一:Pandas操作Excel
1.1: 创建/读取excel文件
-
读取excel
pd.read_excel(filepath) -
读取指定标题行
pd.read_excel(filepath,header=2) -
读取设置索引列
pd.read_excel(filepath,index_col=col_name) -
设置索引列
df.set_index(col_name)或者df=df.set_index('ID',inplace=True) -
保存excel
df.to_excel(filepath) -
显示内容
df.[shape|columns|head()|tail()|head(3)|tail(5)]
1.1.1: 创建excel文件
import pandas as pd
dataDic={'ID':[1,2,3,4,5],'Name':['Tim','Tom','Tony','Nick','Gala']}
df = pd.DataFrame(dataDic)
df.to_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output.xlsx')
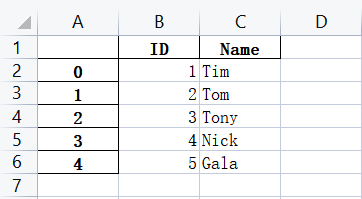
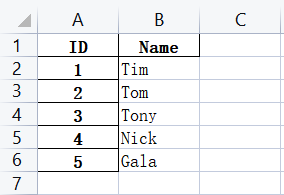
前面A列的0-4是索引,如果把ID列当成索引列,使用set_index:
import pandas as pd
dataDic={'ID':[1,2,3,4,5],'Name':['Tim','Tom','Tony','Nick','Gala']}
df = pd.DataFrame(dataDic)
df = df.set_index('ID')
df.to_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output.xlsx')
1.1.2: 读取excel文件
import pandas as pd
people = pd.read_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output.xlsx')
print (people.shape) # 总用有多少行,多少列
print (people.columns) # 显示所有列名
print (people.head()) # 显示前面几行,默认是5行
print (people.head(3)) # 显示前面3行
print ('================')
print (people.tail(3)) # 显示末尾3行
如果标题不是在第一行,需要选择指定行作为标题行: pd.read_excel(path,header=2)
如果前两行都是空的,则不用header=2,自动会跳过空行
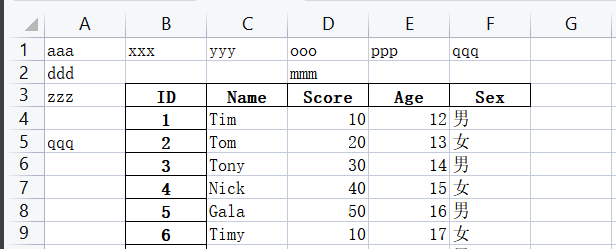
import pandas as pd
people = pd.read_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output.xlsx',header=2)
print (people.columns) # 显示所有列名
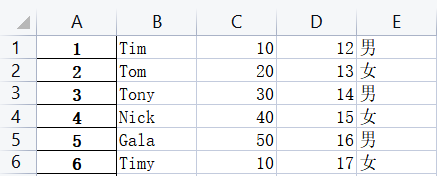
如果首行不是标题,使用header=None忽略第一行当作标题
如果需要手动添加标题: people.columns=['ID','Name','Score','Age','Sex']
如果要去处自动生成的索引列,使用已有的ID列作为索引列:
方法1
people.set_index('ID',inplace=True)
方法2people = people.set_index('ID')
import pandas as pd
people = pd.read_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output.xlsx',header=None)
people.columns=['ID','Name','Score','Age','Sex']
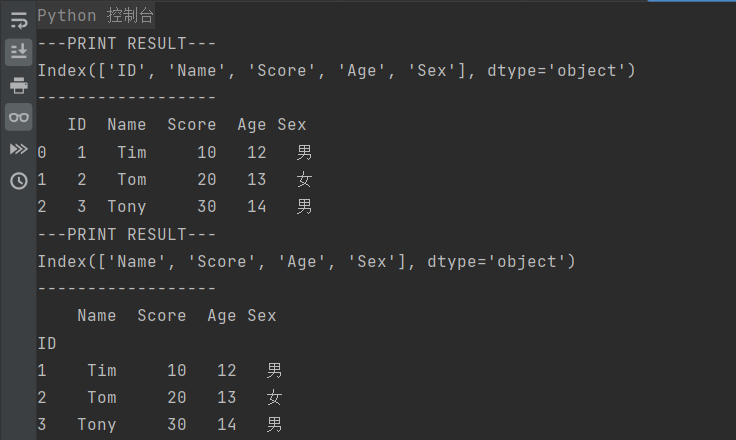
print ('---PRINT RESULT---')
print (people.columns) # 显示所有列名
print ('------------------')
print (people.head(3)) # 显示前面3行
# 显示结果
---PRINT RESULT---
Index(['ID', 'Name', 'Score', 'Age', 'Sex'], dtype='object')
------------------
ID Name Score Age Sex
0 1 Tim 10 12 男
1 2 Tom 20 13 女
# 如果要去掉前面生成的索引列
import pandas as pd
people = pd.read_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output.xlsx',header=None)
people.columns=['ID','Name','Score','Age','Sex']
people.set_index('ID',inplace=True) # 方法1
# people = people.set_index('ID') # 方法2
people.to_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output2.xlsx')
print ('---PRINT RESULT---')
print (people.columns) # 显示所有列名
print ('------------------')
print (people.head(3)) # 显示前面3行
---PRINT RESULT---
Index(['Name', 'Score', 'Age', 'Sex'], dtype='object')
------------------
Name Score Age Sex
ID
1 Tim 10 12 男
2 Tom 20 13 女
3 Tony 30 14 男
读取文件的时候,可以指定索引列,这样就不会多生成一列了.
import pandas as pd
people = pd.read_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output2.xlsx')
print ('---PRINT RESULT---')
print (people.columns) # 显示所有列名
print ('------------------')
print (people.head(3)) # 显示前面3行
people = pd.read_excel('G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\output2.xlsx',index_col='ID')
print ('---PRINT RESULT---')
print (people.columns) # 显示所有列名
print ('------------------')
print (people.head(3)) # 显示前面3行
1.2: 基础操作Excel
1.2.1: 字典,列表序列化
import pandas as pd
d={'x':100,'y':200,'z':300}
l1=[100,200,300]
l2=['x','y','z']
s1 = pd.Series(d)
print(s1)
s2 = pd.Series(l1,index=l2)
print(s2)
# 返回结果
x 100
y 200
z 300
dtype: int64
x 100
y 200
z 300
dtype: int64
1.2.2: 数据生成DataFrame
import pandas as pd
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([10,20,30],index=[1,2,3],name='B')
s3 = pd.Series([100,200,300,400],index=[1,2,3,4],name='C')
print ('#返回结果')
df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3})
print (df)
print ('---------------')
df = pd.DataFrame([s1,s2,s3])
print (df)
#返回结果
A B C
1 1.0 10.0 100
2 2.0 20.0 200
3 3.0 30.0 300
4 NaN NaN 400
---------------
1 2 3 4
A 1.0 2.0 3.0 NaN
B 10.0 20.0 30.0 NaN
C 100.0 200.0 300.0 400.0
1.2.3: 自动填充
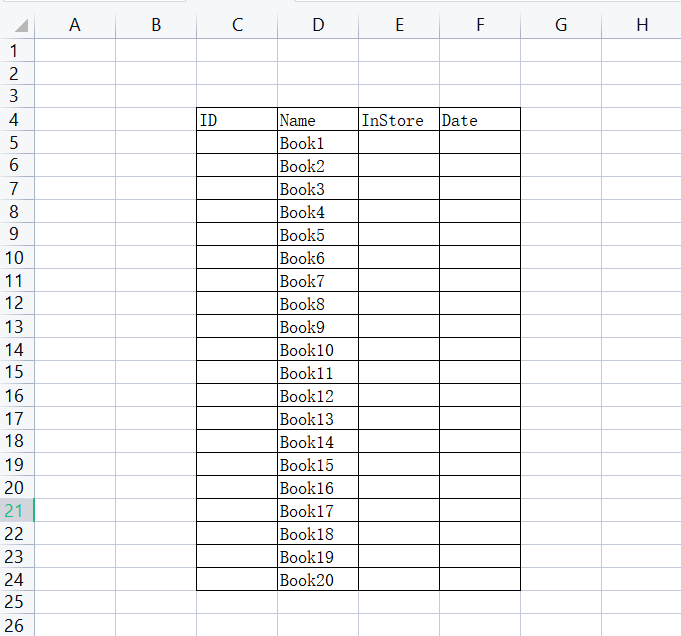
- 指定某行列值
df[colname].at[i]=value - ID列递增填充
books['ID'].at[i]=i+1 - InStore[Yes|No]循环填充
books['InStore'].at[i]='Yes' if i%2 == 0 else 'No' - Date时间按天递增填充
books['Date'].at[i]=start + timedelta(days=i)
import pandas as pd
from datetime import date,timedelta
def add_month(d,md):
"""
:param d: 开始日期
:param md: 增加的月份数
:return: 增加月份后的日期
"""
yd = md // 12
m = d.month + md % 12
if m != 12:
yd += m // 12
m = m % 12
return date(d.year + yd,m,d.day)
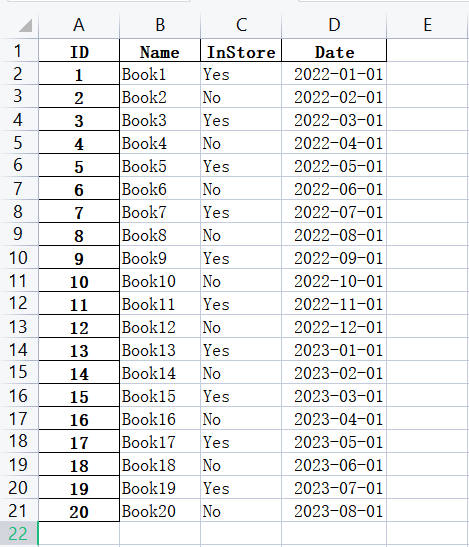
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx',skiprows=3,usecols="C:F",index_col=None,dtype={'ID':str,'InStore':str,'Date':str})
start = date(2022,1,1)
for i in books.index:
books['ID'].at[i]=i+1
books['InStore'].at[i]='Yes' if i%2 == 0 else 'No'
# books['Date'].at[i]=start + timedelta(days=i) ## 按照日期递增填充
# books['Date'].at[i]=date(start.year+i,start.month,start.day) ## 按照年份递增填充
books['Date'].at[i]=add_month(start,i) ## 按照月份递增填充
books.set_index('ID',inplace=True)
books.to_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books_fix.xlsx')
print (books)
1.2.4: 修改单元格内容
- 修改单元格内容
df.at[i,col_name] = value - Series级更新内容:
books['Price'] = books['ListPrice']*books['Discount'] - 单元格级更新内容:
books['Price'].at[i] = books['ListPrice'].at[i] * books['Discount'].at[i]
import pandas as pd
from datetime import date,timedelta
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx',skiprows=3,usecols="C:F",index_col=None,dtype={'ID':str,'InStore':str,'Date':str})
start = date(2022,1,1)
for i in books.index:
books.at[i,'ID']=i+1
books.at[i,'InStore']='Yes' if i%2 == 0 else 'No'
books.at[i,'Date']=start + timedelta(days=i)
books.set_index('ID',inplace=True)
books.to_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books_fix.xlsx')
print (books)
1.2.5: 函数填充,计算列
import pandas as pd
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx')
books['Price'] = books['ListPrice']*books['Discount']
print (books)
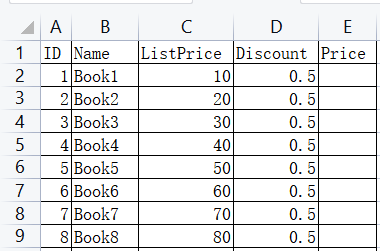
# 返回结果
ID Name ListPrice Discount Price
0 1 Book1 10 0.5 5.0
1 2 Book2 20 0.5 10.0
2 3 Book3 30 0.5 15.0
3 4 Book4 40 0.5 20.0
4 5 Book5 50 0.5 25.0
5 6 Book6 60 0.5 30.0
6 7 Book7 70 0.5 35.0
7 8 Book8 80 0.5 40.0
# 只需要算出部分列的价格
import pandas as pd
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx')
for i in range(5,10):
books['Price'].at[i] = books['ListPrice'].at[i] * books['Discount'].at[i]
print (books)
# 返回结果
ID Name ListPrice Discount Price
0 1 Book1 10 0.5 0
1 2 Book2 20 0.5 0
2 3 Book3 30 0.5 0
3 4 Book4 40 0.5 0
4 5 Book5 50 0.5 0
5 6 Book6 60 0.5 30
6 7 Book7 70 0.5 35
7 8 Book8 80 0.5 40
8 9 Book9 90 0.5 45
9 10 Book10 100 0.5 50
10 11 Book11 110 0.5 0
11 12 Book12 120 0.5 0
- 通过函数计算列值
import pandas as pd
def add_2(x):
return x+2
# 把ListPrice列价格+2元
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx',index_col='ID')
books['ListPrice'] = books['ListPrice'].apply(add_2)
# books['ListPrice'] = books['ListPrice'].apply(lambda x:x+2) # 用lambda表达式替换函数
print (books)
# 返回结果
Name ListPrice Discount Price
ID
1 Book1 12 0.5 NaN
2 Book2 22 0.5 NaN
3 Book3 32 0.5 NaN
4 Book4 42 0.5 NaN
5 Book5 52 0.5 NaN
6 Book6 62 0.5 NaN
7 Book7 72 0.5 NaN
8 Book8 82 0.5 NaN
1.2.6: 排序,多重排序
- 单列排序
books.sort_values(by='Price',inplace=True,ascending=False) - 多列排序
books.sort_values(by=['Worthy','Price'],inplace=True,ascending=[True,False])
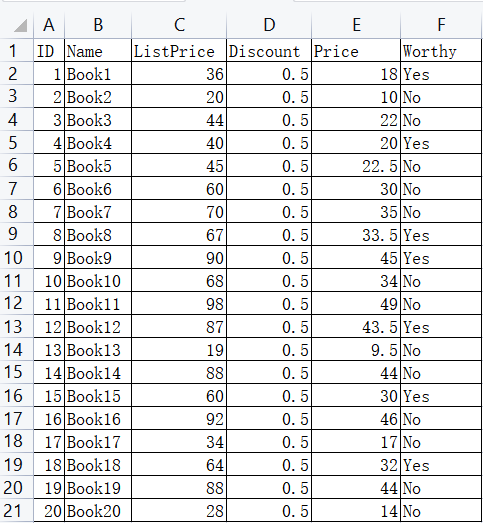
# 单列排序
import pandas as pd
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx',index_col='ID')
# 按照Price倒序 [inplace=True在当前列排序,不回生成新的列排序]
books.sort_values(by='Price',inplace=True,ascending=False)
print (books)
# 返回结果
Name ListPrice Discount Price Worthy
ID
11 Book11 98 0.5 49.0 No
16 Book16 92 0.5 46.0 No
9 Book9 90 0.5 45.0 Yes
19 Book19 88 0.5 44.0 No
14 Book14 88 0.5 44.0 No
12 Book12 87 0.5 43.5 Yes
7 Book7 70 0.5 35.0 No
10 Book10 68 0.5 34.0 No
8 Book8 67 0.5 33.5 Yes
...
# 多列排序
import pandas as pd
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx',index_col='ID')
books.sort_values(by=['Worthy','Price'],inplace=True,ascending=[True,False])
print (books)
# 返回结果
Name ListPrice Discount Price Worthy
ID
11 Book11 98 0.5 49.0 No
16 Book16 92 0.5 46.0 No
14 Book14 88 0.5 44.0 No
19 Book19 88 0.5 44.0 No
7 Book7 70 0.5 35.0 No
10 Book10 68 0.5 34.0 No
6 Book6 60 0.5 30.0 No
5 Book5 45 0.5 22.5 No
3 Book3 44 0.5 22.0 No
17 Book17 34 0.5 17.0 No
20 Book20 28 0.5 14.0 No
2 Book2 20 0.5 10.0 No
13 Book13 19 0.5 9.5 No
9 Book9 90 0.5 45.0 Yes
12 Book12 87 0.5 43.5 Yes
8 Book8 67 0.5 33.5 Yes
18 Book18 64 0.5 32.0 Yes
15 Book15 60 0.5 30.0 Yes
4 Book4 40 0.5 20.0 Yes
1 Book1 36 0.5 18.0 Yes
1.2.7: 数据筛选,过滤
-
筛选
df.loc[df[colname].apply(func)]或者df.loc[df.colname.apply(func)] -
单列筛选
books.loc[books.Price.apply(price_40_to_60)] -
多列筛选
books.loc[books.Price.apply(price_40_to_60)].loc[books.Discount.apply(discount_3_to_7)]
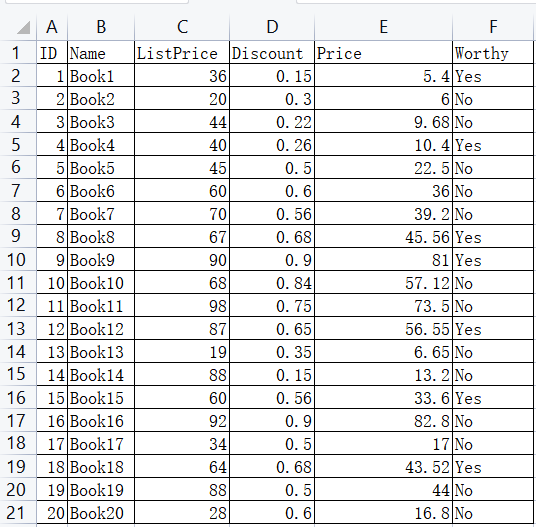
import pandas as pd
def price_40_to_60(a):
"""
:param a: 价格
:return: 价格在40-60之间
"""
return 40<=a<60
def discount_3_to_7(b):
"""
:param b: 折扣
:return: 折扣在3-7折之间
"""
return 0.3<=b<0.7
books = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\books.xlsx',index_col='ID')
# 下面两种筛选格式
# books = books.loc[books['Price'].apply(price_40_to_60)].loc[books['Discount'].apply(discount_3_to_7)]
# books = books.loc[books.Price.apply(price_40_to_60)].loc[books.Discount.apply(discount_3_to_7)]
# 使用lambda表达式替换函数
books = books.loc[books.Price.apply(lambda a:40<=a<60)].loc[books.Discount.apply(lambda a:0.3<=a<0.7)]
books.sort_values(by=['Worthy','Price'],inplace=True,ascending=[True,False])
print (books)
# 返回结果
Name ListPrice Discount Price Worthy
ID
19 Book19 88 0.50 44.00 No
12 Book12 87 0.65 56.55 Yes
8 Book8 67 0.68 45.56 Yes
18 Book18 64 0.68 43.52 Yes
1.3: 绘制图表
1.3.1: 柱状图
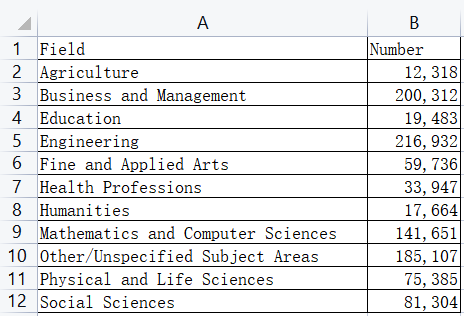
import pandas as pd
import matplotlib.pyplot as plt
students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx')
print (students)
students.sort_values(by='Number',inplace=True,ascending=False) # 排序 inplace=True 表示覆盖原对象,不生成新对象
# students.plot.bar(x='Field',y='Number',color='orange',title='International Students by Field') # 使用pandas绘图
# 下面使用pyplot绘图
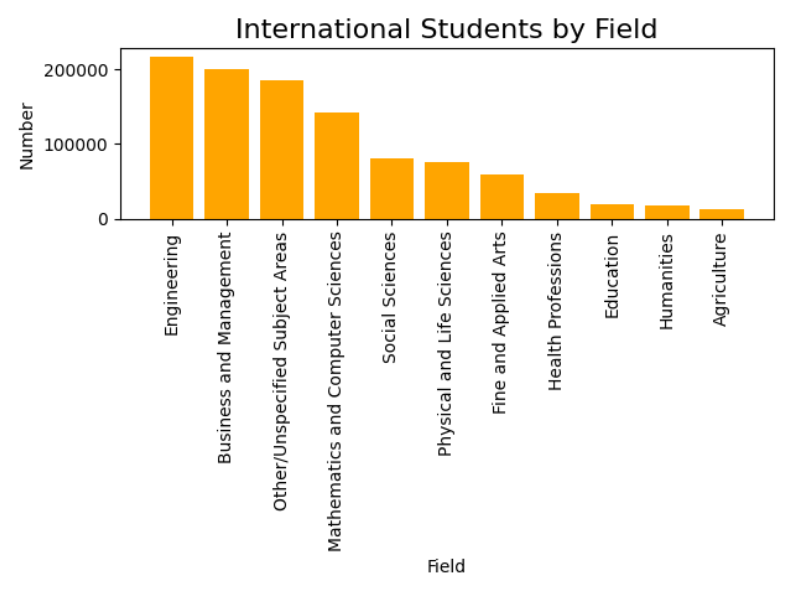
plt.bar(students.Field,students.Number,color='orange') # 数据传给plt
plt.xticks(students.Field,rotation='90') # X轴标签转90度
plt.xlabel('Field') # X轴名称
plt.ylabel('Number') # Y轴名称
plt.title('International Students by Field',fontsize=16) # 标题
plt.tight_layout() # 紧凑型布局
plt.show() # 展示
1.3.2: 分组柱图深度优化
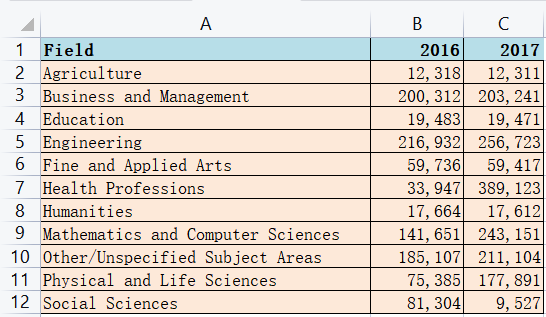
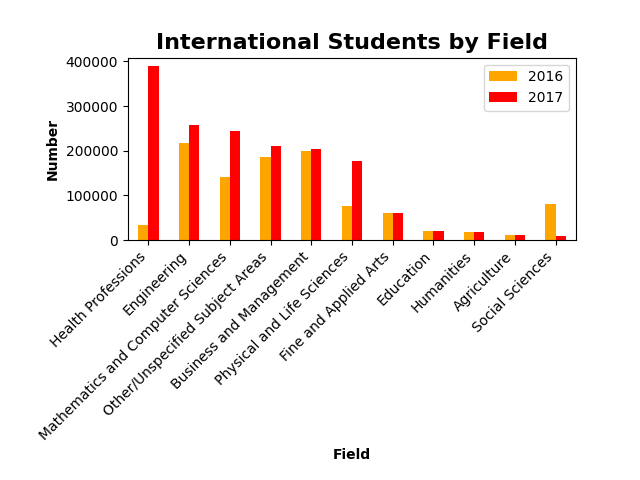
import pandas as pd
import matplotlib.pyplot as plt
students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx')
print (students)
students.sort_values(by=2017,inplace=True,ascending=False)
students.plot.bar(x='Field',y=[2016,2017],color=['orange','red'])
plt.title('International Students by Field',fontsize=16,fontweight='bold')
plt.xlabel('Field',fontweight='bold')
plt.ylabel('Number',fontweight='bold')
ax = plt.gca() # 轴
ax.set_xticklabels(students['Field'],rotation=45,ha='right') # rotation旋转角度,ha x轴标签对齐方式
f = plt.gcf() # 图形
f.subplots_adjust(left=0.2,bottom=0.50)
# plt.tight_layout()
plt.show() # 展示
1.3.3: 叠加水平柱状图
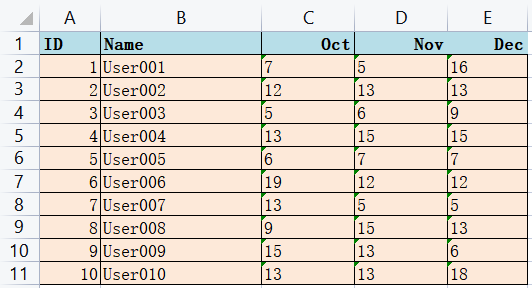
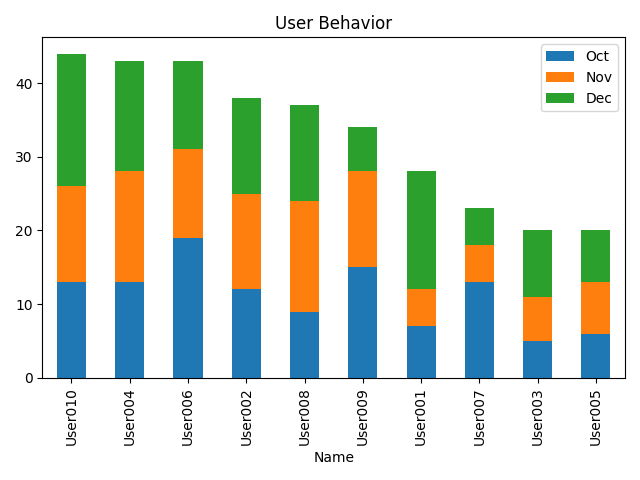
import pandas as pd
import matplotlib.pyplot as plt
students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx')
students['Total']=students['Oct']+students['Nov']+students['Dec']
students.sort_values(by='Total',inplace=True,ascending=False)
print (students)
students.plot.bar(x='Name',y=['Oct','Nov','Dec'],stacked=True,title='User Behavior') # plot.bar 是纵向展示
plt.tight_layout()
plt.show()
# 水平展示
students.sort_values(by='Total',inplace=True)
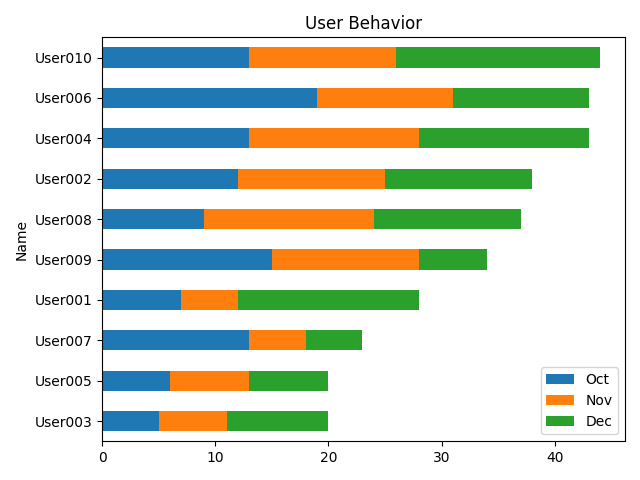
students.plot.barh(x='Name',y=['Oct','Nov','Dec'],stacked=True,title='User Behavior') # plot.barh 是水平展示
plt.tight_layout()
plt.show()
1.3.4: 饼图
import pandas as pd
import matplotlib.pyplot as plt
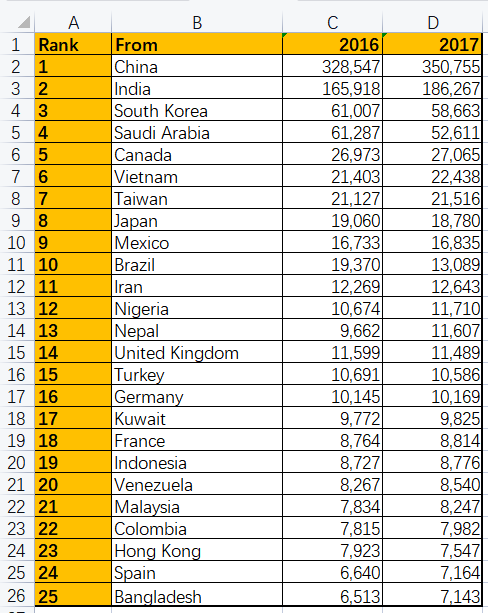
students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx',index_col='From')
print (students)
# 饼图顺时针调整 方法1:sort_values(ascending=True) 方法2:counterclock=False
# 饼图起始角度从正上方中间开始: startangle=-270
# students['2017'].sort_values(ascending=True).plot.pie(fontsize=8,startangle=-270)
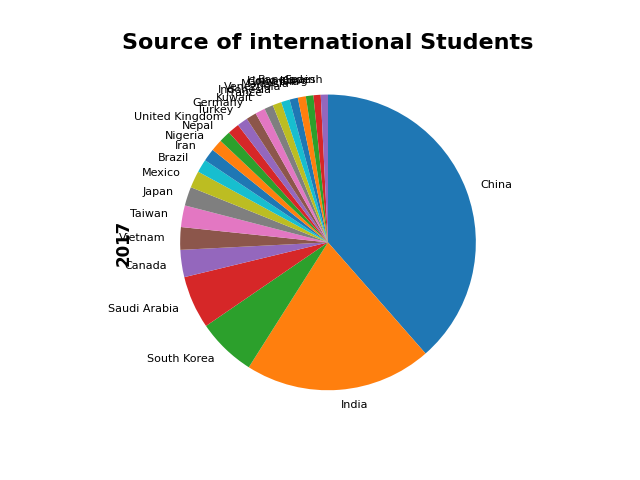
students['2017'].plot.pie(fontsize=8,counterclock=False,startangle=-270)
plt.title('Source of international Students',fontsize=16,fontweight='bold')
plt.ylabel('2017',fontsize=12,fontweight='bold')
plt.show()
1.3.5: 折线图,叠加区域图
import pandas as pd
import matplotlib.pyplot as plt
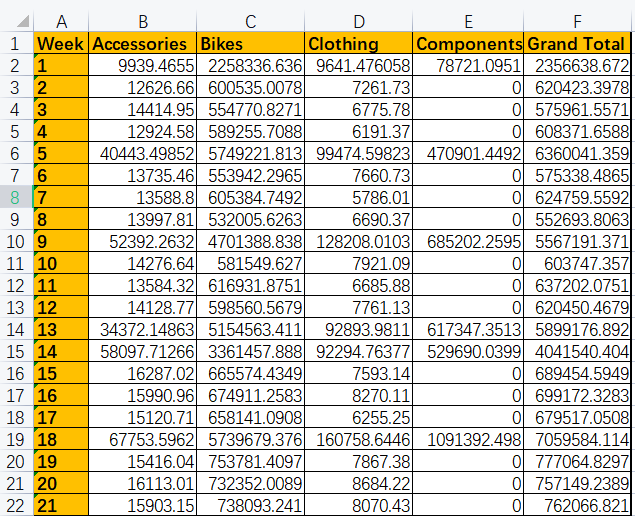
weeks = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\orders.xlsx',index_col='Week')
print (weeks)
# weeks.plot(y=['Accessories','Bikes','Clothing','Components']) # 折线图
# weeks.plot.bar(y=['Accessories','Bikes','Clothing','Components'],stacked=True) # 叠加柱状图
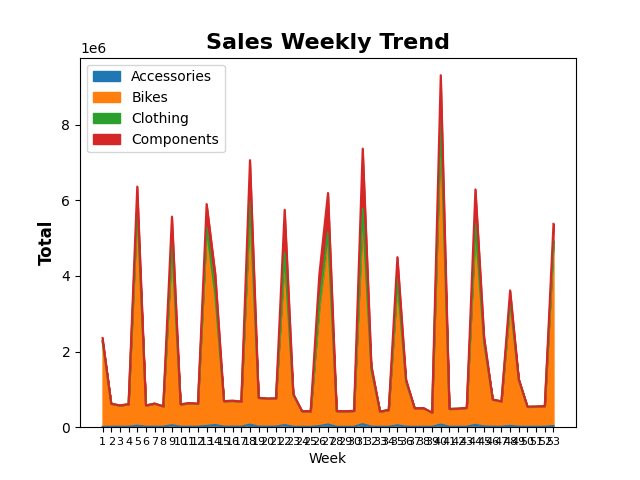
weeks.plot.area(y=['Accessories','Bikes','Clothing','Components']) # 叠加区域图
plt.title('Sales Weekly Trend',fontsize=16,fontweight='bold')
plt.ylabel('Total',fontsize=12,fontweight='bold')
plt.xticks(weeks.index,fontsize=8)
plt.show()
1.3.6: 散点图,直方图,密度图
- 解决中文显示为方块问题:
plt.rcParams['font.sans-serif'] = ['SimHei'] - 解决负号'-'显示为方块问题:
plt.rcParams['axes.unicode_minus'] = False - 列数太多不显示,可设置显示列数:
pd.options.display.max_columns = 100
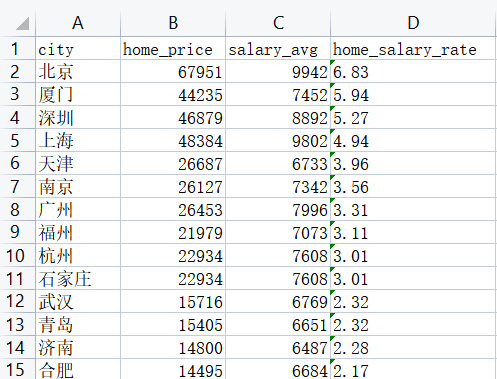
# 散点图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体,解决中文显示为方块问题
plt.rcParams['axes.unicode_minus'] = False # 解决保存图象中负号'-'显示为方块问题
pd.options.display.max_columns = 100 # 显示最大的列数
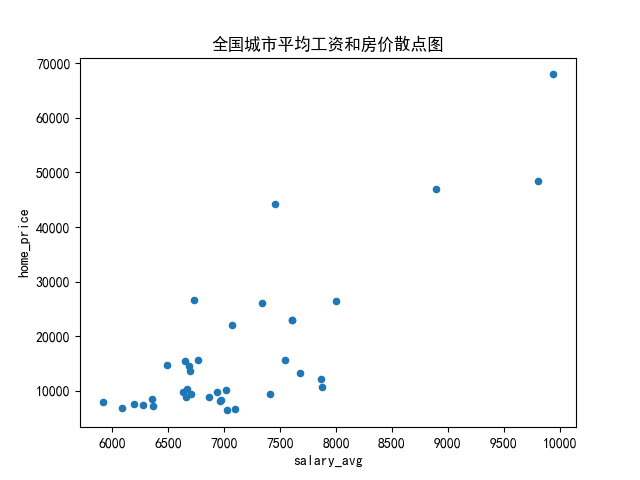
homes = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\home_data.xlsx')
print (homes)
homes.plot.scatter(x='salary_avg',y='home_price')
plt.title('全国城市平均工资和房价散点图')
plt.show()
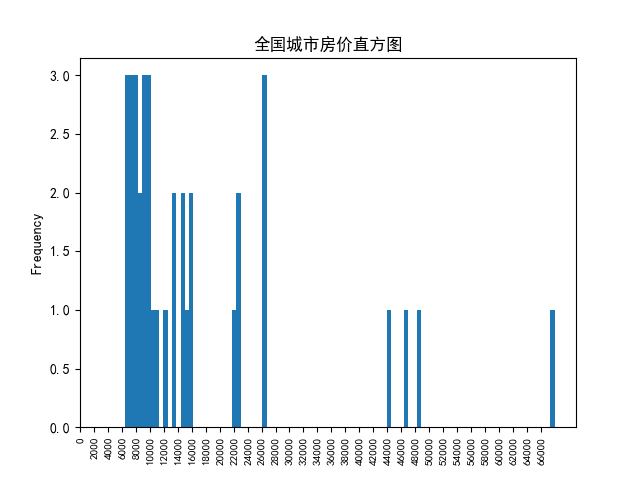
# 直方图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体,解决中文显示为方块问题
plt.rcParams['axes.unicode_minus'] = False # 解决保存图象中负号'-'显示为方块问题
pd.options.display.max_columns = 100 # 显示最大的列数
homes = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\home_data.xlsx')
print (homes)
homes.home_price.plot.hist(bins=100) # 计算home_price列直方图,bins=100设置桶数(精度)
plt.xticks(range(0,max(homes.home_price),2000),fontsize=8,rotation=90) # 设置x轴刻度区间,字体大小,刻度名旋转角度
plt.title('全国城市房价直方图')
plt.show()
# 密度图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体,解决中文显示为方块问题
plt.rcParams['axes.unicode_minus'] = False # 解决保存图象中负号'-'显示为方块问题
homes = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\home_data.xlsx')
print (homes)
homes.home_price.plot.kde() # plot.kde 密度图
plt.xticks(range(0,max(homes.home_price),5000),fontsize=8,rotation=90) # 设置x轴刻度区间,字体大小,刻度名旋转角度
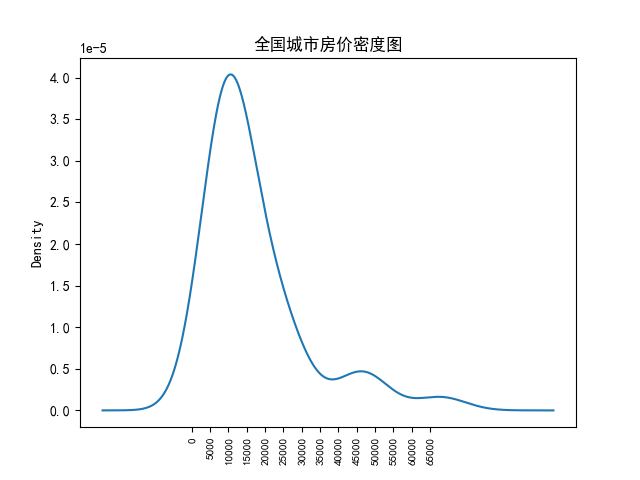
plt.title('全国城市房价密度图')
plt.show()
# 两两相关性(表格中每两列之间的相关性)
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体,解决中文显示为方块问题
plt.rcParams['axes.unicode_minus'] = False # 解决保存图象中负号'-'显示为方块问题
homes = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\home_data.xlsx')
print (homes.corr()) # 两两之间相关性
home_price salary_avg home_salary_rate
home_price 1.000000 0.816346 0.980898
salary_avg 0.816346 1.000000 0.721629
home_salary_rate 0.980898 0.721629 1.000000
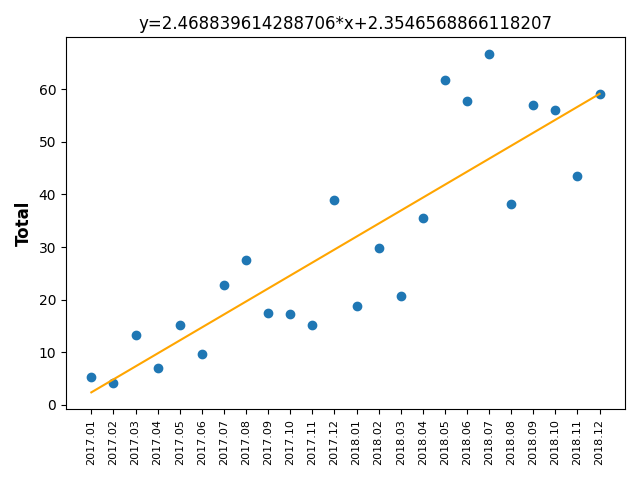
1.3.7: 线性回归,数据预测
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import linregress # 线性回归
sales = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Sales.xlsx',dtype={'Month':str})
print (sales)
slope,intercept,r,p,std_err = linregress(sales.index,sales.Revenue)
exp = sales.index * slope + intercept
# plt.bar(sales.index,sales.Revenue)
plt.scatter(sales.index,sales.Revenue)
plt.plot(sales.index,exp,color='orange')
plt.title(f'y={slope}*x+{intercept}')
plt.xticks(sales.index,sales.Month,rotation=90,fontsize=8)
plt.ylabel('Total',fontsize=12,fontweight='bold')
plt.tight_layout()
plt.show()
1.4: 进阶操作Excel
1.4.1: 多表联合
- 读取指定sheet:
students = pd.read_excel(file_path,sheet_name='students') - 两个sheet使用merge关联(inner join):
students.merge(scores,on='ID') - 两个sheet使用merge左右关联(left|right join):
students.merge(scores,how='left|right',on='ID') - 两个sheet关联列名不一样:
merge(scores,how='left',left_on='ID',right_on='ID') - NaN值给默认值0:
students.merge(scores,how='left',on='ID').fillna(0) - 列类型转换:
table.Score = table.Score.astype(int) - 两个sheet使用join关联:
students.join(scores,how='left',on='ID').fillna(0)没有left_on和right_on
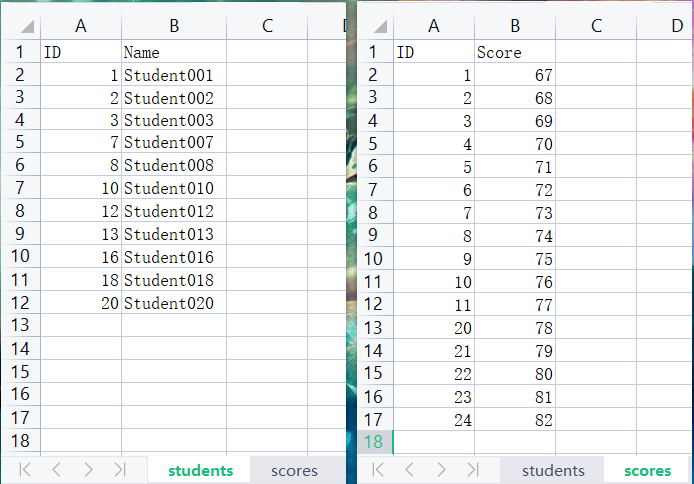
# 未指定索引列
import pandas as pd
students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students_score.xlsx',sheet_name='students')
scores = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students_score.xlsx',sheet_name='scores')
# print (students)
# print (scores)
# table = students.merge(scores,on='ID') ## 相当于inner join
# table = students.merge(scores,how='left',on='ID').fillna(0) ## 相当于 left join
table = students.merge(scores,how='left',left_on='ID',right_on='ID').fillna(0) ## 如果两列的关联字段名不一样
table.Score = table.Score.astype(int) ## 把Score列浮点型转为整型
print (table)
# 返回结果
Name Score
ID
1 Student001 67
2 Student002 68
3 Student003 69
7 Student007 73
8 Student008 74
10 Student010 76
12 Student012 0
13 Student013 0
16 Student016 0
18 Student018 0
20 Student020 78
# 指定索引列
import pandas as pd
students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students_score.xlsx',sheet_name='students',index_col='ID')
scores = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students_score.xlsx',sheet_name='scores',index_col='ID')
# table = students.merge(scores,how='left',left_on=students.index,right_on=students.index).fillna(0) ## 索引列关联
# table = students.join(scores,how='left').fillna(0) ## join默认使用索引列关联
table = students.join(scores,how='left',on='ID').fillna(0) ## join也可以使用ON,但是没有left_on和right_on
table.Score = table.Score.astype(int) ## 把Score列浮点型转为整型
print (table)
Name Score
ID
1 Student001 67
2 Student002 68
3 Student003 69
7 Student007 73
8 Student008 74
10 Student010 76
12 Student012 0
13 Student013 0
16 Student016 0
18 Student018 0
20 Student020 78
1.4.2: 数据校验,轴的概念
- axis(轴):
=0从上到下,=1是从左到右一个个校验 (一行行数据校验就是从左到右)
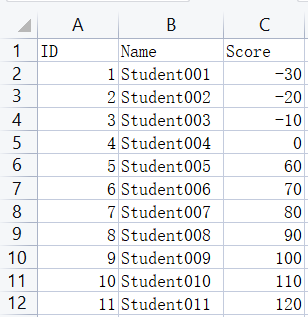
校验分数不能小于0或者大于100
import pandas as pd
def score_validation(row):
try:
assert 0<=row.Score<=100
except:
print (f'#{row.ID}\tstudent {row.Name} has an invalid score {row.Score}')
def score_validation2(row):
if not 0<=row.Score<=100
print(f'#{row.ID}\tstudent {row.Name} has an invalid score {row.Score}')
scores = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\scores.xlsx')
# scores.apply(score_validation,axis=1) # axis(轴)=0从上到下,1是从左到右一个个校验. (一行行数据校验就是从左到右)
scores.apply(score_validation2,axis=1) # axis(轴)=0从上到下,1是从左到右一个个校验. (一行行数据校验就是从左到右)
# 返回结果
#1 student Student001 has an invalid score -30
#2 student Student002 has an invalid score -20
#3 student Student003 has an invalid score -10
#10 student Student010 has an invalid score 110
#11 student Student011 has an invalid score 120
1.4.3: 一列数据分割成多列
- 切割字符串split :
.split(',') # 如果不填,默认是使用Tab或者空格作为分割符 - 切割字符串split :
.split(n=0) # 如果不填(或n=0),默认是所有; 如果n=2,则表示切割出多个字符串,只取前面两个
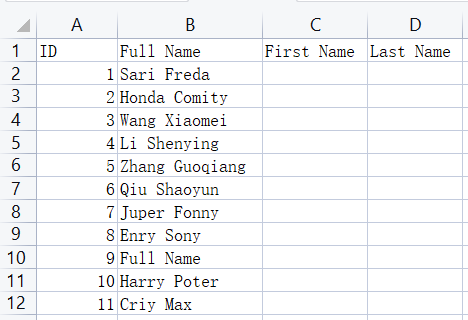
import pandas as pd
users = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\users.xlsx',index_col='ID')
df = users['Full Name'].str.split(expand=True)
users['First Name']=df[0].str.upper() # 取切割出的第1个字符串,并转为大写
users['Last Name']=df[1].str.upper() # 取切割出的第2个字符串,并转为大写
print (users)
# .split(',') # 如果不填,默认是使用Tab或者空格作为分割符
# .split(n=0) # 如果不填(或n=0),默认是所有; 如果n=2,则表示切割出多个字符串,只取前面两个
# 返回结果
Full Name First Name Last Name
ID
1 Sari Freda SARI FREDA
2 Honda Comity HONDA COMITY
3 Wang Xiaomei WANG XIAOMEI
4 Li Shenying LI SHENYING
5 Zhang Guoqiang ZHANG GUOQIANG
6 Qiu Shaoyun QIU SHAOYUN
7 Juper Fonny JUPER FONNY
8 Enry Sony ENRY SONY
9 Full Name FULL NAME
10 Harry Poter HARRY POTER
11 Criy Max CRIY MAX
1.4.4: 求和,求平均
相关函数参考: DataFrame — pandas 1.4.4 documentation (pydata.org)
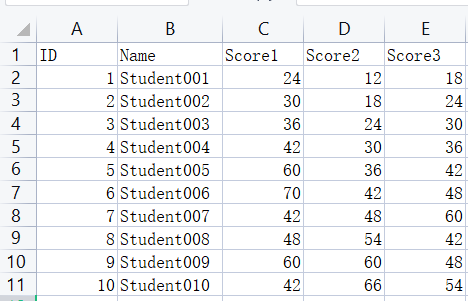
计算学生三次成绩的总分和平均分,并计算所有同学的总分和平均分
import pandas as pd
scores = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\scores.xlsx',index_col='ID')
# print (scores)
temp = scores[['Score1','Score2','Score3']]
row_sum = temp.sum(axis=1) # 横向求和
# col_sum = temp.sum(axis=0) # 纵向求和 .sum() 默认是纵向
row_mean = temp.mean(axis=1) # 统计平均值
scores['Total'] = row_sum
scores['Average'] = row_mean
col_mean = scores[['Score1','Score2','Score3','Total','Average']].mean() # 统计总平均值
col_mean['Name'] = 'Summary' # 添加合计名称
scores = scores.append(col_mean,ignore_index=True)
print (scores)
# 返回结果
Name Score1 Score2 Score3 Total Average
0 Student001 24.0 12.0 18.0 54.0 18.000000
1 Student002 30.0 18.0 24.0 72.0 24.000000
2 Student003 36.0 24.0 30.0 90.0 30.000000
3 Student004 42.0 30.0 36.0 108.0 36.000000
4 Student005 60.0 36.0 42.0 138.0 46.000000
5 Student006 70.0 42.0 48.0 160.0 53.333333
6 Student007 42.0 48.0 60.0 150.0 50.000000
7 Student008 48.0 54.0 42.0 144.0 48.000000
8 Student009 60.0 60.0 48.0 168.0 56.000000
9 Student010 42.0 66.0 54.0 162.0 54.000000
10 Summary 45.4 39.0 40.2 124.6 41.533333
Computations / descriptive stats (计算/描述性统计)
DataFrame.abs() |
Return a Series/DataFrame with absolute numeric value of each element. |
|---|---|
DataFrame.all([axis, bool_only, skipna, level]) |
Return whether all elements are True, potentially over an axis. |
DataFrame.any([axis, bool_only, skipna, level]) |
Return whether any element is True, potentially over an axis. |
DataFrame.clip([lower, upper, axis, inplace]) |
Trim values at input threshold(s). |
DataFrame.corr([method, min_periods]) |
Compute pairwise correlation of columns, excluding NA/null values. |
DataFrame.corrwith(other[, axis, drop, method]) |
Compute pairwise correlation. |
DataFrame.count([axis, level, numeric_only]) |
Count non-NA cells for each column or row. |
DataFrame.cov([min_periods, ddof]) |
Compute pairwise covariance of columns, excluding NA/null values. |
DataFrame.cummax([axis, skipna]) |
Return cumulative maximum over a DataFrame or Series axis. |
DataFrame.cummin([axis, skipna]) |
Return cumulative minimum over a DataFrame or Series axis. |
DataFrame.cumprod([axis, skipna]) |
Return cumulative product over a DataFrame or Series axis. |
DataFrame.cumsum([axis, skipna]) |
Return cumulative sum over a DataFrame or Series axis. |
DataFrame.describe([percentiles, include, ...]) |
Generate descriptive statistics. |
DataFrame.diff([periods, axis]) |
First discrete difference of element. |
DataFrame.eval(expr[, inplace]) |
Evaluate a string describing operations on DataFrame columns. |
DataFrame.kurt([axis, skipna, level, ...]) |
Return unbiased kurtosis over requested axis. |
DataFrame.kurtosis([axis, skipna, level, ...]) |
Return unbiased kurtosis over requested axis. |
DataFrame.mad([axis, skipna, level]) |
Return the mean absolute deviation of the values over the requested axis. |
DataFrame.max([axis, skipna, level, ...]) |
Return the maximum of the values over the requested axis. |
DataFrame.mean([axis, skipna, level, ...]) |
Return the mean of the values over the requested axis. |
DataFrame.median([axis, skipna, level, ...]) |
Return the median of the values over the requested axis. |
DataFrame.min([axis, skipna, level, ...]) |
Return the minimum of the values over the requested axis. |
DataFrame.mode([axis, numeric_only, dropna]) |
Get the mode(s) of each element along the selected axis. |
DataFrame.pct_change([periods, fill_method, ...]) |
Percentage change between the current and a prior element. |
DataFrame.prod([axis, skipna, level, ...]) |
Return the product of the values over the requested axis. |
DataFrame.product([axis, skipna, level, ...]) |
Return the product of the values over the requested axis. |
DataFrame.quantile([q, axis, numeric_only, ...]) |
Return values at the given quantile over requested axis. |
DataFrame.rank([axis, method, numeric_only, ...]) |
Compute numerical data ranks (1 through n) along axis. |
DataFrame.round([decimals]) |
Round a DataFrame to a variable number of decimal places. |
DataFrame.sem([axis, skipna, level, ddof, ...]) |
Return unbiased standard error of the mean over requested axis. |
DataFrame.skew([axis, skipna, level, ...]) |
Return unbiased skew over requested axis. |
DataFrame.sum([axis, skipna, level, ...]) |
Return the sum of the values over the requested axis. |
DataFrame.std([axis, skipna, level, ddof, ...]) |
Return sample standard deviation over requested axis. |
DataFrame.var([axis, skipna, level, ddof, ...]) |
Return unbiased variance over requested axis. |
DataFrame.nunique([axis, dropna]) |
Count number of distinct elements in specified axis. |
DataFrame.value_counts([subset, normalize, ...]) |
Return a Series containing counts of unique rows in the DataFrame. |
1.4.5: 定位,消除重复数据
- 删除重复数据:
drop_duplicates(subset='Name',inplace=True,keep='first') - 找出重复数据:
duplicated(subset='Name') ... iloc[dupe.index]
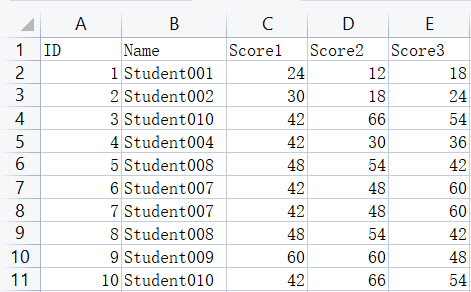
# 删除重复的数据
import pandas as pd
scores = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\scores.xlsx')
scores.drop_duplicates(subset='Name',inplace=True,keep='first') # 按照一列去重,keep保留第几个(first|last),默认为first
# scores.drop.duplicates(subset=['Name','Score1','Score2','Score3']) # 按照多列去重
print (scores)
# 找出重复数据,并标记
import pandas as pd
scores = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\scores.xlsx')
dupe = scores.duplicated(subset='Name')
# print (dupe) # True表示重复,False表示没有重复
# print (dupe.any()) # True表示有重复数据
dupe = dupe[dupe] # 等价于 dupe = dupe[dupe == True]
print (f'重复数据:\n {scores.iloc[dupe.index]}')
1.4.6: 旋转数据表(行列转换)
- 行转列:
transpose()
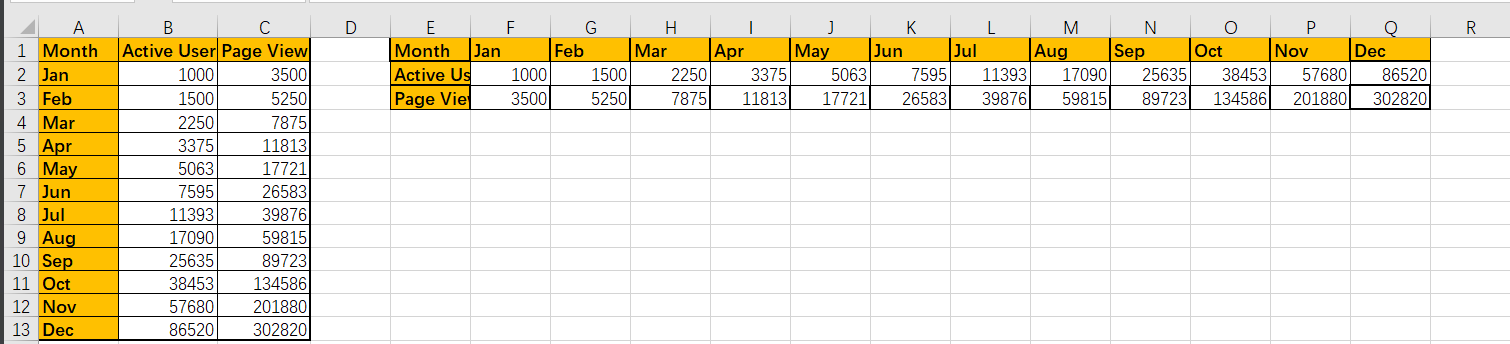
# 行转列
import pandas as pd
pd.options.display.max_columns=999
videos = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Videos.xlsx',index_col='Month')
table = videos.transpose()
print (table)
# 返回结果
Month Jan Feb Mar Apr May Jun Jul Aug Sep \
Active User 1000 1500 2250 3375 5063 7595 11393 17090 25635
Page View 3500 5250 7875 11813 17721 26583 39876 59815 89723
Month Oct Nov Dec
Active User 38453 57680 86520
Page View 134586 201880 302820
1.4.7:读取CSV,TSV,TXT中数据
- 读取csv,tsv,txt文件都是用方法:
read_csv - 指定分隔符:
sep='\t'
import pandas as pd
students1 = pd.read_csv(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.csv',index_col='ID')
students2 = pd.read_csv(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.tsv',sep='\t',index_col='ID')
students3 = pd.read_csv(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.txt',sep='|',index_col='ID')
print (students1)
print (students2)
print (students3)
1.4.8: 透视表,分组,聚合
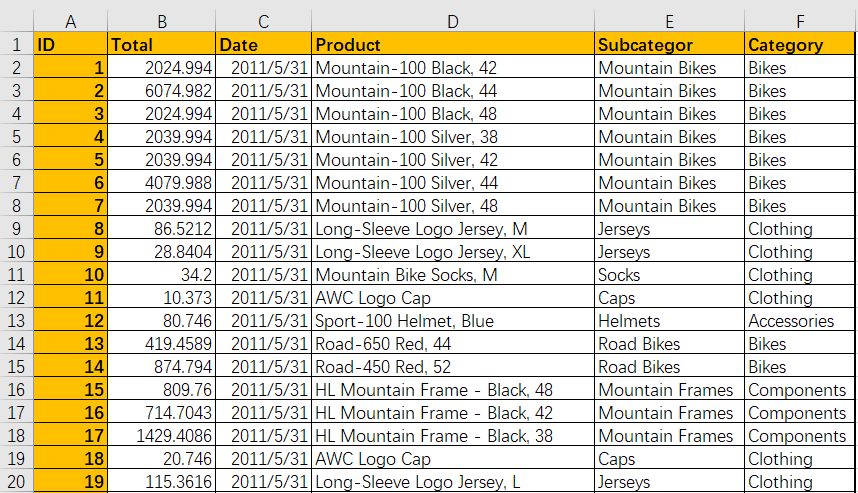
import pandas as pd
import numpy as np
pd.options.display.max_columns = 999
orders = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Orders.xlsx')
orders['Year'] = pd.DatetimeIndex(orders['Date']).year
# 方法一
pt1 = orders.pivot_table(index='Category',columns='Year',values='Total',aggfunc=np.sum)
print (pt1)
# 方法二
groups = orders.groupby(['Category','Year'])
s = groups['Total'].sum()
c = groups['ID'].count()
pt2 = pd.DataFrame({'Sum':s,'Count':c})
print (pt2)
# pt1结果
Year 2011 2012 2013 2014
Category
Accessories 2.082077e+04 1.024398e+05 6.750247e+05 4.737876e+05
Bikes 1.194565e+07 2.898552e+07 3.626683e+07 1.745318e+07
Clothing 3.603148e+04 5.555877e+05 1.067690e+06 4.612336e+05
Components 6.391730e+05 3.880758e+06 5.612935e+06 1.669727e+06
# pt2结果
Sum Count
Category Year
Accessories 2011 2.082077e+04 360
2012 1.024398e+05 1339
2013 6.750247e+05 20684
2014 4.737876e+05 18811
Bikes 2011 1.194565e+07 3826
2012 2.898552e+07 10776
2013 3.626683e+07 16485
2014 1.745318e+07 8944
Clothing 2011 3.603148e+04 655
2012 5.555877e+05 4045
2013 1.067690e+06 10266
2014 4.612336e+05 6428
Components 2011 6.391730e+05 875
2012 3.880758e+06 5529
2013 5.612935e+06 9138
2014 1.669727e+06 3156
1.4.9: 条件格式上色
-
先安装anconda,然后进入cmd执行命令
jupyter notebook, 根据返回的地址在浏览器中打开即可使用了. -
点击[New]--[Python 3] 进入python交互界面
-
测试代码如下
# 1: 给小于60分的字体改为红色 import pandas as pd def low_score_red(s): color = 'red' if s<60 else 'green' return f'color:{color}' students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.xlsx') students.style.applymap(low_score_red, subset=['Test_1', 'Test_2', 'Test_3']) ======================== # 2: 给最高分添加柠檬色背景,其它为红色背景 import pandas as pd def highest_score_green2(col): return ['background-color:lime' if v==col.max() else 'background-color:red' for v in col] students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.xlsx') students.style.apply(highest_score_green2, subset=['Test_1', 'Test_2', 'Test_3']) ======================== # 3: 添加浓淡色背景,数值越高颜色越深 import pandas as pd import seaborn as sns color_map = sns.light_palette('green', as_cmap=True) students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.xlsx') students.style.background_gradient(cmap=color_map, subset=['Test_1','Test_2','Test_3']) ======================== # 4: 添加颜色柱状展示,数值越深柱状越长 import pandas as pd students = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\Students.xlsx') students.style.bar(color='orange', subset=['Test_1','Test_2','Test_3'])
-
测试结果如下
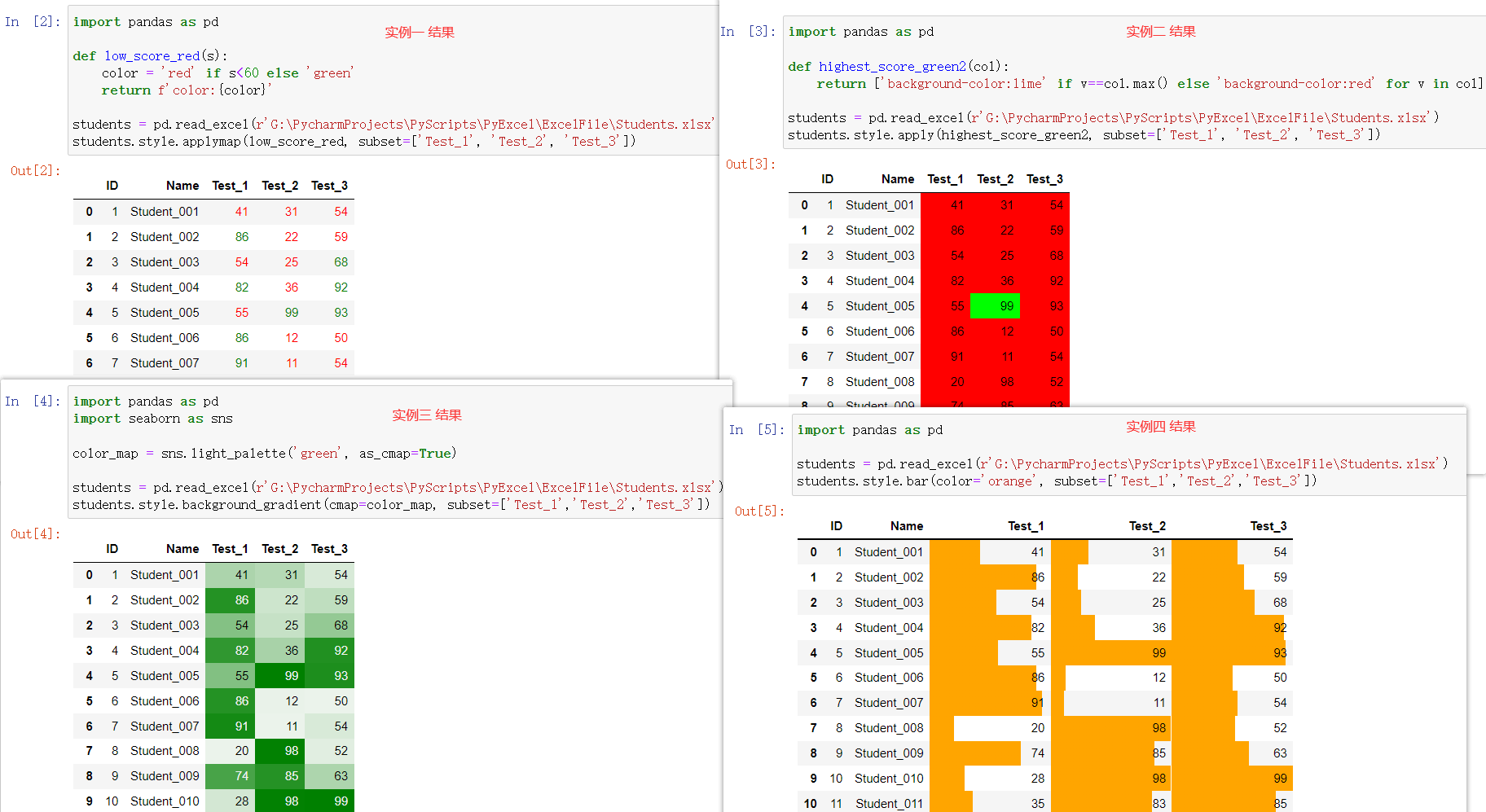
1.5: 常用操作集锦
1.5.1: 行操作集锦
- 两个表竖向串联
df.append(df2)或者pd.concat([df1,df2],axis=0).reset_index(drop=True) - 两个表横向串联
pd.concat([df1,df2],axis=1).reset_index(drop=True) - 新生成索引并删除老的索引
reset_index(drop=True) - 修改单元格
df.at[index,'colname']='colvalue' - 替换单元格
df.iloc[index]= SeriesData - 删除数据行--指定索引删除
df.drop(index=[0,1,2],inplace=True) - 删除数据行--range索引删除
df.drop(index=range(0,10),inplace=True) - 删除数据行--切片索引删除
df.drop(index=students[0:10].index,inplace=True)
import pandas as pd
page_001 = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx',sheet_name='Page_001')
page_002 = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx',sheet_name='Page_002')
# 拼接并重置索引列同时删除旧的索引列(append方法即将移除,使用concat替换)
# students = page_001.append(page_002).reset_index(drop=True)
students = pd.concat([page_001,page_002]).reset_index(drop=True)
# 追加手动创建的一行数据
stu = pd.Series({'ID':41,'Name':'Abel','Score':99})
students = students.append(stu,ignore_index=True)
# stu = pd.Series({'ID':41,'Name':'Abel','Score':99})
# students = pd.concat([students,stu],axis=0,ignore_index=True).reset_index(drop=True)
# 修改单元格数据
students.at[38,'Name']='Tony'
students.at[38,'Score']=98
# 替换单元格数据
stu = pd.Series({'ID':37,'Name':'Bailey','Score':120})
students.iloc[36]=stu
# 中间插入一行(切片)
stu = pd.Series({'ID':101,'Name':'Dana','Score':101})
part1 = students[:20]
part2 = students[20:]
students = part1.append(stu,ignore_index=True).append(part2).reset_index(drop=True)
# 删除数据行
students.drop(index=[0,1,2],inplace=True) # 指定删除
students.drop(index=range(0,10),inplace=True) # range索引删除
students.drop(index=students[0:10].index,inplace=True) # 切片索引删除
# 按条件删除数据行(删除名字为空的行)
for i in range(5,15):
students['Name'].at[i] = ''
missing = students.loc[students['Name']=='']
students.drop(index=missing.index,inplace=True)
students = students.reset_index(drop=True) # 重置索引,让从0开始连续
print (students)
1.5.2: 列操作集锦
- 追加列
df['Age']=18 - 删除列
df.drop(columns=['Age','Score'],inplace=True) - 插入列
df.insert(index,column='Foo',value='colvalue') - 修改列名
df.rename(column={'OldColName':'NewColName','OldColName2':'NewColName2'},inplace=True) - 删除存在nan值的数据行
df.dropna(inplace=True)
import pandas as pd
import numpy as np
page_001 = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx',sheet_name='Page_001')
page_002 = pd.read_excel(r'G:\PycharmProjects\PyScripts\PyExcel\ExcelFile\students.xlsx',sheet_name='Page_002')
students = pd.concat([page_001,page_002]).reset_index(drop=True)
# 追加列
students['Age']=np.arange(0,len(students))
# 删除列
students.drop(columns=['Age','Score'],inplace=True)
# 插入列 Foo,填充内容为 ColValue
students.insert(1,column='Foo',value=np.repeat('ColValue',len(students)))
# 修改列名
students.rename(columns={'Foo':'FOO','Name':'NAME'},inplace=True)
# 删除nan行
students['ID'] = students['ID'].astype(float)
for i in range (5,15):
students['ID'].at[i]=np.nan
# 横向扫描每一行,该行中任意一列存在nan值,就删除该行数据
students.dropna(inplace=True)
print (students)