1.前言
我们开发中经常用到 Redis 作为缓存,将高频数据放在 Redis 中能够提高业务性能,降低 MySQL 等关系型数据库压力,甚至一些系统使用 Redis 进行数据持久化,Redis 松散的文档结构非常适合业务系统开发,在精确查询,数据统计业务有着很大的优势。
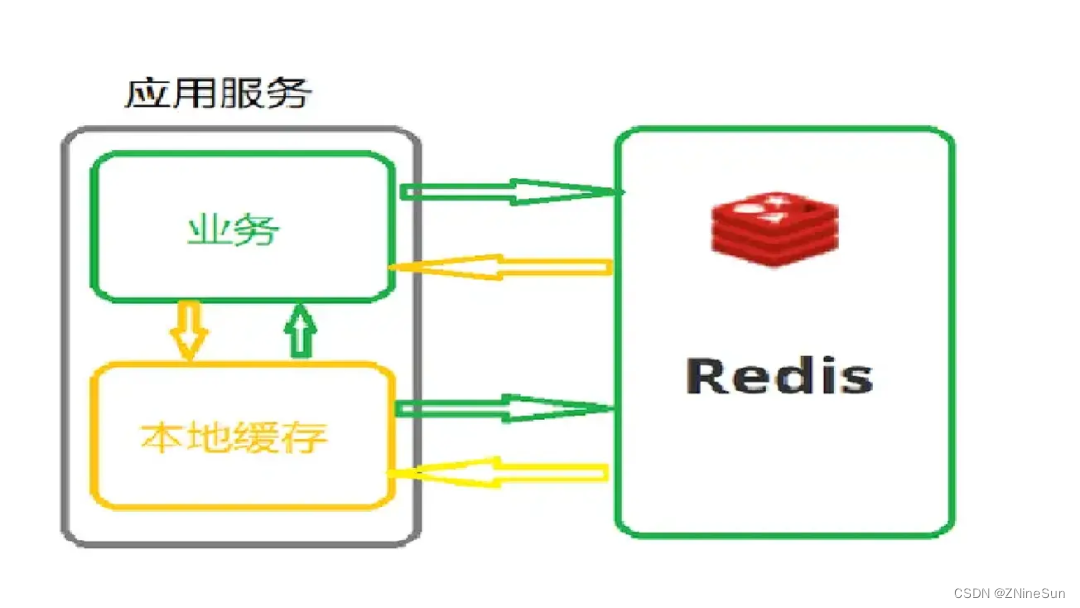
同时我们在处理redis的热key时,最常用的解决方案便是通过本地缓存+redis缓存的方式,当然本地缓存的实现有很多,如:caffeine,ehcache,guava等,这样的话就可以将缓存的数据直接读到本地缓存了,本文通过google的guava来实现二级缓存。
很多人读到此处可能就在想我们直接使用ConcurrentMap 直接进行缓存不也一样吗,因为都是直接操作内存,ConcurrentMap 做的又是如此优秀,而且是线程安全的。
Guava Cache 是其中的一个专门用于处理本地缓存的轻量级框架,是全内存方式的本地缓存,而且是线程安全的。
和 ConcurrentMap 相比,Guava Cache 可以限制内存的占用,并可设置缓存的过期时间,可以自动回收数据,而 ConcurrentMap 只能通过静态方式来控制缓存,移除数据元素需要显示的方式来移除。
2.Redis 懒加载缓存设计
数据在新增到 MySQL 不进行缓存,在精确查找进行缓存,做到查询即缓存,不查询不缓存。
传统设计架构下,我们数据的加载流程如下:
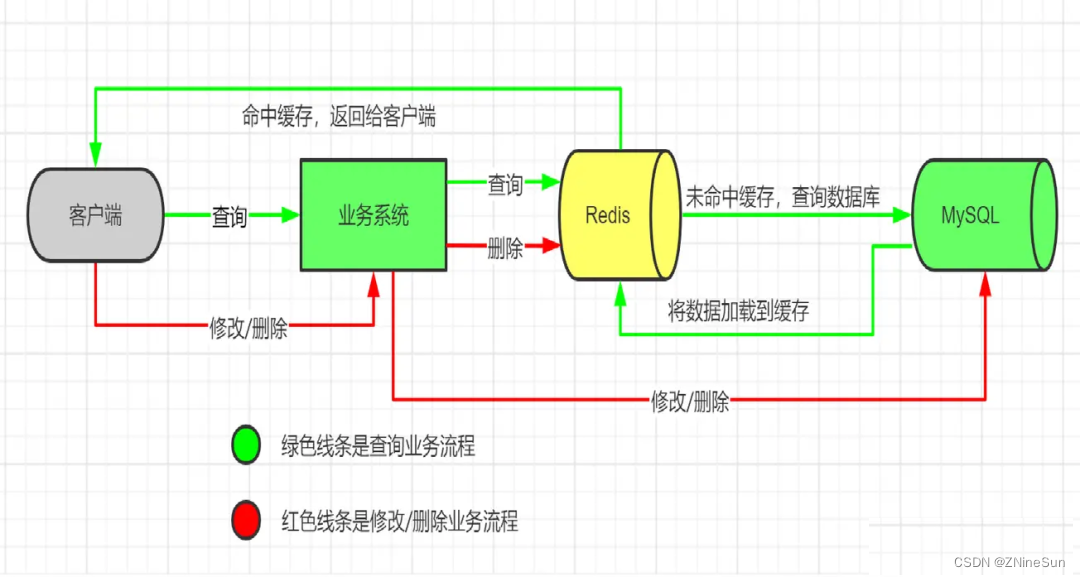
即先去查看缓存,若缓存中没有数据则去访问数据库,同时将数据更新至缓存
在这种场景下
优点如下:
- 保证最小的缓存量满足精确查询业务,避免冷数据占用宝贵的内存空间
- 对增删改查业务入侵小、删除即同步
- 可插拔,对于老系统升级,历史数据无需在启动时初始化缓存
缺点如下:
- 数据量需可控,在无限增长业务场景不适用
- 在微服务场景不利于全局缓存应用
总结:
- 空间最小化
- 满足精确查询场景
- 总数据量可控推荐使用
- 微服务场景不适用
3.Redis 结合本地缓存实现热点数据下的缓存的高可用
微服务场景下,多个微服务使用一个大缓存,流数据业务下,高频读取缓存对 Redis 压力很大,我们使用本地缓存结合 Redis 缓存使用,降低 Redis 压力,同时本地缓存没有连接开销,性能更优。
最典型的就是明星的绯闻,吃瓜群众纷纷去留言,就很容易导致评论的这个功能崩溃,这些短时间内,某些key访问量过大,然后请求到同一台数据分片上,最终会导致该分片不堪重负,最终导致缓存雪崩,进而引发我们的服务雪崩。
怎么检测热key呢?
常规呢就是根据业务以往的数据做一个判定,比如说我们的促销活动,商品秒杀,热门话题等,我们可以写一个方法去判定如果见到某个key的QPS(每秒访问量)达到了1000,此时我们就要注意了,这个key很有可能就是个热key
所以为了解决以上问题,引入了本地缓存机制来实现一个二级缓存机制,把热点数据放到我们JVM的本地缓存中,本地缓存可以使用caffeine,ehcache,guava。本文则是通过guava进行实现的。
流程图如下:
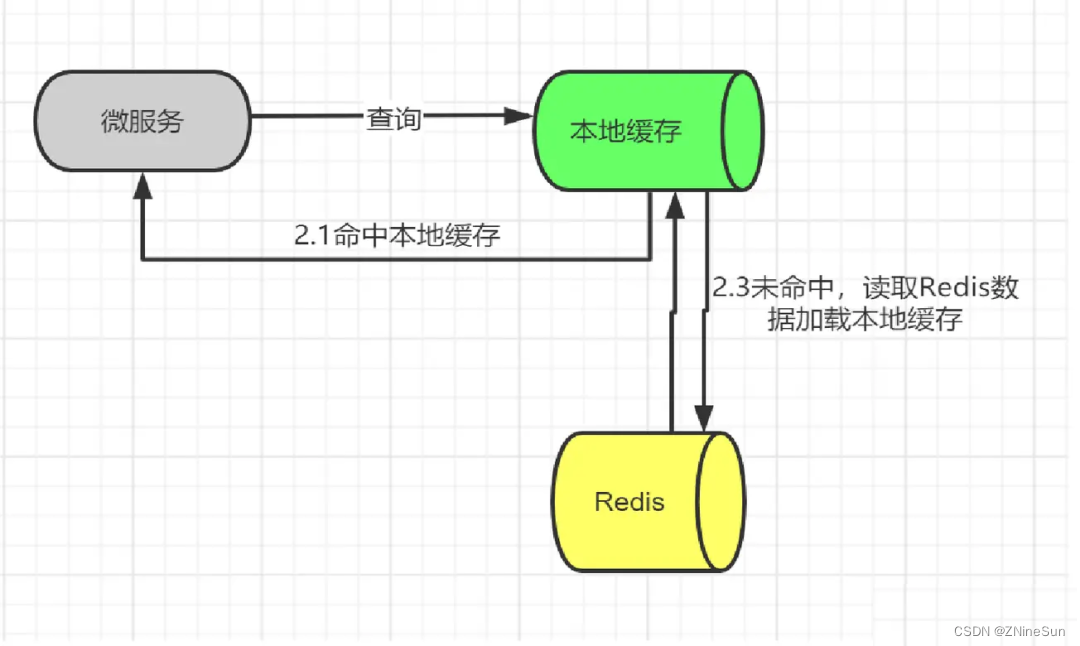
所以总体架构设计如下:
如果是redis的单点设计,那么没什么好讨论的,但是如果是通过redis集群来实现的,我们可以通过一致性hash算法构建一个hash环,主要是防止某一个或者某些个redis结点宕机或者下线而导致数据丢失的问题以及我们后面动态进行扩容的问题。
ps:我个人还是比较推崇一致性hash算法
一致性hash是指将 “存储节点” 和 “数据” 都映射到一个首尾相连的hash环上。如果增删节点,仅影响该节点在hash环上顺时针相邻的后继节点,其他数据不会受到影响。
大家可以去读一下《千万级并发架构下,如何进行关系型数据库的分库分表》第五章,可以跳过前面的内容,直接去读一下第五章
假如:我们redis集群里有3个结点,分别是:192.168.1.2:3069、192.168.1.2:3070、192.168.1.2:3071,那么这样的话我们可以通过一致性hash算法将其计算为一个个Hash环上的结点。
一致性hash算法的实现如下:
import java.util.LinkedList;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHashingWithVirtualNode {
//待添加入Hash环的服务器列表
private static final String[] servers = {"192.168.1.2:6379", "192.168.1.2:6380"};
//key表示服务器的hash值,value表示服务器
private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>();
//程序初始化,将所有的服务器放入sortedMap中
static {
for (int i = 0; i < servers.length; i++) {
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]" + "加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println();
}
//得到应当路由到的结点
public static String getServer(String key) {
//得到该key的hash值
int hash = getHash(key);
//得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap = sortedMap.tailMap(hash);
if (subMap.isEmpty()) {
//如果没有比该key的hash值大的,则从第一个node开始
Integer i = sortedMap.firstKey();
//返回对应的服务器
return sortedMap.get(i);
} else {
//第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
//返回对应的服务器
return subMap.get(i);
}
}
//使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
public static void main(String[] args) {
String[] keys = {"userName", "userName1111", "asasass"};
for (int i = 0; i < keys.length; i++)
System.out.println("[" + keys[i] + "]" + "的hash值为" + getHash(keys[i])
+ ",被路由到结点[" + getServer(keys[i]) + "]");
}
}
在选择具体的redis结点时可以通过key计算出hash值,通过key的hash值顺序查找redis服务,从而实现流量的均摊。
下面我们导入redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
然后完成一个工具类来实现redis的一些相应的操作
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.time.Duration;
public class RedisPoolConfig {
private static JedisPoolConfig getPoolConfig() {
JedisPoolConfig config = new JedisPoolConfig();
//连接池最大阻塞等待时间(使用负值表示没有限制)
config.setMaxWait(Duration.ofDays(-1));
config.setMaxTotal(50);//设置最大连接数
//连接池中的最大空闲连接
config.setMaxIdle(10);
//连接池中的最小空闲连接
config.setMinIdle(0);
return config;
}
/**
* 获取redis连接对象
*
* @param url
* @param port
* @param password
* @return
*/
public static Jedis getJedis(String url, Integer port, String password) {
//1.创建Jedis连接池对象
JedisPool jedisPool = new JedisPool(getPoolConfig(), url, port);
//2.获取连接
Jedis jedis = jedisPool.getResource();
jedis.auth(password);
return jedis;
}
}
我们的整体逻辑就是请求过来,然后向本地缓存去找数据,如果没有便更新本地缓存,值得我们注意的是,一旦有更新或者修改操作时,为了保证数据的缓存一致性,要更新数据库在去更新缓存。
添加guava依赖:
<!--guava本地缓存依赖包-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
获取本地缓存:
import com.example.secondcache.utils.ConsistentHashingWithVirtualNode;
import com.google.common.cache.*;
import org.springframework.util.StringUtils;
import redis.clients.jedis.Jedis;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
public class GuavaLocalCache {
/**
* 本地缓存
*/
private static Cache<String, String> localCache = CacheBuilder.newBuilder()
.concurrencyLevel(16) // 并发级别
.initialCapacity(1000) // 初始容量
.maximumSize(10000) // 缓存最大长度
.expireAfterAccess(1, TimeUnit.HOURS) // 缓存1小时没被使用就过期
.build();
public static String loadString(String key) throws ExecutionException {
String ans = localCache.get(key, new Callable<String>() {//如果本地缓存没有数据,便从redis缓存中拉取数据
@Override
public String call() throws Exception {
String ipAndPort = ConsistentHashingWithVirtualNode.getServer(key);//通过key来决定访问哪一个redis结点
String[] ipAndPorts = ipAndPort.split(":");
String ip = ipAndPorts[0];
String port = ipAndPorts[1];
//从redis中获取值
Jedis jedis = RedisPoolConfig.getJedis(ip, Integer.valueOf(port), null);
System.out.println("本地缓存未获取到数据,需要从redis缓存中获取");
return jedis.get(key);
}
});
return ans;
}
}
Callable的作用便是若本地缓存才会执行的操作。
此处我们按照我们的设计思路,即本地缓存无法获取的话便从redis缓存中获取
我们写个接口进行测试:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import redis.clients.jedis.Jedis;
import java.util.concurrent.ExecutionException;
@RestController
public class TestController {
@GetMapping("add")
public Object addKey(@RequestParam(value = "key") String key,
@RequestParam(value = "answer") String answer) {
String ipAndPort = ConsistentHashingWithVirtualNode.getServer(key);
String[] ip_port = ipAndPort.split(":");
Jedis jedis = RedisPoolConfig.getJedis(ip_port[0], Integer.valueOf(ip_port[1]), null);
jedis.set(key, answer);
return "已将数据放至ip:" + ip_port[0] + "-port:" + ip_port[1];
}
@GetMapping("get")
public String getKey(@RequestParam(value = "key") String key) throws ExecutionException {
String val = GuavaLocalCache.loadString(key);
return val;
}
}
先访问:http://localhost:8080/add?key=userName&answer=ninesun
在访问:http://localhost:8080/get?key=userName
我们第一次访问,由于二级缓存中也就是我们的本地缓存中并没有数据,所以一定会从redis中获取
在访问一次http://localhost:8080/get?key=userName,就会发现控制台已经不再打印从redis中获取数据的提示。
4.缓存数据一致性的问题
多级缓存有一个比较大的缺陷,便是缓存一致性,解决缓存一致性的思路便是,当有update或者delete操作时,先更新数据库,再删除缓存中的数据,至于为何这样设计,可以看一下:《如何保证数据库和缓存双写一致性》
4.1 guava的数据回收策略
对于guava的数据删除分为被动移除和主动移除两种
被动移除
基于大小的移除
看字面意思就知道就是按照缓存的大小来移除,如果即将到达指定的大小,那就会把不常用的键值对从cache中移除。
guava提供了两个基于时间移除的方法:
- expireAfterAccess(long, TimeUnit) 这个方法是根据某个键值对最后一次访问之后多少时间后移除
- expireAfterWrite(long, TimeUnit) 缓存项在给定时间内没有被写访问(创建或覆盖),则回收。如果认为缓存数据总是在固定时候后变得陈旧不可用,这种回收方式是可取的
基于引用的移除
这种移除方式主要是基于java的垃圾回收机制,根据键或者值的引用关系决定移除。
主动移除数据
主动移除有三种方法:
- 单独移除 Cache.invalidate(key)
- 批量移除 Cache.invalidateAll(keys)
- 移除所有 Cache.invalidateAll()
我们呢肯定不能依赖于被动的移除,只能靠主动删除