文章目录
🧸 位图(BitMap)概念

在之前的文章中提到了对于存储数据的数据结构分别为哈希表与红黑树;
在STL当中底层为这两个数据结构所实现的容器分别为map,set与unordered_map,unordered_set;
同时能知道这几个容器实际上是在内存当中存储数据的;
-
腾讯曾经有一道面试题是这样的:
存在40亿个不重复的无符号整数,其中这些数据并未排过序;给定一个无符号整数,如何快速判断这个数是否存在于这40亿个数中;
很显然,这个面试题问的是一个数据在不在的问题;
那么如何能够对数据进行判断在不在的问题?
-
遍历数据逐个判断
遍历数据逐个判断可以理解为一种暴力的解法,这种暴力的解法通过枚举的思路对数据逐个查询;
但实际上该方法的时间复杂度为O(N)[由于需要遍历整组数据];
-
排序后再利用二分查找的方式对数据进行查找
排序所需要的时间复杂度大概为O(NlogN);
利用二分查找的时间复杂度为O(logN);
以上面的两种方法确实可以达到在大量数据中判断一个数据是否存在;
除此之外还有两个问题?
| 本文主要围绕32位机器进行解析 |
-
在内存当中如何对数据进行存储?
已知一个无符号的整型大小为
4byte,而一个字节为8bit;40亿个无符号整型的大小为4 * 108 * 40 = 160 * 108 byte,最终的换算结果为16GB;
而若是使用上面提到的两种方法都不能很好的使数据完整的放置至内存当中;
而若是使用
char来存放数据的话则为16GB / 4 = 4GB,同时在此基础上使用其他算法将数据存入内存当中;那么实际上
4GB放置在内存当中也会变得比较大;那么还有什么方式可以使得能够有效的存放数据?
-
如何使得判断的效率变得更快?
在上述的两种方法中,实际操作起来其总体效率都比较慢;
如何提高判断的效率?
在之前的博客『 C++ - Hash 』闭散列与开散列哈希表详解及其实现 ( 万字 )-CSDN博客 中对于哈希函数提到了一种为直接定址法的方法;
这种方法根据直接定址来判断数据是否存在该组数据当中;
那么这种方法与该面试题有何种关联?
综上所述需要解决两个点:
- 将数据"放置"在内存当中;
- 根据对应算法使得提高判断效率;
实际上可以采用类似哈希函数中直接定址法的思路对问题进行解决;
在计算机当中,判断一个数据是否存在无非是一个 “是不是” 的问题,而 “是不是” 可以使用1或者0来进行判断;
而1与0在内存当中只需要1bit;
所以可以开空间并使用bit为单位来判断这个数据是否存在;

以该图为例,设计一个以char为单位的数组;
已知char类型的大小为1byte,而1byte == 8bit;
若是存在一个数据为14,那么这个数据可以在对应的:
第14/8个char中的第14%8个bit中;
那么已知size_t无符号整型的最大值为4294967295,也就是232-1;
若是需要判断一个无符号整型是否在40亿个数据当中也只需要开辟大约512MB的空间;而判断在不在也只需要直接映射即可,在判断的情况下只需要常数级别的时间复杂度也就是O(1);
这种数据结构被称为位图;
在C++的STL中也有对应的容器,名为std::bitset;
🧸 位图的实现
在上文当中提到了关于位图的概念,那么位图应该如何实现?
🪅 总体框架
对于位图而言总体框架是一个char类型的数组,当然也可以选用int类型作为数组的数据类型(根据需求进行修改);
template <size_t N>
class bitset {
public:
bitset() { _bits.resize(N / 8 + 1, 0); }
void set(size_t x);
void reset(size_t x);
bool test(size_t x) ;
private:
std::vector<char> _bits;
};
为了位图能够合理的开辟内存在框架之中还使用了非类型模板参数N,并根据N来确定内存的大小;
🪅 位图的数据插入
实际上在物理意义上位图由于内存的限制不能使得数据真正意义上的存放至内存当中,只能根据映射的方式使其能够与位图中产生关联;
那么如何使得在一个char类型当中映射单个bit而不影响单个bit?
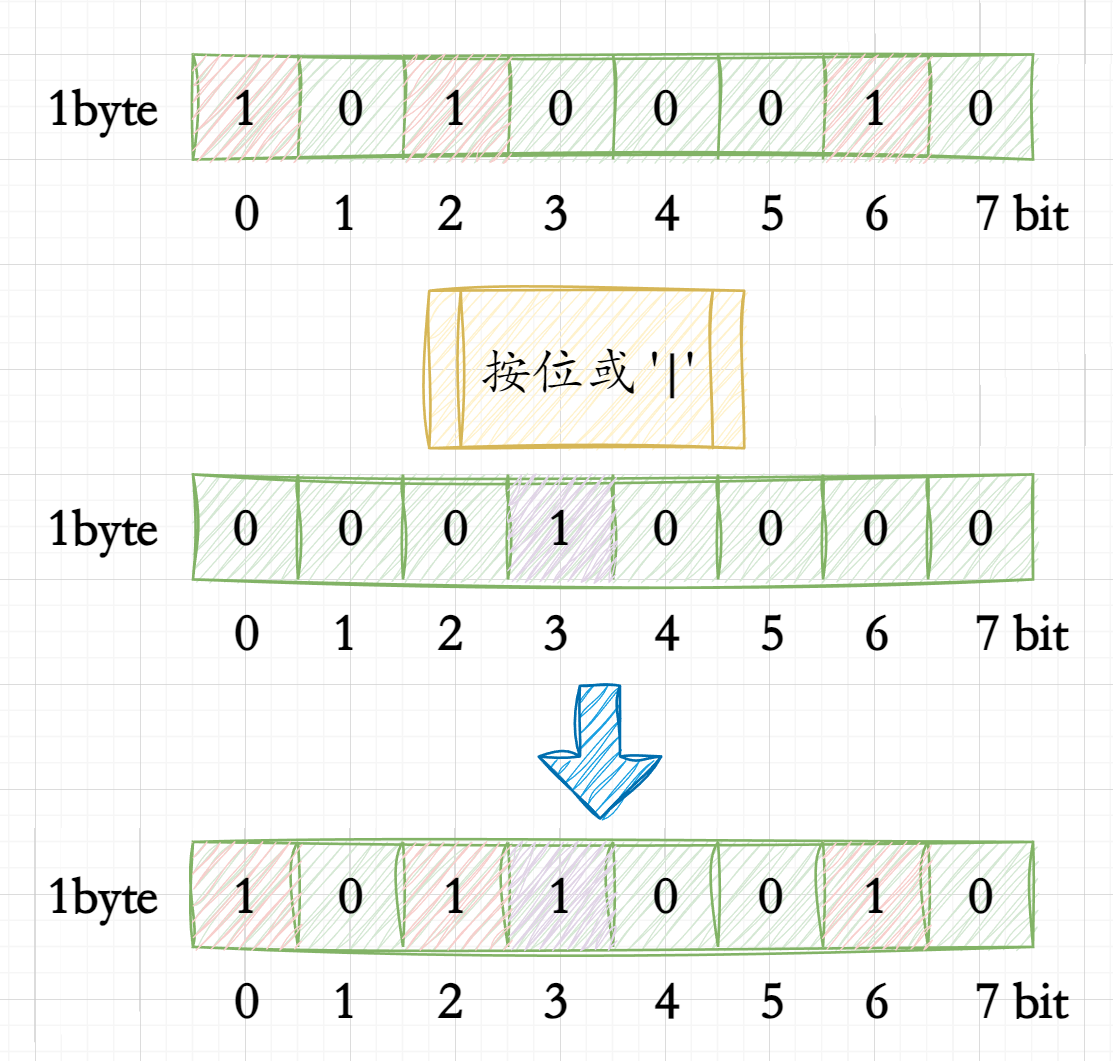
实际上使用按位或'|'即可使得在不影响其他位的情况下对该bit进行置1操作;
而数据只需要使用按位左移<<即可使得数据偏移至单byte中的对应bit使其能够进行上述操作;
-
那么如何计算对应位置?
由于数组的数据类型是
char,且单个char的大小为1byte == 8bit;所以只需要对数据进行
/8操作即可知道数据所在的char位置;而对数据进行
%8操作即可知道数据映射在对应char位置中的bit位置;具体演示参照上文中的 “示例(点击跳转)” ;
-
代码(供参考)
void set(size_t x) { size_t i = x / 8; size_t j = x % 8; /*第i个char中的第j个比特位*/ _bits[i] |= (1 << j); // 运算符优先级 }
当然在代码中应该时刻注意运算符的优先级(位运算的优先级往往是比较低的);
🧩 左移操作与右移操作的区别
- 在上文当中对数据的单个
bit映射位置的设置为什么是左移而不是右移,左移与右移之间有什么区别?是否需要根据机器的情况来调整左移或者右移的操作?
左移和右移虽然听起来是一个方向的位置,若是按字面意思来解左移与右移的话可能对应的则为左移是向左移动,而右移是向右移动;
而实际上在c/C++中,左移或者右移实际上是对于高低值进行移动;
-
左移
向高位移动;
-
右移
向低位移动;
无论是十六进制例0x12ff40,或者十进制例1024,更或者是二进制例0101而言都是左高右低;
以该篇文章而言所实现的位图而言,以我们的角度而言他可能是这样的:

而实际上在内存当中是这样的:

所以并不需要根据机器的情况来调整左移或者右移的操作;
🪅 位图的数据删除
由于在位图当中没有真正的存储数据而是对数据与位图进行一种映射关系;
所以实质上对数据的删除只需要对对应的bit位置进行置0操作即可;
将1左移至对应的位置并对该数据进行按位取反'~',最终将该数据与对应位置进行按位与'&'的操作即可;
-
代码(供参考)
void reset(size_t x) { size_t i = x / 8; size_t j = x % 8; _bits[i] &= ~(1 << j); }
🪅 位图的数据查找
对于数据的查找而言只需要将1左移至对应的偏移量最后与对应位置进行按位与'&'操作即可;
-
代码(供参考)
bool test(size_t x) { size_t i = x / 8; size_t j = x % 8; return _bits[i] & (1 << j); }
当按位与'&'操作的结果为1说明该数据存在,若是为0则不存在;
🪅 位图整体代码(供参考)
#pragma once
#include <iostream>
#include <vector>
namespace MyBitset {
template <size_t N>
class bitset {
public:
bitset() { _bits.resize(N / 8 + 1, 0); }
void set(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
/*第i个char中的第j个比特位*/
_bits[i] |= (1 << j); // 运算符优先级
}
void reset(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}
bool test(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1 << j);
}
private:
std::vector<char> _bits;
};
} // namespace MyBitset
🧸 布隆过滤器(Bloom Filter)概念
在上文中所讲述的是位图所对应的内容;
位图在对于解决数据在不在的问题无论是在效率上还是在内存大小当中都是数据结构中的佼佼者;
但是对应的位图也存在着缺点:
-
优点:
-
内存需求小;
-
效率高(时间复杂度为常数级);
-
-
缺点:
- 只能存储整型类型;
在位图当中普遍都是对大量的整型数据进行映射,判断其是否存在,而遇到其他类型则只能袖手旁观;
可能会有人想到使用哈希中的除留余数法并于位图进行结合;
但是这样的话以字符串类型string为例,使用除留余数法主要是依靠计算ASCII值对数据进行映射存储,而使用该种方法避免不了的为哈希冲突;
在1970年,伯顿·霍华德·布隆(Burton Howard Bloom)提出了一个概率型数据结构,这个数据结构则为今天的布隆过滤器(Bloom Filter);
这个数据结构是利用位图以及哈希算法来实现的;
在实现布隆过滤器中布隆并未想解决哈希冲突,而是降低了哈希冲突的概率;
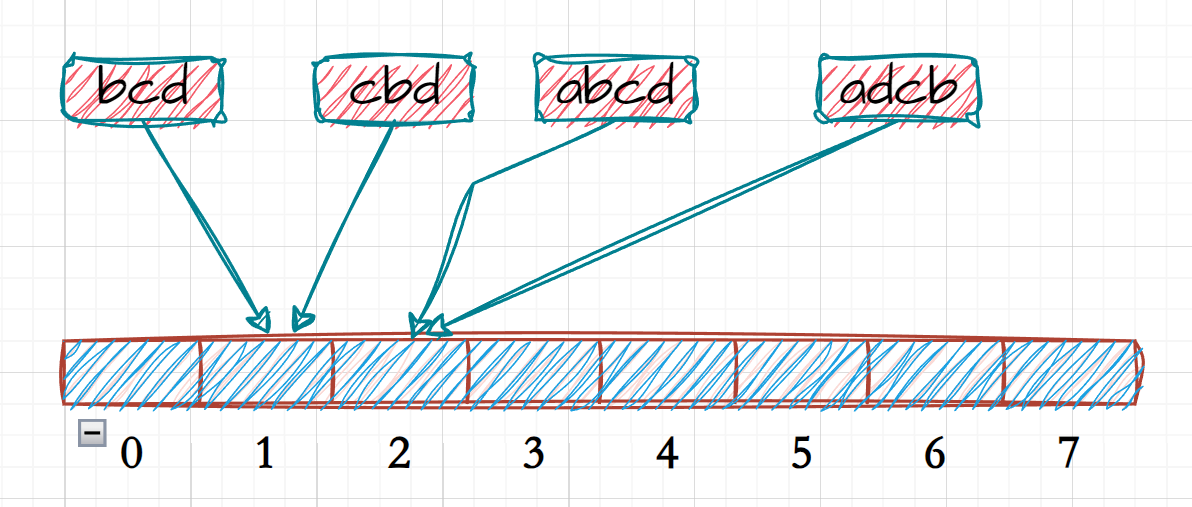
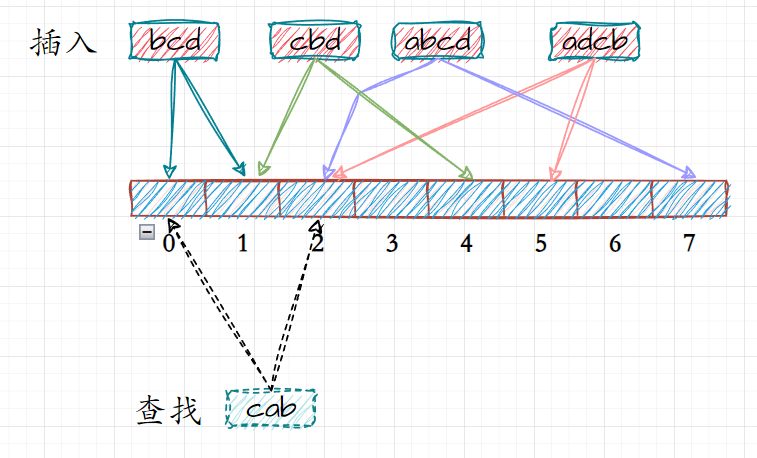
以上图为例,若是只以一种哈希函数来对位图进行映射,那么当发生哈希冲突时,由于例如相同字符而字符顺序不同的两个字符串而言极容易发生冲突,其将会被对应的位图的去重性而无法判断该数据是否存在;
那么在一个哈希函数的基础上再加上几个哈希函数那么由于哈希函数的不同,对应每个哈希函数都需要映射一个位置,那么其将大大减小哈希冲突的概率;
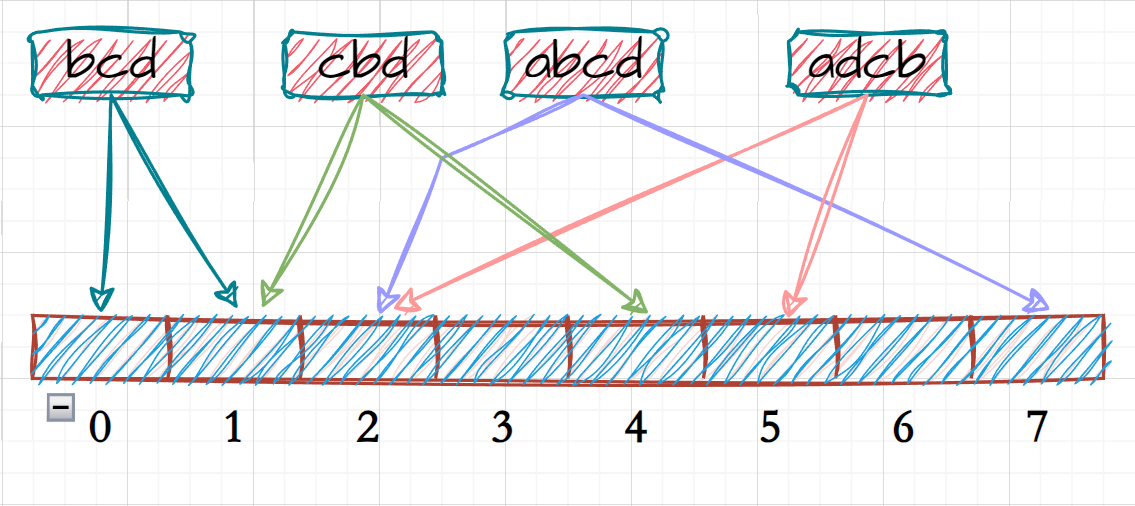
以该图为例,该图演示了当使用两个哈希函数对数据进行映射时,其在一个哈希函数中可能发生冲突,但另一个哈希函数不一定发生同样的冲突,这种方式有效的降低了在位图当中的哈希冲突,即为布隆过滤器;
🪅 哈希函数的个数及布隆过滤器的长度
在上文当中提到了对于布隆过滤器的基本概念,其本质是通过多个哈希函数将同一个字符串映射至位图中的不同位置从而降低布隆过滤器中的整体的哈希冲突概率;
同时根据上文的内容当中可以得知,实际上布隆过滤器不仅与概念有关,而且与对应的哈希函数个数与布隆过滤器长度的选择有关;
-
举个例子
存在
100个string数据,若是在一个布隆过滤器当中使用4个哈希函数作为布隆过滤器的哈希函数,而在布隆过滤器的选择上开辟了400bit的空间;那么在这种情况下由于数据的插入将会引来大量的哈希冲突,大量的
bit都将被置为1从而导致每次的判断都为可能存在;故实际上布隆过滤器的长度
m>=n*k,其中m为长度,n为数据个数,k为哈希函数的个数;
而对于哈希函数的个数也是如此;
以降低误判率而言,哈希函数的个数越多越好,但实际上越多的哈希函数虽然能够有效降低布隆过滤器中的误判率,但随着哈希函数的个数越多,为了对应的降低误判率,其布隆过滤器的长度也要变得更大,从而增大了整体的内存开销;
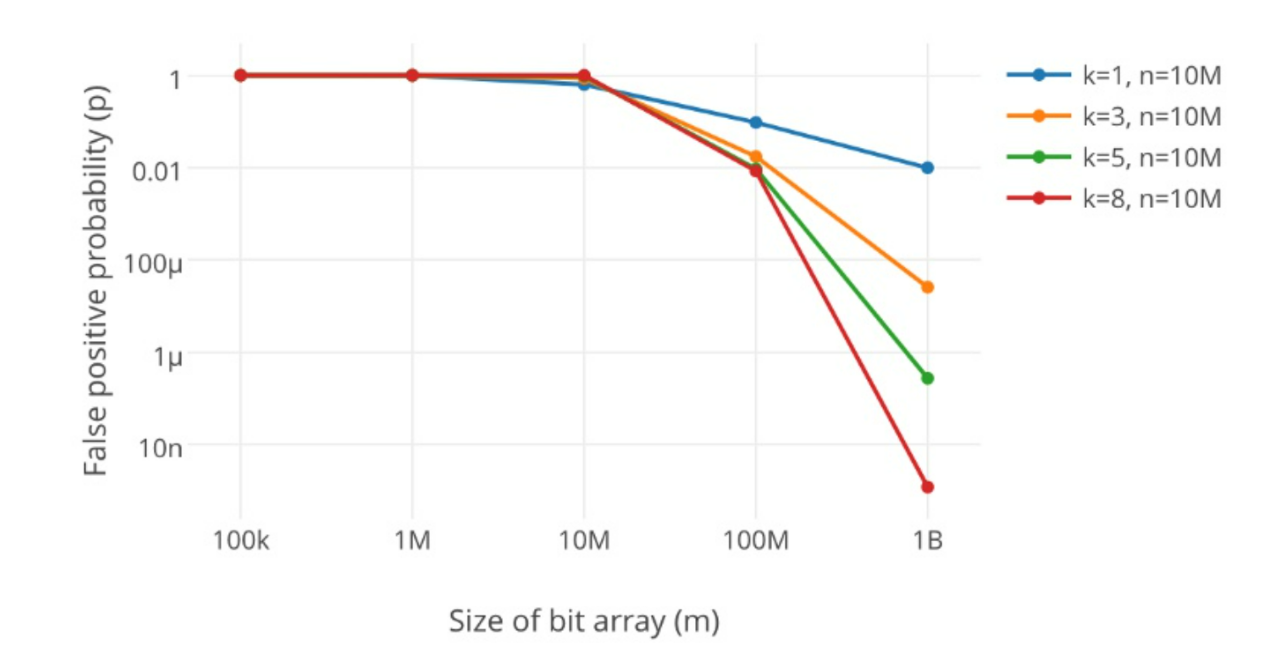
其中p为误判率,k为哈希函数个数,m为布隆过滤器的长度,n为插入元素个数;
通常情况下,哈希函数的个数与布隆过滤器的长度都可以使用公式进行计算:
-
哈希函数个数
k = m n ln ( 2 ) k = \frac{m}{n} \ln(2) k=nmln(2)
-
布隆过滤器长度
m = − n ln p ( ln 2 ) 2 m = - \frac{n \ln p}{(\ln 2)^2} m=−(ln2)2nlnp
🧸 布隆过滤器的实现
在上文当中提到了布隆过滤器采用的是多个哈希算法与位图的结合;
在本文章中着重实现哈希函数数量为3的布隆过滤器;
🪅 总体框架
在上文当中提到了布隆过滤器的大致原理;
实际上就是采用多个哈希函数使同一个字符串根据不同的哈希函数规则映射至不同的位置,从而降低布隆过滤器中整体的哈希冲突;
而本文章中重点实现使用3个哈希函数实现布隆过滤器;
所使用的哈希函数分别为DKBRHash,APHash及DJBHash;
#pragma once
#include "BitSet.h"
struct _BKDR__Hash {
size_t operator()(const std::string& key) {
size_t hash = 0;
for (auto e : key) {
hash *= 31;
hash += e;
}
return hash;
}
};
struct _AP__Hash {
size_t operator()(const std::string& key) {
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++) {
char ch = key[i];
if ((i & 1) == 0) {
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
} else {
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct _DJB__Hash {
size_t operator()(const std::string& key) {
size_t hash = 5381;
for (auto ch : key) {
hash += (hash << 5) + ch;
}
return hash;
}
};
template <size_t N, class K = std::string, class Hash1 = _BKDR__Hash , class Hash2 = _AP__Hash,
class Hash3 = _DJB__Hash>
class BloomFilter {
public:
void set(const K& key);
bool test(const K& key);
private:
const static size_t _X = 5;
MyBitset::bitset<N*_X> _bits; // N为数据量最多
};
在模板参数中定义一个非类型模板参数N,该非类型模板参数作为处理数据时的数据个数;
从该段代码中可以看出,其成员函数重点为一个位图_bits及对应的一个乘数因子_X;
其中乘数因子_X决定了最终布隆过滤器的长度;
-
根据公式
k = m n ln ( 2 ) k = \frac{m}{n} \ln(2) k=nmln(2)
可以推断出最终的布隆过滤器的长度大概为
4.3n;此处实现为向上取整将乘数因子的大小控制在
5(可根据项目条件酌情替换);
该处将哈希函数以仿函数的形式定义,并将该仿函数声明于模板参数中作为缺省参数,分别为Hash1,Hash2,Hash3;
🪅 布隆过滤器的数据插入
布隆过滤器的数据插入只需要调用对应的仿函数(哈希函数),并调用位图中的set接口将其映射至位图中的对应部分即可;
void set(const K& key){
size_t len = N * _X;
size_t hash1 = Hash1()(key) % len;
_bits.set(hash1);
size_t hash2 = Hash2()(key) % len;
_bits.set(hash2);
size_t hash3 = Hash3()(key) % len;
_bits.set(hash3);
}
🪅 布隆过滤器的数据查找
关于布隆过滤器的数据查找而言只需要使用与插入同样的逻辑即可;
bool test(const K& key){
size_t len = N * _X;
size_t hash1 = Hash1()(key) % len;
if(!_bits.test(hash1)){
return false;
}
size_t hash2 = Hash2()(key) % len;
if (!_bits.test(hash2)) {
return false;
}
size_t hash3 = Hash3()(key) % len;
if (!_bits.test(hash3)) {
return false;
}
else{
return true;
}
}
当然实际上布隆过滤器的数据查找在判断是否存在中仍有误判的概率;
-
数据存在
数据存在是存在误判的概率,所以在布隆过滤器当中当数据返回结果判定为数据存在时其真正的意义是 “可能存在”;
由于布隆过滤器是将同一个数据通过不同的哈希函数映射至位图中不同的位置;
真正在对数据进行查找时,无法真正判断该数据是否存在于该位图当中;
以该图为例,当一个数据不存在时,实际上其对应映射的位置可能被其他数据所映射,从而导致了返回其存在的误判;
故实际上在布隆过滤器当中对 “存在” 的概念是不确定的;
-
数据不存在
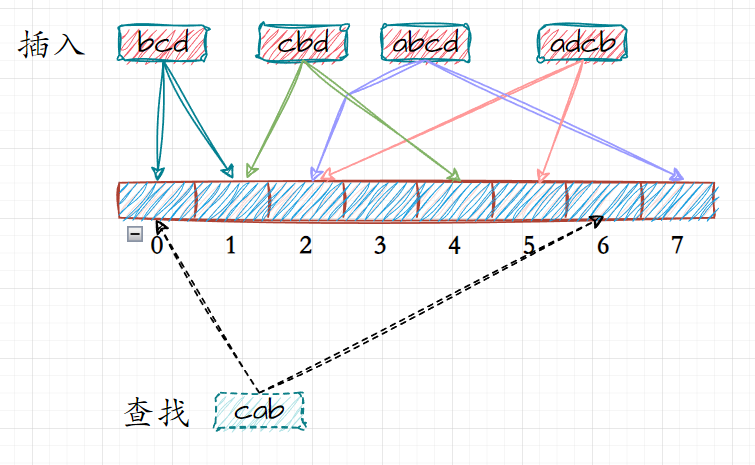
相对的,对于布隆过滤器而言,数据不存在才是准确且值得信任的;
当一个数据不存在时,其数据对应所映射的位置也必定为空,当其映射的位置其中的一个位置为空时则表示该数据不存在于位图当中;
以该图为例;
🪅 布隆过滤器的数据删除
在布隆过滤器当中实际上是不能进行删除的,而对于有些布隆过滤器的变种而言其可以进行数据的删除操作,这里不进行阐述;
-
为什么布隆过滤器不支持数据的删除操作?
在上文中关于布隆过滤器的查找中的"数据是否存在"问题中对于误判有着详细的解释;
由于无法百分百确认一个数据在布隆过滤器中的位图当中是否存在,所以在布隆过滤器当中不能对数据进行随意的删除;
与上文的例子相符,假设一个数据不存在,而该数据所对应映射的位置恰巧有其他数据的映射,那么则会判断该数据 “可能存在”;
而若是对这个 “可能存在” 的数据进行删除则会影响其他数据;
可能有些人设想在实现布隆过滤器当中使其加入一个关于计数的功能使其能够在布隆过滤器当中对数据进行计数删除操作;
而实际上,若是增加位的计数器从而达到能够对数据进行数据的方法确实可以在某种程度上达到一定效果;
而布隆过滤器中所设置的计数器是按照二进制展开从而达到计数的目的,当数据量大过其本身能够计数的大小时,其将会进行 “计数器回绕”;
-
例:
101 -> 110 -> 111 -> 000
这将完全影响对应的秩序;
故对于一般的布隆过滤器而言,其不能进行数据的删除操作;
🪅 布隆过滤器整体代码(供参考)
#pragma once
#include "BitSet.h"
struct _BKDR__Hash {
size_t operator()(const std::string& key) {
size_t hash = 0;
for (auto e : key) {
hash *= 31;
hash += e;
}
return hash;
}
};
struct _AP__Hash {
size_t operator()(const std::string& key) {
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++) {
char ch = key[i];
if ((i & 1) == 0) {
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
} else {
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct _DJB__Hash {
size_t operator()(const std::string& key) {
size_t hash = 5381;
for (auto ch : key) {
hash += (hash << 5) + ch;
}
return hash;
}
};
template <size_t N, class K = std::string, class Hash1 = _BKDR__Hash , class Hash2 = _AP__Hash,
class Hash3 = _DJB__Hash>
class BloomFilter {
public:
void set(const K& key){
size_t len = N * _X;
size_t hash1 = Hash1()(key) % len;
_bits.set(hash1);
size_t hash2 = Hash2()(key) % len;
_bits.set(hash2);
size_t hash3 = Hash3()(key) % len;
_bits.set(hash3);
}
bool test(const K& key){
size_t len = N * _X;
size_t hash1 = Hash1()(key) % len;
if(!_bits.test(hash1)){
return false;
}
size_t hash2 = Hash2()(key) % len;
if (!_bits.test(hash2)) {
return false;
}
size_t hash3 = Hash3()(key) % len;
if (!_bits.test(hash3)) {
return false;
}
else{
return true;
}
}
private:
const static size_t _X = 5;
MyBitset::bitset<N*_X> _bits; // N为数据量最多
};
其中"BitSet.h"文件参考上文当中的位图;
🪅 布隆过滤器的应用
布隆过滤器(Bloom Filter),其功能的应用范围可以以字面意思进行理解;
其为 “过滤器”,即实际上其本身的功能并不是将数据进行存储,而是对数据进行一个过滤的作用,例如使用布隆过滤器减少磁盘IO或者网络请求;
当一个数据在布隆过滤器当中被判断不存在,由于不存在在布隆过滤器中是一个肯定的,可以信任的返回;
所以当一个数据被判断不存在时,其就可以不需要再进行后续的查询请求;
除了上述应用以外,由于其存在误判性,其也可以在一些可以对误判进行容忍的场景下进行应用;