
导读:本文主要分为两个部分:一部分是网络爬虫的概述,帮助大家详细了解网络爬虫;另一部分是HTTP请求的Python实现,帮助大家了解Python中实现HTTP请求的各种方式,以便具备编写HTTP网络程序的能力。
作者:范传辉
如需转载请联系大数据(ID:hzdashuju)
01 网络爬虫概述
接下来从网络爬虫的概念、用处与价值和结构等三个方面,让大家对网络爬虫有一个基本的了解。
1. 网络爬虫及其应用
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,网络爬虫应运而生。网络爬虫(又被称为网页蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。下面通过图3-1展示一下网络爬虫在互联网中起到的作用:
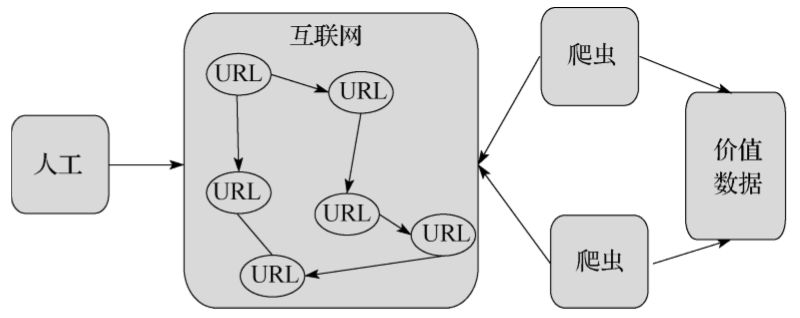
▲图3-1 网络爬虫
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
搜索引擎(Search Engine),例如传统的通用搜索引擎baidu、Yahoo和Google等,是一种大型复杂的网络爬虫,属于通用性网络爬虫的范畴。但是通用性搜索引擎存在着一定的局限性:
不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。
聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择地访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
说完了聚焦爬虫,接下来再说一下增量式网络爬虫。增量式网络爬虫是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。
例如:想获取赶集网的招聘信息,以前爬取过的数据没有必要重复爬取,只需要获取更新的招聘数据,这时候就要用到增量式爬虫。
最后说一下深层网络爬虫。Web页面按存在方式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的Web页面。深层网络是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。
例如用户登录或者注册才能访问的页面。可以想象这样一个场景:爬取贴吧或者论坛中的数据,必须在用户登录后,有权限的情况下才能获取完整的数据。
2. 网络爬虫结构
下面用一个通用的网络爬虫结构来说明网络爬虫的基本工作流程,如图3-4所示。
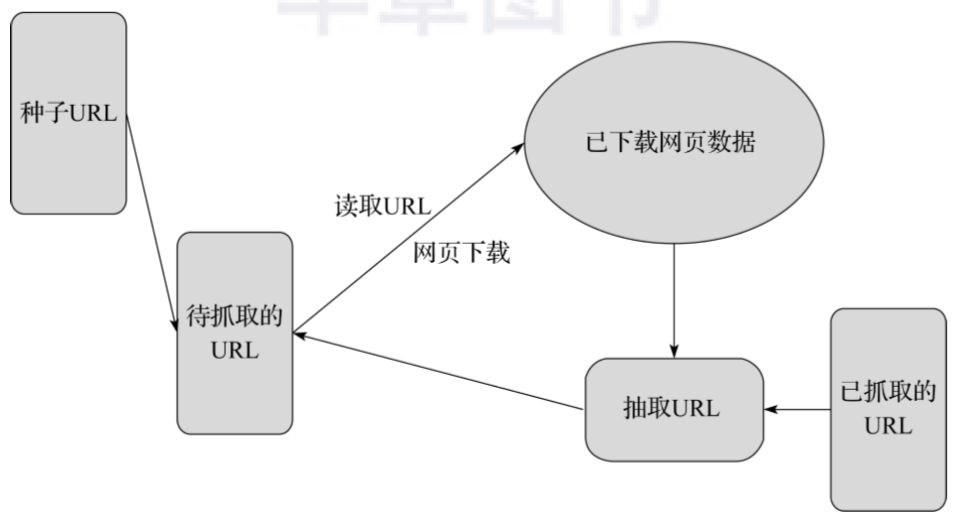
▲图3-4 网络爬虫结构
网络爬虫的基本工作流程如下:
首先选取一部分精心挑选的种子URL。
将这些URL放入待抓取URL队列。
从待抓取URL队列中读取待抓取队列的URL,解析DNS,并且得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,从已下载的网页数据中分析出其他URL,并和已抓取的URL进行比较去重,最后将去重过的URL放入待抓取URL队列,从而进入下一个循环。
02 HTTP请求的Python实现
通过上面的网络爬虫结构,我们可以看到读取URL、下载网页是每一个爬虫必备而且关键的功能,这就需要和HTTP请求打交道。接下来讲解Python中实现HTTP请求的三种方式:urllib2/urllib、httplib/urllib以及Requests。
1. urllib2/urllib实现
urllib2和urllib是Python中的两个内置模块,要实现HTTP功能,实现方式是以urllib2为主,urllib为辅。
1.1 首先实现一个完整的请求与响应模型
urllib2提供一个基础函数urlopen,通过向指定的URL发出请求来获取数据。最简单的形式是:
import urllib2
response=urllib2.urlopen('http://www.zhihu.com')
html=response.read()
print html其实可以将上面对http://www.zhihu.com的请求响应分为两步,一步是请求,一步是响应,形式如下:
import urllib2
# 请求
request=urllib2.Request('http://www.zhihu.com')
# 响应
response = urllib2.urlopen(request)
html=response.read()
print html
上面这两种形式都是GET请求,接下来演示一下POST请求,其实大同小异,只是增加了请求数据,这时候用到了urllib。示例如下:
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
postdata = {'username' : 'qiye',
'password' : 'qiye_pass'}
# info 需要被编码为urllib2能理解的格式,这里用到的是urllib
data = urllib.urlencode(postdata)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
html = response.read()但是有时会出现这种情况:即使POST请求的数据是对的,但是服务器拒绝你的访问。这是为什么呢?问题出在请求中的头信息,服务器会检验请求头,来判断是否是来自浏览器的访问,这也是反爬虫的常用手段。
1.2 请求头headers处理
将上面的例子改写一下,加上请求头信息,设置一下请求头中的User-Agent域和Referer域信息。
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
referer='http://www.xxxxxx.com/'
postdata = {'username' : 'qiye',
'password' : 'qiye_pass'}
# 将user_agent,referer写入头信息
headers={'User-Agent':user_agent,'Referer':referer}
data = urllib.urlencode(postdata)
req = urllib2.Request(url, data,headers)
response = urllib2.urlopen(req)
html = response.read()
也可以这样写,使用add_header来添加请求头信息,修改如下:
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
referer='http://www.xxxxxx.com/'
postdata = {'username' : 'qiye',
'password' : 'qiye_pass'}
data = urllib.urlencode(postdata)
req = urllib2.Request(url)
# 将user_agent,referer写入头信息
req.add_header('User-Agent',user_agent)
req.add_header('Referer',referer)
req.add_data(data)
response = urllib2.urlopen(req)
html = response.read()
对有些header要特别留意,服务器会针对这些header做检查,例如:
User-Agent:有些服务器或Proxy会通过该值来判断是否是浏览器发出的请求。
Content-Type:在使用REST接口时,服务器会检查该值,用来确定HTTP Body中的内容该怎样解析。在使用服务器提供的RESTful或SOAP服务时,Content-Type设置错误会导致服务器拒绝服务。常见的取值有:application/xml(在XML RPC,如RESTful/SOAP调用时使用)、application/json(在JSON RPC调用时使用)、application/x-www-form-urlencoded(浏览器提交Web表单时使用)。
Referer:服务器有时候会检查防盗链。
1.3 Cookie处理
urllib2对Cookie的处理也是自动的,使用CookieJar函数进行Cookie的管理。如果需要得到某个Cookie项的值,可以这么做:
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open('http://www.zhihu.com')
for item in cookie:
print item.name+':'+item.value但是有时候会遇到这种情况,我们不想让urllib2自动处理,我们想自己添加Cookie的内容,可以通过设置请求头中的Cookie域来做:
import urllib2
opener = urllib2.build_opener()
opener.addheaders.append( ( 'Cookie', 'email=' + "[email protected]" ) )
req = urllib2.Request( "http://www.zhihu.com/" )
response = opener.open(req)
print response.headers
retdata = response.read()
1.4 Timeout设置超时
在Python2.6之前的版本,urllib2的API并没有暴露Timeout的设置,要设置Timeout值,只能更改Socket的全局Timeout值。示例如下:
import urllib2
import socket
socket.setdefaulttimeout(10) # 10 秒钟后超时
urllib2.socket.setdefaulttimeout(10) # 另一种方式在Python2.6及新的版本中,urlopen函数提供了对Timeout的设置,示例如下:
import urllib2
request=urllib2.Request('http://www.zhihu.com')
response = urllib2.urlopen(request,timeout=2)
html=response.read()
print html
1.5 获取HTTP响应码
对于200 OK来说,只要使用urlopen返回的response对象的getcode()方法就可以得到HTTP的返回码。但对其他返回码来说,urlopen会抛出异常。这时候,就要检查异常对象的code属性了,示例如下:
import urllib2
try:
response = urllib2.urlopen('http://www.google.com')
print response
except urllib2.HTTPError as e:
if hasattr(e, 'code'):
print 'Error code:',e.code
1.6 重定向
urllib2默认情况下会针对HTTP 3XX返回码自动进行重定向动作。要检测是否发生了重定向动作,只要检查一下Response的URL和Request的URL是否一致就可以了,示例如下:
import urllib2
response = urllib2.urlopen('http://www.zhihu.cn')
isRedirected = response.geturl() == 'http://www.zhihu.cn'
如果不想自动重定向,可以自定义HTTPRedirectHandler类,示例如下:
import urllib2
class RedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(self, req, fp, code, msg, headers):
pass
def http_error_302(self, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(self, req, fp, code,
msg, headers)
result.status = code
result.newurl = result.geturl()
return result
opener = urllib2.build_opener(RedirectHandler)
opener.open('http://www.zhihu.cn')1.7 Proxy的设置
在做爬虫开发中,必不可少地会用到代理。urllib2默认会使用环境变量http_proxy来设置HTTP Proxy。但是我们一般不采用这种方式,而是使用ProxyHandler在程序中动态设置代理,示例代码如下:
import urllib2
proxy = urllib2.ProxyHandler({'http': '127.0.0.1:8087'})
opener = urllib2.build_opener([proxy,])
urllib2.install_opener(opener)
response = urllib2.urlopen('http://www.zhihu.com/')
print response.read()这里要注意的一个细节,使用urllib2.install_opener()会设置urllib2的全局opener,之后所有的HTTP访问都会使用这个代理。这样使用会很方便,但不能做更细粒度的控制,比如想在程序中使用两个不同的Proxy设置,这种场景在爬虫中很常见。比较好的做法是不使用install_opener去更改全局的设置,而只是直接调用opener的open方法代替全局的urlopen方法,修改如下:
import urllib2
proxy = urllib2.ProxyHandler({'http': '127.0.0.1:8087'})
opener = urllib2.build_opener(proxy,)
response = opener.open("http://www.zhihu.com/")
print response.read()
2. httplib/urllib实现
httplib模块是一个底层基础模块,可以看到建立HTTP请求的每一步,但是实现的功能比较少,正常情况下比较少用到。在Python爬虫开发中基本上用不到,所以在此只是进行一下知识普及。下面介绍一下常用的对象和函数:
创建HTTPConnection对象:
class httplib.HTTPConnection(host[, port[, strict[, timeout[, source_address]]]])。
发送请求:
HTTPConnection.request(method, url[, body[, headers]])。
获得响应:
HTTPConnection.getresponse()。
读取响应信息:
HTTPResponse.read([amt])。
获得指定头信息:
HTTPResponse.getheader(name[, default])。
获得响应头(header, value)元组的列表:
HTTPResponse.getheaders()。
获得底层socket文件描述符:
HTTPResponse.fileno()。
获得头内容:
HTTPResponse.msg。
获得头http版本:
HTTPResponse.version。
获得返回状态码:
HTTPResponse.status。
获得返回说明:
HTTPResponse.reason。
接下来演示一下GET请求和POST请求的发送,首先是GET请求的示例,如下所示:
import httplib
conn =None
try:
conn = httplib.HTTPConnection("www.zhihu.com")
conn.request("GET", "/")
response = conn.getresponse()
print response.status, response.reason
print '-' * 40
headers = response.getheaders()
for h in headers:
print h
print '-' * 40
print response.msg
except Exception,e:
print e
finally:
if conn:
conn.close()
POST请求的示例如下:
import httplib, urllib
conn = None
try:
params = urllib.urlencode({'name': 'qiye', 'age': 22})
headers = {"Content-type": "application/x-www-form-urlencoded"
, "Accept": "text/plain"}
conn = httplib.HTTPConnection("www.zhihu.com", 80, timeout=3)
conn.request("POST", "/login", params, headers)
response = conn.getresponse()
print response.getheaders() # 获取头信息
print response.status
print response.read()
except Exception, e:
print e
finally:
if conn:
conn.close()3. 更人性化的Requests
Python中Requests实现HTTP请求的方式,是本人极力推荐的,也是在Python爬虫开发中最为常用的方式。Requests实现HTTP请求非常简单,操作更加人性化。
Requests库是第三方模块,需要额外进行安装。Requests是一个开源库,源码位于:
GitHub: https://github.com/kennethreitz/requests
希望大家多多支持作者。
使用Requests库需要先进行安装,一般有两种安装方式:
使用pip进行安装,安装命令为:pip install requests,不过可能不是最新版。
直接到GitHub上下载Requests的源代码,下载链接为:
https://github.com/kennethreitz/requests/releases
将源代码压缩包进行解压,然后进入解压后的文件夹,运行setup.py文件即可。
如何验证Requests模块安装是否成功呢?在Python的shell中输入import requests,如果不报错,则是安装成功。如图3-5所示。
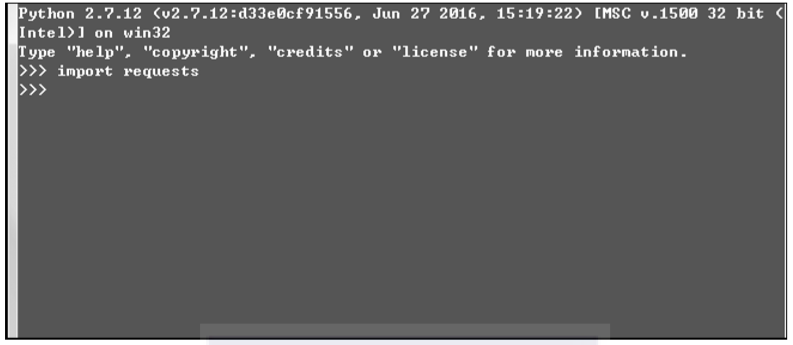
▲图3-5 验证Requests安装
3.1 首先还是实现一个完整的请求与响应模型
以GET请求为例,最简单的形式如下:
import requests
r = requests.get('http://www.baidu.com')
print r.content大家可以看到比urllib2实现方式的代码量少。接下来演示一下POST请求,同样是非常简短,更加具有Python风格。示例如下:
import requests
postdata={'key':'value'}
r = requests.post('http://www.xxxxxx.com/login',data=postdata)
print r.contentHTTP中的其他请求方式也可以用Requests来实现,示例如下:
r = requests.put('http://www.xxxxxx.com/put', data = {'key':'value'})
r = requests.delete('http://www.xxxxxx.com/delete')
r = requests.head('http://www.xxxxxx.com/get')
r = requests.options('http://www.xxxxxx.com/get')接着讲解一下稍微复杂的方式,大家肯定见过类似这样的URL:
http://zzk.cnblogs.com/s/blogpost?Keywords=blog:qiyeboy&pageindex=1
就是在网址后面紧跟着“?”,“?”后面还有参数。那么这样的GET请求该如何发送呢?肯定有人会说,直接将完整的URL带入即可,不过Requests还提供了其他方式,示例如下:
import requests
payload = {'Keywords': 'blog:qiyeboy','pageindex':1}
r = requests.get('http://zzk.cnblogs.com/s/blogpost', params=payload)
print r.url通过打印结果,我们看到最终的URL变成了:
http://zzk.cnblogs.com/s/blogpost?Keywords=blog:qiyeboy&pageindex=1
3.2 响应与编码
还是从代码入手,示例如下:
import requests
r = requests.get('http://www.baidu.com')
print 'content-->'+r.content
print 'text-->'+r.text
print 'encoding-->'+r.encoding
r.encoding='utf-8'
print 'new text-->'+r.text其中r.content返回的是字节形式,r.text返回的是文本形式,r.encoding返回的是根据HTTP头猜测的网页编码格式。
输出结果中:“text-->”之后的内容在控制台看到的是乱码,“encoding-->”之后的内容是ISO-8859-1(实际上的编码格式是UTF-8),由于Requests猜测编码错误,导致解析文本出现了乱码。Requests提供了解决方案,可以自行设置编码格式,r.encoding='utf-8'设置成UTF-8之后,“new text-->”的内容就不会出现乱码。
但是这种手动的方式略显笨拙,下面提供一种更加简便的方式:chardet,这是一个非常优秀的字符串/文件编码检测模块。安装方式如下:
pip install chardet安装完成后,使用chardet.detect()返回字典,其中confidence是检测精确度,encoding是编码形式。示例如下:
import requests
r = requests.get('http://www.baidu.com')
print chardet.detect(r.content)
r.encoding = chardet.detect(r.content)['encoding']
print r.text直接将chardet探测到的编码,赋给r.encoding实现解码,r.text输出就不会有乱码了。
除了上面那种直接获取全部响应的方式,还有一种流模式,示例如下:
import requests
r = requests.get('http://www.baidu.com',stream=True)
print r.raw.read(10)设置stream=True标志位,使响应以字节流方式进行读取,r.raw.read函数指定读取的字节数。
3.3 请求头headers处理
Requests对headers的处理和urllib2非常相似,在Requests的get函数中添加headers参数即可。示例如下:
import requests
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={'User-Agent':user_agent}
r = requests.get('http://www.baidu.com',headers=headers)
print r.content3.4 响应码code和响应头headers处理
获取响应码是使用Requests中的status_code字段,获取响应头使用Requests中的headers字段。示例如下:
import requests
r = requests.get('http://www.baidu.com')
if r.status_code == requests.codes.ok:
print r.status_code# 响应码
print r.headers# 响应头
print r.headers.get('content-type')# 推荐使用这种获取方式,获取其中的某个字段
print r.headers['content-type']# 不推荐使用这种获取方式
else:
r.raise_for_status()
上述程序中,r.headers包含所有的响应头信息,可以通过get函数获取其中的某一个字段,也可以通过字典引用的方式获取字典值,但是不推荐,因为如果字段中没有这个字段,第二种方式会抛出异常,第一种方式会返回None。
r.raise_for_status()是用来主动地产生一个异常,当响应码是4XX或5XX时,raise_for_status()函数会抛出异常,而响应码为200时,raise_for_status()函数返回None。
3.5 Cookie处理
如果响应中包含Cookie的值,可以如下方式获取Cookie字段的值,示例如下:
import requests
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={'User-Agent':user_agent}
r = requests.get('http://www.baidu.com',headers=headers)
# 遍历出所有的cookie字段的值
for cookie in r.cookies.keys():
print cookie+':'+r.cookies.get(cookie)如果想自定义Cookie值发送出去,可以使用以下方式,示例如下:
import requests
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={'User-Agent':user_agent}
cookies = dict(name='qiye',age='10')
r = requests.get('http://www.baidu.com',headers=headers,cookies=cookies)
print r.text还有一种更加高级,且能自动处理Cookie的方式,有时候我们不需要关心Cookie值是多少,只是希望每次访问的时候,程序自动把Cookie的值带上,像浏览器一样。Requests提供了一个session的概念,在连续访问网页,处理登录跳转时特别方便,不需要关注具体细节。使用方法示例如下:
import Requests
oginUrl = 'http://www.xxxxxxx.com/login'
s = requests.Session()
#首先访问登录界面,作为游客,服务器会先分配一个cookie
r = s.get(loginUrl,allow_redirects=True)
datas={'name':'qiye','passwd':'qiye'}
#向登录链接发送post请求,验证成功,游客权限转为会员权限
r = s.post(loginUrl, data=datas,allow_redirects= True)
print r.text上面的这段程序,其实是正式做Python开发中遇到的问题,如果没有第一步访问登录的页面,而是直接向登录链接发送Post请求,系统会把你当做非法用户,因为访问登录界面时会分配一个Cookie,需要将这个Cookie在发送Post请求时带上,这种使用Session函数处理Cookie的方式之后会很常用。
3.6 重定向与历史信息
处理重定向只是需要设置一下allow_redirects字段即可,例如:
r=requests.get('http://www.baidu.com',allow_redirects=True)
将allow_redirects设置为True,则是允许重定向;设置为False,则是禁止重定向。如果是允许重定向,可以通过r.history字段查看历史信息,即访问成功之前的所有请求跳转信息。示例如下:
import requests
r = requests.get('http://github.com')
print r.url
print r.status_code
print r.history打印结果如下:
https://github.com/
200
(<Response [301]>,)上面的示例代码显示的效果是访问GitHub网址时,会将所有的HTTP请求全部重定向为HTTPS。
3.7 超时设置
超时选项是通过参数timeout来进行设置的,示例如下:
requests.get('http://github.com', timeout=2)3.8 代理设置
使用代理Proxy,你可以为任意请求方法通过设置proxies参数来配置单个请求:
import requests
proxies = {
"http": "http://0.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)也可以通过环境变量HTTP_PROXY和HTTPS_PROXY?来配置代理,但是在爬虫开发中不常用。你的代理需要使用HTTP Basic Auth,可以使用http://user:password@host/语法:
proxies = {
"http": "http://user:[email protected]:3128/",
}03 小结
本文主要讲解了网络爬虫的结构和应用,以及Python实现HTTP请求的几种方法。希望大家对本文中的网络爬虫工作流程和Requests实现HTTP请求的方式重点吸收消化。
关于作者:范传辉,资深网虫,Python开发者,参与开发了多项网络应用,在实际开发中积累了丰富的实战经验,并善于总结,贡献了多篇技术文章广受好评。研究兴趣是网络安全、爬虫技术、数据分析、驱动开发等技术。
本文摘编自《Python爬虫开发与项目实战》,经出版方授权发布。
延伸阅读《Python爬虫开发与项目实战》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:零基础学习爬虫技术,从Python和Web前端基础开始讲起,由浅入深,包含大量案例,实用性强。

「大数据」内容合伙人之「鉴书小分队」上线啦!
最近,你都在读什么书?有哪些心得体会想要跟大家分享?
数据叔最近搞了个大事——联合优质图书出版商机械工业出版社华章公司发起鉴书活动。
简单说就是:你可以免费读新书,你可以免费读新书的同时,顺手码一篇读书笔记就行。详情请在大数据公众号后台对话框回复合伙人查看。
据统计,99%的大咖都完成了这个神操作
▼
更多精彩
在公众号后台对话框输入以下关键词
查看更多优质内容!
PPT | 报告 | 读书 | 书单 | 干货
大数据 | 揭秘 | Python | 可视化
人工智能 | 机器学习 | 深度学习 | 神经网络
AI | 1024 | 段子 | 区块链 | 数学
猜你想看
Q: 你开始爬了吗?
欢迎留言与大家分享
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:[email protected]
更多精彩,请在后台点击“历史文章”查看

