前言
InfluxDB是一个时序性数据库,详细资料如下
http://liubin.org/blog/2016/02/18/tsdb-intro/
下载和安装
LZ从官网下载的是influxdb-1.2.4_windows_amd64这个版本,这种数据库不需要安装,解压后配置完毕直接使用,解压后的文件为
influx.exe---->influxdb 命令行客户端
influxd.exe---->influxdb服务器
influxdb.conf---->配置文件,指定对应数据存储文件的位置、日志信息、连接数量、连接时间等等功能的具体配置
主要需要修改的内容如下:
meta部分
data部分
retention部分
shard-percreation部分
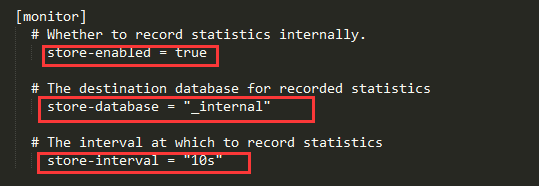
monitor部分
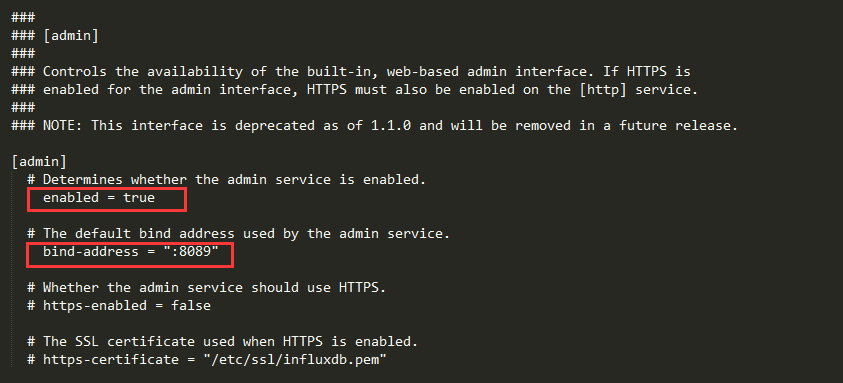
admin部分
bind-address端口视服务器端口使用情况而定,这个端口是用来通过浏览器访问的
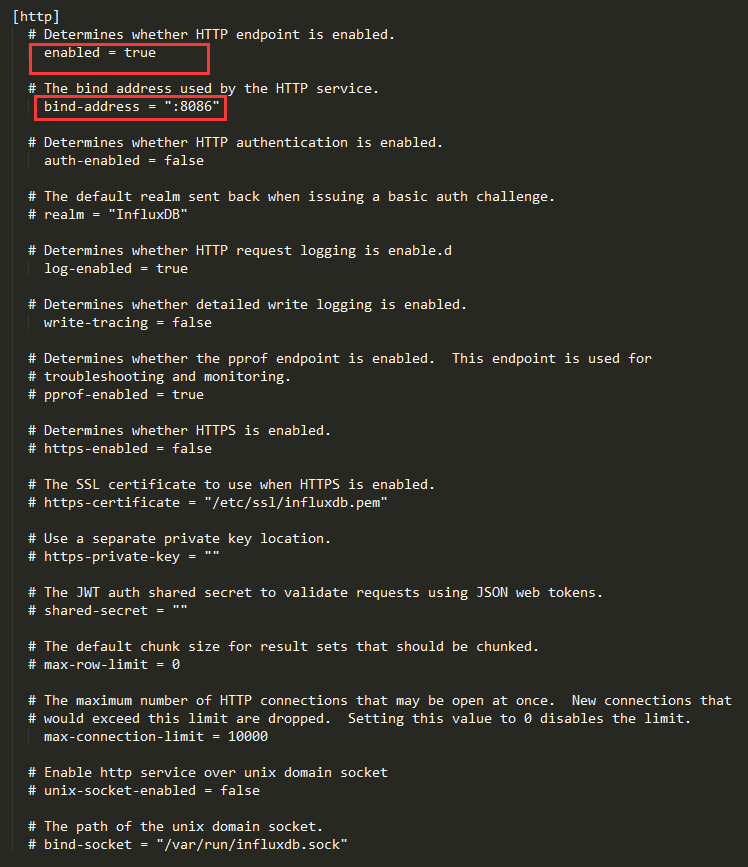
http部分
这个端口是用来通过程序来访问的,各种参数的具体含义详见
https://github.com/mike-zhang/mikeBlogEssays/blob/master/2017/20170206_InfluxDB%E5%AE%89%E8%A3%85%E5%8F%8A%E9%85%8D%E7%BD%AE.md
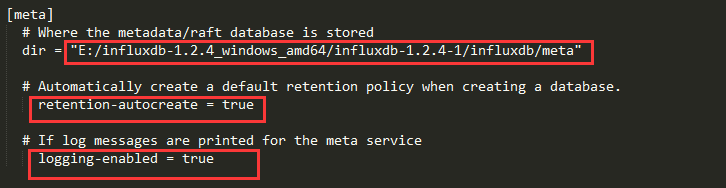
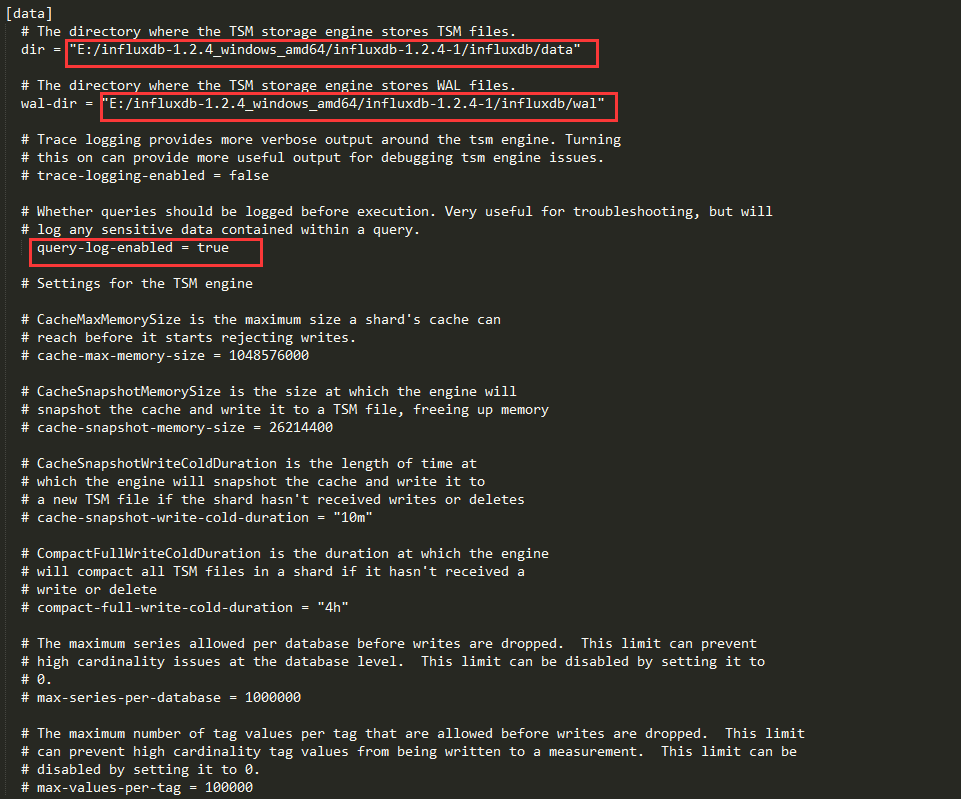

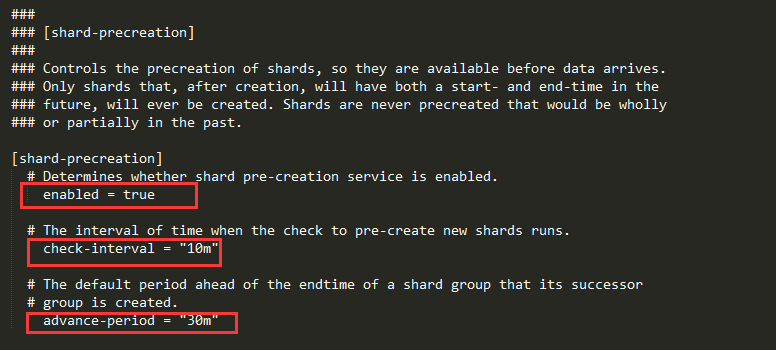
启动
通过cmd打开window的命令窗口,进入到influxdb的放置目录,执行命令:influxd.exe -config influxdb.conf即可开启influxdb服务,同时按照上面配置文件产生相应的文件
通过http://127.0.0.1:8089即可实现图形化的访问,其中8087是influxdb.conf文件中admin部分bind-address所指定的,在浏览器中输入这个地址即可实现图形化的访问
http请求的方式为http://178.24.1.3:8086,其中178.24.1.3为当前window机器的IP地址,8086为influxdb.conf文件中http部分bind-address所指定的,这种方式是供程序访问的地址;
另外,还可以直接打开influx.exe,通过influxDB提供的命令来查询数据库中的内容;
备份
备份数据库时,按照influxdb.conf文件中meta、data部分指定的meta、data、wal目录,将这三个目录备份即可;
基础概念
InfluxDB教程
https://www.linuxdaxue.com/influxdb-study-series-manual.html
Java持久层框架
官方提供目前只提供了通过http api访问数据库的方式,我们用GitHub上的开源框架与数据库进行交互,项目地址为:https://github.com/influxdata/influxdb-java,主要实现类如下
InfluxDBFactory
是一个工厂类,可以通过如下方式返回一个InfluxDB的实例
InfluxDB influxDB = InfluxDBFactory.connect("http://172.17.0.2:8086", "111", "111");
InfluxDBImpl
实现了InfluxDB接口,提供了对数据库操作的基本方法,如新建数据库,删除数据库,插入数据,进行查询
Point
相当于关系型数据库中的一行数据,因为此类数据库一行数据在图中一般显示为一个点,故为Point,可以此类添加行数据,如tag(索引列)field(普通列)
Query
通过要执行的SQL和数据库名构造Query对象,作为参数传递到InfluxDBImpl类的查询方法中,即可返回一个QueryResult对象,里面封装了查询生成的数据
QueryResult
这个类比较复杂
public class QueryResult {
private List<Result> results;
private String error;
public static class Result {
private List<Series> series;
private String error;
}
public static class Series {
private String name;
private Map<String, String> tags;
private List<String> columns;
private List<List<Object>> values;
}
}
其中Result和Series为QueryResult的内部类,嵌套比较深,取数据比较麻烦,取数据的方法大都类似于
Object obj = queryResult.getResults().get(0).getSeries().get(0).getValues().get(0).get(1);
这种方法
InfluxDBResultMapper
可以通过如下方式将查询结构映射到一个Bean中
InfluxDBResultMapper resultMapper = new InfluxDBResultMapper();
List<NewBean> cpuList = resultMapper.toPOJO(queryResult, NewBean.class);
其中NewBean是一个POJO类
注意事项
通过StringBuilder拼接SQL语句,进行查询,注意不能单独查询tag列,必须有一个field列
