关于 langchain 的 RAG 实践,可以参考我的 github 项目:
https://github.com/5zjk5/prompt-engineering
目录
txt 有多行,我的这份数据有 67 行,样例如下:
字段1\t值1\n
字段2\t值2\n
...
chroma 检索
pip install langchain-chroma
在本地下载了 embedding 模型,使用去向量化,并检索 top3
指定向量化后的数据库保存到哪里 persist_directory
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
filepath = 'data/专业描述.txt'
raw_documents = TextLoader(filepath, encoding='utf8').load()
# 按行分割块
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="\n",
length_function=len,
is_separator_regex=True,
)
documents = text_splitter.split_documents(raw_documents)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# 创建向量数据库
db = Chroma.from_documents(documents, embedding, persist_directory=r"./chroma/")
db.persist() # 确保嵌入被写入磁盘
'''
如果已经创建好了,可以直接读取
db = Chroma(persist_directory=persist_directory, embedding_function=embedding)
'''
# 直接传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
docs = db.similarity_search(query, k=3)
# docs = db.similarity_search_with_score(query, k=3) # 带分数的
print(docs[0].page_content)
# 传入向量去搜索
embedding_vector = embedding.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector, k=3)
print(docs[0].page_content)

faiss 检索
pip install faiss-cpu
感觉 faiss 向量化要快一些
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
filepath = 'data/专业描述.txt'
raw_documents = TextLoader(filepath, encoding='utf8').load()
# 按行分割块
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="\n",
length_function=len,
is_separator_regex=True,
)
documents = text_splitter.split_documents(raw_documents)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# 创建向量数据库
db = FAISS.from_documents(documents, embedding)
# 保存
db.save_local("./faiss_index")
'''
如果已经创建好了,可以直接读取
db = FAISS.load_local("./faiss_index", embeddings)
'''
# 直接传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
docs = db.similarity_search(query, k=3)
# docs = db.similarity_search_with_score(query, k=3) # 带分数的
print(docs[0].page_content)
# 传入向量去搜索
embedding_vector = embedding.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector, k=3)
print(docs[0].page_content)
检索器
相似性
在上面默认情况下,向量存储检索器使用相似性搜索
我们在用上面的例子,使用 faiss 已经创建好了向量数据库,我们在最后面修改检索的代码
选取 top30
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
filepath = 'data/专业描述.txt'
raw_documents = TextLoader(filepath, encoding='utf8').load()
# 按行分割块
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="\n",
length_function=len,
is_separator_regex=True,
)
documents = text_splitter.split_documents(raw_documents)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# # 创建向量数据库
# db = FAISS.from_documents(documents, embedding)
# # 保存
# db.save_local("./faiss_index")
# 如果已经创建好了,可以直接读取
db = FAISS.load_local("./faiss_index", embedding, allow_dangerous_deserialization=True)
# 直接传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
retriever = db.as_retriever(search_kwargs={'k': 30}) # 构建检索器
docs = retriever.get_relevant_documents(query)
print(docs)

最大相关性mmr
直接比较使用相似性,相似度方法,可能会有重复数据,使用 mmr 不会有重复的检索结果
retriever = db.as_retriever(search_type="mmr", search_kwargs={'k': 30}) # 构建检索器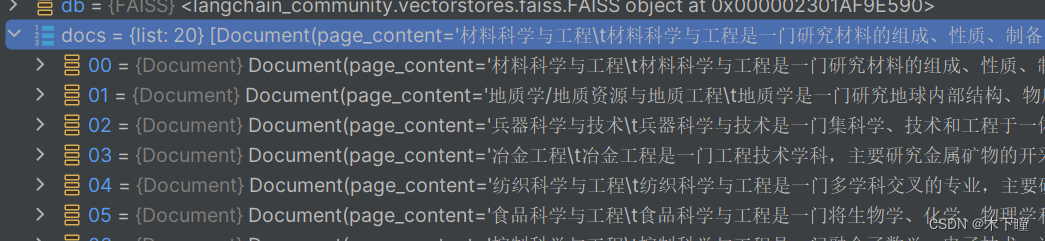
会发现我指定 top30,只返回了 20 个
fetch_k 默认是 20,数据库提取的候选文档数量,理解为 mmr 算法使用时内部操作的参数就可以了
想取出 30 那,只需要设置大于 30 即可
retriever = db.as_retriever(search_type="mmr", search_kwargs={'k': 30, 'fetch_k': 50}) # 构建检索器相似数阈值
相似度大于 0.5 的拿出来
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5}) # 构建检索器
多角度查询
基于向量距离的检索可能因微小的询问词变化或向量无法准确表达语义而产生不同结果;
使用大预言模型自动从不同角度生成多个查询,实现提示词优化;
对用户查询生成表达其不同方面的多个新查询(也就是query利用大模型生成多个表述),对每个表述进行检索,去结果的并集;
优点是生成的查询多角度,可以覆盖更全面的语义和信息需求;
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
load_dotenv('key.env') # 指定加载 env 文件
key = os.getenv('DASHSCOPE_API_KEY') # 获得指定环境变量
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量
model = Tongyi(temperature=1)
filepath = 'data/专业描述.txt'
raw_documents = TextLoader(filepath, encoding='utf8').load()
# 按行分割块
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="\n",
length_function=len,
is_separator_regex=True,
)
documents = text_splitter.split_documents(raw_documents)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# 如果已经创建好了,可以直接读取
db = FAISS.load_local("./faiss_index", embedding, allow_dangerous_deserialization=True)
# 直接传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
# MultiQueryRetriever 检索
from langchain.retrievers.multi_query import MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=db.as_retriever(search_kwargs={'k': 8}), llm=model
)
unique_docs = retriever_from_llm.get_relevant_documents(query=query)
print(unique_docs)
上下文压缩
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
相当于提取每个检索结果的核心,简化每个文档,利用大模型的能力
这里我们就选择 top1,可以看到检索结果跟 query 一模一样了,是同一句话
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
load_dotenv('key.env') # 指定加载 env 文件
key = os.getenv('DASHSCOPE_API_KEY') # 获得指定环境变量
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量
model = Tongyi(temperature=1)
filepath = 'data/专业描述.txt'
raw_documents = TextLoader(filepath, encoding='utf8').load()
# 按行分割块
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="\n",
length_function=len,
is_separator_regex=True,
)
documents = text_splitter.split_documents(raw_documents)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# 如果已经创建好了,可以直接读取
db = FAISS.load_local("./faiss_index", embedding, allow_dangerous_deserialization=True)
# 传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
# 检索
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
retriever = db.as_retriever(search_kwargs={'k': 1})
compressor = LLMChainExtractor.from_llm(model)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
unique_docs = compression_retriever.get_relevant_documents(query)
print(unique_docs)

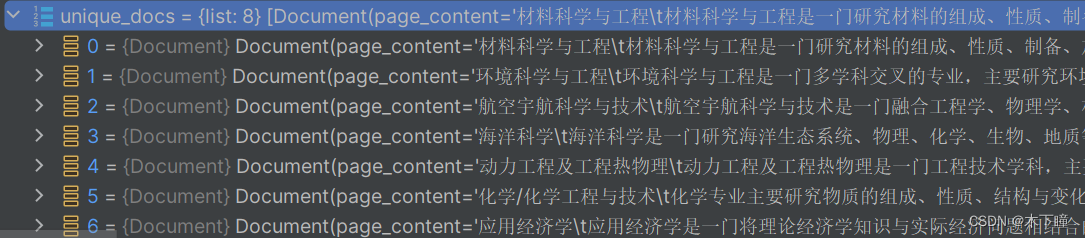
上面这个我是只取了 top1,但是我把全部结果打出来,发现有重复的,我用了下面检索代码,就去重了;官网的意思是:
LLMChainFilter 使用 LLM 链来决定过滤掉最初检索到的文档中的哪些以及返回哪些文档,而无需操作文档内容。
# 检索
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.retrievers.document_compressors import LLMChainFilter
_filter = LLMChainFilter.from_llm(model)
retriever = db.as_retriever(search_kwargs={'k': 10})
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
unique_docs = compression_retriever.get_relevant_documents(query)
print(unique_docs)对每个检索到的文档进行额外的 LLM 调用既昂贵又缓慢。EmbeddingsFilter通过嵌入文档和查询并仅返回那些与查询具有足够相似嵌入的文档
相当于少调用 llm 去判断相关的文档,改用 embedding 模型
# 检索
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import EmbeddingsFilter
retriever = db.as_retriever(search_kwargs={'k': 10})
embeddings_filter = EmbeddingsFilter(embeddings=embedding, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(query)
print(compressed_docs)
还有一种,是把文档分割为再小块一些的,再去做 embedding
def contextual_compression_by_embedding_split(cls, db, query, embedding_model, topk=5, similarity_threshold=0.76,
chunk_size=300, chunk_overlap=0, separator=". "):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
上下文压缩检索器,embedding 模型,会对结果去重,将文档分割成更小的部分
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
利用 embedding 来计算
:param db:
:param query:
:param embedding_model:
:param topk: 不生效,默认是 4 个
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap, separator=separator)
redundant_filter = EmbeddingsRedundantFilter(embeddings=embedding_model)
relevant_filter = EmbeddingsFilter(embeddings=embedding_model, similarity_threshold=similarity_threshold)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
return retriever_docs混合检索
通过利用不同算法的优势, EnsembleRetriever可以获得比任何单一算法更好的性能
最常见的模式是将稀疏检索器(如 BM25)与密集检索器(如嵌入相似性)相结合,因为它们的优势是互补的。它也被称为“混合搜索”。稀疏检索器擅长根据关键词查找相关文档,而密集检索器擅长根据语义相似度查找相关文档。
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
doc_list_1 = [
"I like apples",
"I like oranges",
"Apples and oranges are fruits",
]
# initialize the bm25 retriever and faiss retriever
bm25_retriever = BM25Retriever.from_texts(
doc_list_1, metadatas=[{"source": 1}] * len(doc_list_1)
)
bm25_retriever.k = 2
doc_list_2 = [
"You like apples",
"You like oranges",
]
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
faiss_vectorstore = FAISS.from_texts(
doc_list_2, embedding, metadatas=[{"source": 2}] * len(doc_list_2)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
docs = ensemble_retriever.invoke("apples")
print(docs)

检索后上下文重新排序
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
load_dotenv('key.env') # 指定加载 env 文件
key = os.getenv('DASHSCOPE_API_KEY') # 获得指定环境变量
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量
model = Tongyi(temperature=1)
filepath = 'data/专业描述.txt'
raw_documents = TextLoader(filepath, encoding='utf8').load()
# 按行分割块
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="\n",
length_function=len,
is_separator_regex=True,
)
documents = text_splitter.split_documents(raw_documents)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# 如果已经创建好了,可以直接读取
db = FAISS.load_local("./faiss_index", embedding, allow_dangerous_deserialization=True)
# 传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
# 检索
from langchain_community.document_transformers import LongContextReorder
retriever = db.as_retriever(search_type="mmr", search_kwargs={'k': 10, 'fetch_k': 50}) # 构建检索器
docs = retriever.get_relevant_documents(query)
# 对检索结果重新排序
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs)
父文档检索器
大文档拆分成小文档(比如大文档指多个 txt 或文件)
小文档快通过向量空间建模,实现更准确的语义检索,大块提供跟完整的语义内容
检索小的,最后返回大的对应 id 进行返回
from langchain.storage import InMemoryStore
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers import ParentDocumentRetriever
loaders = [
TextLoader("data/专业描述.txt", encoding="utf-8"),
TextLoader("data/专业描述_copy.txt", encoding="utf-8"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# This text splitter is used to create the child documents
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(
collection_name="full_documents", embedding_function=embedding
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
# 会有两个键,添加了两个文档
# print(list(store.yield_keys()))
# 传入文本
query = "材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属"
# 检索小块
sub_docs = vectorstore.similarity_search(query)
print(sub_docs[0].page_content)
# 检索大块
retrieved_docs = retriever.get_relevant_documents("justice breyer")
print(retrieved_docs)
如果文档还是太大,可先把父文档文档分割,参考:
Parent Document Retriever | 🦜️🔗 LangChain
自查询
通过大预言模型生成向量存储可识别使用的查询语句;
当我们给定一个自然语言查询,自组织检索器会首先通过大预言模型编写一个结构化查询,然后将该结构化查询转化成底层向量存储可识别可使用的查询语句,最终应用于底层向量存储从而获得检索结果。
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
# 加载模型
load_dotenv('key.env') # 指定加载 env 文件
key = os.getenv('DASHSCOPE_API_KEY') # 获得指定环境变量
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量
model = Tongyi(temperature=1)
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
# 实验数据,重点关注 metadata 部分
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,
"director": "Andrei Tarkovsky",
"genre": "thriller",
"rating": 9.9,
},
),
]
# 使用具备高级检索的向量存储,Chroma,faiss 不行
vectorstore = Chroma.from_documents(docs, embedding)
# 定义在子查询中用于提取结构化数据的数据结构,细化到属性名称,描述,类型
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
# 提供文档主题内容描述
document_content_description = "Brief summary of a movie"
# 构建自查讯,把以上准备的大语言模型,向量存储,结构化数据描述导入
retriever = SelfQueryRetriever.from_llm(
model,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True # 可以让检索器可以识别自然语言定义的文档返回数量
)
# 只查元数据
res1 = retriever.invoke("I want to watch a movie rated higher than 8.5")
# 即查询元数据,又查询文档内容
res2 = retriever.invoke("Has Greta Gerwig directed any movies about women")
# 查询多类元数据
res3 = retriever.invoke("What's a highly rated (above 8.5) science fiction film?")
# 即查询多类元数据,又查询文档内容
res4 = retriever.invoke(
"What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
)
pass
上面是官网文档代码,运行报错,Self-querying | 🦜️🔗 LangChain

时间权重检索
Time-weighted vector store retriever | 🦜️🔗 LangChain
TF-IDF检索
from langchain.retrievers import TFIDFRetriever
with open('data/专业描述.txt', encoding='utf8') as f:
lst = f.readlines()
retriever = TFIDFRetriever.from_texts(lst)
result = retriever.get_relevant_documents("材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属")
print(result)

KNN检索
from langchain.retrievers import KNNRetriever
from langchain.embeddings import HuggingFaceEmbeddings
with open('data/专业描述.txt', encoding='utf8') as f:
lst = f.readlines()
# 加载本地 embedding 模型
embedding = HuggingFaceEmbeddings(model_name='bge-small-zh-v1.5')
retriever = KNNRetriever.from_texts(lst, embedding)
result = retriever.get_relevant_documents("材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属")
print(result)
RAG全流程模块
加载数据-分割数据-向量化-检索
又加了写 prompt tool,outparser解析模块,放这里了
"""
Name: langchain
Version: 0.1.16
Name: langchain-community
Version: 0.0.32
Name: langchain-core
Version: 0.1.42
DocsLoader: 加载文档
TextSpliter: 文档分割
EmbeddingVectorDB: embedding,向量数据库
Retriever: 检索
Prompt:prompt 模版
"""
import json
import os
import pprint
from pathlib import Path
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters import RecursiveJsonSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainFilter
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_community.document_transformers import LongContextReorder
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.retrievers import KNNRetriever
from langchain.retrievers import TFIDFRetriever
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import UnstructuredHTMLLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_community.document_loaders import UnstructuredExcelLoader
from langchain_community.document_loaders import UnstructuredPowerPointLoader
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
from langchain_text_splitters import HTMLHeaderTextSplitter
from langchain_text_splitters import Language
from langchain_text_splitters import MarkdownHeaderTextSplitter
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.document_loaders import UnstructuredImageLoader
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatMessagePromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import FewShotPromptTemplate
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
from langchain_core.prompts import FewShotChatMessagePromptTemplate
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain.chains import LLMChain
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.output_parsers import DatetimeOutputParser
from langchain_core.output_parsers import JsonOutputParser
from langchain.agents import load_tools
from langchain_experimental.utilities import PythonREPL
from langchain_community.utilities import TextRequestsWrapper
from langchain.agents import AgentType, initialize_agent
class DocsLoader():
@classmethod
def txt_loader(cls, filepath):
"""
加载 txt 数据
:param filepath:
:return:
"""
loader = TextLoader(filepath, encoding='utf8')
docs = loader.load()
return docs
@classmethod
def csv_loader(cls, filepath):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/csv/
可用参数解释:https://blog.csdn.net/zjkpy_5/article/details/137727850?spm=1001.2014.3001.5501
加载 csv 数据
:param filepath:
:return:
"""""
loader = CSVLoader(file_path=filepath, encoding='utf8')
docs = loader.load()
return docs
@classmethod
def json_loader(cls, filepath):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/json/
官网 jq 用不了 win 系统
加载 json 数据
:param filepath:
:return:
"""
docs = json.loads(Path(filepath).read_text(encoding='utf8'))
return docs
@classmethod
def file_directory_loader(cls, filepath, glob="**/[!.]*", loader_cls=TextLoader, silent_errors=False, show_progress=True,
use_multithreading=True, max_concurrency=4, exclude=[], recursive=True):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/file_directory/
根据目录加载里面所有数据,不会加载文件.rst或.html文件
:param filepath:
:param glob: 默认加载所有非隐藏文件
*.txt:只加载所有 txt
:param loader_cls: 加载器,默认是 UnstructuredFileLoader,可以指定文本加载器(TextLoader)避免编码报错
:param autodetect_encoding: 自动检测编码
:param silent_errors: 跳过无法加载的文件并继续加载过程
:param show_progress: 显示进度条
:param use_multithreading: 多线程开启加载
:param max_concurrency: 线程数量
:param exclude: 指定不加的文件格式,列表格式
:param recursive: 递归加载文件,目录下还有文件夹,加载里面的文件
:return:
"""
text_loader_kwargs = {'autodetect_encoding': True}
loader = DirectoryLoader(filepath, glob=glob, loader_cls=loader_cls, silent_errors=silent_errors,
loader_kwargs=text_loader_kwargs, show_progress=show_progress,
use_multithreading=use_multithreading, max_concurrency=max_concurrency,
exclude=exclude, recursive=recursive)
docs = loader.load()
return docs
@classmethod
def html_loader(cls, filpath):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/html/
加载 html
官网 BSHTMLLoader 会报编码错
其他加载方式是利用爬虫,第三方的,需要申请 api
:param filpath:
:return: 网页中的文本
"""
loader = UnstructuredHTMLLoader(filpath)
data = loader.load()
return data
@classmethod
def markdown_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/markdown/
加载 markdown
:param filepath:
:param mode: 分割模式,single 全部合在一起,elements 把每一块都单独分开
:return:
"""
loader = UnstructuredMarkdownLoader(filepath, mode=mode)
data = loader.load()
return data
@classmethod
def pdf_loader(cls, filepath, extract_images=True, is_directory=False):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/pdf/
加载 pdf,默认 page 是页码,但可能多出几页
:param filepath:
:param extract_images: 默认提取图片文字,是否提取 pdf 中的图片的文字
:param is_directory: 如果传入进来是目录,加载此路径下的所有 pdf,但图片中的文字不能识别
:return:
"""
if is_directory:
filepath = is_directory
loader = PyPDFDirectoryLoader(filepath)
docs = loader.load()
return docs
else:
if extract_images:
loader = PyPDFLoader(filepath, extract_images=extract_images)
else:
loader = PyMuPDFLoader(filepath) # 最快的 PDF 解析选项,但不能提取图片中的文字
pages = loader.load_and_split()
return pages
@classmethod
def excel_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/microsoft_excel/
excel 加载,处理.xlsx和.xls文件
:param filepath:
:param mode: 式下使用加载程序 "elements",则该键下的文档元数据中将提供 Excel 文件的 HTML 表示形式text_as_html
:return:
"""
loader = UnstructuredExcelLoader(filepath, mode='elements')
docs = loader.load()
return docs
@classmethod
def ppt_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/microsoft_powerpoint/
加载 ppt,不能提取图片中的文字
:param filepath:
:param mode: 分割模式,single 全部合在一起,elements 把每一页的文本框,表格等都单独分开
:return:
"""
loader = UnstructuredPowerPointLoader(filepath, mode=mode)
data = loader.load()
return data
@classmethod
def word_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/microsoft_word/
:param filepath:
:param mode: 分割模式,single 全部合在一起,elements 把每一页单独分开,不能识别图片文字
:return:
"""
loader = UnstructuredWordDocumentLoader(filepath, mode=mode)
data = loader.load()
return data
@classmethod
def img_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/image/
加载图片,可以识别上面文字,但不一定准
报错:no modul pdfminer.utils:https://github.com/langchain-ai/langchain/issues/14326
:param filepath:
:param mode: single-所有文字合在一起,elements-每个文字单独分开为一个快
:return:
"""
loader = UnstructuredImageLoader(filepath, mode=mode)
data = loader.load()
return data
class TextSpliter():
@classmethod
def text_split_by_char(cls, docs, separator='\n', chunk_size=100, chunk_overlap=20, length_function=len,
is_separator_regex=False):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/character_text_splitter/
指定字符拆分,separator 指定,若指定有效 chunk_size 失效
:param docs: 文档,必须为 str,如果是 langchain 加载进来的需要转换一下
:param separator: 分割字符
:param chunk_size: 每块大小
:param chunk_overlap: 允许字数重叠大小
:param length_function:
:param is_separator_regex:
:return:
"""
text_splitter = CharacterTextSplitter(
separator=separator,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=length_function,
is_separator_regex=is_separator_regex,
)
docs = docs[0].page_content # langchian 加载的 txt 转换为 str
text_split = text_splitter.create_documents([docs])
return text_split
@classmethod
def text_split_by_manychar_or_charnum(cls, docs, separator=["\n\n", "\n", " ", ""], chunk_size=100, chunk_overlap=20,
length_function=len, is_separator_regex=True):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_text_splitter/
按照 chunk_size 字数分割,separator 不需要传,保持默认值即可
多个字符拆分,separator 指定,符合列表中的字符就会被拆分
:param docs: 文档,必须为 str,如果是 langchain 加载进来的需要转换一下
:param separator: 分割字符,默认以列表中的字符去分割 ["\n\n", "\n", " ", ""]
:param chunk_size: 每块大小
:param chunk_overlap: 允许字数重叠大小
:param length_function:
:param is_separator_regex:
:return:
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # 指定每块大小
chunk_overlap=chunk_overlap, # 指定每块可以重叠的字符数
length_function=length_function,
is_separator_regex=is_separator_regex,
separators=separator # 指定按照什么字符去分割,如果不指定就按照 chunk_size +- chunk_overlap(100+-20)个字去分割
)
docs = docs[0].page_content # langchian 加载的 txt 转换为 str
split_text = text_splitter.create_documents([docs])
return split_text
@classmethod
def json_split(cls, json_data, min_chunk_size=50, max_chunk_size=300):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_json_splitter/
json 拆分,每一个块会拆分为完整的字典
:param json_data:
:param min_chunk_size:
:param max_chunk_size:
:return:
"""
splitter = RecursiveJsonSplitter(min_chunk_size=min_chunk_size, max_chunk_size=max_chunk_size)
json_chunks = splitter.split_json(json_data=json_data)
return json_chunks
@classmethod
def html_split(cls, html_string='', url='', chunk_size=500, chunk_overlap=30):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/HTML_header_metadata/
html 分割,两种方式
:param html_string: 字符串类型 html
:param url: 传入 url 分割 html
:return:
"""
# 按照标题标签分,相同的 h 标签会在元数据可以看到属于哪一个 h
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("h4", "Header 4"),
("h5", "Header 5"),
("h6", "Header 6"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
if html_string:
splits = html_splitter.split_text(html_string)
else:
html_header_splits = html_splitter.split_text_from_url(url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(html_header_splits)
return splits
@classmethod
def code_split(cls, code, language=Language.PYTHON, chunk_size=50, chunk_overlap=0):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/code_splitter/
# Full list of supported languages
[e.value for e in Language]
分割代码
:param code:
:param language: 默认 python
:param chunk_size:
:param chunk_overlap:
:return:
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=language, chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
docs = python_splitter.create_documents([code])
return docs
@classmethod
def markdown_split(cls, mkardown_string, char_level_splits=False, strip_headers=False, chunk_size=250,
chunk_overlap=30):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/markdown_header_metadata/
分割 markdown
:param mkardown_string: markdown 字符串
:param char_level_splits: 是否在标题分割后再继续按字数分割
:param strip_headers: 默认情况下,从输出块的内容中删除分割的标头。可以通过设置禁用此功能 strip_headers = False。
:return:
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on,
strip_headers=strip_headers)
md_header_splits = markdown_splitter.split_text(mkardown_string)
splits = md_header_splits
if char_level_splits:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(md_header_splits)
return splits
@classmethod
def semantic_chunker_split(cls, txt, embedding_model, breakpoint_threshold_type="percentile"):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker/
语义分块
:param txt: txt 字符串
:param embedding_model:
:param breakpoint_threshold_type: 分割断点
percentile:默认的分割方式是基于百分位数。在此方法中,计算句子之间的所有差异,然后分割任何大于 X 百分位数的差异
standard_deviation:任何大于 X 个标准差的差异都会被分割。
interquartile:使用四分位数距离来分割块
:return:
"""
text_splitter = SemanticChunker(embedding_model, breakpoint_threshold_type=breakpoint_threshold_type)
docs = text_splitter.create_documents([txt])
return docs
class EmbeddingVectorDB():
@classmethod
def load_local_embedding_model(cls, embedding_model_path, device='cpu'):
"""加载本地向量模型"""
embedding_model = HuggingFaceEmbeddings(model_name=embedding_model_path, model_kwargs={'device': device})
return embedding_model
@classmethod
def faiss_vector_db(cls, split_docs, vector_db_path, embedding_model):
"""
https://python.langchain.com/docs/modules/data_connection/vectorstores/
faiss 创建向量数据库
:param split_docs: 分割的文本块
:param vector_db_path: 向量数据库存储路径
:param embedding_model: embedding 模型
:return:
"""
if os.path.exists(vector_db_path):
print('加载向量数据库路径 =》', vector_db_path)
db = FAISS.load_local(vector_db_path, embedding_model, allow_dangerous_deserialization=True)
else:
print('创建向量数据库路径 =》', vector_db_path)
db = FAISS.from_documents(split_docs, embedding_model)
db.save_local(vector_db_path)
return db
@classmethod
async def faiss_vector_db_await(cls, split_docs, vector_db_path, embedding_model):
"""
https://python.langchain.com/docs/integrations/vectorstores/faiss_async/#similarity-search-with-score
:param split_docs: 分割的文本块
:param vector_db_path: 向量数据库存储路径
:param embedding_model: embedding 模型
:return:
"""
if os.path.exists(vector_db_path):
print('加载向量数据库路径 =》', vector_db_path)
db = FAISS.load_local(vector_db_path, embedding_model, allow_dangerous_deserialization=True)
else:
print('创建向量数据库路径 =》', vector_db_path)
db = await FAISS.afrom_documents(split_docs, embedding_model)
db.save_local(vector_db_path)
return db
@classmethod
def chroma_vector_db(cls, split_docs, vector_db_path, embedding_model):
"""
https://python.langchain.com/docs/modules/data_connection/vectorstores/
faiss 创建向量数据库
:param split_docs: 分割的文本块
:param vector_db_path: 向量数据库存储路径
:param embedding_model: embedding 模型
:return:
"""
if os.path.exists(vector_db_path):
print('加载向量数据库路径 =》', vector_db_path)
db = Chroma(persist_directory=vector_db_path, embedding_function=embedding_model)
else:
print('创建向量数据库路径 =》', vector_db_path)
db = Chroma.from_documents(split_docs, embedding_model, persist_directory=vector_db_path)
db.persist()
return db
class Retriever():
@classmethod
def similarity(cls, db, query, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/vectorstore/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
相似度,不带分数的,会把检索出所有最相似的返回,如果文档中有重复的,那会返回重复的
:param db:
:param query:
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def similarity_with_score(cls, db, query, topk=5, long_context=False):
"""
https://python.langchain.com/docs/integrations/vectorstores/usearch/#similarity-search-with-score
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
带分数的,距离分数是L2距离。因此,分数越低越好
:param db:
:param query:
:param long_context: 长上下文排序
:return:
"""
retriever_docs = db.similarity_search_with_score(query, k=topk)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def mmr(cls, db, query, topk=5, fetch_k=50, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/vectorstore/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
mmr 算法会去重,会把检索出所有最相似的返回
:param db:
:param query:
:param topk: 指定最相似的返回几个, 最多返回的数量不会超过 fetch_k
:param fetch_k: 给 mmr 的最多文档数
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_type="mmr", ssearch_kwargs={'k': topk, 'fetch_k': fetch_k})
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def similarity_score_threshold(cls, db, query, topk=5, score_threshold=0.8, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
相似分数过滤
:param db:
:param query:
:param topk:
:param score_threshold: 相似分数
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={'k': topk, "score_threshold": score_threshold})
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def multi_query_retriever(cls, db, query, model, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
多查询检索器
基于向量距离的检索可能因微小的询问词变化或向量无法准确表达语义而产生不同结果;
使用大预言模型自动从不同角度生成多个查询,实现提示词优化;
对用户查询生成表达其不同方面的多个新查询(也就是query利用大模型生成多个表述),对每个表述进行检索,去结果的并集;
优点是生成的查询多角度,可以覆盖更全面的语义和信息需求;
指定 topk 好像没用,不知道为什么
:param db:
:param query:
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
retriever = MultiQueryRetriever.from_llm(retriever=retriever, llm=model)
retriever_docs = retriever.get_relevant_documents(query=query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def contextual_compression_by_llm(cls, db, query, model, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
上下文压缩检索器,大模型,会对结果去重
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
相当于提取每个检索结果的核心,简化每个文档,利用大模型的能力
不知道为什么 topk 不管用
:param db:
:param query:
:param model:
:param topk:
:param long_context: 长上下文排序
:return:
"""
_filter = LLMChainFilter.from_llm(model)
retriever = db.as_retriever(search_kwargs={'k': topk})
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def contextual_compression_by_embedding(cls, db, query, embedding_model, topk=5, similarity_threshold=0.76,
long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
上下文压缩检索器,embedding 模型,会对结果去重
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
利用 embedding 来计算
:param db:
:param query:
:param embedding_model:
:param topk:
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
embeddings_filter = EmbeddingsFilter(embeddings=embedding_model, similarity_threshold=similarity_threshold)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def contextual_compression_by_embedding_split(cls, db, query, embedding_model, topk=5, similarity_threshold=0.76,
chunk_size=100, chunk_overlap=0, separator=". ", long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
上下文压缩检索器,embedding 模型,会对结果去重,将文档分割成更小的部分
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
利用 embedding 来计算
:param db:
:param query:
:param embedding_model:
:param topk: 不生效,默认是 4 个
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap, separator=separator)
redundant_filter = EmbeddingsRedundantFilter(embeddings=embedding_model)
relevant_filter = EmbeddingsFilter(embeddings=embedding_model, similarity_threshold=similarity_threshold)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def ensemble(cls, query, text_split_docs, embedding_model, bm25_topk=5, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
混合检索
最常见的模式是将稀疏检索器(如 BM25)与密集检索器(如嵌入相似性)相结合,因为它们的优势是互补的。它也被称为“混合搜索”。
稀疏检索器擅长根据关键词查找相关文档,而密集检索器擅长根据语义相似度查找相关文档。
:param query:
:param text_split_docs: langchain 分割后的文档对象
:param long_context: 长上下文排序
:param bm25_topk: bm25 topk
:param topk: 相似性 topk
:return: 会返回两个的并集,结果可能会小于 bm25_topk + topk
"""
text_split_docs = [text.page_content for text in text_split_docs]
bm25_retriever = BM25Retriever.from_texts(
text_split_docs, metadatas=[{"source": 1}] * len(text_split_docs)
)
bm25_retriever.k = bm25_topk
faiss_vectorstore = FAISS.from_texts(
text_split_docs, embedding_model, metadatas=[{"source": 2}] * len(text_split_docs)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": topk})
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
retriever_docs = ensemble_retriever.invoke(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def bm25(cls, query, text_split_docs, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
稀疏检索器擅长根据关键词查找相关文档
:param query:
:param text_split_docs: langchain 分割后的文档对象
:param topk:
:param long_context: 长上下文压缩
"""
text_split_docs = [text.page_content for text in text_split_docs]
bm25_retriever = BM25Retriever.from_texts(
text_split_docs, metadatas=[{"source": 1}] * len(text_split_docs)
)
bm25_retriever.k = topk
retriever_docs = bm25_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def parent_document_retriever(cls, docs, query, embedding_model):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/parent_document_retriever/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
父文档检索,只适合,chroma 数据库, faiss 不支持
适合多个文档加载进来后检索出符合的小文本段,及对应大的 txt
可以根据此方法,检索出来大的 txt 后,用其他方法再精细化检索 txt 中的内容
:param docs: example
loaders = [
TextLoader("data/专业描述.txt", encoding="utf-8"),
TextLoader("data/专业描述_copy.txt", encoding="utf-8"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
:return:
"""
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(
collection_name="full_documents", embedding_function=embedding_model
)
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
sub_docs = vectorstore.similarity_search(query)
parent_docs = retriever.get_relevant_documents(query)
return sub_docs, parent_docs
@classmethod
def tfidf(cls, query, docs_lst, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
tfidf 关键词检索
:param query:
:param docs_lst: ['xxx', 'dsfsdg'.....]
:param long_context: 长上下文排序
:return:
"""
retriever = TFIDFRetriever.from_texts(docs_lst)
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def knn(cls, query, docs_lst, embedding_model,long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
knn 检索
:param query:
:param docs_lst: ['xxx', 'dsfsdg'.....]
:param long_context:
:return:
"""
retriever = KNNRetriever.from_texts(docs_lst, embedding_model)
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
class Prompt():
@classmethod
def prompt_template(cls, prompt_string, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#prompttemplate
基本 prompt 接受变量的写法,也可以不传入变量
:param prompt_string: 字符串 prompt,变量用 {} 括起来
:param kwargs: 字典,依次传入的变量取值
e.g prompt_string="可以给我介绍一下`{fruit}`还有`{fruit2}`吗?",
fruit='苹果', fruit2='香蕉'
可以给我介绍一下`苹果`还有`香蕉`吗?
:return:
"""
prompt_template = PromptTemplate.from_template(prompt_string)
prompt = prompt_template.format(**kwargs)
return prompt
@classmethod
def chat_prompt_template(cls, text):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#chatprompttemplate
对话式模版
content 可以手动设置好,每次传入人工的提示词 text
:param text:
:return:
"""
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant that re-writes the user's text to "
"sound more upbeat."
)
),
HumanMessagePromptTemplate.from_template("{text}"),
]
)
messages = chat_template.format_messages(text=text)
return messages
@classmethod
def chat_message_prompt_template(cls, prompt_string, role='human', **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#message-prompts
聊天模型支持以任意角色获取聊天消息,您可以使用ChatMessagePromptTemplate,它允许用户指定角色名称
:param prompt_string:
:param role: 指定的角色
:param kwargs:
:return:
"""
chat_message_prompt = ChatMessagePromptTemplate.from_template(
role=role, template=prompt_string
)
message = chat_message_prompt.format(**kwargs)
return message
@classmethod
def messages_placeholder(cls, human_prompt, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#messagesplaceholder
可以让您完全控制格式化期间要呈现的消息。当您不确定消息提示模板应使用什么角色或希望在格式化期间插入消息列表时,这会很有用
content 可以手动定义
:param human_prompt:
:param kwargs: prompt 变量
:return:
"""
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
[MessagesPlaceholder(variable_name="conversation"), human_message_template]
)
human_message = HumanMessage(content="What is the best way to learn programming?")
ai_message = AIMessage(
content="""\
1. Choose a programming language: Decide on a programming language that you want to learn.
2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.
3. Practice, practice, practice: The best way to learn programming is through hands-on experience\
"""
)
message = chat_prompt.format_prompt(
conversation=[human_message, ai_message], **kwargs
).to_messages()
return message
@classmethod
def example_selectors_length_based(cls, examples, string, max_length=25):
"""
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/length_based/
按 prompt 长度选择示例
prefix 可以定义,是显示在开头的
:param examples: 示例列表
e.g examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
:param examples: 传进来的 prompt
:param max_length: 传进来的 prompt 最大长度小于它则选择全部示例,否则根据长度自动选择几个示例
:return:
"""
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = LengthBasedExampleSelector(
# The examples it has available to choose from.
examples=examples,
# The PromptTemplate being used to format the examples.
example_prompt=example_prompt,
max_length=max_length,
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
example_prompt = dynamic_prompt.format(adjective=string)
return example_prompt
@classmethod
def example_selectors_by_mmr(cls, examples, string, embedding_model, k=2):
"""
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/mmr/
根据与输入最相似的示例的组合来选择示例,同时还针对多样性进行优化。
它通过查找与输入具有最大余弦相似度的嵌入示例来实现这一点,然后迭代地添加它们,同时惩罚它们与已选择示例的接近程度
总的来说就是选出的每个示例尽量都不相相似,不重复
prefix 可以自己定义,显示在开头的
:param examples: 示例列表
e.g examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
:param string: prompt 字符串
:param examples:
:param embedding_model:
:param k: 选几个示例
:return:
"""
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples, embedding_model, FAISS, k=k
)
mmr_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
mmr_prompt = mmr_prompt.format(adjective=string)
return mmr_prompt
@classmethod
def example_selectors_similarity(cls, examples, string, embedding_model, k=1):
"""
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/similarity/
该对象根据与输入的相似性来选择示例。它通过查找与输入具有最大余弦相似度的嵌入示例来实现这一点。
会选择跟 string 相似的示例
:param examples: 示例列表
e.g examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
:param string:
:param embedding_model:
:param k: 选择几个
:return:
"""
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, embedding_model, Chroma, k=k,
)
similar_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
similar_prompt = similar_prompt.format(adjective=string)
return similar_prompt
@classmethod
def few_shot_examples_chat(cls, examples, string, model):
"""
https://python.langchain.com/docs/modules/model_io/prompts/few_shot_examples_chat/#fixed-examples
适用于 chat 模型
system 可以手动设置
:param examples:
e.g examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
:param string:
:param model: 大模型
:return:
"""
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
few_shot_prompt = few_shot_prompt.format()
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
chain = final_prompt | model
res = chain.invoke({"input": string})
return res
@classmethod
def few_shot_examples(cls, examples, string, embedding_model, k=1):
"""
https://python.langchain.com/docs/modules/model_io/prompts/few_shot_examples/#create-the-example-set
根据与输入的相似性来选择少数样本。它使用嵌入模型来计算输入和少数样本之间的相似度,并使用向量存储来执行最近邻搜索。
:param examples: 列表,参照 few_shot_examples_chat 样例
:param string:
:param embedding_model:
:return:
"""
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
""",
}
]
example_prompt = PromptTemplate(
input_variables=["question", "answer"], template="Question: {question}\n{answer}"
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, embedding_model, Chroma, k=k,
)
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"],
)
prompt = prompt.format(input=string)
return prompt
class Chain():
@classmethod
def base_llm_chain(cls, model, prompt, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/composition/#string-prompt-composition
基础链,带有变量的 prompt ,model 两个组成链
:param model: llm
:param prompt: prompt 其中的变量是用 {} 括起来的
:param kwargs: prompt 中的变量
:return:
"""
prompt = PromptTemplate.from_template(prompt)
chain = LLMChain(llm=model, prompt=prompt)
res = chain.run(kwargs)
return res
@classmethod
def batch_base_llm_chain(cls, model, prompt, max_concurrency=5, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/composition/#string-prompt-composition
基础链,带有变量的 prompt ,model 两个组成链,批次调用
:param model: llm
:param prompt: prompt 其中的变量是用 {} 括起来的
:param kwargs: prompt 中的变量
:param max_concurrency: 并发请求数
e.g:
promt = 'tell me a joke about {other} and {topic2}'
other = ['bear', 'dog']
topic2 = ['cat', 'monkey']
传进来后的 kwargs: kwargs = {'topic1': ['bear', 'dog'], 'topic2': ['cat', 'monkey']}
处理后 batch_list: batch_list = [{"topic1": "bears", "topic2": "cat"}, {"topic1": "dog", "topic2": "monkey"}]
:return:
"""
prompt = PromptTemplate.from_template(prompt)
chain = LLMChain(llm=model, prompt=prompt)
# 确保所有列表长度相同,构造批次列表
keys = list(kwargs.keys())
first_list_length = len(kwargs[keys[0]])
if all(len(kwargs[key]) == first_list_length for key in keys):
# 使用zip函数将所有值配对
paired_values = zip(*[kwargs[key] for key in keys])
# 遍历配对后的值,构造新的字典列表
batch_list = [dict(zip(keys, values)) for values in paired_values]
else:
print("批次对应列表长度不一致,无法转换。")
return None
res = chain.batch(batch_list, config={"max_concurrency": max_concurrency})
return res
@classmethod
def base_chat_llm_chain(cls, model, inputs, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/composition/#string-prompt-composition
基础链,对话模型 prompt ,model 两个组成链
:param model:
:param input: 输入
:param kwargs: 可以带一些变量
:return:
"""
prompt = SystemMessage(content="你是个智能助手,能回答各种各样的问题。")
new_prompt = (
prompt + HumanMessage(content="hi") + AIMessage(content="what?") + "{input}"
)
new_prompt.format_messages(input="i said hi")
chain = LLMChain(llm=model, prompt=new_prompt)
res = chain.run(inputs)
return res
@classmethod
def csv_parser_chain(cls, prompt_string, model, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/output_parsers/types/csv/
列表格式
:param prompt_string: prompt 字符串,里面变量使用 {} 括起来
:param model: llm
:param kwargs: 字典变量
:return:
"""
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
kwargs['format_instructions'] = format_instructions # 格式化输出设置
prompt = PromptTemplate(
template=prompt_string+"\n{format_instructions}",
input_variables=[],
partial_variables=kwargs, # 变量赋值
)
chain = prompt | model | output_parser
res = chain.invoke({})
return res
@classmethod
def datetime_parser_chain(cls, prompt_string, model, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/output_parsers/types/datetime/
输出时间格式,2009-01-03 18:15:05
:param prompt_string: prompt 字符串,里面变量使用 {} 括起来
:param model: llm
:param kwargs: 字典变量
:return:
"""
output_parser = DatetimeOutputParser()
template = prompt_string + """{format_instructions}"""
kwargs['format_instructions'] = output_parser.get_format_instructions() # 设置输出格式
prompt = PromptTemplate.from_template(
template,
partial_variables=kwargs, # 设置所有变量
)
chain = prompt | model | output_parser
output = chain.invoke({})
return output
@classmethod
def json_parser_chain(cls, prompt_string, model, json_class=None, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/output_parsers/types/json/
json
:param prompt_string: prompt 字符串,里面变量是已经填充好的
:param model: llm
:param enum_class: json 类,用来指定输出字典的键,也可以不用指定,这样默认就一个键
from langchain_core.pydantic_v1 import BaseModel, Field
e.g class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
:param kwargs: 字典变量
:return:
"""
parser = JsonOutputParser(pydantic_object=json_class)
format_instructions = parser.get_format_instructions()
kwargs['format_instructions'] = format_instructions # 格式化输出设置
kwargs['prompt_string'] = prompt_string
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{prompt_string}\n",
input_variables=[],
partial_variables=kwargs, # 设置所有变量
)
chain = prompt | model | parser
res = chain.invoke({})
return res
class Tools():
@classmethod
def python_repl_tool(cls, code):
"""
https://python.langchain.com/docs/integrations/tools/python/
可以执行 python 代码,但是注意缩进
:param code:
:return:
"""
python_repl = PythonREPL()
res = python_repl.run(code)
return res
# # You can create the tool to pass to an agent
# repl_tool = Tool(
# name="python_repl",
# description="A Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`.",
# func=python_repl.run,
# )
@classmethod
def requests_get_tool(cls, url):
"""
https://python.langchain.com/docs/integrations/tools/requests/
可能有乱码,好像没有指定编码的参数
requests_tools 包含以下包装器
[RequestsGetTool(name='requests_get', description='A portal to the internet. Use this when you need to get specific content from a website. Input should be a url (i.e. https://www.google.com). The output will be the text response of the GET request.', args_schema=None, return_direct=False, verbose=False, callbacks=None, callback_manager=None, requests_wrapper=TextRequestsWrapper(headers=None, aiosession=None)),
RequestsPostTool(name='requests_post', description='Use this when you want to POST to a website.\n Input should be a json string with two keys: "url" and "data".\n The value of "url" should be a string, and the value of "data" should be a dictionary of \n key-value pairs you want to POST to the url.\n Be careful to always use double quotes for strings in the json string\n The output will be the text response of the POST request.\n ', args_schema=None, return_direct=False, verbose=False, callbacks=None, callback_manager=None, requests_wrapper=TextRequestsWrapper(headers=None, aiosession=None)),
RequestsPatchTool(name='requests_patch', description='Use this when you want to PATCH to a website.\n Input should be a json string with two keys: "url" and "data".\n The value of "url" should be a string, and the value of "data" should be a dictionary of \n key-value pairs you want to PATCH to the url.\n Be careful to always use double quotes for strings in the json string\n The output will be the text response of the PATCH request.\n ', args_schema=None, return_direct=False, verbose=False, callbacks=None, callback_manager=None, requests_wrapper=TextRequestsWrapper(headers=None, aiosession=None)),
RequestsPutTool(name='requests_put', description='Use this when you want to PUT to a website.\n Input should be a json string with two keys: "url" and "data".\n The value of "url" should be a string, and the value of "data" should be a dictionary of \n key-value pairs you want to PUT to the url.\n Be careful to always use double quotes for strings in the json string.\n The output will be the text response of the PUT request.\n ', args_schema=None, return_direct=False, verbose=False, callbacks=None, callback_manager=None, requests_wrapper=TextRequestsWrapper(headers=None, aiosession=None)),
RequestsDeleteTool(name='requests_delete', description='A portal to the internet. Use this when you need to make a DELETE request to a URL. Input should be a specific url, and the output will be the text response of the DELETE request.', args_schema=None, return_direct=False, verbose=False, callbacks=None, callback_manager=None, requests_wrapper=TextRequestsWrapper(headers=None, aiosession=None))]
:param url:
:return:
"""
# requests_tools = load_tools(["requests_all"])
# # Each tool wrapps a requests wrapper
# requests_tools[0].requests_wrapper
requests = TextRequestsWrapper()
res = requests.get(url)
return res