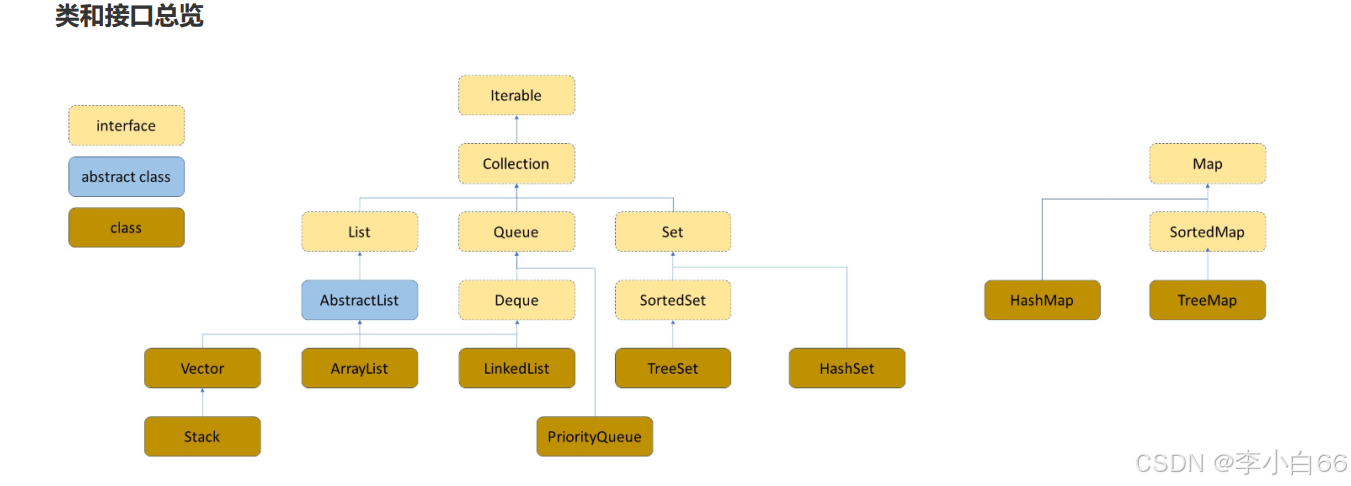
常见的集合框架
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
System.out.println(a == b);//[-128,127]
Integer a1 = 200;
Integer b1 = 200;//源码里面,如果超过127则会new一个新的对象
System.out.println(a1 == b1);
}
//
true
false泛型就是适用于很多类型,从代码来说就是对类型实现了参数化
关于擦除机制: 编译的时候所有的T都被替换成Object,
顺序表和链表/ArrayList和LinkedList/数组和链表的区别
ArrayList需要注意的点
1. 我们在创建ArrayList实例的时候,不设置参数,我们调用的是无参构造方法,里面是一个空的数组,没有分配内存.
2. 当第一次add的时候,我们才会分配大小为10的内存
3. 如果add方法检测出size大小等于数组大小,就会进行1.5倍的扩容
ArrayList是基于动态数据实现的,它的逻辑地址和物理地址都是连续的.
优点:
1> ArrayList 是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询
操作效率会比较高(在内存里是连着放的)。查询的时间复杂度是O(1)
缺点:
1> 插入数据必须移动其他数据,最坏的情况下插入到第一个位置,时间复杂度是O(N)
2> 删除数据也必须移动其他数据,最坏情况下删除第一个位置,时间复杂度是O(N)
3> 1.5倍扩容之后,假设我们只用了扩容后的一点,会造成空间的浪费
总结: 顺序表比较适合进行给指定下标查找的情况
LinkedList
LinkedList(双向链表) 基于链表的数据结构,链表是由一个个节点通过引用链接组成,每个结点分为value数据域和next引用域组成.
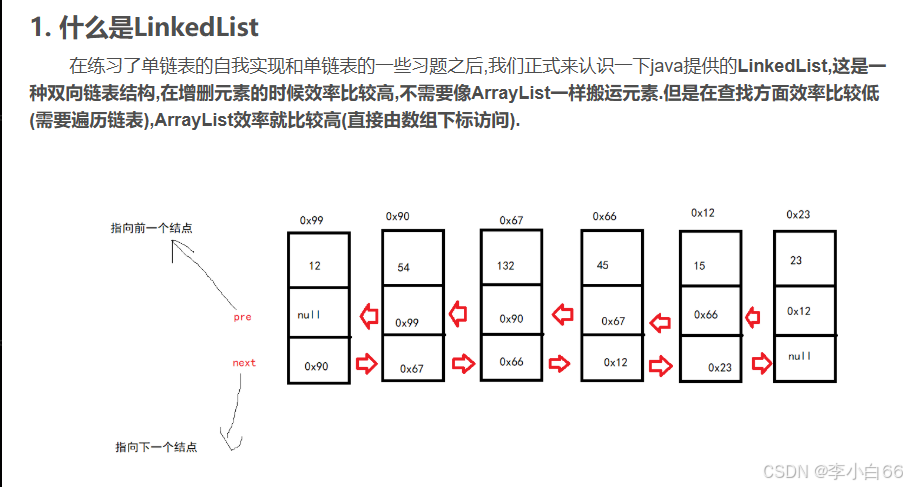
优点:LinkedList 基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址。对于新增和删除操作,LinkedList 比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景。
缺点:因为 LinkedList 要移动指针,所以查询操作性能比较低。
适用场景:
1> 如果需要根据下标来查询元素就使用顺序表
2> 如果经常进行元素的插入和删除操作,适合使用链表
3> 如果容量固定,并且只会添加到尾部,不会引起扩容,优先采用 ArrayList。
| 不同点 | ArrayList | LinkedList |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需修改引用的指向,时间复杂度为O(1) |
| 插入 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
用过 ArrayList 吗?说一下它有什么特点?
1> ArarayList是基于动态数组实现的,当增加到一定程度的时候会自动1.5倍扩容
2> 我们在创建ArrayList实例的时候,不设置参数,我们调用的是无参构造方法,里面是一个空的数组,没有分配内存.
3> 当第一次add的时候,我们才会分配大小为10的内存
4> 高并发的情况下,线程不安全。多个线程同时操作 ArrayList,会引发不可预知的异常或错误。
5> 实现了ReandomAccess接口,可以支持随机访问
6>实现 了Cloneable接口,表面是可以克隆的
有数组了为什么还要搞个 ArrayList 呢?
如果在不明确插入数据数量的情况下,普通数组就难以实现的,因为你不晓得初始化数组大小为多少,而ArrayList可以使用默认的大小,当达到一定程度后,会自动扩容.
栈和队列
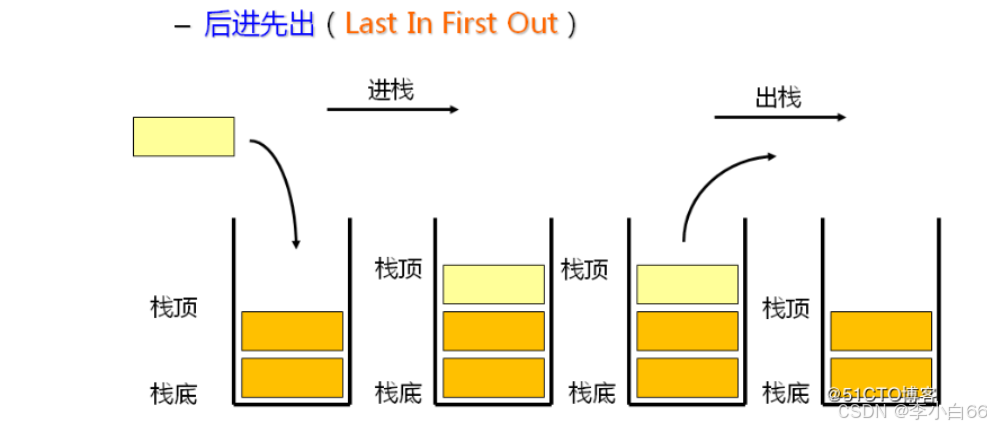
栈: 后进先出的数据结构
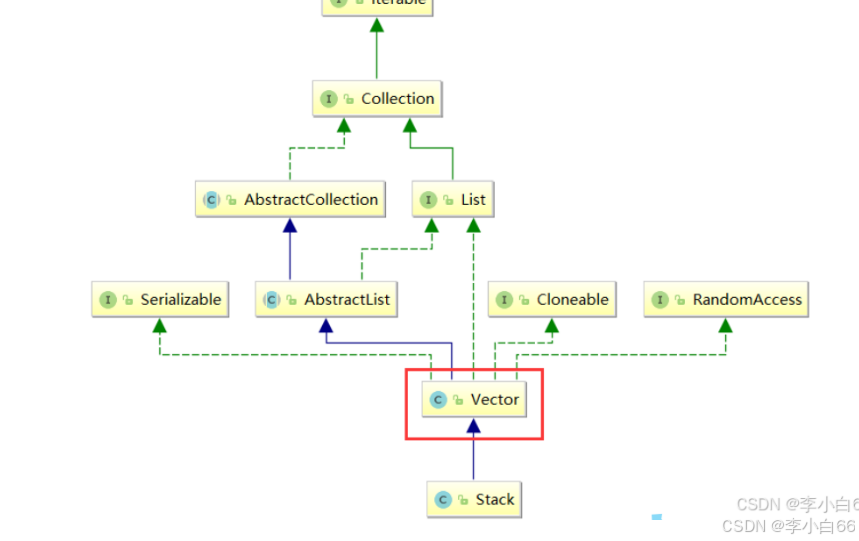
栈、虚拟机栈、栈帧有什么区别呢?
虚拟机栈: 是Java虚拟机(JVM)的一个概念,每个线程运行的时候都会创建自己的虚拟机栈.
简而言之: JVM划分的一块内存.
栈帧: 是用于支持Java虚拟机进行方法调用和方法执行的数据结构,是虚拟机栈的一部分,每次发生方法的调用就会为该方法创建一个新的栈帧并压入栈顶.
简而言之: 方法调用的时候会在虚拟机给方法开辟一块内存.
栈: 是一种规定只能在一端进行插入或者删除的线性表,是一种后进先出的数据结构.
队列: 先进先出的线性表
栈和队列都可以使用数组和链表进行实现
二叉树
一棵二叉树是结点的一个有限集合,该集合:
1. 或者为空
2. 或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。
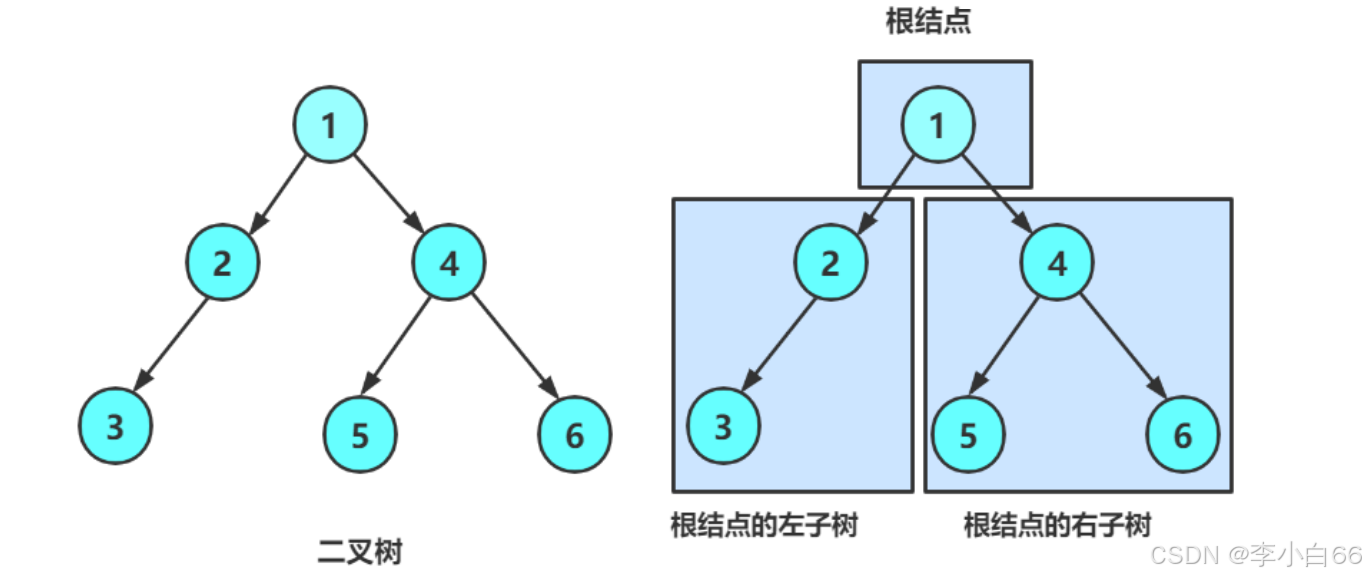
NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点--->根的左子树--->根的右子树。
LNR:中序遍历(Inorder Traversal)——根的左子树--->根节点--->根的右子树。
LRN:后序遍历(Postorder Traversal)——根的左子树--->根的右子树--->根节点。
优先级队列
队列是一种先进先出的数据结构,而如果我们操作的数据带有优先级,我们出队的时候就会先出队优先级最高的元素.是由堆来进行实现的.
堆中某个节点的值总是不大于或不小于其父节点的值;
堆分为大根堆和小根堆
1> 小根堆
根结点一定小于孩子结点->小根堆
2> 大根堆
根结点一定大于孩子结点->大根堆

完全二叉树
优先级队列的扩容机制
如果容量小于64时,是按照oldCapacity的2倍方式扩容的
如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容

PriorityQueue默认情况下是小堆---即每次获取到的元素都是最小的元素
排序算法
插入排序
1. 直接插入排序
思想:
- 从第二个元素开始,假设第一个元素已经是排好序的。
- 将当前元素与前面的元素进行比较,如果比它小就往前进行覆盖,然后将当前元素插入到适当的位置,使得插入后的部分依然是有序的。
- 重复这个过程,直到整个数组有序。
使用i往前走,j用来遍历有序区间
代码:
public static void insertSort(int[] array) {
//从第一个元素开始
for (int i = 1; i < array.length ; i++) {
int j = i - 1;
//保存当前下标的值
int tem = array[i];
//加不加=会对稳定性产生影响,如果一个排序是稳定的就可以变成不稳定的,但是不稳定的不能变成稳定的)
for (; j >= 0 ; j--) {//j所在的区间是有序区间
//如果前面的元素大于tem,就往前移动
if(array[j] > tem) {
array[j+1] = array[j];//不用i的原因是j会一直改变,不一定就是j的前一个
}else {
break;
}
//最后把元素放在前面
//因为循环出来的条件表示必须j要小于0,所以直接传j会下标越界
}
array[j + 1] = tem;
}
}时间复杂度:O(n^2)
稳定性: 稳定
2. 希尔排序
思想:
1. 分组,组内进行排序(直接插入排序)
2. 然后逐渐缩小组数
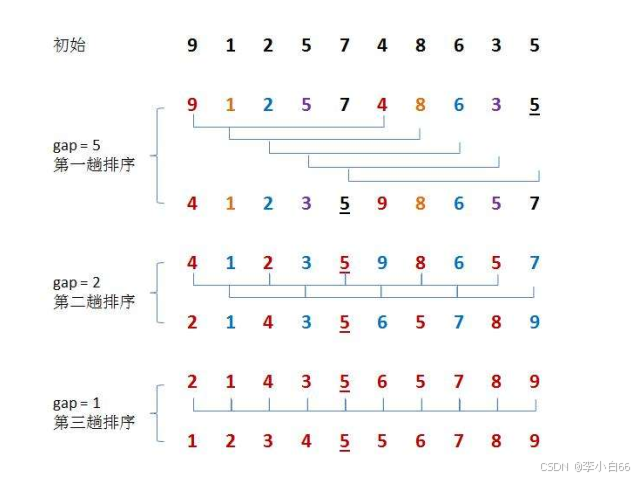
定义一个gap,然后每一次按照gap来进行一次直接插入排序(越有序越快),再减小gap的大小
代码:
public static void shellsort(int[] array) {
//分组
int gap = array.length;
while (gap > 0){
gap /= 2;
//每次分组进行一次直接插入排序
shell(array,gap);
}
}
public static void shell(int[] array,int gap) {
//我们默认第一个元素是有序的
for (int i = gap; i < array.length; i++) {
int temp = array[i];
//j下标等于i前面一个gap的下标值
int j = i - gap;
//然后逐渐和该组前面的数进行比较
for(; j >= 0 ; j -= gap) {
if(array[j] > temp) {
//往前移动一个gap的
array[j + gap] = array[j];
}else {
break;
}
}
array[j + gap] = temp;
}
}时间复杂度: O(n^0.25)~O(1.6n^0.25)
稳定性: 不稳定
选择排序
3. 选择排序
思想:
1. 俩层循环, 外层循环相当于每一次提供一个比较数,内层循环就把比较数后面的数和比较数进行比较,如果比比较数还小,就记录下来下标的值
2. 内层循环完之后,说明我们找到了这一趟最小值的下标,让其和外层循环所指的元素进行交换.
1> 我们定义i,j
2> 记录i下标为初始的min值下标
3> 然后我们让j遍历i后面的元素,和min下标的值做比较,然后返回这一趟找到的最小值的下标
4> 交换i和min下标的元素,每一趟都能找到这一趟最小的元素,然后放到前面去

代码:
public static void selectSort(int[] array) {
for (int i = 0; i < array.length; i++) {
int min = i;
//让j为i+1
for (int j = i + 1; j < array.length; j++) {
if(array[min] > array[j]) {
min = j;//min保存的是每一趟最小值的下标
}
}
int tmp = array[i];
array[i] = array[min];
array[min] = tmp;
}
}时间复杂度:O(n^2)
稳定性: 不稳定
4. 堆排序
思想: 升序排序,每一次建立大根堆,然后第一个元素和最后一个元素进行交换,然后对除了换过来的以外元素进行向下调整建立大根堆,这样每次找到的都是该趟的最大值.相反如果进行降序排序,利用的是小根堆.
1. 创建大根堆,把所有元素放在大根堆里面
2. 定义变量end,作为最后一个有效元素的下标
3. 交换0下标和end下标的值
4. 进行0下标到end下标的向下调整
5. end--;

代码:
//堆排序
private static void creatHeap(int[] array) {
for (int parent = (array.length - 1 - 1) / 2; parent >= 0 ; parent--) {
siftDown(array,parent,array.length);
}
}
//TODO alt+enter
private static void siftDown(int[] array,int parent,int length) {
int child = 2 * parent + 1;
while (child < length) {
if(child + 1 < length && array[child] < array[child + 1]) {
child++;
}
if(array[child] > array[parent]) {
swap(array,child,parent);
parent = child;
child = 2*parent+1;
}else {
break;
}
}
}
public static void heapSort(int[] array) {
//创建大根堆
creatHeap(array);
int end = array.length - 1;
while (end > 0) {
swap(array,0,end);
siftDown(array,0,end);
end--;
}
}时间复杂度: O(n * log(n))
稳定性: 不稳定
交换排序
5. 冒泡排序
思想:
内层循环每次每次从0开始,把小的交换到前面,大的换到后面,每一轮回,把该轮的最大值换到最后.

代码:
public static void bubbleSort(int[] array) {
//i表示趟数
for (int i = 0; i < array.length - 1; i++) {
//j来比较每个数据的大小
for (int j = 0; j < array.length - 1 ; j++) {
if(array[j] > array[j + 1]) {
swap(array,j,j+1);
}
}
}
}优化:
1. 减少j的遍历次数
2. 考虑极端情况,如果有序的话,我们就直接可以结束循环
public static void bubbleSort1(int[] array) {
//i表示趟数
for (int i = 0; i < array.length - 1; i++) {
boolean flag = false;
//j来比较每个数据的大小
// for (int j = 0; j < array.length - 1 - i; j++) {
for (int j = 0; j < array.length - 1 - i ; j++) {//优化1
if(array[j] > array[j + 1]) {
swap(array,j,j+1);
flag = true;
}
}
if (flag == false) {
break;
}
}
}时间复杂度:O(n^2)
稳定性: 不稳定
6. 快速排序
思想:
hoare法
首先我们把第一个元素作为基准值,让left和right分别指向数组的开头和结尾,然后我们让left去寻找比基准值大的数,让right去寻找比基准值小的数,然后我们把找到的下标丢到swap里面进行交换,然后继续上面的操作直到left和right相遇为止.然后我们更新基准值,把相遇位置和之前的基准位置进行交换,这样我们就以基准值作为标准,左边都是比基准值小的,右边都是比基准大的,然后我们再通过递归,在左右区间重复刚刚的操作.
代码:
public static void quickSort(int[] array) {
quick(array,0,array.length - 1);
}
private static void quick(int[] array, int start, int end) {
//走到头了
if (start >= end) {
return;
}
//找到基准值
//相当于二叉树的前序遍历
int pivot = partitionHoare(array,start,end);
//调整左区间
quick(array,start,pivot - 1);
//调整右区间
quick(array,pivot + 1,end);
}
private static int partitionHoare(int[] array, int left, int right) {
//记录第一个元素的值,把它作为基准
int tmp = array[left];
int i = left;
while (left < right) {
while (left < right && array[right] >= tmp) {
right--;
}
while (left < right && array[left] <= tmp) {
left++;
}
//此时左边找到了比基准大的值,右边找到了比基准小的值,那么我们就进行交换
swap(array,right,left);
}
//然后我们把相遇的值和基准的值进行交换
swap(array,i,left);
//返回基准值的下标
return left;
}其他方法的思想:
挖坑法:
先让最左边作为基准值,定义left和right分别指向数组的开头和结尾,然后right一直向后找,去找到比基准值小的数,然后和覆盖left位置的数,同理left一直向前找找到比基准值大的数,然后覆盖right位置的值.当left和right相遇的时候,我们把原先的基准值填空到这个位置,这个位置作为新的基准值,进行下一轮递归.
时间复杂度: O(n^2)
稳定性: 不稳定
归并排序
7. 归并排序
思想: 分治思想,先分解再合并
1> 分成一个个子序列,让子序列有序
2> 然后再进行合并,合并后任然保证有序
即先使每个子序列有序,再使子序列段间有序。
分成小区间,先让小区间有序,然后在进行合并的时候,通过比较然后让合并的大区间也有序
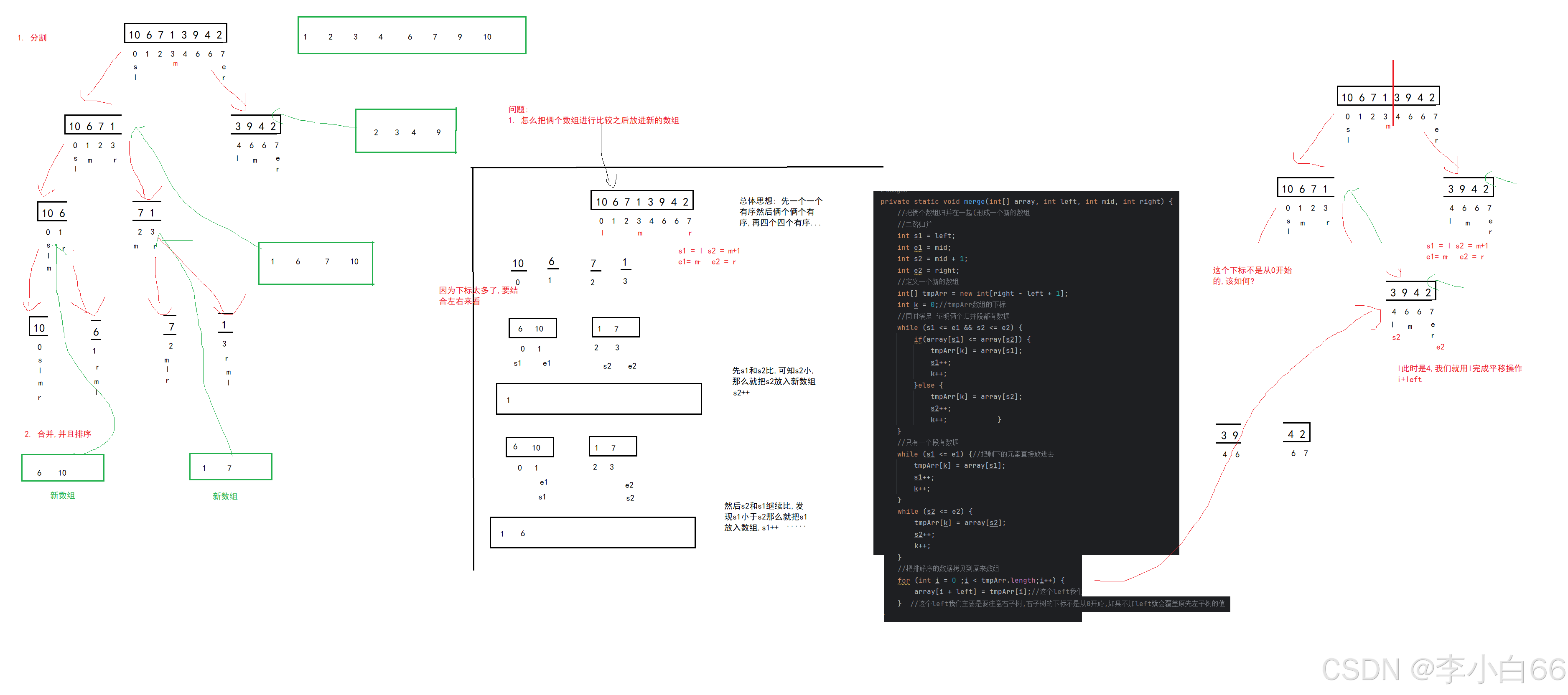
代码:
private static void merge(int[] array, int left,int mid, int right) {
int s1 = left;
int e1 = mid;
int s2 = mid+1;
int e2 = right;
int i = 0;//新数组的下标
//创建一个新的数组
int[] arryTemp = new int[right - left + 1];
//俩端都有元素的时候
while (s1 <= e1 && s2 <= e2) {
//进行比较
if(array[s1] <= array[s2]) {
arryTemp[i++] = array[s1++];
}else {
arryTemp[i++] = array[s2++];
}
}
//此时只有一端有元素,就直接放进数组即可
while (s1 <= e1) {
arryTemp[i++] = array[s1++];
}
while (s2 <= e2) {
arryTemp[i++] = array[s2++];
}
//我们要把元素放进原来的数组里面
for (int j = 0; j < arryTemp.length; j++) {
array[j + left] = arryTemp[j];
}
}
//非递归
private static void mergeSortNor(int[] array) {
//每组多少个数据
int gap = 1;
while (gap <= array.length) {
for (int i = 0; i < array.length; i = i + 2 * gap) {//i每一次循环都在gap个元素的分组下进行排序
//确定左右分组的边界值
int left = i;
int mid = left + gap - 1;
int right = mid + gap;
//防止越界操作,比如left是数组的最后一个元素,我们Mid和right就越界了
if(mid >= array.length) {
mid = array.length - 1;
}
if(right >= array.length) {
right = array.length - 1;
}
//合并左右半区的元素
merge(array,left,mid,right);
}
//增大每组的元素
gap *=2;
}
}
时间复杂度: O(nlgn)
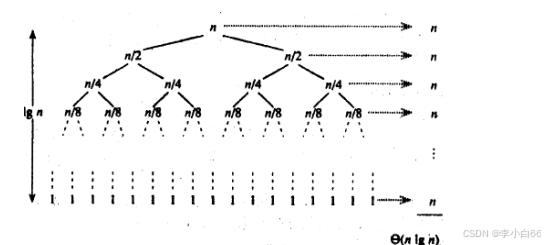
稳定性: 稳定
| 排序方法 | 最好 | 平均 | 最坏 | 空间复杂度 | 稳定性 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 希尔排序 | O(n) | O(n^1.3) | O(n^0.15) | O(1) | 不稳定 |
| 堆排序 | O(n * log(n)) | O(n * log(n)) | O(n * log(n)) | O(1) | 不稳定 |
| 快速排序 | O(n * log(n)) | O(n * log(n)) | O(n^2) | O(log(n)) ~ O(n) | 不稳定 |
| 归并排序 | O(n * log(n)) | O(n * log(n)) | O(n * log(n)) | O(n) | 稳定 |
Map和Set
二叉搜索树的概念,当我们中序遍历它的时候,就可以得到一个有序的从小到大的一组数.
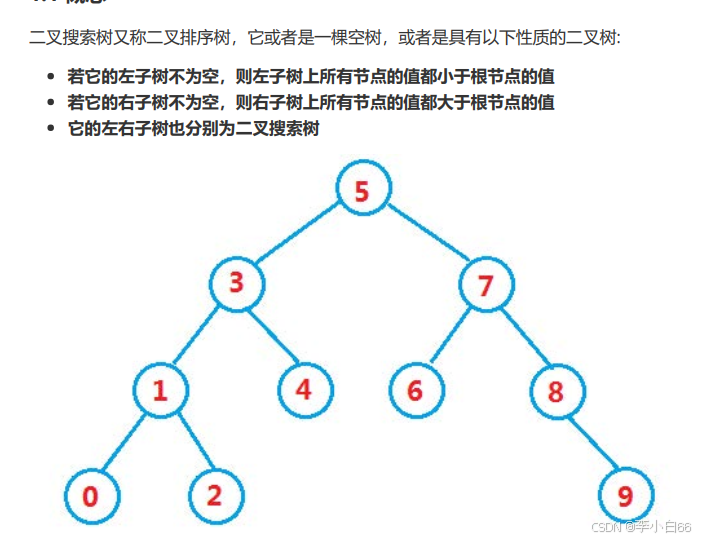
AVL树: 也就是二叉平衡树,这个树是基于二叉搜索树的,它主要是来解决二叉搜索树出现单分支情况,而导致树的高度太高了.解决方式是左旋或者右旋(左右高度差大于等于2就进行).这样就把树的高度给平衡了.
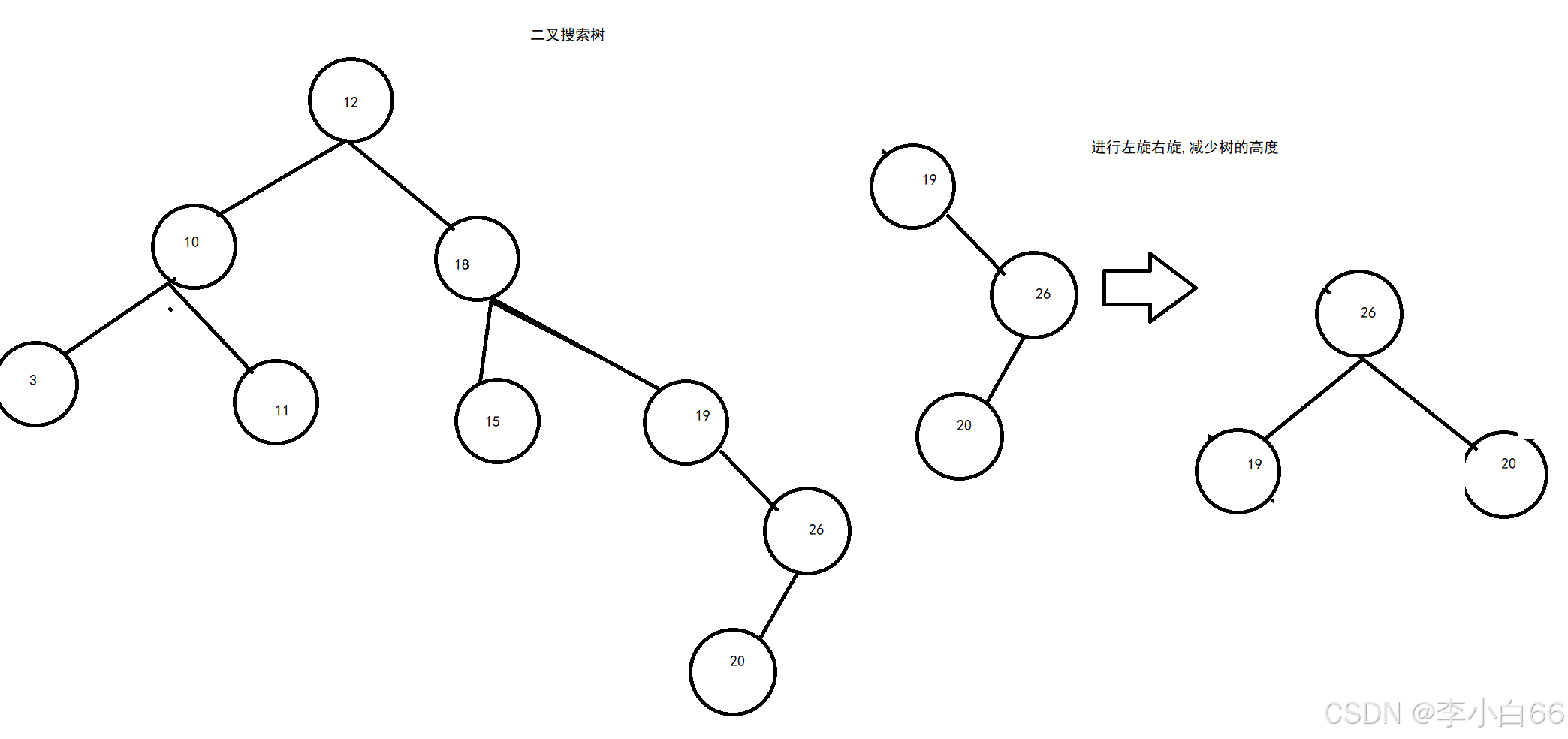
红黑树: 它是基于AVL树进行改良的,给每个节点加上了颜色,然后可以减少左旋右旋的次数来平衡高度.
map和set整体框架介绍
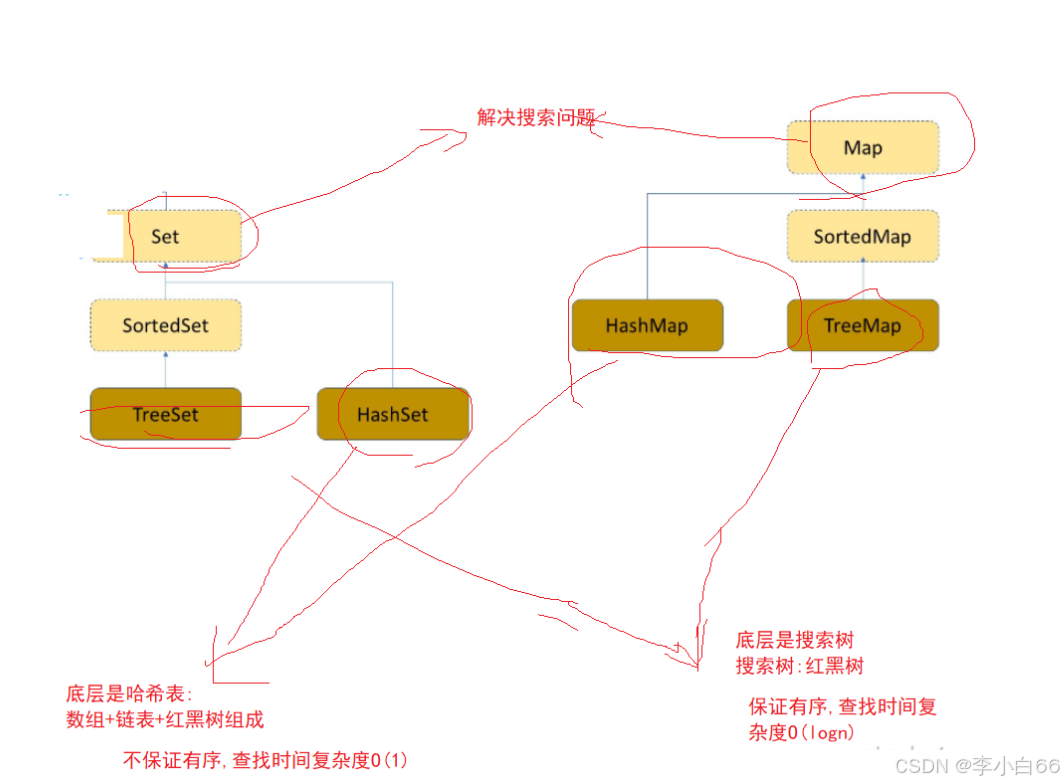
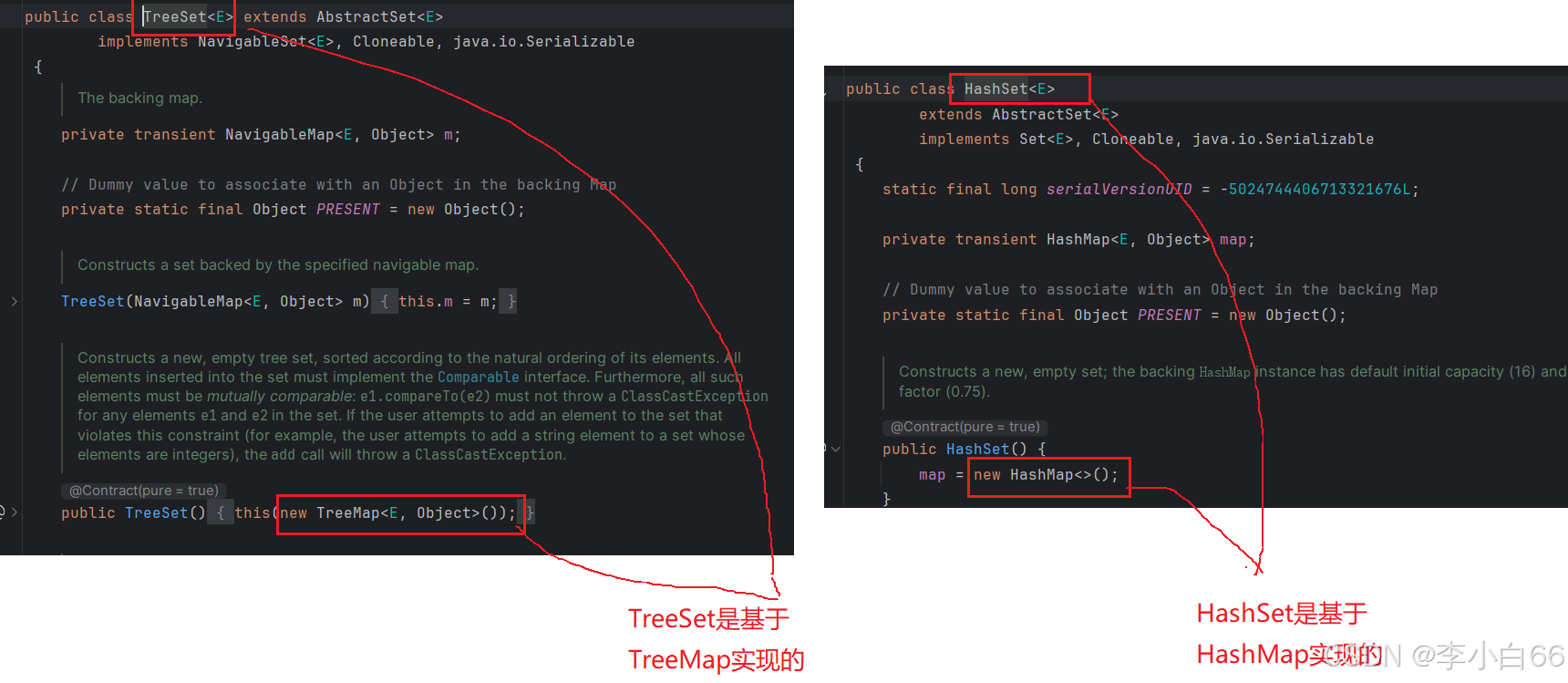
Set是基于Map实现的
map和set的结构
map里面存储的是key-val键值对(K一定是唯一的,不能重复.).比如:单词-该单词搜索的次数
set里面只存储了key(key一定要唯一).比如:快速查找某个名字在不在通讯录中
TreeMap和HashMap的区别
| Map底层结构 | TreeMap | HashMap |
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(logn) | O(1) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要对元素进行比较 | 需要通过哈希函数计算哈希地址 |
| 比较和覆盖 | key必须能够进行比较,否则会抛出ClassCastException异常 | 自定义类型需要覆盖和重写equals和hashCode方法 |
| 应用场景 | 需要Key有序的情况下 | Key是否有序无所谓,主要是搜索的更快 |
TreeSet和HashSet的区别
| Set底层结构 | TreeSet | HashSet |
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(logn) | O(1) |
| 是否有序 | 关于key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1. 先计算key哈希地址 2. 进行插入和删除 |
| 比较和覆写 | Key必须能够进行比较,否则会抛出ClassCastException | 自定义类型需要覆盖hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序并不关系,搜索速度够快 |
哈希表

实现O(1)的查询
不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
我们因此设计了哈希表.哈希表是一种由数组+链表+红黑树组成的数据结构.
插入元素
根据插入元素的关键码,以此函数计算出该元素的存储位置并把元素存放到这个位置上.
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当作元素的存储位置,在结构中按此位置取元素进行比较,如果关键码相等,则搜索成功.
哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
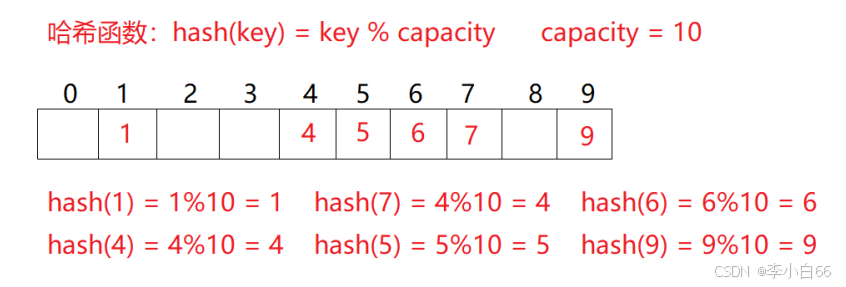
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
hash冲突以及解决方式
当不同关键码通过同一个哈希函数计算出来同一个hash地址,这个就是哈希冲突
解决方式: 冲突的发生是必然的,但我们能做的应该是尽量的降低冲突率
1> 调节负载因子
负载因子: a = 填入表中的元素个数 / 散列表的长度
根据这个公式,如果我们需要降低负载因子的大小,我们只能增加散列表的长度,不能够减小元素个数.
负载因子越大说明产生冲突的概率就越大, java内部负载因子长度为0.75,超过了这个值,就会resize散列表("扩容",但是并不是单纯就扩大数组长度,后面实现hash表的时候会具体解释)
2> 闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。下面介绍找到空位置的方法
1.线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
缺点: 产生冲突的元素都聚在一起了

2. 二次探测
(i表示冲突次数)Hi = (H0 + i^2) % m,产生冲突的元素就分散开来了
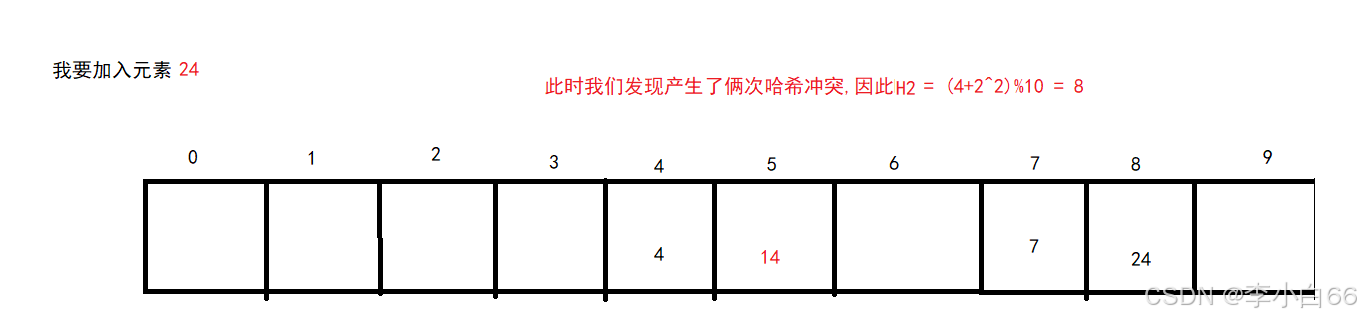
3> 哈希桶
哈希桶: 由数组+链表+红黑树所组成的数据结构
注意: 数组长度大于64并且链表长度大于8的时候就会把链表树化成红黑树

解决冲突:
1. 每个桶的背后是另一个哈希表

2. 每个桶的背后是一棵搜索树
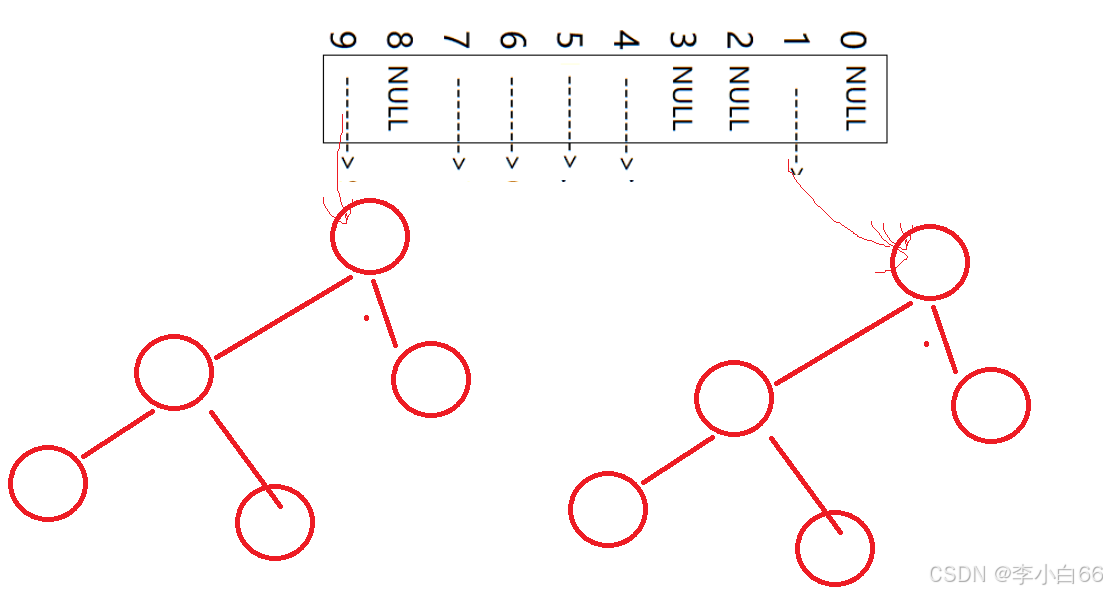
哈希桶的底层实现->把结点放进数组

进行扩容操作:
array = Arrays.copyOf(array,2 * array.length);仅仅进行这样的扩容操作是否有问题呢?(面试题)
答案是肯定的,因为我们扩容之后用的是扩容后的长度进行%,因此放的位置肯定不同,因此需要冲洗hash.
步骤:
1. 先产生一个新的数组(大小是原来的二倍)
2. 遍历原来的数组元素(找每个下标是否连接链表)
3. 根据链表元素和新的哈希函数,我们计算出要插入的新数组的位置
4. 然后我们进行头插法

hash桶和hash表的区别

HashCode的应用--String进阶
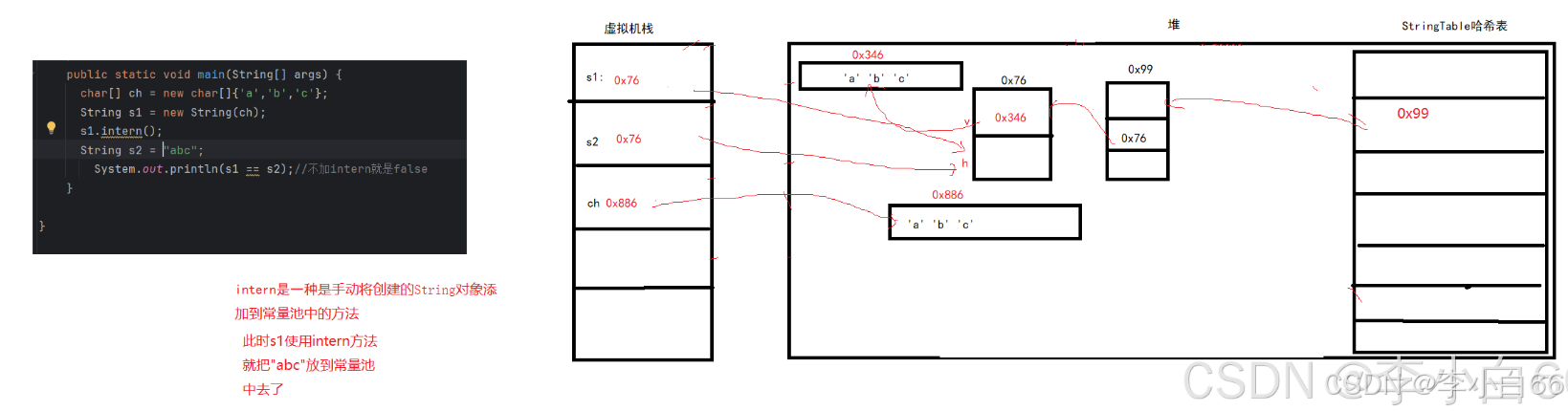
池的概念:
我们先得知道什么是池,池这个东西就是存着我们经常用的一种容器,是为了实现随去随用的,提高运行速度节省内存的容器.
字符串常量池: 字符串常量池在JVM中是StringTable类,实际是一个固定大小的HashTable,java8里面,字符串常量池在堆里面.
这里注意,只要是""引起来的都会放到字符串常量池中.
重点:
1. 创建字符串的俩种方法在虚拟机和堆上是怎么创建的
2. intern方法把字符串手动放进字符串常量池
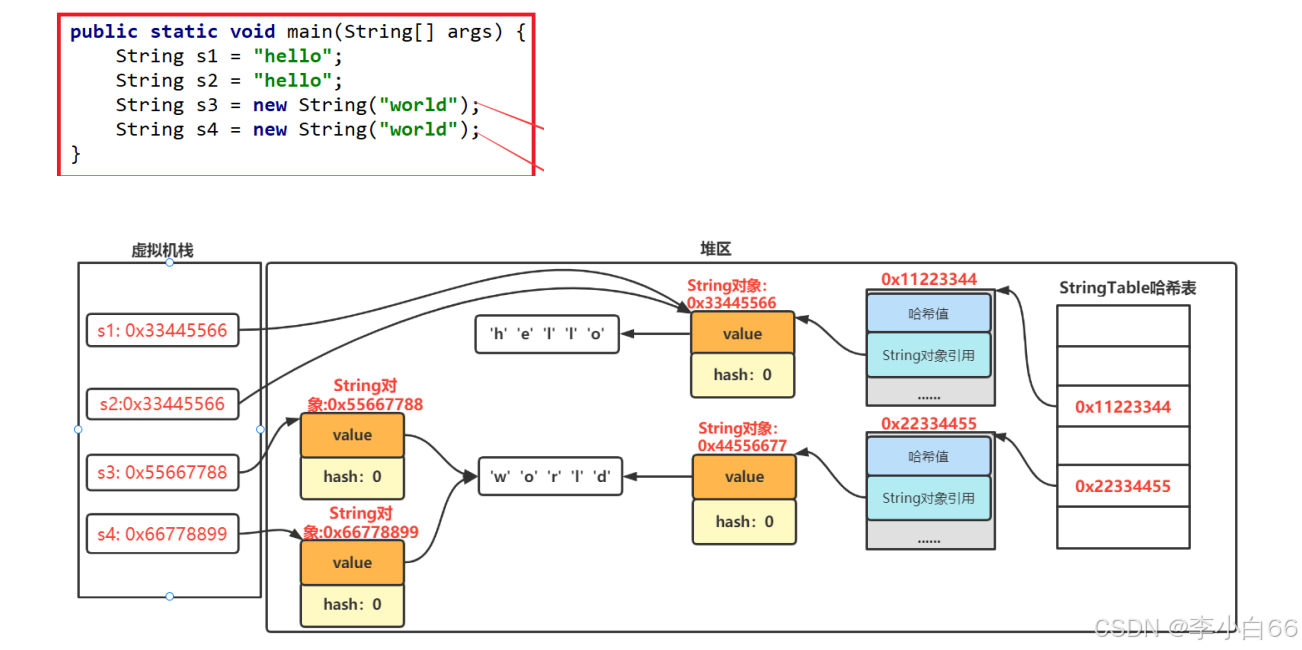
intern
intern 是一个native方法(Native方法指:底层使用C++实现的,看不到其实现的源代码),该方法的作用是手动将创建的String对象添加到常量池中
不加intern
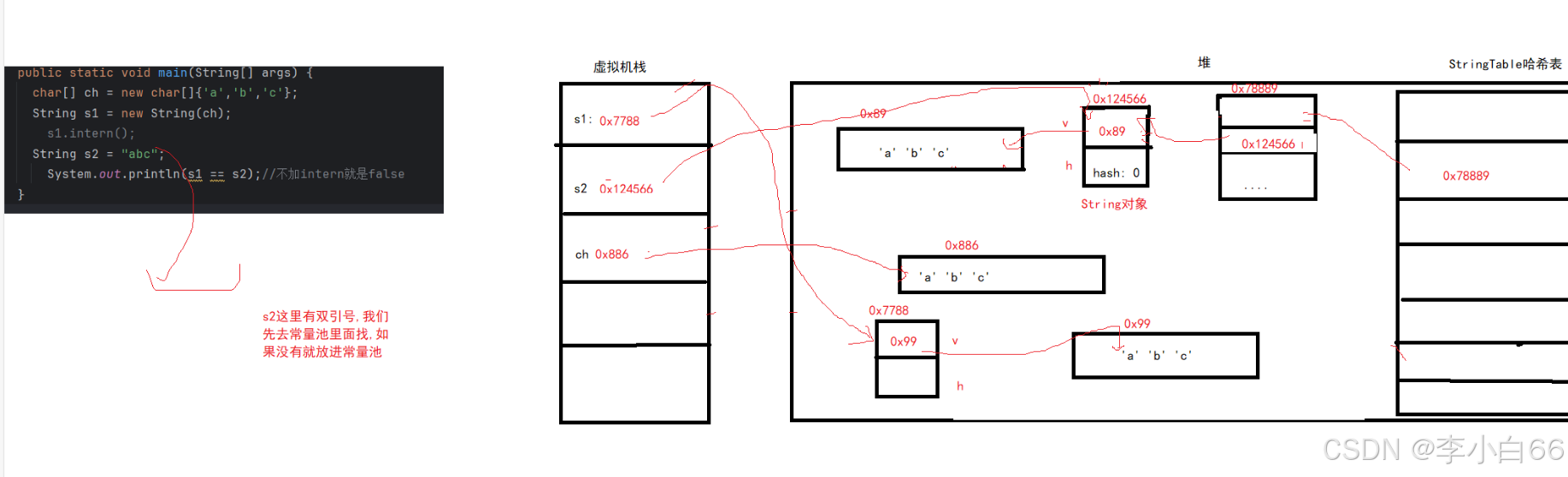
加了intern
反射机制
反射是一种在运行状态下就能知道任意一个类的属性和方法(包括私有的)的一种机制.对于任意一个对象,都能够调用它的任意方法和属性,既然能拿到那么,我们就可以修改部分类型信息;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射(reflection)机制.
关于运行时和编译时
java程序中许多对象在运行时会出现两种类型:运行时类型(RTTI)和编译时类型,例如Person p = new Student();这句代码中p在编译时类型为Person,运行时类型为Student。程序需要在运行时发现对象和类的真实信息。而通过使用反射程序就能判断出该对象和类属于哪些类.
这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制
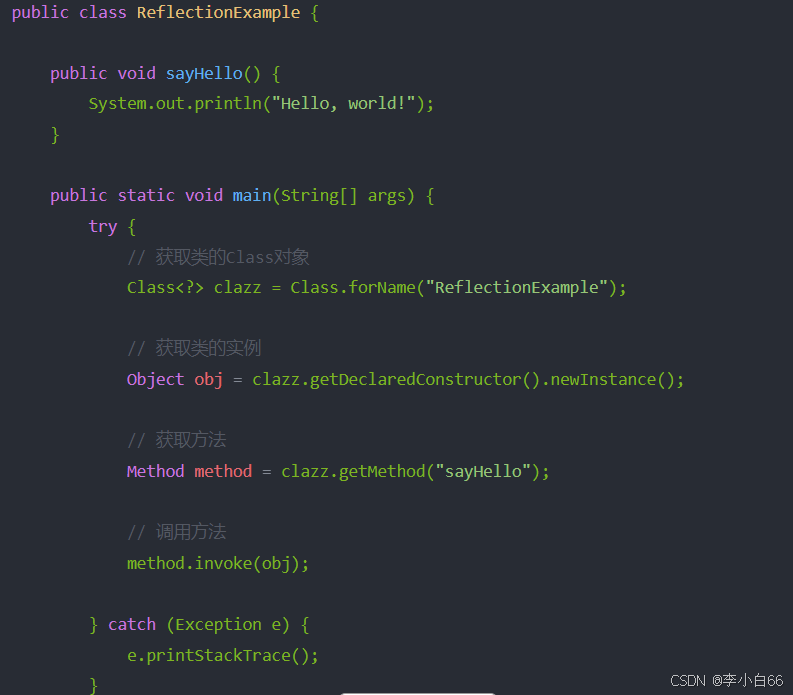
class类
Java文件在被编译之后生成了.class文件 , JVM把.class解析为一个对象,这个对象就是Class类对象(java.lang.Class).
1. 获得class对象 class.forName(类路径)
方式
1)Class.forName(“类的路径”);
2)类名.class
3)对象名.getClass()
4)基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象
2. 获取类的实例 类对象.getDeclaredConstrucetor().newInstance()
3. 获取方法 实例.getMethod(方法名称)
4. 调用方法 方法名.invoke(实例)
应用: JDBC连接数据库
枚举类型是一种组织常量的数据类型
优点: 把常量组织起来统一进行管理
应用: 错误状态码,颜色的划分,状态机...
枚举不能反射
Lambda表达式
(parameters) -> expression或者(parameters)->{statements;}
1> paramaters: 相当于方法中的形参列表(可以省去类型,jvm会自己推断出来).当只有一个推断类型的时候可以省去"()".
2> -> :这个是被应用于的意思
3> 方法体: 相当于函数式接口里面方法的实现,也就是方法体,可以返回值也可以不反回值.

函数式接口:一个接口有且只有一个抽象方法.一般都会在这个接口上声明@FunctionInterface.

lambda表达式的基本使用:
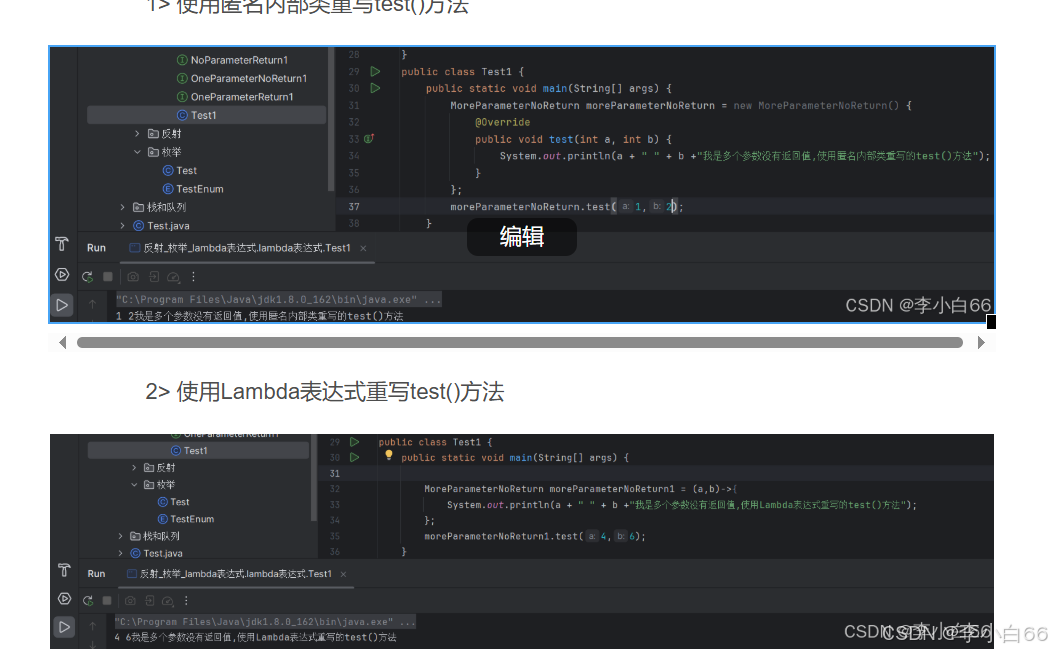
Lambda可以理解为:Lambda就是匿名内部类的简化,实际上是创建了一个类,实现了接口,重写了接口的方法 。
匿名内部类:是Java中一种特殊的内部类,它没有名字,通常用于实现接口或继承类的实例,并且只使用一次。它是一个简化类定义的方式,常用于临时的实现,特别是在需要传递一个类的实例给方法时。
使用匿名内部类和lambda表达式
变量捕获:只要被匿名内部类里面的函数所使用的变量就不能被修改lambda也如此.
因此在匿名内部类里面所使用的变量:1. 要么是常量 2.要么是没有被修改过的变量
Lambda表达式最大的优点就是代码会变的非常的简洁,但是于此同时的缺点就是代码可读性差,补容易进行调试.
通配符: ?
? 用于在泛型的使用,即为通配符
?表示可以接收所有的泛型类型,但是又不能够让用户随意修改。
小结:
1. ?一般作为参数类型使用,T一般用于泛型类,泛型方法的定义来使用.
2. ? 一般不晓得确切类型,因此只能读不能写(修改).T一般晓得确切类型,可以读和修改.
3. 通配符的下界,不能进行读取数据,只能写入数据。通配符的上界,不能进行写入数据,只能进行读取数据。