SSD: Single Shot MultiBox Detector论文解读
背景
CVPR2016,在目标检测的领域上,RBG大神又参与了YOLO的工作,提出了一种新的目标检测的思路。YOLO的方法有了一个明显的优点就是速度很快,能达到45FPS,并且保持mAP63.4的精度。这种方法的提出,为实时性目标检测提供了可能,但是缺点也很明显,就是精度比较低,之前的方法Faster-RCNN 速度7FPS, mAP 能达到73.2。也就是说YOLO虽然检索速度快了,但是这种快是牺牲精度达到的。所以,作者提出了一种新的构想,能不能让目标检测又快又好呢?答案是确定的。YOLO快主要是利用了回归的想法,不需要寻找region proposal,而是直接预测目标的位置和置信度。 但是Faster-RCNN准,却利用了anchor box的思想,利用卷积层的特征来预测多尺度的box,不像YOLO一样,每一个box只预测一个目标,显得更加合理。作者的思路很明显,就是Faster RCNN+YOLO,利用YOLO的思路和Faster RCNN的anchor box的思想,于是SSD诞生了。
主要工作
整个论文主要做了如下的工作:
- 设计了一个SSD的网络结构,比YOLO快,更加精确
- 在feature map用3*3的卷积核,预测多尺度的一系列的Box offsets和category scores
- SSD主要利用不同层的feature map,获得不同比例的图像。
- 设计了一个end-to-end的训练
- 通过实验,在不同的数据集训练,验证自己的效果的确优于其他方法。
对于论文,个人觉得论文这几句话道出了本文的精辟。
The fundamental improvement in speed comes from eliminating bounding box proposals and the subsequent pixel or feature resampling stage.
Our improvements include using a small convolutional filter to predict object categories and offsets in bounding box locations, using separate predictors (filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection at multiple scales.
SSD
Model
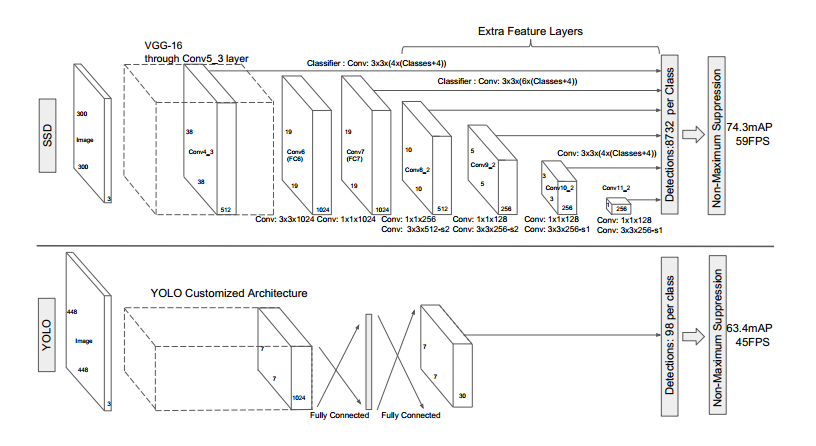
上图是SSD300的模型。观察上图可以发现,不同的feature map都会用一个卷积核进行卷积操作,不同的feature map对应着不同的感受野,在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。观察YOLO,后面存在两个全连接层,全连接层以后,每一个输出都会观察到整幅图像,并不是很合理。但是SSD去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的feature map,预测不同宽高比的图像,这样比YOLO增加了预测更多的比例的box。
对于上图如何得到8732是怎么得到的?在阅读paper的时候一直很迷惑,后来论文看完才豁然开朗。Conv4_3 38*38的feature map通过3*3的卷积层预测4个不同宽高比的box,Conv7 19