目录
1)启动hadoop,为当前登录的Windows用户在HDFS中创建用户目录
3)将windows操作系统本地的一个文件上传到hdfs的test目录中
4)把test目录复制到windows本地文件系统某个目录下
1,Hadoop简介
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。 高可靠性。 高效性。 高可扩展性。 高容错性。 成本低。 运行在Linux平台上。 支持多种编程语言。,2,分布式文件系统HDFS
2,分布式文件系统HDFS
1. HDFS简介
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop项目的两大核心之一,是针对谷歌文件系统(Google File System,GFS)的开源实现。 总体而言,HDFS要实现以下目标: 兼容廉价的硬件设备。 流数据读写。 大数据集。 简单的文件模型。 强大的跨平台兼容性。
2.HDFS体系结构

Hadoop包含了HDFS和MapReduce两大核心组件,本教程主要使用HDFS,没有使用MapReduce,但是,仍然要完整地安装Hadoop。这里采用的Apache Hadoop版本是3.1.3。 Hadoop包括三种安装模式:
单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
3,Hadoop的安装
这里介绍Hadoop伪分布式模式的安装方法。
到Hadoop官网(https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/)下载Hadoop3.1.3安装文件hadoop-3.1.3.tar.gz。
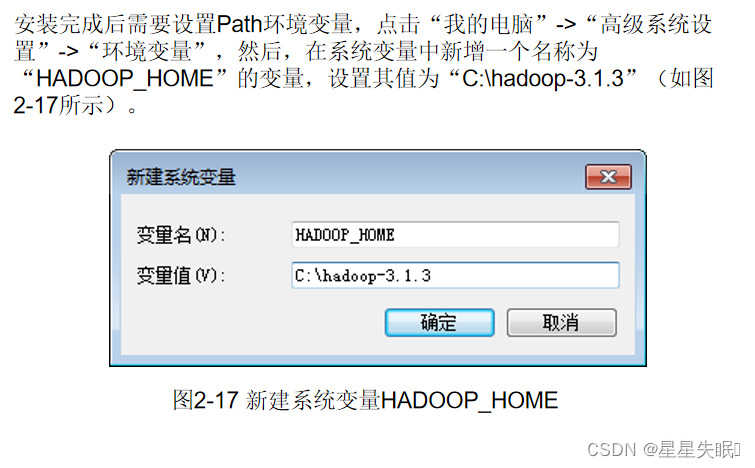
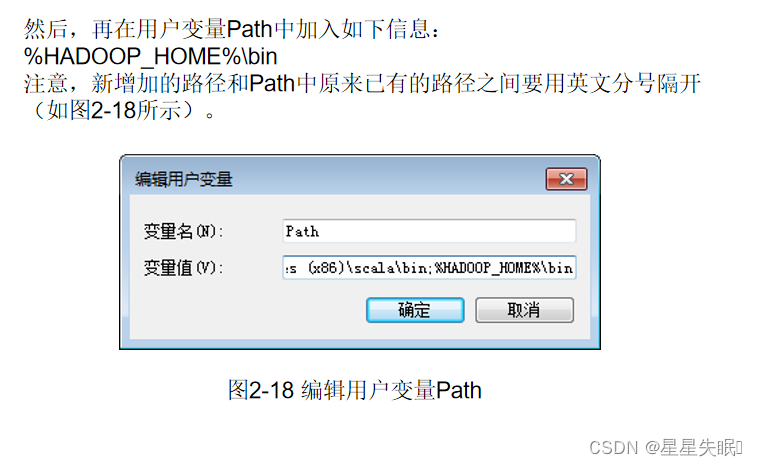
由于Hadoop不直接支持Windows系统,因此,需要使用工具集winutils进行支持。到github.com网站(https://github.com/s911415/apache-hadoop-3.1.3-winutils)下载与Hadoop3.1.3配套的winutils。进入下载页面后,如图2-16所示,点击“Code”按钮,然后在弹出的菜单中点击“Download ZIP”即可下载得到压缩文件apache-hadoop-3.1.3-winutils-master.zip,再将该压缩文件进行解压缩。
把Hadoop3.1.3安装文件hadoop-3.1.3.tar.gz解压缩到“C:\”(或者其他目录),使用winutils中的bin目录整个替换Hadoop中的bin目录。
在“C:\ hadoop-3.1.3”目录下新建tmp目录,再在tmp目录下新建两个子目录,分别是datanode和namenode。
对“C:\ hadoop-3.1.3\etc\hadoop”下面的3个配置文件进行修改。
把core-site.xml文件的配置修改为如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
把hdfs-site.xml文件的配置修改为如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/C:/hadoop-3.1.3/tmp/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/C:/hadoop-3.1.3/tmp/datanode</value> </property> </configuration>
修改hadoop-env.cmd文件,找到如下一行: set JAVA_HOME=%JAVA_HOME% 把%JAVA_HOME%替换成JDK的绝对路径,比如: set JAVA_HOME=C:\ Java\jdk1.8.0_111 需要注意的是,如果JDK路径中包含了空格,如果直接使用如下设置后面步骤会报错: set JAVA_HOME= C:\Program Files\Java\jdk1.8.0_111 如果采用这种带有空格的路径,后面运行“hdfs namenode -format”命令时就会报错,因为Program Files中存在空格。为了解决这个问题,可以使用下面两种方式之一进行处理:
(1)只需要用PROGRA~1 代替Program Files,即改为C:\PROGRA~1\Java\jdk1.8.0_111 (2)或是使用双引号,即改为 “C:\Program Files”\Java\jdk1.8.0_111
然后,在Windows系统中打开一个cmd窗口,执行如下命令对Hadoop系统进行格式化:
> cd c:\hadoop-3.1.3\bin
> hdfs namenode -format
上述命令执行以后,如果返回类似如下的信息则表示格式化成功:
\hadoop-3.1.3\tmp\namenode has been successfully formatted. 执行如下命令启动
> cd c:\hadoop-3.1.3\sbin
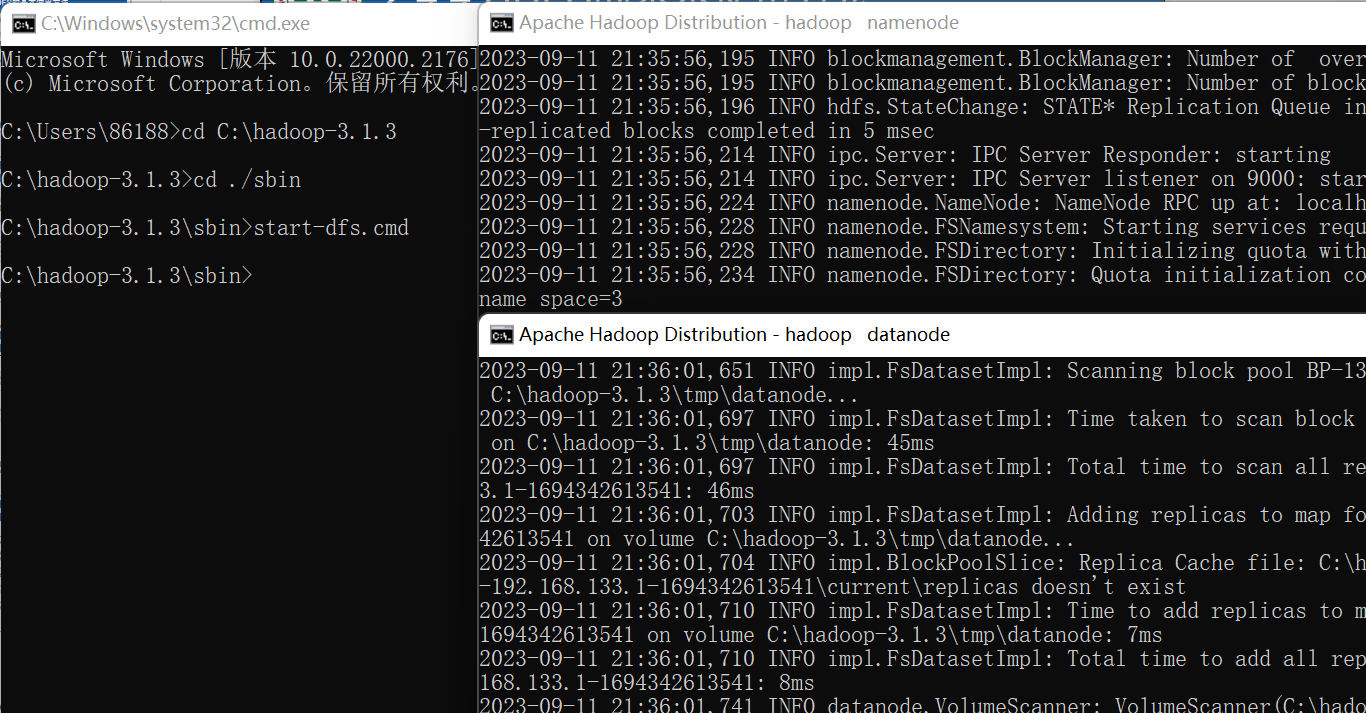
> start-dfs.cmd 执行该命令以后,会同时弹出另外2个cmd窗口,这2个新弹出的cmd窗口不要关闭,然后,在刚才执行start-dfs.cmd命令的cmd窗口内,继续执行JDK自带的命令jps查看Hadoop已经启动的进程:
> jps
需要注意的是,这里在使用jps命令的时候,没有带上绝对路径,是因为已经把JDK添加到了Path环境变量中。 执行jps命令以后,如果能够看到“DataNode”和“NameNode”这两个进程,就说明Hadoop启动成功。 需要关闭Hadoop时,可以执行如下命令:
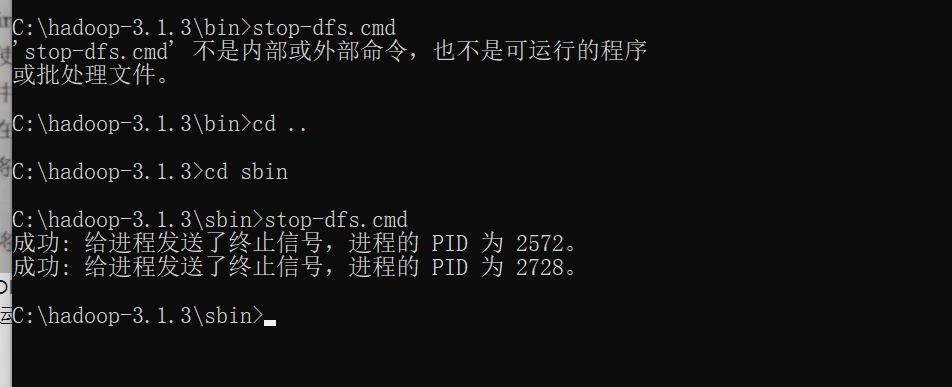
> cd c:\hadoop-3.1.3\sbin > stop-dfs.cmd
1.使用WEB管理页面操作HDFS
首先启动Hadoop,然后可以在浏览器中输入“http://localhost:9870”,就可以访问Hadoop的WEB管理页面
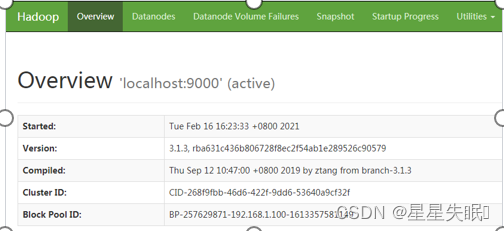
在WEB管理页面中,点击顶部右侧的菜单选项“Utilities”,在弹出的子菜单中点击“Browse the file system”,会出现如图2-20所示的HDFS文件系统操作页面,在这个页面中可以创建、查看、删除目录和文件
2.使用命令操作HDFS
除了在浏览器中通过WEB方式操作HDFS以外,还可以在cmd窗口中使用命令对HDFS进行操作。

4,HDFS的基本使用方法
1)启动hadoop,为当前登录的Windows用户在HDFS中创建用户目录
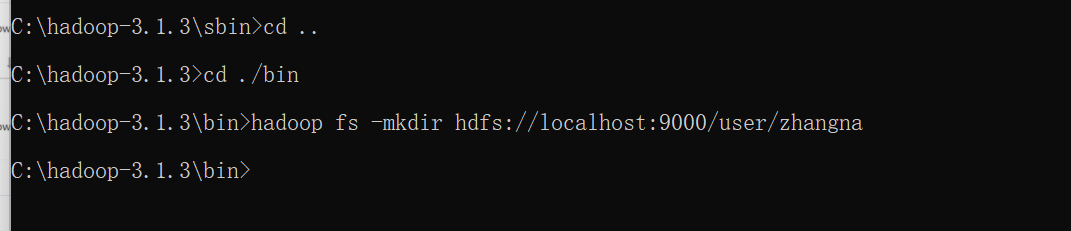
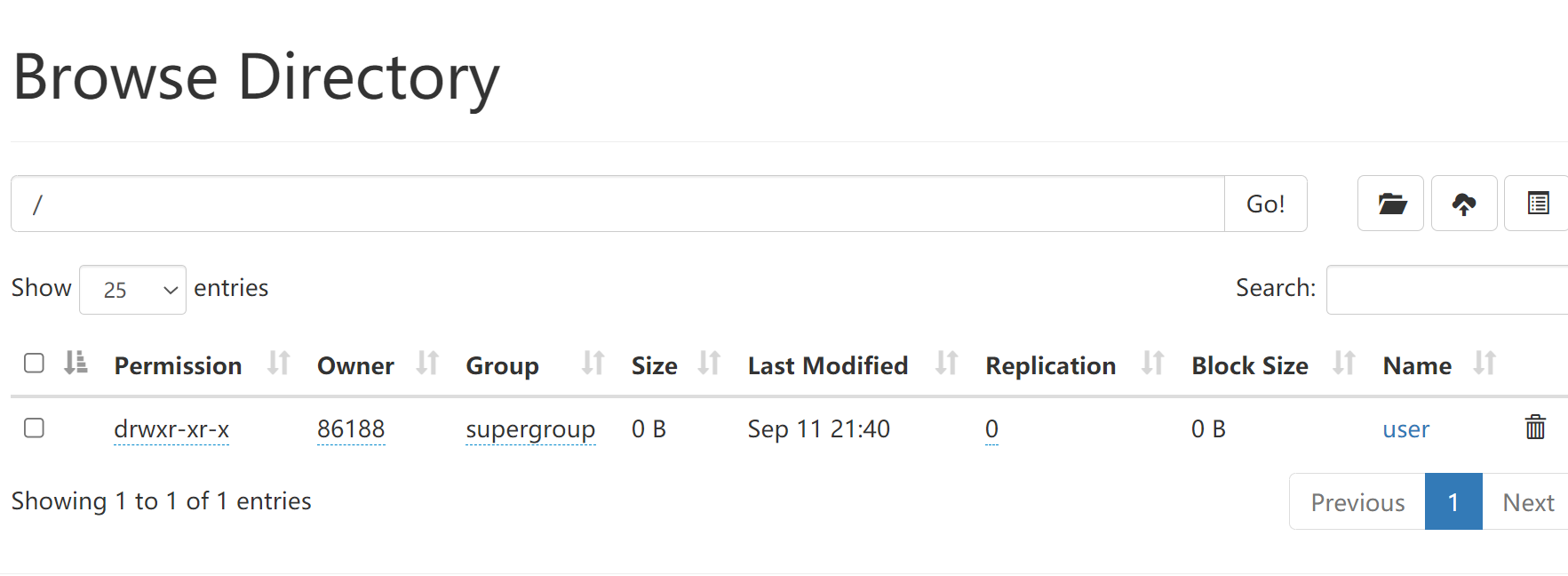

2)在用户名user/zhangna下创建test目录

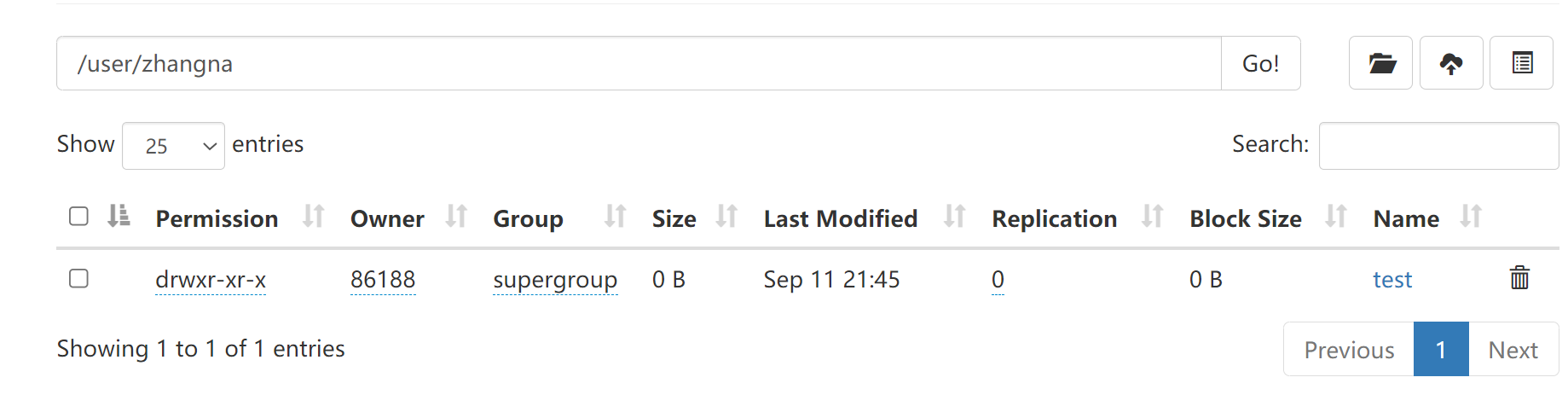
在user/zhangna下有了test目录了
3)将windows操作系统本地的一个文件上传到hdfs的test目录中

我把文件保存到了D盘,并且用hadoop命令put把文件传到了test目录中
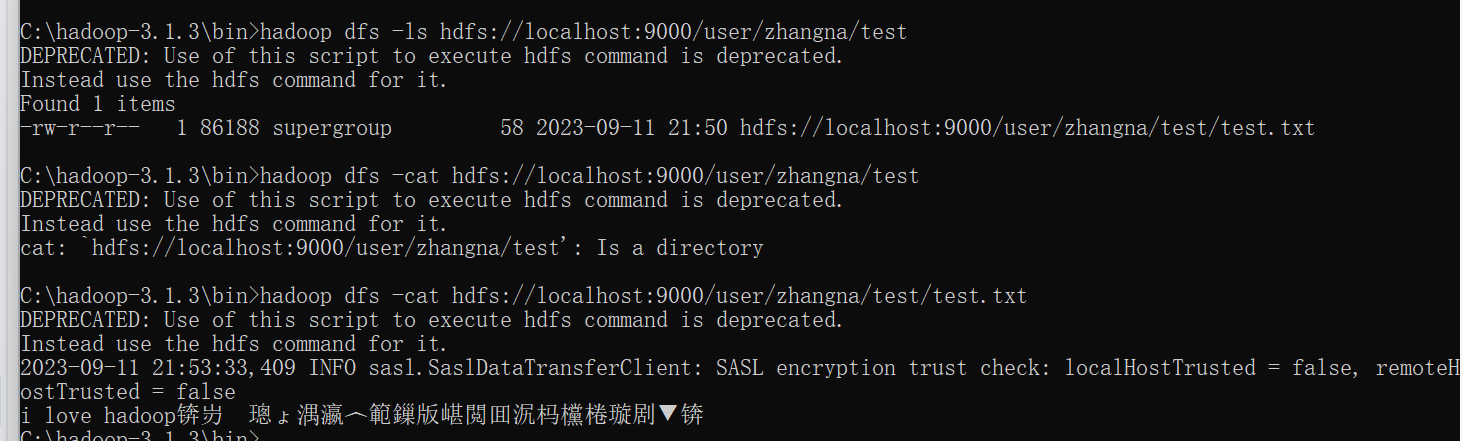
在cmd命令提示符中出现了乱码,在浏览器查看hadoop可以显示出内容
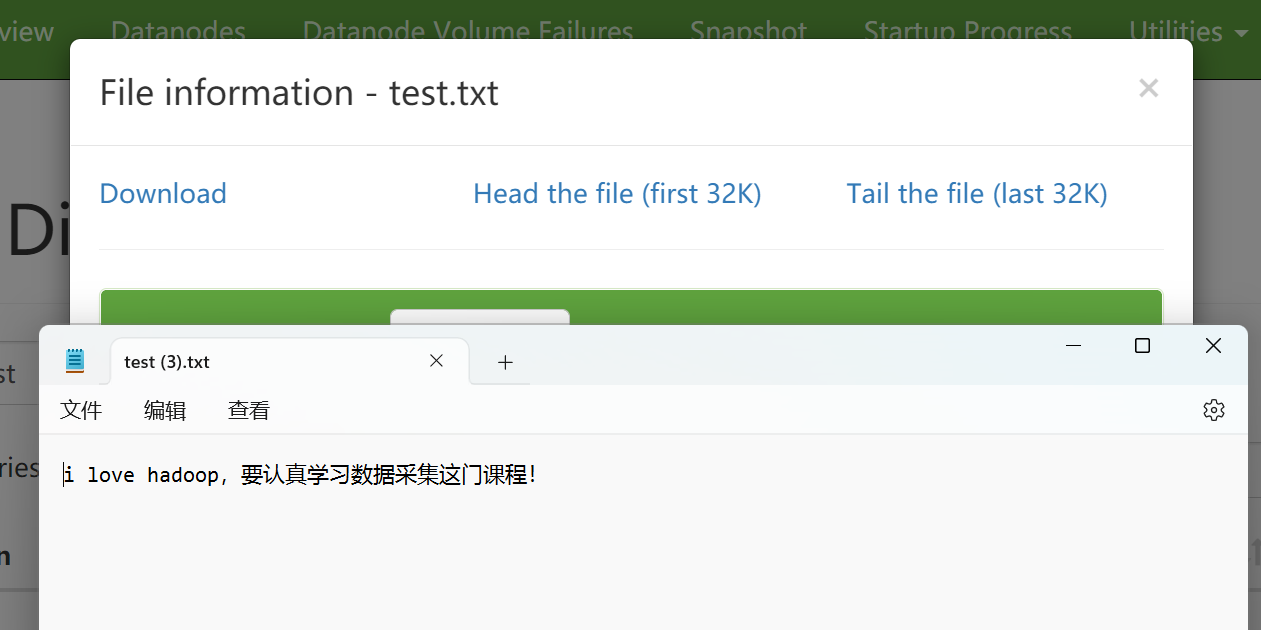
4)把test目录复制到windows本地文件系统某个目录下

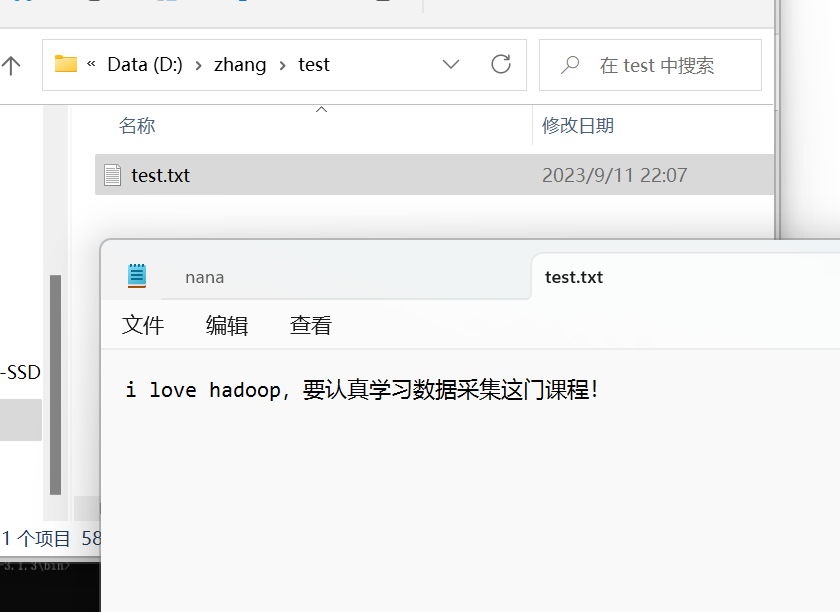
在D盘下面我创建的zhang的文件夹下有test目录,并且有test.txt文件