1. Reduce Join


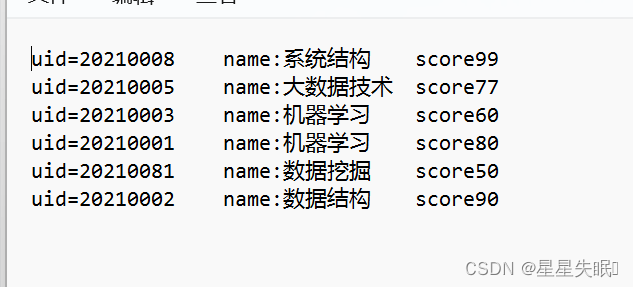
解题思路:
map输出key value是什么?


reduce输出key value是什么?
package com.nefu.zhangna.reducejoin;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class ScoreBeann implements Writable {
private String uid;
private String sid;
private int score;
private String name;
private String flag;
public ScoreBeann() {
}
public String getUid(){
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getSid() {
return sid;
}
public void setSid(String sid) {
this.sid = sid;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(uid);
out.writeUTF(sid);
out.writeInt(score);
out.writeUTF(name);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.uid=in.readUTF();
this.sid=in.readUTF();
this.score=in.readInt();
this.name=in.readUTF();
this.flag=in.readUTF();
}
@Override
public String toString(){
return "uid="+this.uid+"\t"+"name:"+this.name+"\t"+"score"+this.score;
}
}
ScoreMapper
package com.nefu.zhangna.reducejoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ScoreMapper extends Mapper<LongWritable, Text,Text, ScoreBeann>{
private Text outk=new Text();
private ScoreBeann outv=new ScoreBeann();
private String filename;
@Override
protected void setup(Context context){
FileSplit split=(FileSplit) context.getInputSplit();
filename=split.getPath().getName();
}
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String line=value.toString();
if (filename.contains("score")){
String[] sp=line.split("\t");
outk.set(sp[1]);
outv.setSid(sp[1]);
outv.setUid(sp[0]);
outv.setName("");
outv.setScore(Integer.parseInt(sp[2]));
outv.setFlag("score");
}else {
String[] sp1=line.split("\t");
outk.set(sp1[0]);
outv.setUid("");
outv.setName(sp1[1]);
outv.setScore(0);
outv.setSid(sp1[0]);
outv.setFlag("name");
}
context.write(outk,outv);
}
}
ScoreReducer
package com.nefu.zhangna.reducejoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
public class ScoreReducer extends Reducer<Text, ScoreBeann,ScoreBeann,NullWritable> {
@Override
protected void reduce(Text key,Iterable<ScoreBeann> values,Context context) throws IOException, InterruptedException {
ArrayList<ScoreBeann> scoreBeanns=new ArrayList<ScoreBeann>();
ScoreBeann namebean=new ScoreBeann();
for (ScoreBeann value:values){
if("score".equals(value.getFlag())){
ScoreBeann tmpbean=new ScoreBeann();
try {
BeanUtils.copyProperties(tmpbean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
scoreBeanns.add(tmpbean);
}else {
try {
BeanUtils.copyProperties(namebean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
for(ScoreBeann scoreBeann:scoreBeanns){
scoreBeann.setName(namebean.getName());
context.write(scoreBeann,NullWritable.get());
}
}
}
ScoreDriver
package com.nefu.zhangna.maxcount;
import com.nefu.zhangna.reducejoin.ScoreBeann;
import com.nefu.zhangna.reducejoin.ScoreMapper;
import com.nefu.zhangna.reducejoin.ScoreReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
public class ScoreDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration);
job.setJarByClass(ScoreDriver.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(ScoreBeann.class);
job.setOutputKeyClass(ScoreBeann.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\cluster\\input"));
FileOutputFormat.setOutputPath(job,new Path("D:\\cluster\\score"));
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}

2. Map Join
protected void setup(Context context) throws IOException { //获取缓存文件并封装到集合里 URI[] cacheFiles=context.getCacheFiles(); Path path=new Path(cacheFiles[0]); FileSystem fileSystem=FileSystem.get(context.getConfiguration()); FSDataInputStream fis=fileSystem.open(path); BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(fis,"utf-8")); String line; while (!StringUtils.isEmpty(line=bufferedReader.readLine())){ String[] fileds=line.split("\t"); rmap.put(fileds[0],fileds[1]); }这段代码是一个MapReduce程序中的setup方法,它在Mapper或Reducer任务执行之前被调用。具体来说,这段代码的目的是从分布式缓存中读取文件内容,并将文件内容解析后存储到一个集合(可能是一个Map)中。
让我们逐行解释这段代码:1.URI[] cacheFiles=context.getCacheFiles();: 通过context.getCacheFiles()获取分布式缓存中的文件列表的URI数组。
2.Path path=new Path(cacheFiles[0]);: 从URI数组中取第一个元素作为缓存文件的路径。
3.FileSystem fileSystem=FileSystem.get(context.getConfiguration());: 获取Hadoop文件系统(FileSystem)的实例,通过context.getConfiguration()获取配置信息。
4.FSDataInputStream fis=fileSystem.open(path);: 打开文件系统中指定路径的文件,返回一个文件输入流。
5.BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(fis,"utf-8"));: 使用BufferedReader读取文件输入流,并指定使用UTF-8字符集进行解码。
6.String line;: 声明一个字符串变量line,用于存储每次从文件中读取的一行数据。
7.while (!StringUtils.isEmpty(line=bufferedReader.readLine())){: 循环读取文件中的每一行,直到读取到的行为空(文件末尾)。这里使用了StringUtils.isEmpty()来判断是否为空行。
8.String[] fileds=line.split("\t");: 使用制表符(\t)分隔每一行的内容,将分割后的字段存储到字符串数组fileds中。
9.rmap.put(fileds[0],fileds[1]);: 将分割后的字段存储到一个集合(可能是一个Map)中,其中fileds[0]作为键,fileds[1]作为值。总体来说,这段代码的主要作用是在MapReduce任务开始执行前,从分布式缓存中读取一个文件,解析文件内容,并将解析后的数据存储到一个集合中,以便后续任务可以使用这些数据进行计算或其他操作。在这里,数据被存储在了rmap中。
在MapReduce框架中,setup方法在Mapper或Reducer任务执行之前被调用,用于初始化一些资源或数据。在这段代码中,主要的目的是在Map阶段之前从分布式缓存中加载文件,并将文件内容解析后存储到rmap集合中。
这样做的主要作用可能包括:1.数据预处理: 缓存文件中的数据可能需要在Map阶段使用,通过在setup方法中加载并解析文件,可以在Map任务执行时直接使用已准备好的数据,避免在每个Map任务内重复加载或解析文件。
2.共享静态数据: 如果缓存文件中包含一些静态数据,这些数据在整个MapReduce作业中都是相同的,可以通过在setup方法中加载一次,而不是在每个Map任务中重复加载,提高效率。
3.避免重复IO: 通过在setup阶段加载数据,可以避免在每个Map任务中重复进行文件的IO操作,提高整体性能。
4.初始化共享资源: 在某些情况下,可能需要在Map任务执行前初始化一些共享资源,这可以在setup方法中完成。总体来说,这样的操作可以提高MapReduce作业的性能,减少不必要的重复工作,并使得任务执行时所需的数据在启动时就已经准备好。