前言
在前面的文章我做了一个hive整合alluxio的文章,Hive整合Alluxio实操那部分其实是为了SparkSQL的整合做基础。
整合思路
- SparkSQL的目标其实就是实现表的读写都在alluxio内就可以,这个只要是表的location指向alluxio的路径就可以。
- 若需要新建的表也在放在alluxio的路径时,我需要调整库的默认路径
环境准备
alluxio的包自然是要引入的,我们在 spark-defaults.conf 中加入配置:
spark.driver.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.2.0-client.jar
spark.executor.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.2.0-client.jar
其实对于spark本身而言,这样子一配置就算是集成alluxio了,因为spark只是计算框架,不需要做存储,从实现上来说也只是作为客户端可以对alluxio读写就可以。
我们做了配置之后需要同步到各个节点,我们然后在spark-shell下面可以测试一把:
先搞点数据进去,alluxio目录下面:
./bin/alluxio fs copyFromLocal LICENSE /Input
spark-shell --master --master spark://daas-service-01:7077
输入我们的计算任务:
val s = sc.textFile("alluxio://daas-service-01:19998/Input")
val double = s.map(line => line + line)
double.saveAsTextFile("alluxio://daas-service-01:19998/Output")
执行完成之后我们可以在alluxio中查看到生成的数据了。
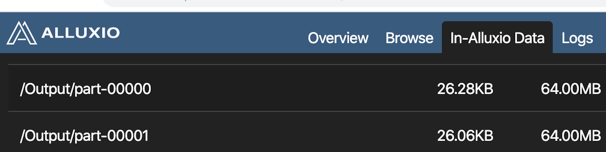
SparkSql中表的操作
对表的操作其实很简单,我们只需要把表的location调整成alluxio的地址就行,这个和hive中是一样的:
hive> desc formatted t3;
Database: default
Owner: hdfs
CreateTime: Sun Mar 29 16:42:50 CST 2020
LastAccessTime: UNKNOWN
Retention: 0
Location: alluxio://daas-service-01:19998/bip/hive_warehouse/t3
Table Type: MANAGED_TABLE
......
我们去spark-sql的客户端进行操作:
spark-sql --master spark://daas-service-01:7077
我们试着像我们的t3表中写入数据:
insert into t3 values(6);
从日志中我们可以看到数据是写入了alluxio中:
......
20/03/30 23:20:38 INFO [main] Hive: Renaming src: alluxio://daas-service-01:19998/bip/hive_warehouse/t3/.hive-staging_hive_2020-03-30_23-20-38_175_3335724859179367294-1/-ext-10000/part-00000-ca31676c-c4a5-43a4-b55a-1299264496dd-c000, dest: alluxio://daas-service-01:19998/bip/hive_warehouse/t3/part-00000-ca31676c-c4a5-43a4-b55a-1299264496dd-c000
......
库的默认路径修改
我们创建一个新表t4:
create table t4(id int);
spark-sql> desc formatted t4;
......
Database default
Table t4
Owner hdfs
Created Time Mon Mar 30 23:25:03 CST 2020
Last Access Thu Jan 01 08:00:00 CST 1970
Created By Spark 2.3.2
Location hdfs://daas-service-01/bip/hive_warehouse/t4
......
我们看到新建的表其实还是在t4下面,这个时候效果就是,如果我们执行类似create table t4 as select * from t1这种操作的时候t4还是会在我们的hdfs路径中。当然,我们一样可以执行命令:
alter table t4 set location "alluxio://daas-service-01:19998/bip/hive_warehouse/t4"
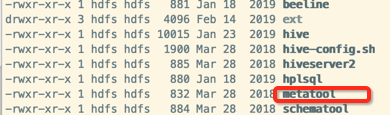
还有一种思路,我们的hive其实有库级别的默认路径的,使用hive的工具可以查询:
为了说明问题,我们先建立一个库csdn:
create database csdn;
我们执行命令:
${HIVE_HOME}/bin/metatool -listFSRoot
我们可以查看我们的库对应的根路径:
hdfs://daas-service-01/bip/hive_warehouse/csdn.db
hdfs://daas-service-01/bip/hive_warehouse/temp.db
hdfs://daas-service-01/bip/hive_warehouse
alluxio://daas-service-01:19998/bip/hive_warehouse/alluxio.db
有个alluxio是之前做实验生成的,我们切可以看到每一个路径其实就是对应我们库路径来着,我们也看到csdn的路径,我们把这个路径调整为alluxio的路径:
${HIVE_HOME}/bin/metatool --updateLocation alluxio://daas-service-01:19998/bip/hive_warehouse/csdn.db hdfs://daas-service-01/bip/hive_warehouse/csdn.db
再次执行:
${HIVE_HOME}/bin/metatool -listFSRoot
我们可以看到csdn下面的路径已经更新为alluxio的路径了:
Listing FS Roots..
alluxio://daas-service-01:19998/bip/hive_warehouse/csdn.db
hdfs://daas-service-01/bip/hive_warehouse/temp.db
hdfs://daas-service-01/bip/hive_warehouse
alluxio://daas-service-01:19998/bip/hive_warehouse/alluxio.db
我们在csdn下面建表:
spark-sql> use csdn;
spark-sql> create table t5(id int);
我们查看t5的信息:
spark-sql> desc formatted t5;
Table t5
Owner hdfs
Created Time Mon Mar 30 23:42:24 CST 2020
Last Access Thu Jan 01 08:00:00 CST 1970
Created By Spark 2.3.2
Type MANAGED
Provider hive
Table Properties [transient_lastDdlTime=1585582944]
Location alluxio://daas-service-01:19998/bip/hive_warehouse/csdn.db/t5
我们看到t5已经在alluxio下面了。我们可以想得到,csdn下面的表其实都会在alluxio里面,我再来一张t6:
create table t6 as select id from default.t3;
我想,到了这里,应该明白了这个规律了~~
spark-sql> desc formatted t6;
......
Location alluxio://daas-service-01:19998/bip/hive_warehouse/csdn.db/t6
直接指定location
直接指定路径其实和hive中是一样的,在SparkSql中完全没有问题的
CREATE TABLE u_user (
userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 'alluxio://daas-service-01:19998/ml-100k';
小总结
- SparkSQL操作的精髓其实就是操作表的location就可以了,从hive到SparkSQL是一样的,我们其实可以联想到presto上面也是一回事。
- 生产环境也不会清一色的把表都放在alluxio,一个是也没那么多内存,另外来说也没必要,我们把经常读的表放在alluxio就可以了
- 通过指定库路径的方式可以让新建的表也是alluxio的路径,这样有时候不需要来回操作location