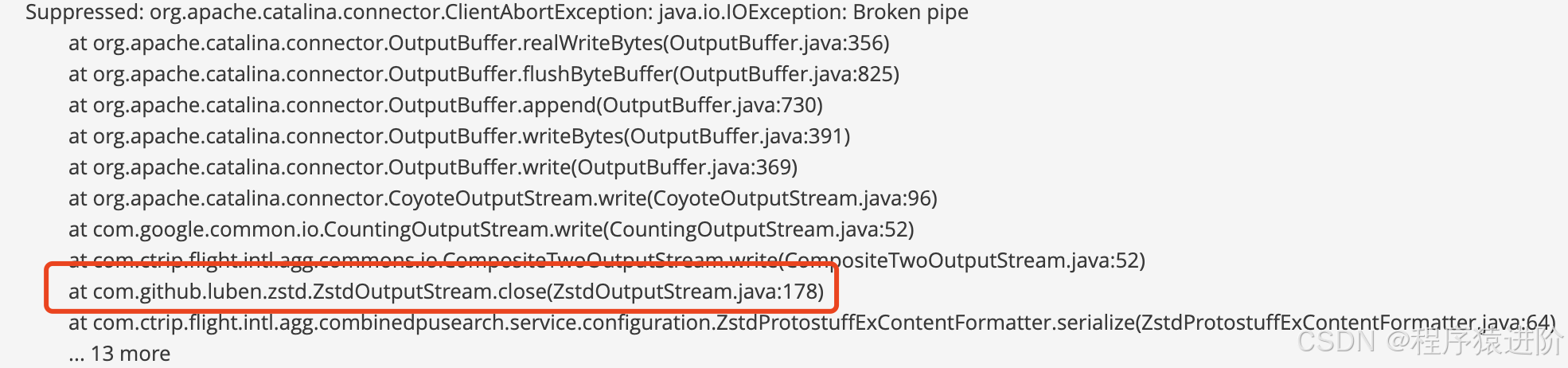
这种broken pipe的异常其实蛮常见的,尤其在有一方断开连接时,很容易就出现这种异常。但顺着调用栈往下看,顿时眼前一亮,其中有ZstdOutputStream的调用。流里面的异常那是很容易泄露的,于是进入到ZstdOutputStream.java 178行看代码,发现了zstd-jni 1.3.x版本存在的bug:当ZstdOutputStream关闭流的时候,会尝试把剩余的数据发送出去。但这时候如果连接已经关闭了,它就咯咯了,导致流关闭不掉,jni的内存也释放不掉。
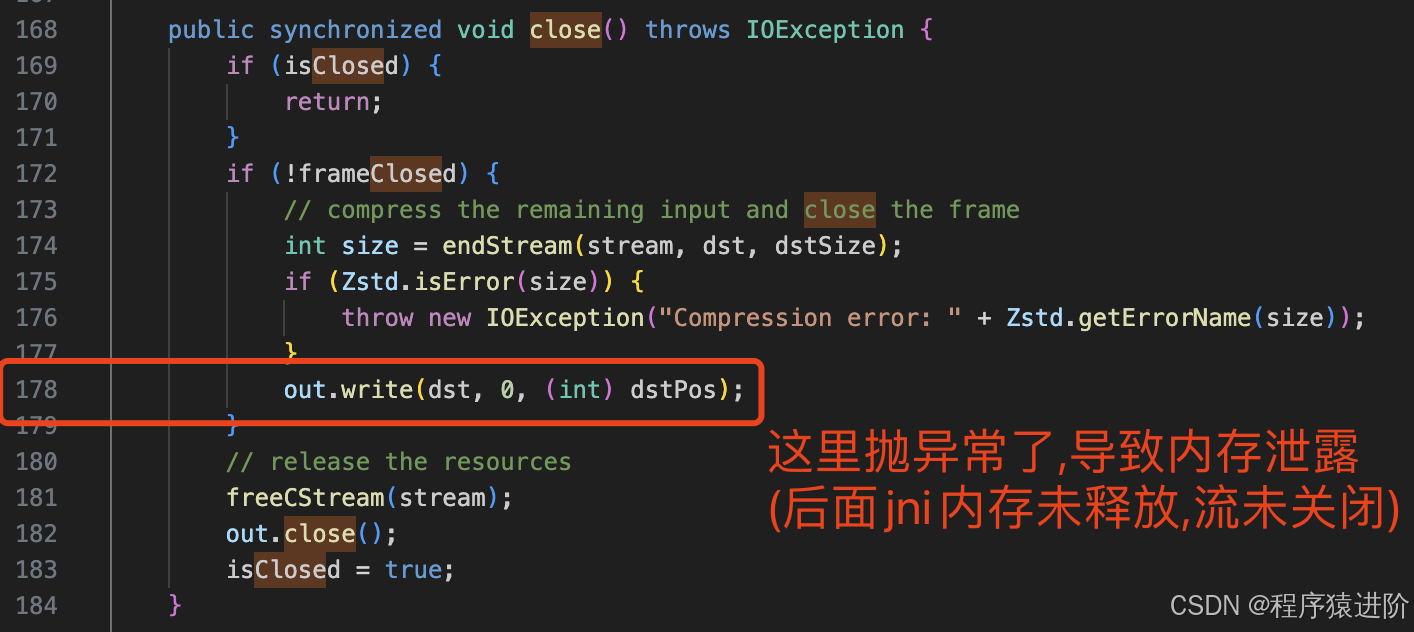
这个bug,在1.4.4-11版本中就修复了,我们可以看到作者用try-finally捕获了out.write的异常,这样不管zstd依赖的流的状态如何,它最终都会释放自己使用的资源。
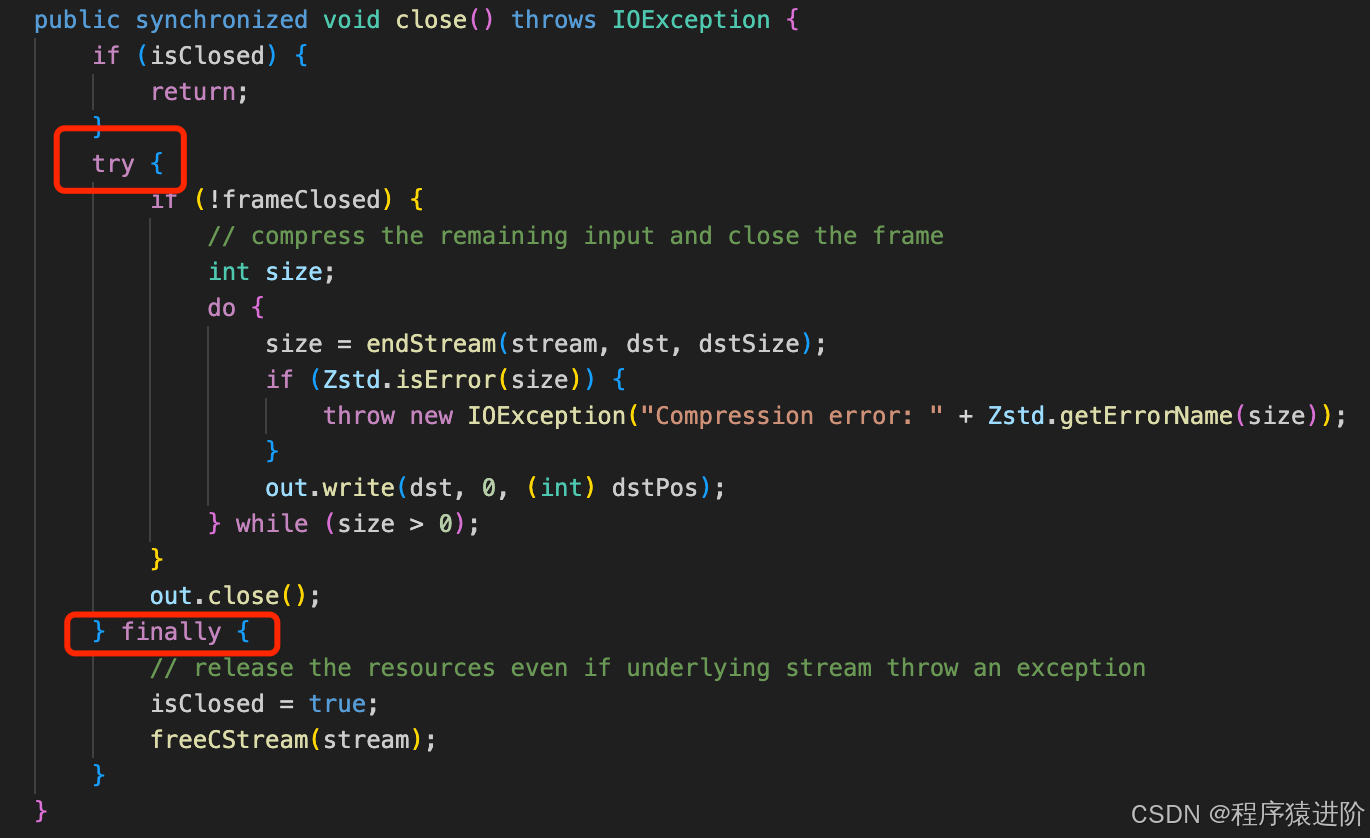
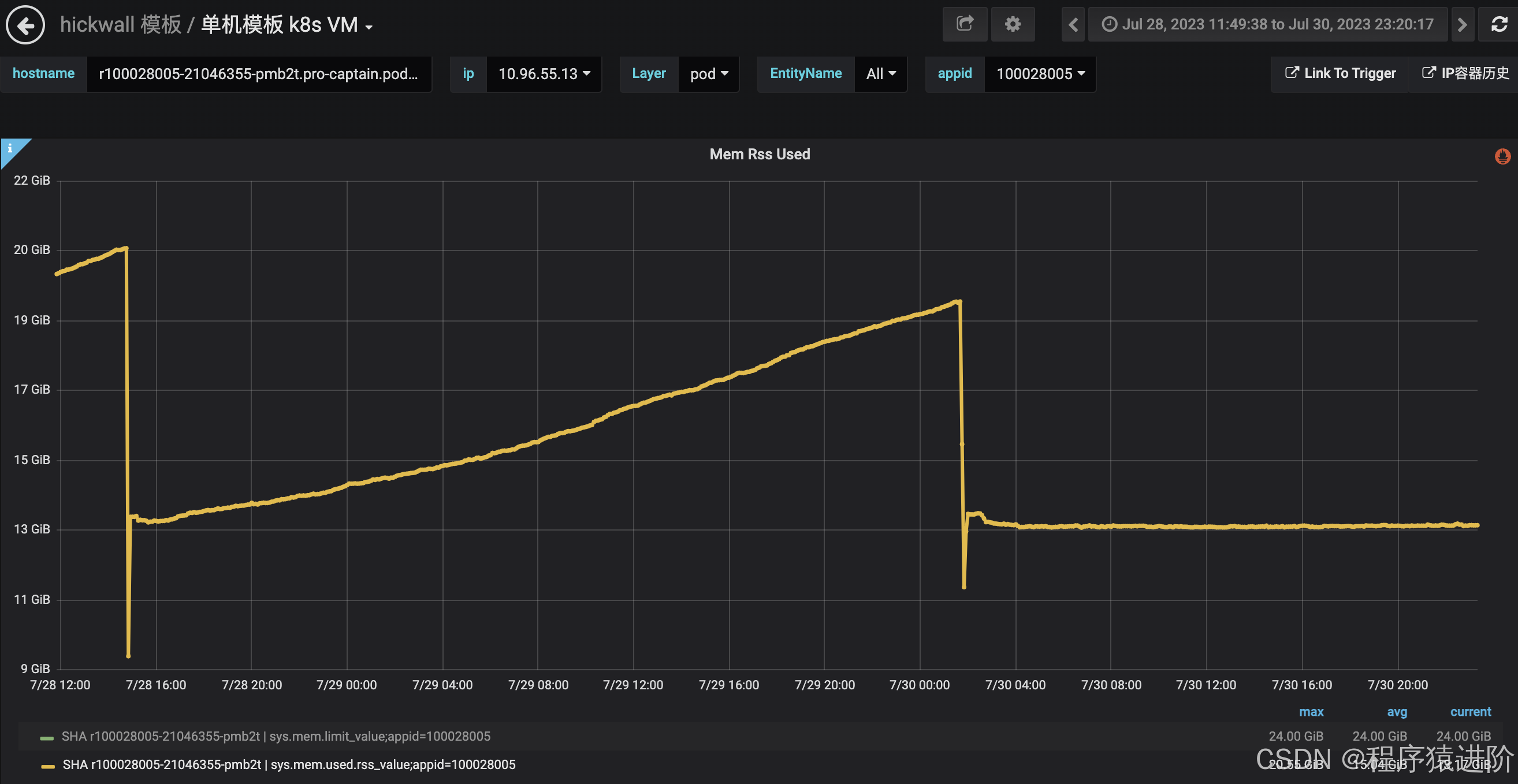
定位到问题之后就好办多了,将zstd-jni的版本升级到1.4.9-5之后的版本,这个问题就不存在了,下面是修复后RSS的情况,可以看到RSS很平稳了:
三、总结
这个case从开始排查到最终定位到问题,花费了一个星期的时间,成本巨大,回过头看看排查的步骤,貌似也没什么问题,但终究是走了一些弯路:
3.1 忽略了异常信息
如果最开始就重视异常信息的话,那么这个问题可能很早就定位到了。但这个应用自己不是直接责任人,而且在看到broken pipe的时候犯了经验性错误,没有往影响流关闭的角度想,导致方向错误,浪费了大量的时间。
所以,系统中任何的异常,都要重视起来,避免产生更严重的问题。
3.2 jemalloc失效
jemalloc在分析内存持续泄露方面比较方便,但对于非稳定复现的场景,如果采样间隔过久,有可能会导致错过问题点。而如果你将采样间隔调短,又会造成生成大量的dump文件,在用jeprof生成分析报告的时候,可能会导致too many arguments的错误而无法生成分析报告。
3.3 内部工具失效
内部工具,能够把可疑的内存段内容用strings命令查看,某些场景是能够发现蛛丝马迹的,为什么这个case就不行了呢?这里猜测是因为zstd对数据做了压缩,用strings看到的全是乱码,没法发现数据的特征;
综上,问题排查很多时候真的像排雷一样,一个个的去排除。这需要的是耐心和毅力,当你最终定位到问题的时候,那种如释重负的感觉会让自己觉得一切都是值得的。