随着cpu技术发展,现在大部分移动设备、PC、服务器都已经使用上64bit的CPU,但是关于Linux内核的虚拟内存管理,还停留在历史的用户态与内核态虚拟内存3:1的观念中,导致在解决一些内存问题时存在误解。

例如现在主流的移动设备操作系统Android,经常遇到进程使用大量内存导致被lmk杀死,分配不到内存而触发OOM/ANR,或者分配内存慢导致卡顿,内核态使用哪个分配内存的函数更合理等问题,有些涉及物理内存分配,有些涉及虚拟内存分配,如果不熟悉虚拟内存管理的技术知识,可能走很多弯路。
我们计划通过一系列文章来介绍虚拟内存分配/释放,缺页处理,内存压缩/回收,内存分配器等知识,梳理虚拟内存的管理。本章节结合代码介绍进程虚拟内存布局以及进程的虚拟内存分配释放流程,涉及的代码是android-8.1, 内核版本kernel-4.9,架构是arm64。
进程虚拟内存空间
虚拟地址空间分布
理论上,64bit地址支持访问的地址空间是[0, 2(64-1)],而实际上现有的应用程序都不会用这么大的地址空间,并且arm64芯片现在也不支持访问这么大的地址空间,arm64架构芯片最大支持访问48bit的地址空间。例如在Android系统中,整个虚拟地址空间分成两部分,如下图所示:
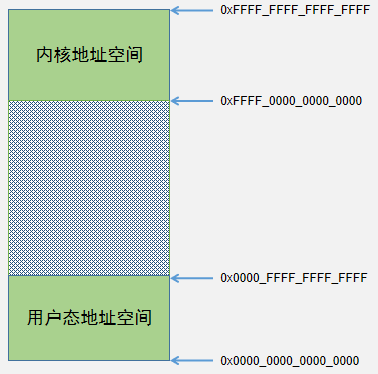
其中[0x0001000000000000,0xFFFF000000000000]之间的地址是不规范地址,不能使用;该段内存把整个虚拟地址空间划分为两段,低段内存为进程用户态地址空间,高段内存为内核地址空间。参考代码(arch\arm64\include\asm\memory.h):

如果内核打开CONFIG_COMPAT选项,说明用户态既支持64位进程,也支持32位进程;由于32bit的地址最多可以访问的虚拟地址空间最多只有4GB(232 Byte),所以32位进程的用户态进程地址空间与64位进程是有区别的。
32位进程的用户态地址空间是[0x0, 0x00000000FFFF_FFFF]
64位进程的用户态地址空间是[0x0, 0x0000FFFFFFFF_FFFF]

从代码看出,32bit进程用户空间大小是4GB,64bit进程的虚拟内存大小与CONFIG_ARM64_VA_BITS的值相关;如果CONFIG_ARM64_VA_BITS是48bit则可以达到256TB,现在的移动设备显然用不到这么大的内存空间,所以大部分Android设备中CONFIG_ARM64_VA_BITS默认配置的是39,即64bit进程的最大虚拟地址空间大小是512GB。
虽然32bit或者64bit的进程在用户态内存空间大小不一样,但是当它们陷入到内核态后,访问的内核空间地址是没有差异的,都是从VA_START开始,直到0xFFFFFFFFFFFFFFFF结束,也是512GB。
每个进程的虚拟地址空间主要分为如下几个区域(如图):
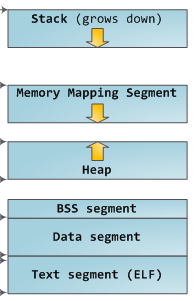
代码段(text)、数据段(data)和未初始化数据段(bss)。
动态库的代码段、数据段和未初始化数据段。
堆(heap),动态分配和释放的内存。
栈(stack),存放局部变量和实现函数调用。
环境变量和参数字符串的存储区。
文件区间映射到虚拟地址空间的内存映射区域。
其中Data Segment、BSS segment、Heap段统称为数据点。
几种地址的概念
介绍完虚拟内存地址空间,澄清几种地址的概念:物理地址、线性地址、逻辑地址三种地址的含义。
物理地址
每片物理内存存储实际地址,例如一个8GB的内存,0x00000000表示第一个byte的地址,而0xFFFFFFFF表示的是最后一个byte的地址;物理地址的值与实际的内存条上的地址一一对应,物理地址的大小与cpu访问物理内存的总线宽度有一定的关系。
线性地址
为了保证系统多任务运行的安全性和可靠性(防止一个任务篡改系统或者其他任务的内存),CPU增加段页式内存管理;段基地址+段内偏移构成的地址就是线性地址;如果开启的分页内存管理,线性地址还要通过MMU计算才能转换出物理地址。
逻辑地址
每个进程运行时CPU看到的地址就是逻辑地址,实际上也是线性地址中的段内偏移地址,逻辑地址与段基地址可以计算出线性地址。
进程在访问虚拟地址空间的任意合法地址时,都要按照逻辑地址->线性地址->物理地址的顺序换算才能找到对应的物理地址;由于段式内存管理存在性能、访问效率的问题,以及Linux要兼容各种CPU,在Linux内核中所有的用户态进程使用的同一个段,且段基地址都是0,如此既可以兼容的传统的段式内存管理,又可以通过页式内存映射更灵活的管理内存。由于同一个段基地址都是0,对每个进程来说,逻辑地址和线性地址是一样的;同时每个进程的PGD是不一样的,从而保证每个进程之间隔离,不同进程同一个虚拟地址映射的物理地址就不一样了。
Linux系统采用延迟分配物理内存的策略,用户态进程每次分配内存时分配的都是虚拟内存,表示一段地址空间已经分配出来供进程使用;当进程第一次访问虚拟地址时,才会发现虚拟地址没有对应的物理内存,系统默认会触发缺页异常,从内核物理内存管理系统中分配物理页,建立页表中把虚拟地址映射到物理地址。对于缺页异常处理流程,页表创建/建立/销毁等操作在以后文章中介绍。
分配内存的系统调用
在Linux系统中,虚拟内存和物理内存都是由kernel管理的,当进程需要分配内存时,都需要通过系统调用陷入到内核空间分配,再虚拟内存起始地址返回到用户态;内核提供了多个系统调用来分配虚拟内存,包括brk、mmap和mremap等。
brk系统调用
brk是传统分配/释放堆内存的系统调用, 堆内存是由低地址向高地址方向增长;
分配内存时,将数据段(.data)的最高地址指针_edata往高地址扩展;
释放内存时,把_edata向低地址收缩。
可以看出brk系统调用管理的始终是一片连续的虚拟地址空间,而且起始地址一经设定就默认不变,只是高地址按需变化。
mmap系统调用
mmap系统调用是在进程堆和栈中间(称为Memory Mapping Segment)找一块空闲的虚拟内存,mmap可以进行匿名映射和文件映射,文件映射即把磁盘存储设备上面的文件映射的内存中,然后访问内存就是访问文件,文件映射的物理页是可以通过kswapd或者direct reclaim回收的;匿名映射即没有映射任何文件。
由于brk系统调用分配内存存在内存碎片化线性,例如先分配100MB的内存,然后再分配4KB内存,再把100MB内存释放掉,此时由于4KB内存还没有释放,_edata就不能收缩,导致100MB内存不能及时操作系统;反之先分配4KB,在分配100MB,则存在内存碎片化的问题。另外由于_edata上面是mmap区域,_edata与最近的mmap内存很接近,则会导致brk系统调用极容易分配失败,即使memory mmap区域还有大量可用内存。Brk分配管理的实际上就是一块匿名映射的内存,所以实际上可以通过mmap匿名映射来满足malloc的内存分配。在Linux操作系统标准libc库中,malloc函数的实现中会根据分配内存的size来决定使用哪个分配函数, 当size小于等于128KB,调用brk分配, 当size大于128KB时,调用mmap分配内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
分配器
如果进程每次分配内存都通过brk和mmap系统调用分配的话,存在两个致命的问题:
碎片化的问题,从内核分配虚拟内存都是按照page(默认是4KB)对齐来分配的,如果进程分配8byte,实际从内核分配的内存是4096byte,这样就存在4088byte的浪费;同时进程的内存分配需求存在随机性,如果不同大小的内存交替分配,当部分内存释放后,整个内存空间严重碎片化,导致最后分配大片内存时高概率会失败。
性能问题,系统调用从用户态陷入到内核态都是通过中断来实现的,在进程从内核态返回到用户态时,任务有可能被调度出cpu;另外,对于多线程的进程,所有的线程共享同一个mm,如果多个线程同时分配内存,则在内核空间存在竞争关系,所有的线程分配请求都要排队处理;如果频繁系统调用分配内存,分配内存的效率会降低。
分配器的出现就是为了解决上述问题,例如我们熟悉的libc库,调用malloc的时候并不是每次都会通过系统调用从内核分配内存的,而是分配器相当于在malloc和系统调用之间插入一层中间件。分配器首先通过系统调用从内核批发大块内存,然后切成不同大小的内存片缓存起来,例如8/16/24/32/64byte等,当调用malloc的时候,直接从cache的空闲小内存片分配;同时为了解决性能问题,分配器对每个线程或者每个cpu预留单独的cache,每个线程从自己的cache中分配,可以减少线程之间的锁竞争。
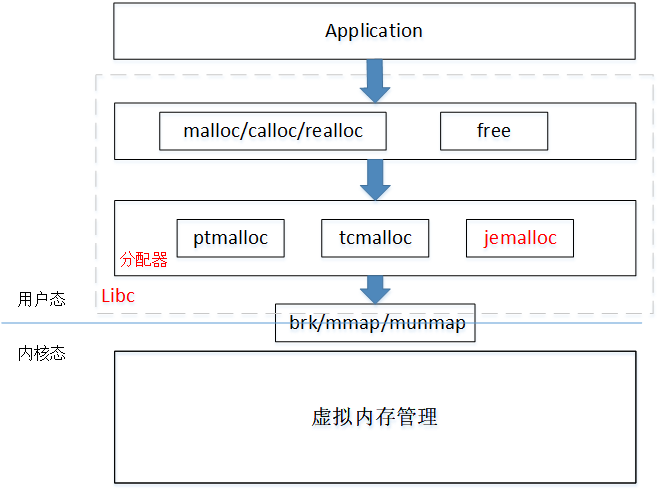
现在业界主流的分配器有ptmalloc、tcmalloc、jemalloc、scudo等。在Android系统中,为例提高兼容性和性能,malloc函数的实现,默认都是通过mmap系统调用分配内存,不再使用brk系统调用(部分三方APP自带SDK可能会用brk)。Android现在用的分配器是jemalloc或者scudo,关于分配启动实现本文不再赘述。
进程分配内存核心函数
本节介绍brk、mmap、munmap函数的实现所用到的几个核心函数。
几个关键的数据结构
在介绍进程如何分配到虚拟内存之前,先了解几个进程内存管理相关的数据结构。
struct mm_struct
每个进程或内核线程都由一个任务描述数据结构(task_struct)来管理,每个task_struct中有个struct mm_strcut数据结构指针,用来管理任务的虚拟地址空间;而内核线程是没有用户态虚拟地址空间,所以其mm字段为NULL;mm的数据结构如下:



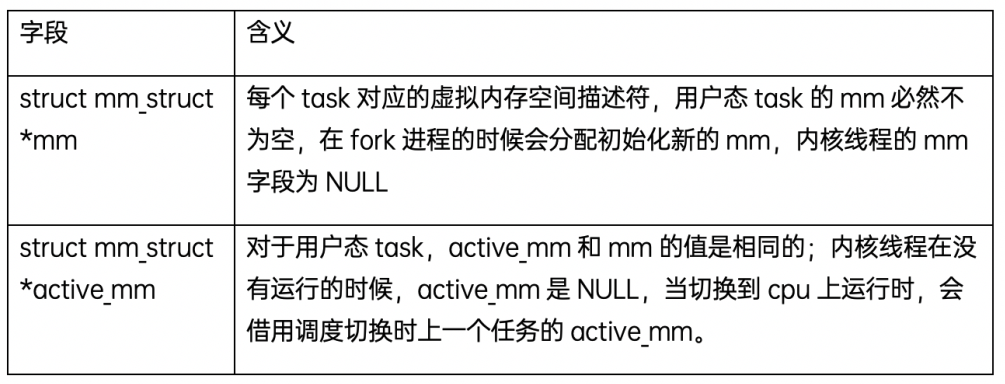
struct mm_struct是每个task的虚拟内存空间的描述符,例如用户态进(线)程栈区间,堆区间的地址和大小等;每个进程只有一个mm,即使是多个线程的进程,所有的线程都是共享同一个mm,mm_struct数据结构中几个关键字段的含义如下:
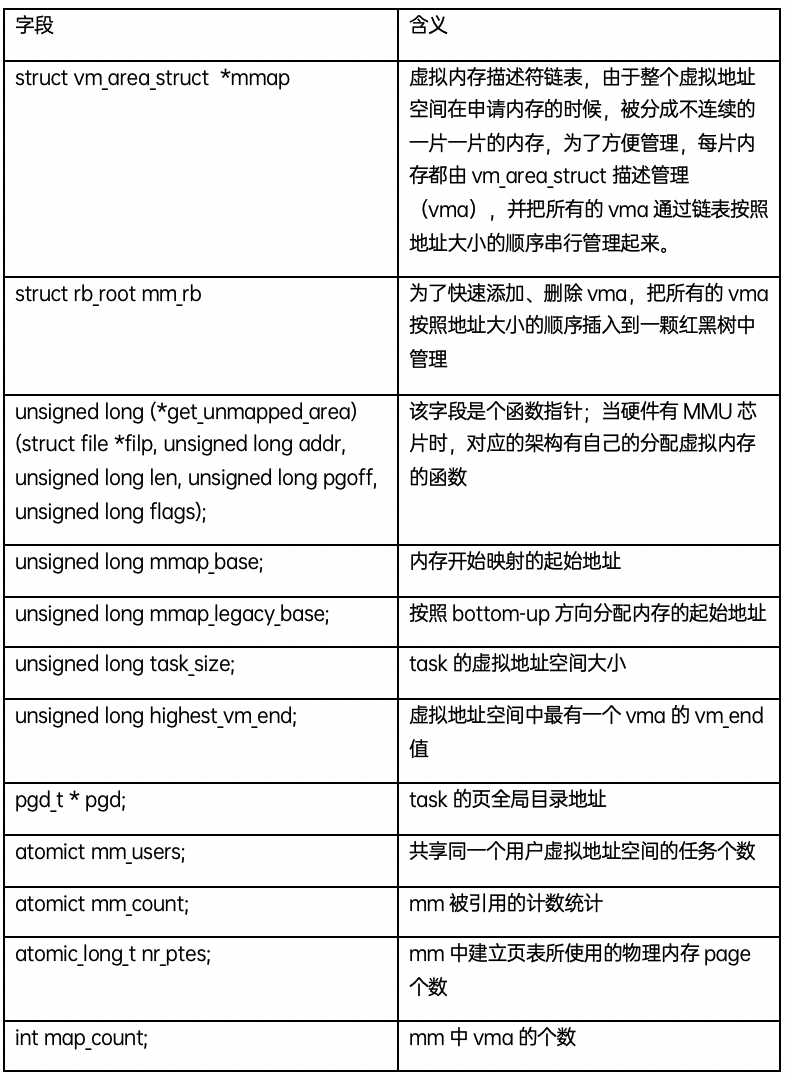
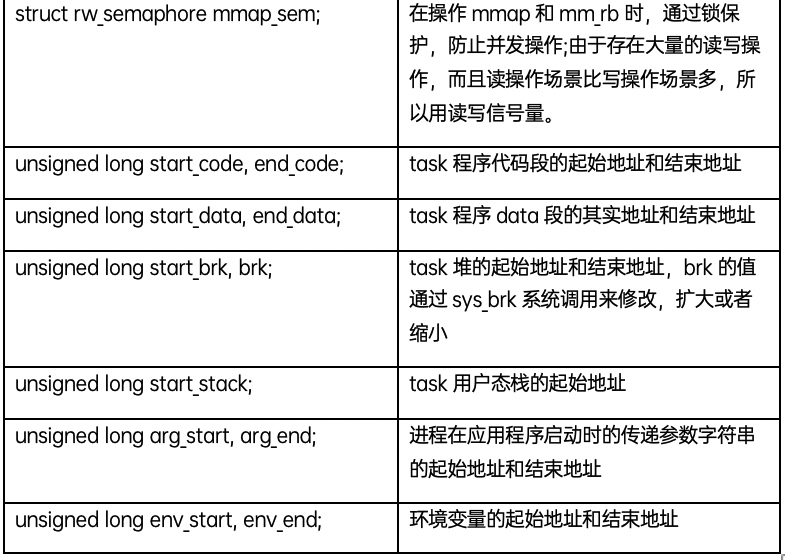
struct vm_area_struct
分配的每个虚拟内存区域都由一个vm_area_struct 数据结构来管理,包括虚拟内存的起始和结束地址,以及内存的访问权限等,通常命名为vma;vm_area_struct 数据结构的定义如下:

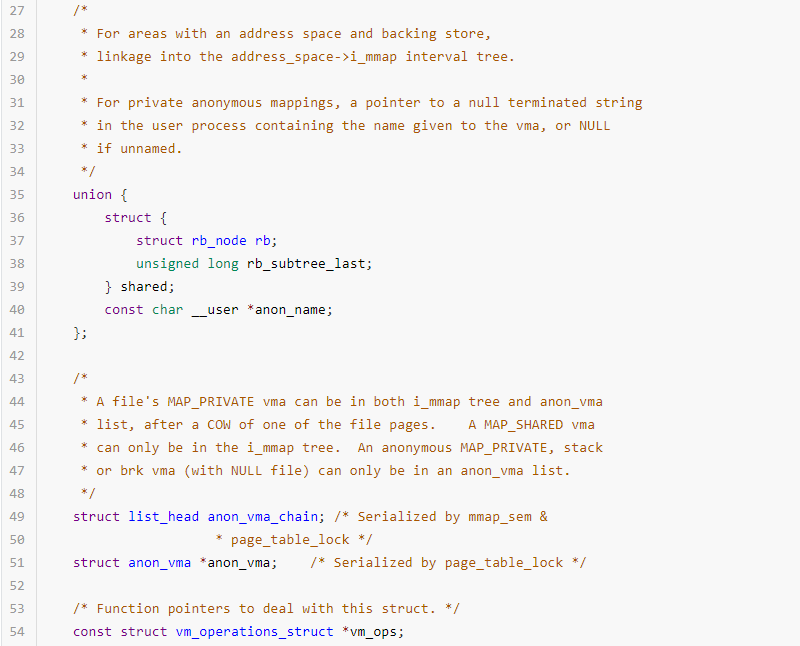

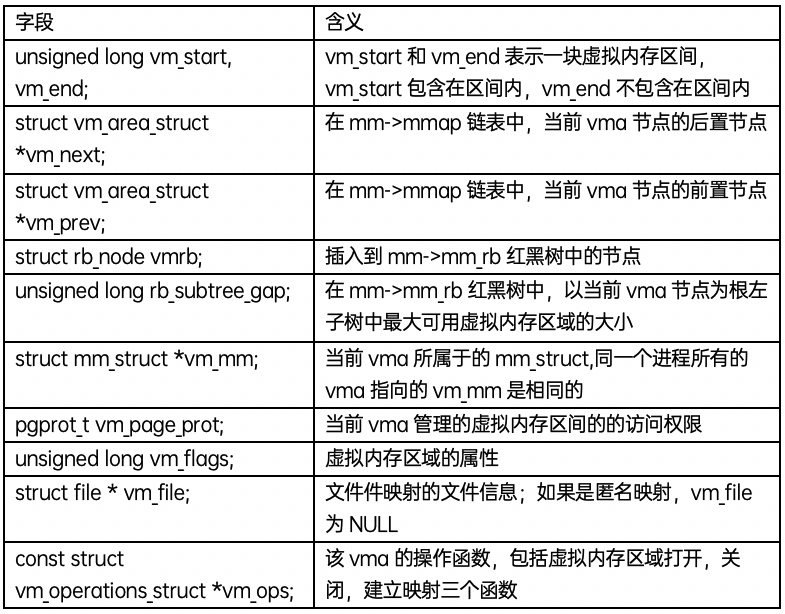
mm_struct和vm_area_struct描述的都是进程的虚拟地址空间,所谓的“虚拟”,意思是指进程有相应大小内存需求,一个虚拟内存地址区域表示该段内存已经分配出去,但是并不保证该地址空间已经映射物理内存,也不保证相应的物理页在内存中。例如分配2MB的内存后,自始至终没有访问过这片内存,所以这2MB的内存只是占用了虚拟地址空间,没有使用相应大小的物理内存。
当访问一个未经映射的虚拟地址时,就会产生一个“Page Fault”事件(通常叫做缺页异常),当前进程会被缺页异常打断而进入异常处理函数,在处理函数中,会从伙伴系统中分配一个page,与相应的虚拟地址建立映射,这个映射关系需要通过页表来管理;同时页表也需要单独分配内存来保存,所以在计算一个进程使用的物理内存时,也要算上页表的内存。
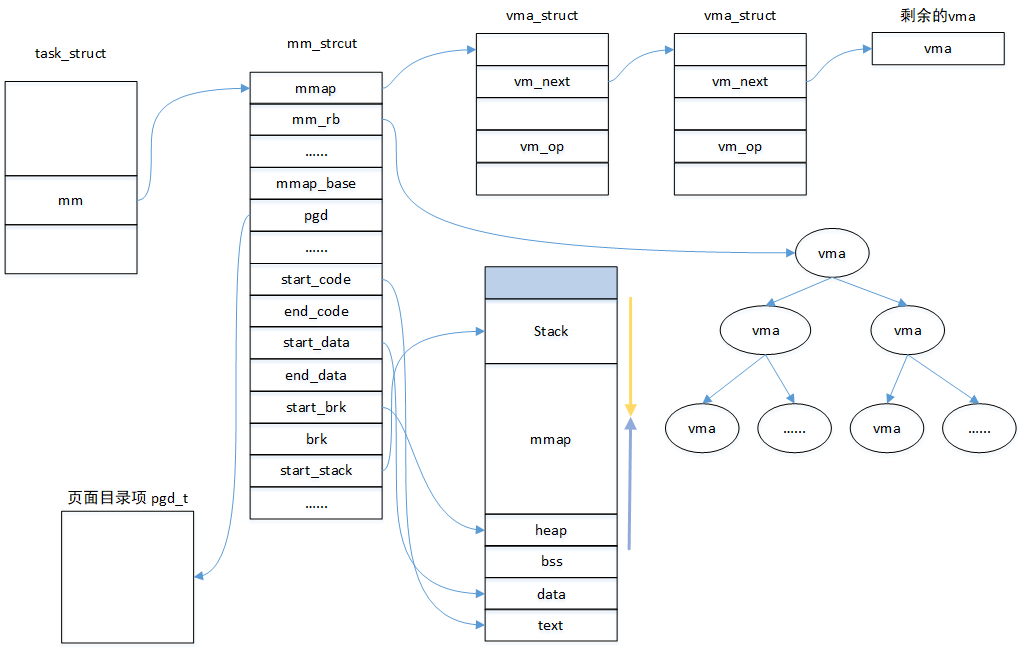
在一个mm中,所有的vma通过两种结构管理一起来,一个是双向链表,一个是红黑树。当遍历这个虚拟地址空间时,通过双向链表是常用的方法;当在虚拟地址空间查找vma是,通过红黑树查找是更便捷的方法。通常两种方法会结合起来使用,例如通过红黑树查找到某个vma,后要找到该vma的前置,则直接通过vma->vm_prev就可以直接获取。通过一个图表展示一下几个数据结构之间的关系:
几个关键的函数
arch_pick_mmap_layout
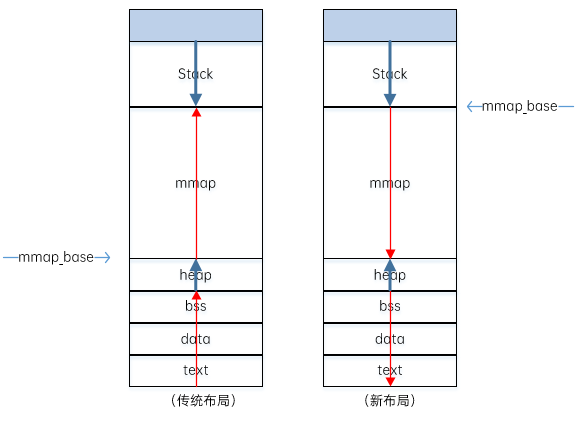
进程虚拟内存映射存在两种布局方式,主要区别是mmap_base值和分配虚拟内存增长方向。
传统布局
映射区域自底向上增长,mmap_base的值是TASK_UNMAPPED_BASE,ARM64架构中定义为TASK_SIZE/4。内核默认启用内存映射区域随机化,在该起始地址加上一个随机值。传统布局的缺点是堆的最大长度受到限制,例如_edata的值增长会受到mmap_base的限制,在32位系统中影响比较大,在64位系统中则不是紧急的问题。
新布局
内存映射区域自顶向下增长,mmap_base的值是(STACK_TOP – STACK_GAP)。默认启用内存映射区域随机化,需要把起始地址再减去一个随机值。
两种布局如下图所示:
开启地址随机化
在进程调用execve以装载ELF文件的时,load_elf_binary会创建进程的用户虚拟地址空间。如果进程描述符的成员personality没有设置标志位ADDR_NO_RANDOMIZE(该标志位表示禁止虚拟地址空间随机化),并且全局变量randomize_va_space是非零值,那么给进程设置标志PF_RANDOMIZE,允许虚拟地址空间随机化。

不同CPU架构内存映射区域的布局可能不一样,所以不同arch都要实现自己的arch_pick_mmap_layout函数。ARM64架构定义的函数arch_pick_mmap_layout如下:
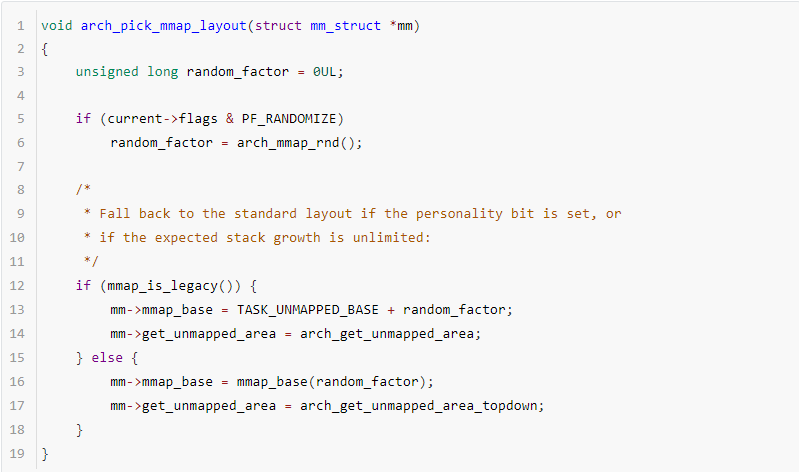
如果开启了地址随机化,则通过arch_mmap_rnd计算获取一个随机值;计算随机值是有范围的:
在传统布局中,随机范围是[0, ((1UL << mmap_rnd_compat_bits) - 1)<<PAGE_SHIFT]
在新布局中,随机值范围[0,((1UL << mmap_rnd_bits) - 1)<<PAGE_SHIFT]。初始化mmap_base后,初始化get_unmapped_area,传统布局调用arch_get_unmapped_area,新布局调用arch_get_unmapped_area_topdown。
arch_get_unmapped_area 和 arch_get_unmapped_area_topdown函数都用到一个核心数据结构struct vm_unmapped_area_info,这个数据结构用于管理分配内存请求。
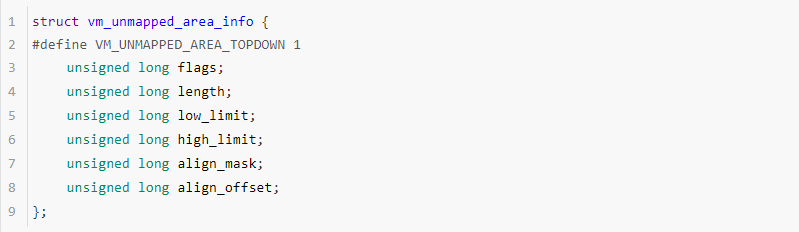

传统布局,查找空闲内存的范围是[mm->mmapbase, TASKSIZE],实现该功能的函数arch_get_unmapped_area代码如下:

1.如果是文件映射分配内存,filp指向对应打开的文件描述数据结构,如果是匿名映射,filp为NULL。addr是建议分配内存起始地址,如果以addr开始的地址恰好是空闲的,且满足本次分配需求则返回成功,参考15~22行代码;如果不满足需求,则初始化info,调用vm_unmapped_area函数来扫描mmap映射区域来查找满足请求的内存。
2.len表示本次请求分配内存的长度。pgoff表示分配的内存映射到filp描述的文件中的偏移,如果是匿名映射,该参数是忽略的。flags表示本次分配内存的属性和权限信息。
新布局中,遍历内存的方法稍微不同,先看下代码:

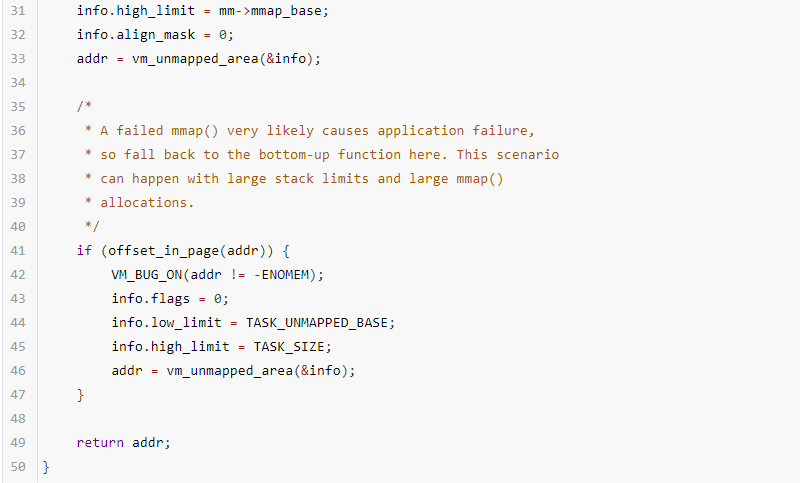
1.参数的含义与arch_get_unmapped_area相同
2.新的布局与传统布局分配新内存的行为有差异,当从高到低的方向分配内存失败的情况下,会再次从低到高的方向分配一次。28~32行代码,设置flag为VM_UNMAPPED_AREA_TOPDOWN,并从mm->mmap_base到max(PAGESIZE, mmap_min_addr)从高地址向低地址分配一次,用offset_in_page判断分配是否成功,由于在分配成功的情况下,分配的addr是page对齐的,所以addr的低12bit都是0,而如果addr的低12bit的值不是0,则说明分配失败。
从41~46行代码看出,flag已经设置为0(方向变成由低到高),同时遍历的区间变成了[TASK_UNMAPPED_BASE, TASK_SIZE]。
unmapped_area
从vm_unmapped_area函数看出,unmapped_area实现由低到高的方向分配内存的方法,unmapped_area_topdown实现由高到低的方向分配内存的方法。
回顾一下,进程虚拟地址空间中所有vma按照地址从小到大的顺序,分别记录在一个双向链表和一个红黑树里面,通过链表可以快速遍历所有分配的内存信息,例如proc/$pid/maps和/proc/$pid/smaps两个节点的实现;通过遍历红黑树可以快速查找到包含指定地址的vma,例如分配内存时查找到空闲内存。
在vma的红黑树中,每个节点的左子树上所有内存地址都小于其右子树上的所有内存地址,传统布局中采用中序遍历的方式从根开始遍历所有vma查找空闲内存,先从左子树开始遍历,直到找到最左边的满足分配需求的内存;如果在根的左子树上面没有找到,则开始遍历右子树,以右子树为根递归遍历;为了提高效率,每个vma的rb_subtree_gap值表示该树最大的空闲内存大小,如果连根节点的rb_subtree_gap都不满足分配需求,则说进程已经OOM;如果满足需求,则开始遍历找到满足请求的空间并返回起始地址。




16~27行代码首先对入参进行合法性判断,其中16行代码info->length + info->align_mask在length的基础上加上对齐的mask,防止执行到最后由于对齐的问题导致分配失败,但是此处也存在缺陷:空闲内存的长度和对齐方式恰好都满足需求,而此处加上mask导致提前分配失败,这是个极端情况,即使出现也说明空闲内存已经不充足。
30~31行代码,当进程第一次进行内存分配时,红黑树最开始原本就是空的,说明此时空闲内存是充足的,所以直接跳到84行开始分配内存。
32~34行,获取根节点的vma,并判断rb_subtree_gap是否满足分配需求,如果不满足需求则只能查看最后一个vma->vm_end到虚拟地址空间最大值之间的内存是否满足需求;由于从低向高方向分配内存时,红黑树最右侧vma的结束地址与虚拟地址空间最大值之间的这段内存在红黑树中是没有统计的,所以需要判断一下。
36~82是核心代码,首先从红黑树的根得知在树种是可以找到满足分配需求的内存的;从39行看出,vma->vm_rb.rb_left先从根的左子树找起,gap_end >= low_limit说明空闲内存是在分配请求内存上下限之间的,那么继续找左子树,直到找到不满足需求的vma,即(gap_end >= low_limit && vma->vm_rb.rb_left)条件不成立,有两种情况,第一种,gap_end >= low_limit不成立说明现在vma已经超出需求上下限范围;vma->vm_rb.rb_left不成立说明已经找到最左节点了,由于是由低到高的方向分配内存的,所以此时左边没有必要找了,接着判断当前vma与vma->vm_prev之间的空间是否满足需求(54~56行),如果当前vma不满足则开始找当前vma的右子树(59~67行),如果在当前vma子树中没有找到满足需求的内存空间,则从上一层根子树中查找。
84~89行代码,当在红黑树中没有找到满足需求的内存时,判断最后一个vma到虚拟地址空间最大值之间的空闲内存是否满足需求,如果不满足则说明oom了。92~101表示已经找到满足需求的内存空间,其中97行堆起始地址进行对齐处理。
unmapped_area_topdown实现由高向低的方向分配内存,与unmapped_area区别是遍历的方法变化了,先从右子树遍历查询,再判断根节点,最后从左子树查询,代码不在这里介绍。
getunmappedarea
分配虚拟内存的时候,首先需要找到一块空闲的满足分配需求的内存空间,调用的函数是get_unmapped_area,代码如下:
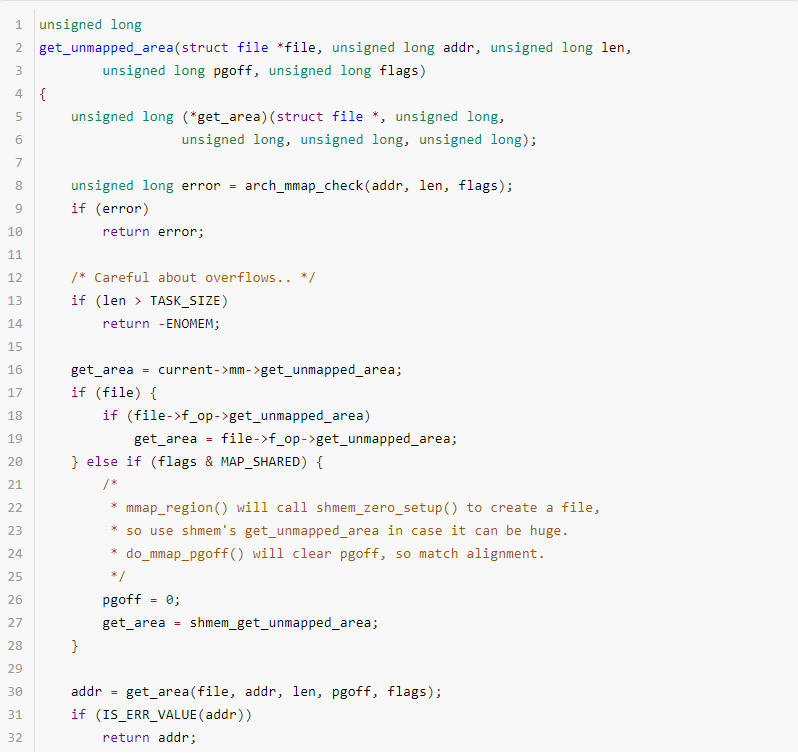
1.参数共5个
struct file *file,如果是匿名映射,file为NULL;如果是文件映射,file不能为空,则表示分配的内存即将映射file中的内容。
unsigned long addr,表示要分配内存的起始地址。
当addr不为0时,如果该地址起始的内存恰好满足需求,返回addr;如果flasgs配置了MAP_FIXED,则不会判断是否满足直接返回addr;
当addr为0时,在整个虚拟地址空间中找到满足需求的空闲内存,对起始地址没有特殊要求。
unsigned long len, 要分配内存的长度,长度单位是Byte,不足PAGE_SIZE按PAGE_SIZE处理。
unsigned long pgoff,分配的内存,映射文件内容在文件中的起点。
unsigned long flags, 指定映射对象的属性,映射选项和映射页是否可以共享,LOCKED等属性。
2.代码分析
第8行,arch_mmap_check是个各个架构实现的mmap校验函数,主要是对固定映射,addr有大小限制,arm64架构定义为空。
13~14行,校验len大小,如果超过TASK_SIZE则明显溢出,直接返回。
16~28行,给函数指针get_area赋值,初始值为current->mm->get_unmapped_area,当本次分配是文件映射分配内存,需要判断file->f_op->get_unmapped_area是否为NULL,如果不为NULL则赋值给get_area,这么操作的原因是部分文件系统文件映射分配虚拟内存时有特殊的要求或操作,例如flags、len等客制化处理等;如果是匿名映射且配置了MAP_SHARED,则赋值shmem_get_unmapped_area给get_area。
30~37行,调用get_area分配新的映射空间,然后校验分配的地址是否有效,其中offset_in_page函数判断的原理是:如果分配成功,addr的值一定是PAGE_ALIGN的,如果addr低12bit不为0,则说明分配失败。
39行,安全检查addr,security_mmap_addr函数是Linux Security Module中函数,这里不详细介绍。
未完待续……