目录
二次补充:最终原因是两个集群distcp打满带宽导致的问题
以下问题分析也是可能导致集群慢的原因,仅供参考
最终根因的最终解释如下:两个hdfs集群通过distcp传输数据,而两个机器的网络单独是两个vlan,两个vlan之间的带宽被打满,导致网络问题。
对源端VLAN内网络的具体影响
内部通信受阻
- 源VLAN内的主机在进行内部通信时,如果需要通过共享的网络资源进行数据传输(如访问同一服务器或共享存储),则可能会受到带宽打满的影响。
- 这会导致内部通信速度下降,甚至可能出现通信中断的情况。
广播域受影响
- VLAN的一个主要功能是隔离广播域。然而,当源VLAN到目标VLAN的带宽打满时,可能会影响到广播域内的正常通信。
- 如果广播数据无法及时传输到目标VLAN,可能会在源VLAN内造成广播积压,进而影响源VLAN内的其他正常通信。
整体性能下降
- 带宽打满会导致网络整体性能下降,包括吞吐量、延迟和抖动等指标。
- 这会影响到源VLAN内所有主机的网络性能,可能导致整体网络体验变差。
问题描述
问题产生之前,上传30G,共40个文件,需要2-3分钟。
问题产生之后,上传需要5-8分钟
分析思路
上传慢的流程包括:上传服务器读磁盘、hdfs client和nn/dn的网络、datanode的磁盘写、集群nnrpc。
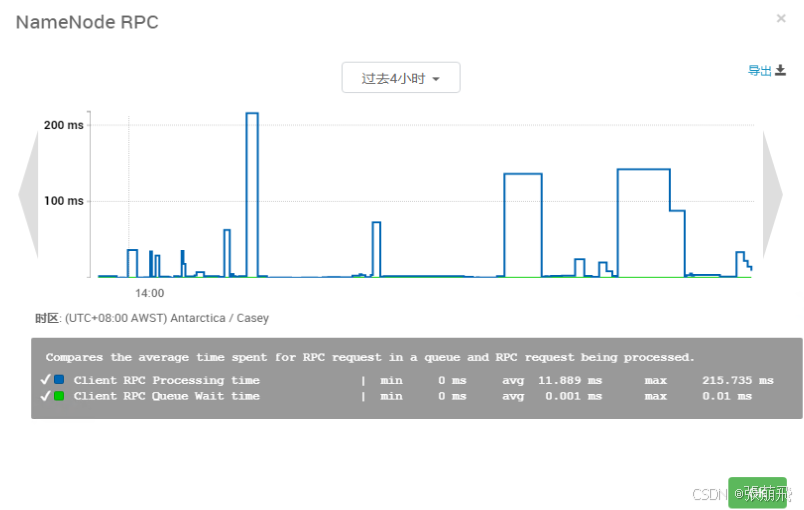
- namenode RPC:我这用的HDP(Cloudera也有自带的监控页面),查看ambari的metric,观察nn的rpc耗时是否异常,生产集群峰值正常在200-500ms左右,单位时间内超过的次数不多也算正常。
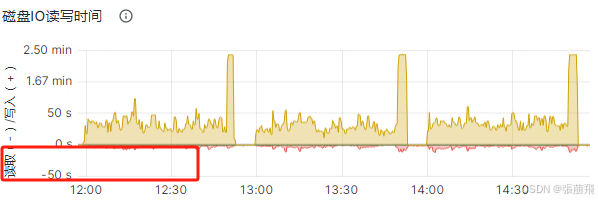
- 客户端服务器IO:优先查看hdfs client主机的磁盘io情况,第二再查cpu、内存、连接数;
- 网络:通过客户端scp一个大点的文件到dn主机,看先传输速度是否正常,我这边正常速度100MB/s;
- dn节点磁盘IO:我这通过普罗米修斯和Grafana,随机查看多个dn主机的IO;
- 上传任务:hdfs dfs -put 是不是单位时间内并行启动太多。
分析过程
NN RPC
客户端主机IO
读的io时间不长,不是瓶颈
网络
客户端主机分别生成1G和10G大小的文件
dd if=/dev/zero of=./1Gb.file bs=1G count=1;
dd if=/dev/zero of=./10Gb.file bs=1G count=10;使用scp命令测试传输速率
time scp 1Gb.file ip:/data
time scp 1Gb.file ip:/data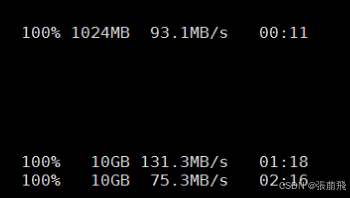
传输速度100MB/s,网络不是瓶颈
DN磁盘IO
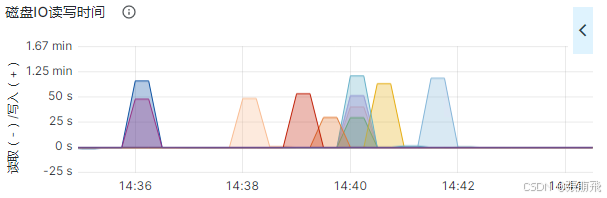
查看datanode服务的日志
vim datanode.log可以看到有Slow BlockReceiver的日志

根据Grafana的io高的时间段,在日志中随便找一条慢的block id,可以看到数据块写入到哪一块盘中
grep 4712711629 datanode.log
查找导致io高的目录
拿着block id去namenode日志中查找hdfs对应实际的文件的绝对路径
grep blk_4712711629_3705187104 namenode.log拿到路径后找业务,或者自己在调度平台上找对应的任务
上传任务
# 通过ps查看主机有多少个put进程
ps -ef|grep FsShell|wc -l查看上传脚本

根因结论
上传脚本中有&后台执行,会存在多个hdfs dfs -put并行上传,由于主机本身的读速率最大在200MB/s左右,峰值不超过300MB/s,当并行较多的时候,由于客户端读io的瓶颈,导致在写hdfs datanode的时候,有存在io抢占的问题,导致每一个datanode数据块写入磁盘的io时间变长,超过10s就会有hdfs集群整体写性能下降,其实最好是在2-5s就完成一次io写入。
解决办法
降低上传并行度,控制在io瓶颈范围内。