一、RPC
RPC 框架是分布式领域核心组件,也是微服务的基础。 RPC (Remote Procedure
Call)全称是远程过程调用,相对于本地方法调用,在同一内存空间可以直接通过方法栈实现调用,远程调用则跨了不同的服务终端,并不能直接调用。
RPC框架 要解决的就是远程方法调用的问题,并且实现调用远程服务像调用本地服务一样简单,框架内部封装实现了网络调用的细节。
1. 通信协议选择
根据不同的需求来选择通信协议,UDP是不可靠传输,一般来说很少做为RPC框架的选择。
TCP和HTTP是最佳选择。
HTTP虽然有很多无用的头部信息,传输效率上会比较低,但是HTTP通用性更强,跨语言,跨平台,更易移植。
TCP可靠传输,需要自定义协议,传输效率更高,但是通用性不强。
1.1 HTTP/1.0和HTTP/1.1的区别
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
- 缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
- 带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
- Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
- 长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
1.2 HTTP/1.1和HTTP/2的区别
- 新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
- 多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
- header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- 服务端推送(server push)HTTP2.0也具有server push功能。
grpc采用了http2协议,由于http的通用性,所以现在的几乎所有的rpc框架都支持grpc
2. 序列化协议
数据在网络中传输,必须是二进制的,所以我们需要先将传输的对象进行序列化之后,才能传输。
接收方通过反序列化将数据解析出来。
序列化协议有XML、 JSON、Protobuf、Thrift 等,Golang 原生支持的 Gob 协议。
3. 编解码
如果使用TCP,我们需要定义数据传输的格式,防止在传输过程中出现的粘包,拆包等问题。
假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下四种情况:
- 服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包
- 服务端一次接受到了两个数据包,D1和D2粘合在一起,称之为TCP粘包
- 服务端分两次读取到了数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这称之为TCP拆包
- 服务端分两次读取到了数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余部分内容D1_2和完整的D2包。
特别要注意的是,如果TCP的接受滑窗非常小,而数据包D1和D2比较大,很有可能会发生第五种情况,即服务端分多次才能将D1和D2包完全接收,期间发生多次拆包。
自定义格式可以使用定长的头和不定长的体,标识数据长度即可。
暂时无法在飞书文档外展示此内容
- magic number : 通信双方协商的一个暗号 魔数的作用是用于服务端在接收数据时先解析出魔数做正确性对比。如果和协议中的魔数不匹配,则认为是非法数据
- version : 不同版本的协议对应的解析方法可能是不同的,应对业务变化需求
- full length: 记录了整个消息的长度
- messageType:普通请求、普通响应、心跳等,根据消息类型做出不同的解析
- compress: 序列化的字节流,还可以进行压缩,使得体积更小,在网络传输更快,不一定要使用
- serialize:序列化方式,比如json,protostuff,glob等
- request id:每个请求分配好请求Id,这样响应数据的时候,才能对的上
- body:具体的数据
二、注册中心
1.Nacos
可以做服务发现、服务注册
前置:
go get -u github.com/nacos-group/nacos-sdk-go 启动nacos-server
1.服务注册
// 服务注册实例
func RegisterService(namingClient naming_client.INamingClient, serviceName string, host string, port uint64) error {
_, err := namingClient.RegisterInstance(vo.RegisterInstanceParam{
Ip: host,
Port: port,
ServiceName: serviceName,
Weight: 10,
Enable: true,
Healthy: true,
Ephemeral: true,
Metadata: map[string]string{"idc": "shanghai"},
//ClusterName: "cluster-a", // 默认值DEFAULT
//GroupName: "group-a", // 默认值DEFAULT_GROUP
})
return err
}
2.服务获取
/*获取健康实例,加权轮训*/
func GetService(namingClient naming_client.INamingClient, serviceName string) (host string, port uint64, err error) {
instance, err := namingClient.SelectOneHealthyInstance(vo.SelectOneHealthInstanceParam{
ServiceName: serviceName,
//GroupName: "group-a", // 默认值DEFAULT_GROUP
//Clusters: []string{"cluster-a"}, // 默认值DEFAULT
})
if err != nil {
return "", uint64(0), err
}
return instance.Ip, instance.Port, nil
}
3.框架修改
客户端连接时connect修改
//更改为从注册中心获取
cli, err := register.CreateNacosClient()
if err != nil {
panic(err)
}
//服务名
host, port, err := register.GetService(cli, c.ServiceName)
if err != nil {
panic(err)
}
addr := fmt.Sprintf("%s:%d", host, int(port))
服务端注册时register修改
//使用nacos进行注册
cli, err := register.CreateNacosClient()
if err != nil {
panic(err)
}
err = register.RegisterService(cli, name, s.Host, uint64(s.Port))
if err != nil {
panic(err)
}
2.etcd
2.1简介
etcd是使用Go语言开发的一个开源的、高可用的分布式key—value存储系统,可以用于配置共享和服务的注册和发现
2.2etcd具有以下的特点:
1.完全复制:集群中的每个节点都可以使用完整的存档
2.高可用性:Etcd可用于避免硬件的单点故障或网络问题
3.一致性:每次读取都会返回跨多主机的最新写入
4.简单:包括一个定义良好、面向用户的API(gRPC)
5.安全:实现了带有可选的客户端证书身份验证的自动化TLS
6.快速:每秒10000次写入的基准速度
7.可靠:使用Raft算法实现了强一致、高可用的服务存储目录
官方文档地址:https://etcd.io/
2.3前置
go get go.etcd.io/etcd/client/v3
3.服务注册抽象
实现接口,框架即可集成不同的服务注册方式
type MyRegister interface {
CreateCli(option Option) error
RegisterService(serviceName string, host string, port int) error
GetValue(serviceName string) (string, error)
Close() error
}
tcp服务端注册修改,添加设置注册类型的方法
func (s *MyTcpServer) SetRegister(registerType string, option register.Option) {
s.RegisterType = registerType
s.RegisterOption = option
if s.RegisterType == "nacos" {
s.RegisterCli = ®ister.NacosRegister{}
}
if s.RegisterType == "etcd" {
s.RegisterCli = ®ister.EtcdRegister{}
}
}
tcp客户端连接修改,在代理调用时设置注册器
func (p *MyTcpClientProxy) Call(ctx context.Context, serviceName string, methodName string, args []any) (any, error) {
client := NewTcpClient(p.option)
client.ServiceName = serviceName
if p.option.RegisterType == "etcd" {
client.RegisterCli = ®ister.EtcdRegister{}
}
if p.option.RegisterType == "nacos" {
client.RegisterCli = ®ister.NacosRegister{}
}
p.client = client
err := client.Connect()
if err != nil {
return nil, err
}
for i := 0; i < p.option.Retries; i++ {
result, err := client.Invoke(ctx, serviceName, methodName, args)
if err != nil {
if i >= p.option.Retries-1 {
log.Println(errors.New("already retry all time"))
client.Close()
return nil, err
}
//睡眠一会,再重试
continue
}
client.Close()
return result, nil
}
return nil, errors.New("retry time is 0")
}
用户调用修改:
Server :
tcpServer := rpc.NewTcpServer("localhost", 9223)
tcpServer.SetRegister("nacos", register.Option{
DialTimeout: 5000,
NacosServerConfig: []constant.ServerConfig{
{
IpAddr: "127.0.0.1",
ContextPath: "/nacos",
Port: 8848,
Scheme: "http",
},
},
})
Client
option.RegisterType = "nacos"
option.RegisterOption = register.Option{
DialTimeout: 5 * time.Second,
NacosServerConfig: []constant.ServerConfig{
{
IpAddr: "127.0.0.1",
ContextPath: "/nacos",
Port: 8848,
Scheme: "http",
},
},
NacosClientConfig: constant.NewClientConfig(
constant.WithNamespaceId(""), //当namespace是public时,此处填空字符串。
constant.WithTimeoutMs(5000),
constant.WithNotLoadCacheAtStart(true),
constant.WithLogDir("/tmp/nacos/log"),
constant.WithCacheDir("/tmp/nacos/cache"),
constant.WithLogLevel("debug"),
),
}
proxy := rpc.NewMyTcpClientProxy(option)
三、网关实现
在微服务的场景下,服务因为分布在不同的服务器上,但是用户在访问的时候,不可能去维护这成百上千的入口,希望有统一的入口来进行访问,这就是网关的作用。
网关最重要的一个功能就是路由功能,能将请求转发到具体的业务服务器上
1. 简单实现
httputil.ReverseProxy 定义了一组方法让使用者去实现,主要有这几个
- Director 最核心的方法, 我们可以在这里对请求进行相应的修改,比如设置请求目标的地址,对原有请求头进行增删改,以及对请求体进行处理等等操作。
- ModifyResponse 可以让我们对响应的结果进行处理,比如修改、读取响应头和响应体。
- ErrorHandler 请求出错或者ModifyResponse返回error时会回调该方法,比如目标服务器无法连接,请求超时等等
实现:
如果引擎打开网关
func (e *Engine) SetGateConfigs(configs []gateway.GWConfig) {
e.gatewayConfigs = configs
//存储路径 和 服务配置
for _, v := range e.gatewayConfigs {
e.gatewayTreeNode.Put(v.Path, v.Name)
e.gatewayConfigMap[v.Name] = v
}
}
找寻网关服务路由是否存在,根据网关配置获得目标服务ip和端口,使用httputill工具进行代理转发自己写处理逻辑
/*加入网关时逻辑修改 找到目标 对应替换*/
func (e *Engine) httpRequestHandle(ctx *Context, w http.ResponseWriter, r *http.Request) {
if e.OpenGateway {
//req -> 网关 -> 配置分发
path := r.URL.Path
node := e.gatewayTreeNode.Get(path)
if node == nil {
ctx.W.WriteHeader(http.StatusNotFound)
fmt.Fprintln(ctx.W, ctx.R.RequestURI+" not found")
return
}
gwConfig := e.gatewayConfigMap[node.GwName]
target, err := url.Parse(fmt.Sprintf("http://%s:%d%s", gwConfig.Host, gwConfig.Port, path))
if err != nil {
ctx.W.WriteHeader(http.StatusInternalServerError)
fmt.Fprintln(ctx.W, err.Error())
}
//网关处理逻辑
director := func(req *http.Request) {
req.Host = target.Host
req.URL.Host = target.Host
req.URL.Path = target.Path
req.URL.Scheme = target.Scheme
if _, ok := req.Header["User-Agent"]; !ok {
req.Header.Set("User-Agent", "")
}
}
response := func(response *http.Response) error {
log.Println("响应修改")
return nil
}
handler := func(writer http.ResponseWriter, request *http.Request, err error) {
log.Println("错误处理:" + err.Error())
}
proxy := httputil.ReverseProxy{Director: director, ModifyResponse: response, ErrorHandler: handler}
//代理帮我转发
proxy.ServeHTTP(ctx.W, ctx.R)
return
}
2.集成注册中心
四、服务容错
1. 服务雪崩问题
在分布式系统中,由于网络原因或自身的原因,服务一般无法保证100%可用,如果一旦一个服务出现问题,调用这个服务就会出现线程阻塞的情况,此时若有大量的请求涌入,就会出现多条线程阻塞等待,进而导致服务瘫痪。
由于服务和服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩效应”。
雪崩效应发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法出现了响应变慢,亦或是某台机器的资源耗尽,我们无法完全杜绝雪崩的源头的发生,只有做好足够的容错,保证在一个服务发生问题,不会影响到其他服务的正常运行。
2. 常见的容错方案
要防止雪崩的扩散,我们就要做好服务的容错,容错说白了就是保护自己不被猪队友拖垮的一些措施,下面介绍常见的服务容错思路和组件。
2.1常见的容错思路
常见的容错思路有隔离,超时,限流,熔断,降级这几种。
2.1.1 隔离
它是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相互独立,无强依赖。
当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其他模块,不影响整体的系统服务。
常见的隔离方式有:线程池隔离和信号量隔离。
线程池隔离中,一旦某个服务挂了,只会影响其中分配的连接,不会影响别的服务的执行,有限的分配连接。
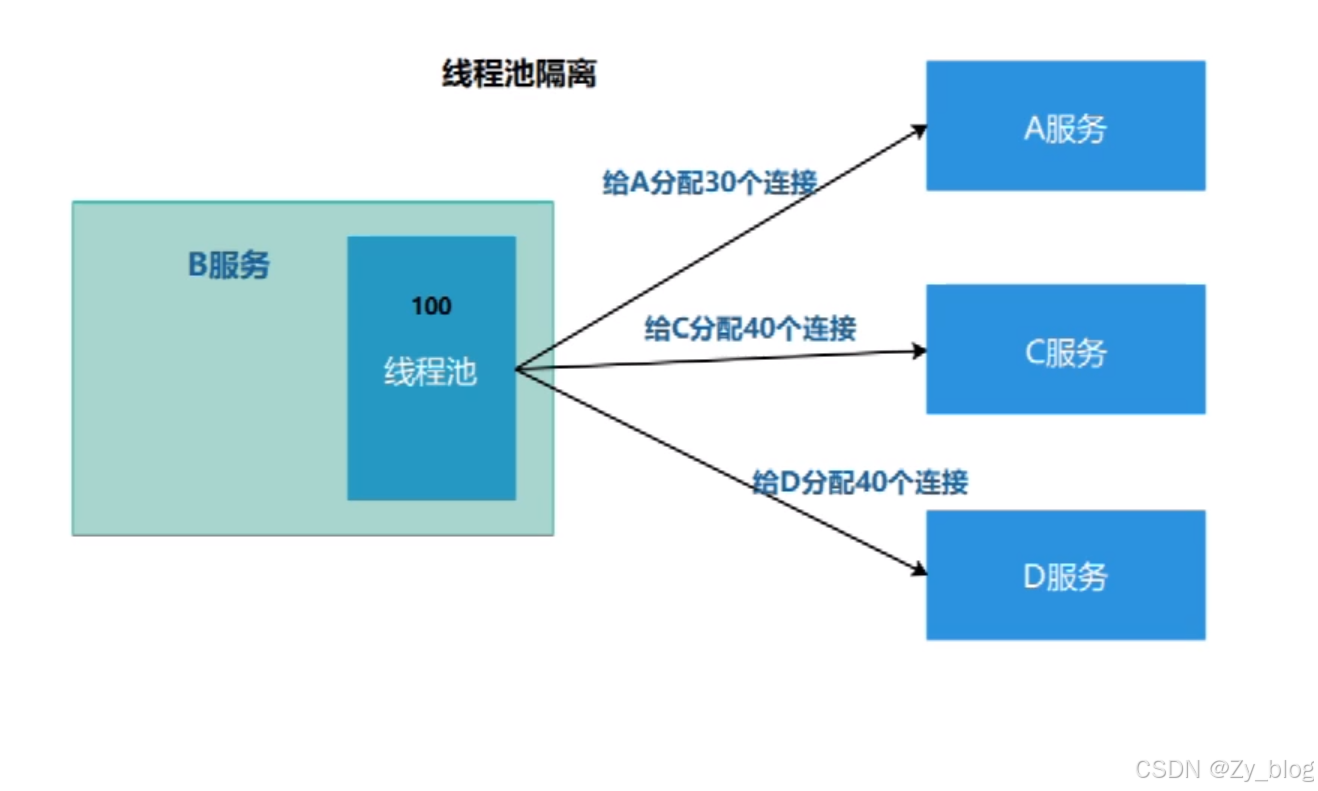
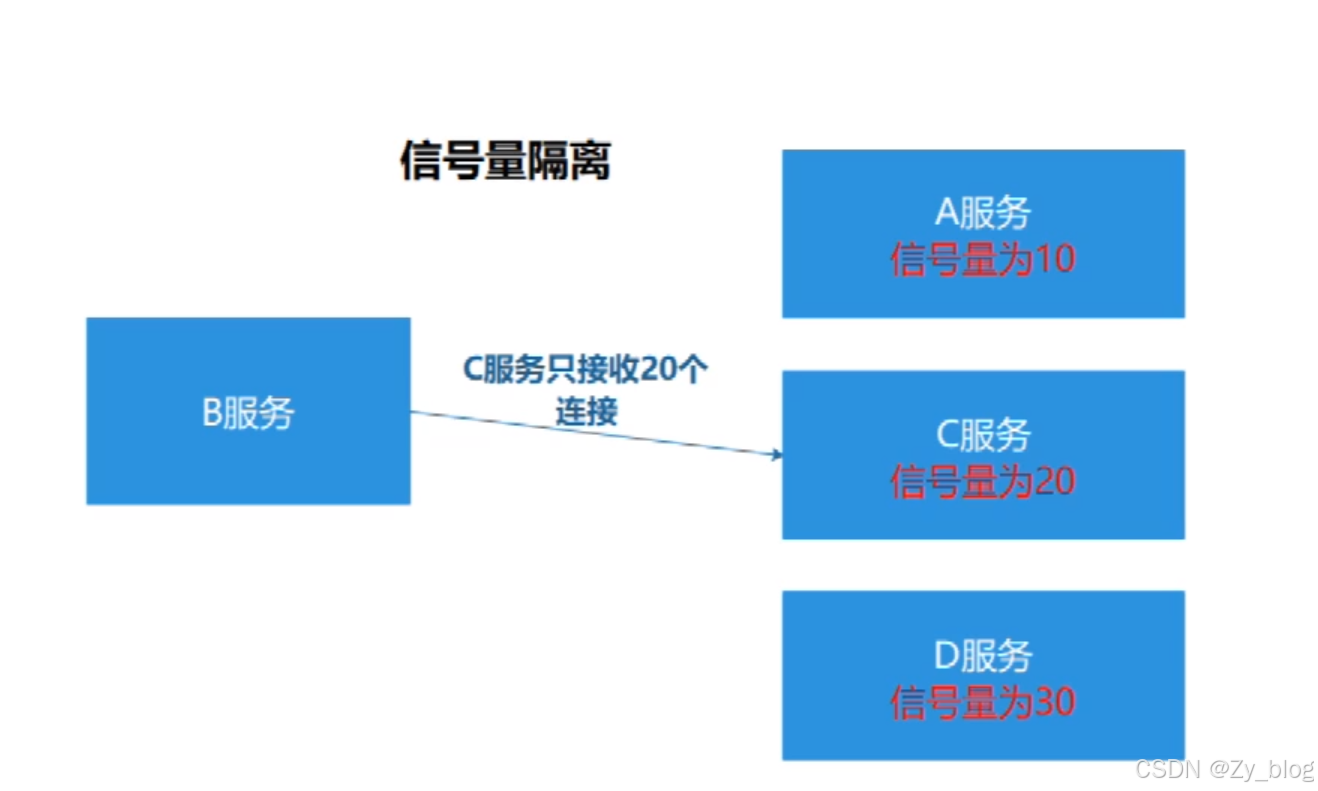
信号量隔离,设置了接收连接的上限,适用于可以快速返回的服务。
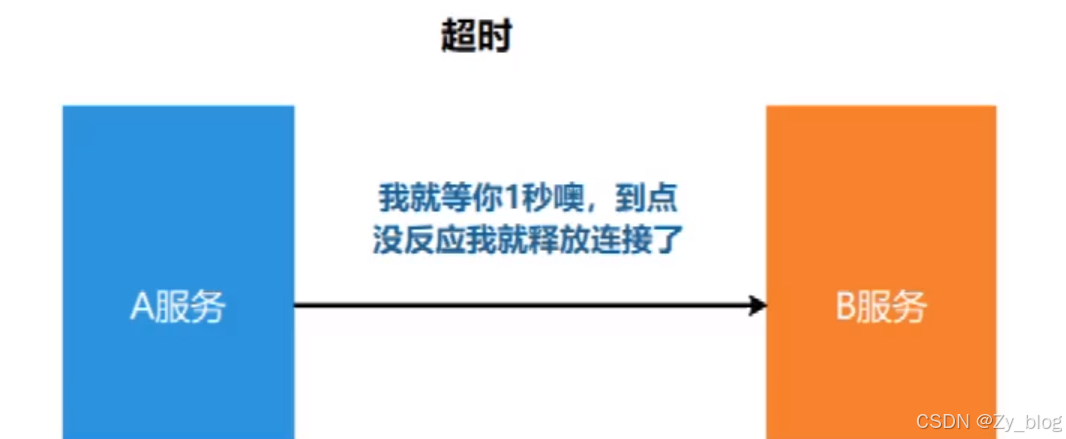
2.1.2 超时
在上游服务调用下游服务的时候,设置一个最大响应时间,如果超过这个时间,下游未做反应,就断开请求,释放掉线程。
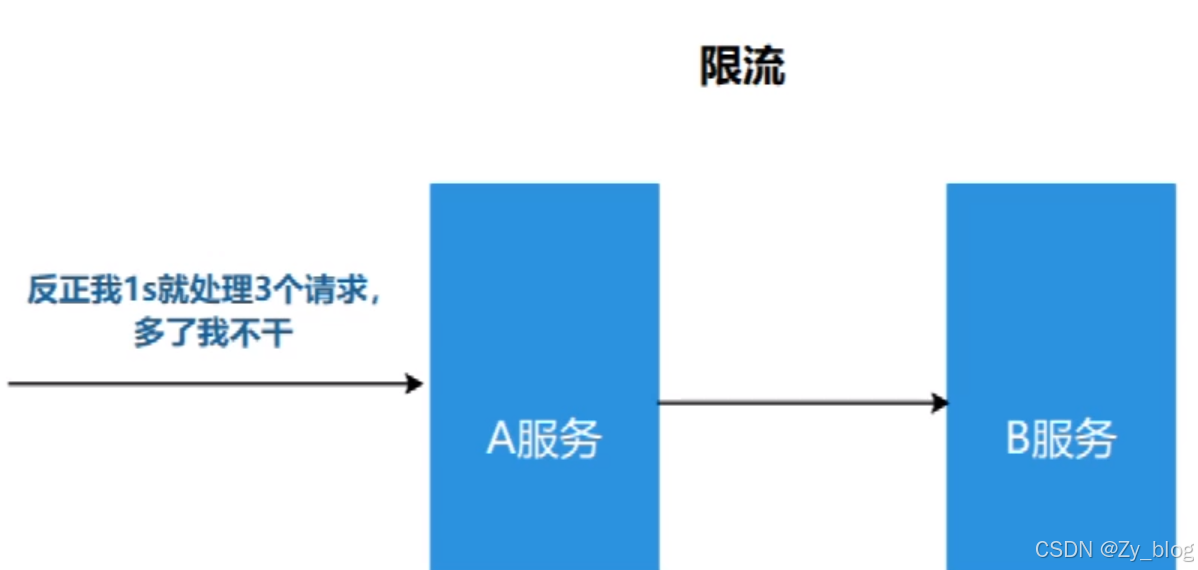
2.1.3 限流
限流就是限制系统的输入和输出流量,已达到保护系统的目的。为了保证系统的稳固运行,一旦达到需要限制的阈值,就需要限制流量并采取少量限制措施以完成限制流量的目的。
2.1.4 熔断
在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游系统为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。

服务熔断一般有三种状态:
- 熔断关闭状态(closed) 服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
- 熔断开启状态 后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法
- 半熔断状态 尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率依旧很低,则重新进入熔断开启状态。
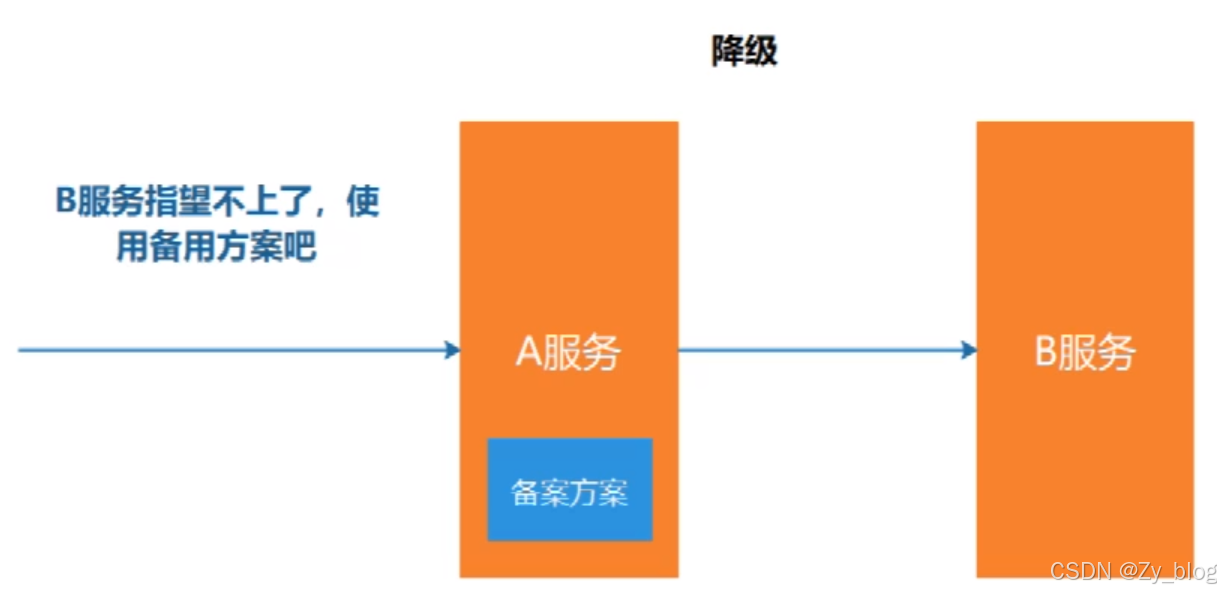
2.1.5 降级
降级其实就是为服务提供一个托底方案,一旦服务无法正常调用,就使用托底方案。
3. 限流实现
3.1 常见的限流算法
计数器
计数器是一种最简单限流算法,其原理就是:在一段时间间隔内,对请求进行计数,与阀值进行比较判断是否需要限流,每结束一个时间间隔时,都会将计数器清零。
计数器算法存在“时间临界点”缺陷,比如每一分钟限制100个请求,可以在00:00:00-00:00:58秒里面都没有请求,在00:00:59瞬间发送100个请求,这个对于计数器算法来是允许的,然后在00:01:00再次发送100个请求,意味着在短短1s内发送了200个请求,如果量更大呢,系统可能会承受不住瞬间流量,导致系统崩溃。
滑动窗口
滑动窗口算法的思想主要来源于Tcp协议,即将一个大的时间窗口分成多个小窗口,每次大窗口向后滑动一个小窗口,并保证大的窗口内流量不会超出最大值,这种实现比固定窗口的流量曲线更加平滑。
对于上述计数器算法存在的不足,对于滑动时间窗口,我们可以把1s的时间窗口划分成10个小窗口,或者想象窗口有10个时间片,
每个时间片统计自己片内100ms的请求数量。每过100ms,都有一个新的时间片加入窗口,早于当前时间1s的时间片滑出窗口,窗口内最多维护10个时间片。
虽然滑动窗口的使用,可以对时间临界问题有一定的优化,但从根本上而言,其实该算法并没有真正地解决固定窗口算法的临界突发流量问题。
漏桶
在介绍漏桶算法前,我们可以回忆一下,一个小学数学上的经典问题,有一个水池,有一个进水口,一个出水口,进水速度为x,出水速度为y,问多久可以把水池注满,相信这个问题大家都不陌生。简单来说漏桶算法,就是这道小学数学题,但是我们并不需要求解,首先想象有一个木桶,桶的容量是固定的。当有请求到来时先放到木桶中,处理请求时则以固定的速度从木桶中取出请求即可,如果木桶已经满了,可以直接返回请求频率超限的错误或进行一些其他处理,算法的好处是,流量一直是以一种均匀的速度在被消费,十分适合某些业务场景。
因为流入请求的速率是不固定的,但流出的速率是恒定的,所以当系统面对突发流量时会有大量的请求失败。这就导致,在类似于电商抢购、微博热点、过年红包等场景中,该算法并不适用。
令牌桶
令牌桶有点像反方向的"漏桶",它是以恒定的速度往木桶里加入令牌,木桶满了则不再加入令牌。服务收到请求时尝试从木桶中取出一个令牌,如果能够得到令牌则继续执行后续的业务逻辑。如果没有得到令牌,直接返回请求频率超限的错误或进行一些其他处理,不继续执行后续的业务逻辑。
同时由于向木桶中添加令牌的速度是恒定的,且木桶的容量是有上限等,所以单位时间内系统能够处理的请求数量也是可控的,从而起到限流的目的。假设加入令牌的速度为
100/s,桶的容量为500,那么在请求比较的少的时候,木桶可以先积攒一些令牌(最多500个)。当有突发流量时,可以一下把木桶内的令牌都取出,也就是500的并发,之后就需要等到有新的令牌加入后,才可以进行新的业务处理了。
3.2 go官方限流器:golang.org/x/time/rate
golang官方提供的扩展库里就自带了限流算法的实现,即 golang.org/x/time/rate ,该限流器也是基于令牌桶实现的。time/rate包中使用 Limiter 类型对限流器进行了定义,所有限流功能都是基于 Limiter 实现的,其结构如下:
type Limiter struct {
mu sync.Mutex
limit Limit
burst int // 令牌桶的大小
tokens float64
last time.Time // 上次更新tokens的时间
lastEvent time.Time // 上次发生限速器事件的时间(通过或者限制都是限速器事件)
}
- limit:字段表示往桶里放token的速率,它的类型是Limit(int64)。limit字段,既可以指定每秒向桶中放入token的数量,也可以指定向桶中放入token的时间间隔
- burst: 令牌桶的大小
- tokens: 桶中的令牌
- last: 上次往桶中放入token的时间
- lastEvent:上次触发限流事件的时间
初始化
rate.NewLimiter 有两个参数,第一个参数是 r Limit,设置的是限流器Limiter的limit字段,代表每秒可以向桶中放入多少个 token,第二个参数是 b int,b 代表桶的大小,也就是限流器 Limiter 的burst字段。Limiter 提供了三类方法供程序消费 Token,可以每次消费一个 Token,也可以一次性消费多个 Token。每种方法代表了当 Token 不足时,各自不同的对应手段,可以阻塞等待桶中Token补充,也可以直接返回取Token失败。
三种Token消费方法
Wait/WaitN:
Wait 实际上就是 WaitN(ctx,1),当使用 Wait 方法消费 Token 时,如果此时桶内 Token 数组不足 (小于 N),那么 Wait 方法将会阻塞一段时间,直至 Token 满足条件,若 Token 数量充足则直接返回。这里可以看到,Wait 方法有一个 context 参数。我们可以设置 context 的 Deadline 或者 Timeout,来决定此次 Wait 的最长时间,具体可以参考示例 wait()
Allow/AllowN:
Allow 实际上就是 AllowN(time.Now(),1),AllowN 方法表示,截止到某一时刻,目前桶中 token 数目是否大于 n 个,若满足则返回 true,同时从桶中消费 n 个 token。若不满足,直接返回false。
Reserve/ReserveN
Reserve 相当于 ReserveN(time.Now(),1),ReserveN 的用法相对复杂一些,当调用完成后,无论 Token 是否充足,都会返回一个 Reservation 的指针对象。我们可以通过调用该对象的Delay()方法得到一个需要等待的时间,时间到后即可进行业务处理。若不想等待,则可以调用Cancel()方法,该方法会将 Token 归还。
3.3代码实现
前置: go get golang.org/x/time/rate
1. 实现中间件:
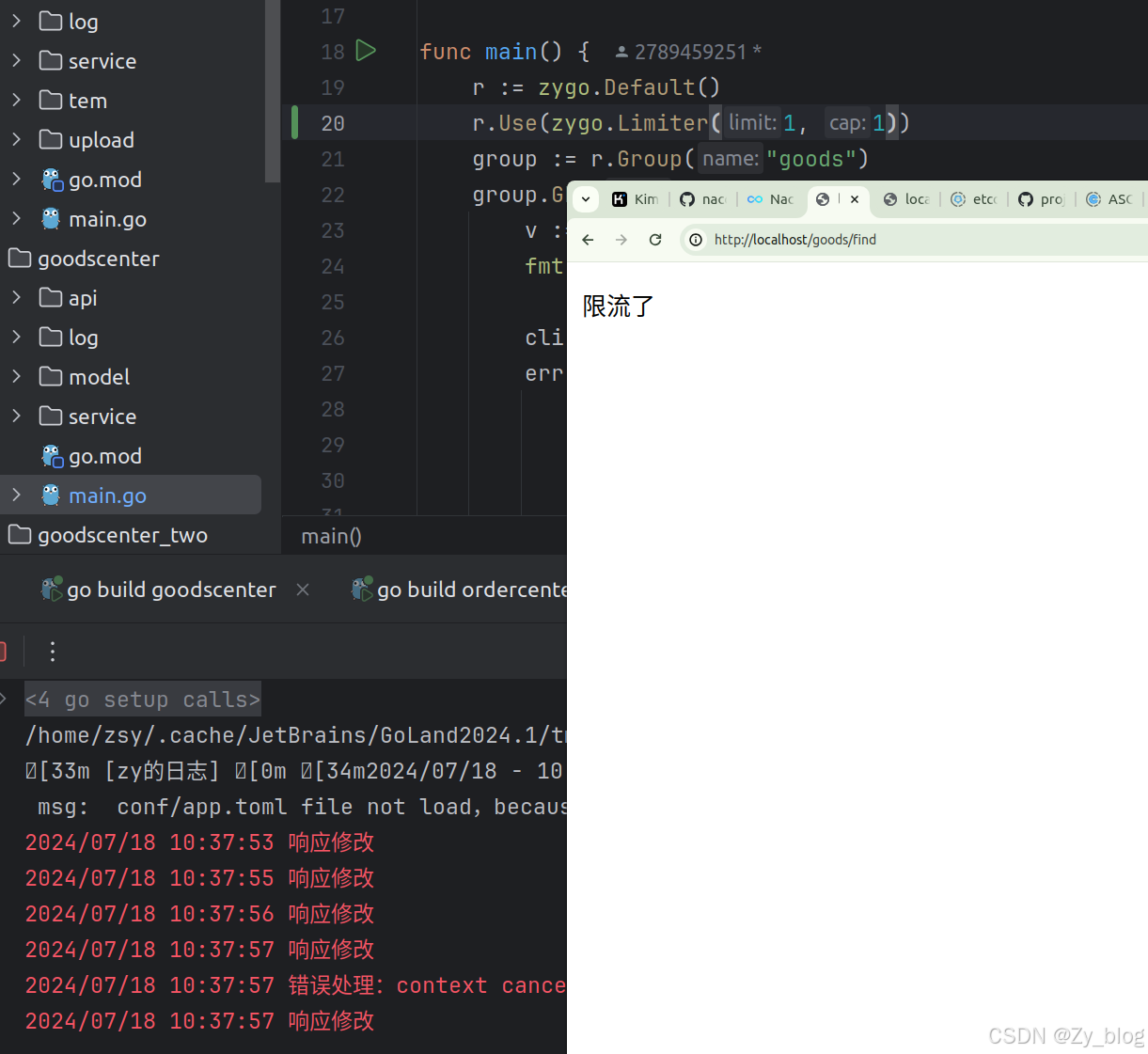
在执行函数之前先拿令牌,如果没有就直接返回限流。
func Limiter(limit, cap int) MiddlewareFunc {
li := rate.NewLimiter(rate.Limit(limit), cap)
return func(next HandlerFunc) HandlerFunc {
return func(ctx *Context) {
//实现限流
con, cancel := context.WithTimeout(context.Background(), time.Duration(1)*time.Second)
defer cancel()
err := li.WaitN(con, 1)
if err != nil {
//没有拿到令牌的操作
ctx.String(http.StatusForbidden, "限流了")
return
}
next(ctx)
}
}
}
2. 框架集成限流
给tcp的server加上限流器和超时时间
type MyTcpServer struct {
.....
LimiterTimeout time.Duration
Limiter *rate.Limiter
}
暴露出方法,设置限流器
/*设置限流器 参数:每秒放入令牌数 、木桶容量*/
func (s *MyTcpServer) SetLimiter(limit, cap int) {
s.Limiter = rate.NewLimiter(rate.Limit(limit), cap)
}
在解码请求之前,执行限流措施(修改readHandle)
//加入限流 - > 构建限流器
ctx, cancel := context.WithTimeout(context.Background(), s.LimiterTimeout*time.Second)
defer cancel()
err3 := s.Limiter.WaitN(ctx, 1)
if err3 != nil {
rsp := &MyRpcResponse{}
rsp.Code = 700 //限流的错误
rsp.Msg = err3.Error()
log.Println("接收数据出错,服务方法调用出错")
msConn.rspChan <- rsp
return
}
服务运行前设置tcp限流
tcpServer.SetLimiter(10, 100)
tcpServer.LimiterTimeout = 1
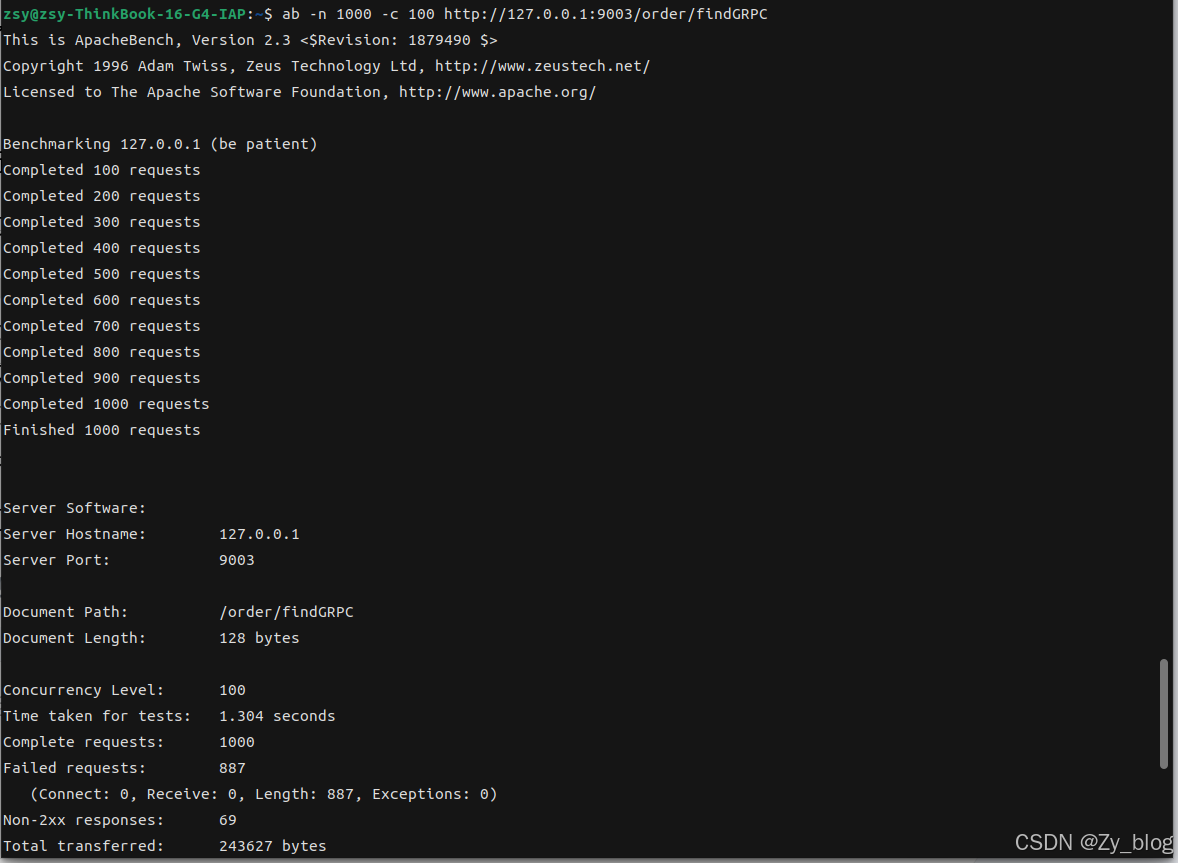
高并发限流测试:
ab -n 1000 -c 100 http://127.0.0.1:9003/order/findGRPC
-n总请求数
-c并发数
4.熔断实现
逻辑:请求成功一次,计算成功一次,连续成功一次,失败一次 计算失败一次 连续失败一次
当连续失败大于阈值 则打开断路器,打开状态,当超过一段时间,设置为半开状态,当连续成功大于阈值,则设置为关闭状态。
- 断路器
state代表断路器状态,关闭代表服务正常,开启表示服务出错,关闭时服务出错达到一定限度转换为半开,开启时过期时间过期,转换为半开。
// CircuitBreaker 断路器
type CircuitBreaker struct {
name string //名字
maxRequests uint32 //最大请求数 当连续请求成功数大于此时 断路器关闭
interval time.Duration //间隔时间
timeout time.Duration //超时时间
readyToTrip func(counts Counts) bool //是否执行熔断
isSuccessful func(err error) bool //是否成功
onStateChange func(name string, from State, to State) //状态变更
Fallback func(err error) (any, error) //降级方法
mutex sync.Mutex
state State //状态
generation uint64 //代 状态变更 new一个
counts Counts //数量
expiry time.Time //到期时间 检查是否从开到半开
}
- 断路器配置
用户通过设置setting来自定义断路器的执行熔断的限度(ReadyToTrip:请求出错多少次状态转换)、状态变更时的操作(OnStateChange)、请求是否成功的判断函数(IsSuccessful)、降级函数( Fallback)、断路器关闭时间隔时间、断路器工作的超时时间、半开时最大请求数
type Settings struct {
Name string //名字
MaxRequests uint32 //最大请求数
Interval time.Duration //间隔时间
Timeout time.Duration //超时时间
ReadyToTrip func(counts Counts) bool //执行熔断
OnStateChange func(name string, from State, to State) //状态变更
IsSuccessful func(err error) bool //是否成功
Fallback func(err error) (any, error)
}
- 计数器
type Counts struct {
Requests uint32 //请求数量
TotalSuccesses uint32 //总成功数
TotalFailures uint32 //总失败数
ConsecutiveSuccesses uint32 //连续成功数量
ConsecutiveFailures uint32 //连续失败数量
}
断路器执行逻辑
func (cb *CircuitBreaker) Execute(req func() (any, error)) (any, error) {
generation, err := cb.beforeRequest()
if err != nil {
//发生错误,设置降级方法,执行
if cb.Fallback != nil {
return cb.Fallback(err)
}
return nil, err
}
defer func() {
e := recover()
if e != nil {
cb.afterRequest(generation, false)
panic(e)
}
}()
result, err := req()
cb.afterRequest(generation, cb.isSuccessful(err))
return result, err
}
请求之前执行beforeRequest()
- 断路器打开或者半开且请求数量大于限度时拦截请求返回错误->是否降级 ->降级/返回错误
请求之后执行afterRequest(generation,cb.isSuccessful(err))
- 断路器在执行完请求后如果发生变化因为成了新一代状态计数刷新不再执行
- 断路器在执行完请求后成功且半开看是否连续成功达到限度可以转换为关闭
- 断路器在执行完请求后失败且关闭看是否连续失败达到限度可以转换为打开
func (cb *CircuitBreaker) beforeRequest() (uint64, error) {
cb.mutex.Lock()
defer cb.mutex.Unlock()
now := time.Now()
state, generation := cb.currentState(now)
if state == StateOpen {
return generation, ErrOpenState
} else if state == StateHalfOpen && cb.counts.Requests >= cb.maxRequests {
return generation, ErrTooManyRequests
}
cb.counts.onRequest()
return generation, nil
}
func (cb *CircuitBreaker) afterRequest(before uint64, success bool) {
cb.mutex.Lock()
defer cb.mutex.Unlock()
now := time.Now()
state, generation := cb.currentState(now)
if generation != before {
return
}
if success {
cb.onSuccess(state, now)
} else {
cb.onFailure(state, now)
}
}
func (cb *CircuitBreaker) currentState(now time.Time) (State, uint64) {
switch cb.state {
case StateClosed:
if !cb.expiry.IsZero() && cb.expiry.Before(now) {
cb.toNewGeneration(now)
}
case StateOpen:
if cb.expiry.Before(now) {
cb.setState(StateHalfOpen, now)
}
}
return cb.state, cb.generation
}
用户调用:
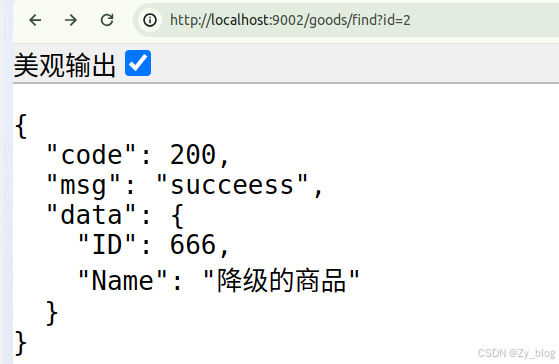
set := breaker.Settings{Fallback: func(err error) (any, error) {
goods := &model.Goods{ID: 666, Name: "降级的商品"}
return goods, nil
}}
var cb = breaker.NewCircuitBreaker(set)
group := r.Group("goods")
group.GET("/find", func(ctx *zygo.Context) {
result, _ := cb.Execute(func() (any, error) {
//网关可以配置header信息
//v := ctx.GetHeader("zy")
//fmt.Println("get zygo" + v)
query := ctx.GetQuery("id")
if query == "2" {
return nil, errors.New("测试熔断")
}
cli := register.NacosRegister{}
err := cli.CreateCli(register.Option{
DialTimeout: 5000,
NacosServerConfig: []constant.ServerConfig{
{
IpAddr: "127.0.0.1",
ContextPath: "/nacos",
Port: 8848,
Scheme: "http",
},
},
})
if err != nil {
return nil, err
}
cli.RegisterService("goodsCenter", "127.0.0.1", 9002)
good := &model.Goods{
ID: 1,
Name: "跳跳糖",
}
return good, nil
})
ctx.JSON(http.StatusOK, &model.Result{
Code: 200,
Msg: "succeess",
Data: result,
})
})
超过五次失败断路器打开,过20秒后转换为半开,可以执行请求。

5.降级实现
在熔断器中加入降级方法,暴露在setting中使得用户可以自定义,当请求之前被熔断器断路后可以执行降级方法。
//用户设置
set := breaker.Settings{Fallback: func(err error) (any, error) {
goods := &model.Goods{ID: 666, Name: "降级的商品"}
return goods, nil
}}
//发生错误,服务端执行降级方法
generation, err := cb.beforeRequest()
if err != nil {
//发生错误,设置降级方法,执行
if cb.Fallback != nil {
return cb.Fallback(err)
}
return nil, err
}
五、链路追踪
在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施
1. 为什么需要分布式链路追踪系统
在分布式架构下,当用户从浏览器客户端发起一个请求时,后端处理逻辑往往贯穿多个分布式服务,这时会浮现很多问题,比如:
- 请求整体耗时较长,具体慢在哪个服务?
- 请求过程中出错了,具体是哪个服务报错?
- 某个服务的请求量如何,接口成功率如何?
回答这些问题变得不是那么简单,我们不仅仅需要知道某一个服务的接口处理统计数据,还需要了解两个服务之间的接口调用依赖关系,只有建立起整个请求在多个服务间的时空顺序,才能更好的帮助我们理解和定位问题,而这,正是分布式链路追踪系统可以解决的。
2. 分布式链路追踪系统如何帮助我们
分布式链路追踪技术的核心思想:在用户一次分布式请求服务的调⽤过程中,将请求在所有子系统间的调用过程和时空关系追踪记录下来,还原成调用链路集中展示,信息包括各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
通过分布式链路追踪构建出完整的请求链路后,可以很直观地看到请求耗时主要耗费在哪个服务环节,帮助我们更快速聚焦问题。
同时,还可以对采集的链路数据做进一步的分析,从而可以建立整个系统各服务间的依赖关系、以及流量情况,帮助我们更好地排查系统的循环依赖、热点服务等问题。
3. 分布式链路追踪系统核心概念
在分布式链路追踪系统中,最核心的概念,便是链路追踪的数据模型定义,主要包括 Trace 和 Span。
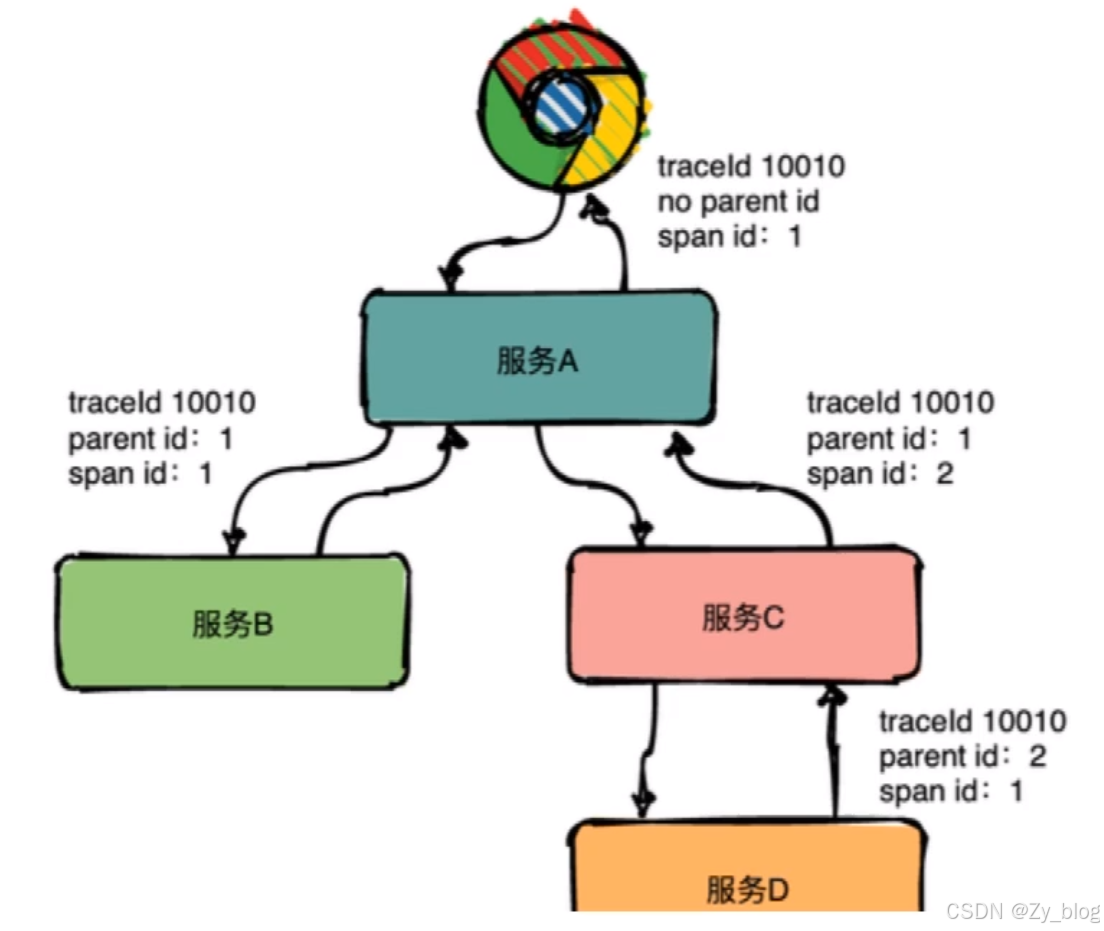
其中,Trace 是一个逻辑概念,表示一次(分布式)请求经过的所有局部操作(Span)构成的一条完整的有向无环图,其中所有的 Span 的 TraceId 相同。
Span 则是真实的数据实体模型,表示一次(分布式)请求过程的一个步骤或操作,代表系统中一个 逻辑运行单元,Span 之间通过嵌套或者顺序排列建立因果关系。Span 数据在采集端生成,之后上报到服务端,做进一步的处理。其包含如下关键属性:
- Name:操作名称,如一个 RPC 方法的名称,一个函数名
- StartTime/EndTime:起始时间和结束时间,操作的生命周期
- ParentSpanId:父级 Span 的 ID
- Attributes:属性,一组 <K,V> 键值对构成的集合
- Event:操作期间发生的事件
- SpanContext:Span 上下文内容,通常用于在 Span 间传播,其核心字段包括 TraceId、SpanId
分布式链路追踪系统的核心任务是:围绕 Span 的生成、传播、采集、处理、存储、可视化、分析,构建分布式链路追踪系统。
4. Jaeger
地址:https://github.com/jaegertracing/jaeger
Jaeger 是受到 Dapper 和 OpenZipkin 启发的由 Uber Technologies 作为开源发布的分布式跟踪系统。
Jaeger 用于监视和诊断基于微服务的分布式系统,包括:
- 分布式上下文传播
- 分布式传输监控
- 根本原因分析
- 服务依赖性分析
- 性能/延迟优化
Uber 发表了一篇博客文章 Evolving Distributed Tracing at Uber,文中解释了 Jaeger 在架构选择方面的历史和原因。Jaeger 的创建者 Yuri Shkuro 还出版了一本书 Mastering Distributed Tracing,该书深入介绍了 Jaeger 设计和操作的许多方面,以及一般的分布式跟踪。
功能特性
- 高可伸缩性
- 兼容 OpenTracing
- 多种存储后端支持
- 现代化Web UI
- 云原生部署
- 可观测性,支持Prometheus
- 安全性
Jaeger 的全链路追踪功能主要由三个角色完成: - client:负责全链路上各个调用点的计时、采样,并将 tracing 数据发往本地 agent。
- agent:负责收集 client 发来的 tracing 数据,并以 gRPC 协议转发给 collector。
- collector:负责搜集所有 agent 上报的 tracing 数据,统一存储。
5. 应用
docker pull jaegertracing/all-in-one
docker run -d -p 5775:5775/udp -p 16686:16686 -p 14250:14250 -p 14268:14268 jaegertracing/all-in-one:latest
访问:16686端口,即可访问UI页面
框架集成前提:
go get -u github.com/uber/jaeger-client-go/
5.1 Sampler 配置
sampler 配置代码示例:
Sampler: &config.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
}
这个 sampler 可以使用 config.SamplerConfig,通过 type、param 两个字段来配置采样器。
为什么要配置采样器?
因为服务中的请求千千万万,如果每个请求都要记录追踪信息并发送到 Jaeger
后端,那么面对高并发时,记录链路追踪以及推送追踪信息消耗的性能就不可忽视,会对系统带来较大的影响。当我们配置 sampler
后,jaeger 会根据当前配置的采样策略做出采样行为。
SamplerConfig 结构体中的字段 Param 是设置采样率或速率,要根据 Type 而定。
下面对其关系进行说明:
sampler.Type=“remote”/sampler.Type=jaeger.SamplerTypeRemote
是采样器的默认值,当我们不做配置时,会从 Jaeger 后端中央配置甚至动态地控制服务中的采样策略。
5.2 Reporter 配置
看一下 ReporterConfig 的定义。
type ReporterConfig struct {
QueueSize int yaml:"queueSize"
BufferFlushInterval time.Duration
LogSpans bool yaml:"logSpans"
LocalAgentHostPort string yaml:"localAgentHostPort"
DisableAttemptReconnecting bool yaml:"disableAttemptReconnecting"
AttemptReconnectInterval time.Duration
CollectorEndpoint string yaml:"collectorEndpoint"
User string yaml:"user"
Password string yaml:"password"
HTTPHeaders map[string]string yaml:"http_headers"
}
Reporter 配置客户端如何上报追踪信息的,所有字段都是可选的。
这里我们介绍几个常用的配置字段。
- QUEUESIZE,设置队列大小,存储采样的 span 信息,队列满了后一次性发送到 jaeger 后端;defaultQueueSize 默认为 100;
- BufferFlushInterval 强制清空、推送队列时间,对于流量不高的程序,队列可能长时间不能满,那么设置这个时间,超时可以自动推送一次。对于高并发的情况,一般队列很快就会满的,满了后也会自动推送。默认为1秒。
- LogSpans 是否把 Log 也推送,span 中可以携带一些日志信息。
- LocalAgentHostPort 要推送到的 Jaeger agent,默认端口 6831,是 Jaeger 接收压缩格式的 thrift 协议的数据端口。
- CollectorEndpoint 要推送到的 Jaeger Collector,用 Collector 就不用 agent 了。
例如通过 http 上传 trace:
Reporter: &config.ReporterConfig{
LogSpans: true,
CollectorEndpoint: “http://127.0.0.1:14268/api/traces”,
},
5.3 单进程使用
g.Get("/findTracer", func(ctx *ms.Context) {
createTracer, closer, err := tracer.CreateTracer("findTracer",
&config.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
&config.ReporterConfig{
LogSpans: true,
CollectorEndpoint: "http://192.168.200.100:14268/api/traces",
}, config.Logger(jaeger.StdLogger),
)
if err != nil {
log.Println(err)
}
defer closer.Close()
goods := model.Goods{Id: 1000, Name: "商品中心9002findTracer商品"}
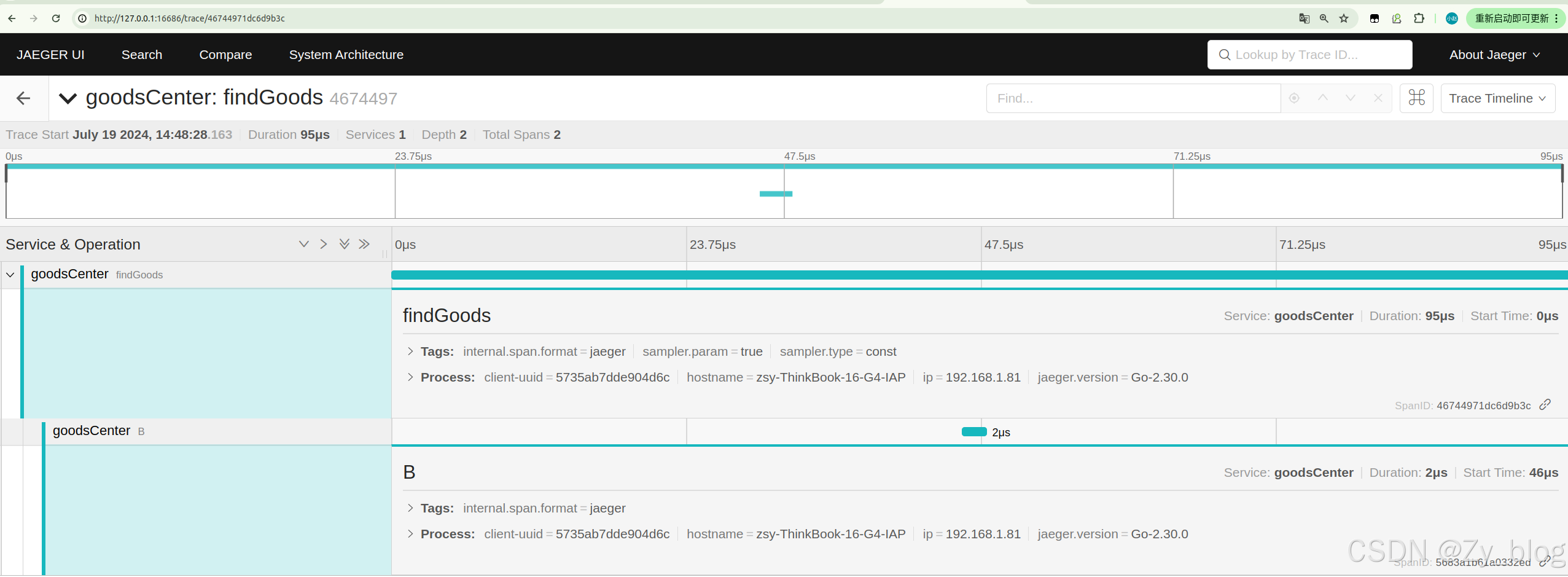
span := createTracer.StartSpan("findGoods")
defer span.Finish()
B(createTracer, span)
ctx.JSON(http.StatusOK, &model.Result{Code: 200, Msg: "success", Data: goods})
})
func B(t opentracing.Tracer, p opentracing.Span) {
//这是B服务
log.Println("B...")
span := t.StartSpan("B", opentracing.ChildOf(p.Context()))
defer span.Finish()
}
5.4 分布式使用
A、B 两个进程,A 通过 HTTP 调用 B 时,通过 Http Header 携带 trace 信息(称为上下文),然后 B 进程接收后,解析出来,在创建 trace 时跟传递而来的 上下文关联起来。
inject 函数打包上下文到 Header 中,而 extract 函数则将其解析出来。
//被调用的服务,使用中间件,解析和header信息,创建 trace 时跟传递而来的 上下文关联
func Tracer(serviceName string, samplerConfig *config.SamplerConfig, reporter *config.ReporterConfig, options ...config.Option) ms.MiddlewareFunc {
return func(next ms.HandlerFunc) ms.HandlerFunc {
return func(ctx *ms.Context) {
// 使用 opentracing.GlobalTracer() 获取全局 Tracer
tracer, closer, spanContext, _ := CreateTracerHeader(serviceName, ctx.R.Header, samplerConfig, reporter, options...)
defer closer.Close()
// 生成依赖关系,并新建一个 span、
// 这里很重要,因为生成了 References []SpanReference 依赖关系
startSpan := tracer.StartSpan(ctx.R.URL.Path, ext.RPCServerOption(spanContext))
defer startSpan.Finish()
// 记录 tag
// 记录请求 Url
ext.HTTPUrl.Set(startSpan, ctx.R.URL.Path)
// Http Method
ext.HTTPMethod.Set(startSpan, ctx.R.Method)
// 记录组件名称
ext.Component.Set(startSpan, "zygo-Http")
// 在 header 中加上当前进程的上下文信息
ctx.R = ctx.R.WithContext(opentracing.ContextWithSpan(ctx.R.Context(), startSpan))
next(ctx)
// 继续设置 tag
ext.HTTPStatusCode.Set(startSpan, uint16(ctx.StatusCode))
}
}
}
func CreateTracerHeader(serviceName string, header http.Header, samplerConfig *config.SamplerConfig, reporter *config.ReporterConfig, options ...config.Option) (opentracing.Tracer, io.Closer, opentracing.SpanContext, error) {
var cfg = config.Configuration{
ServiceName: serviceName,
Sampler: samplerConfig,
Reporter: reporter,
}
tracer, closer, err := cfg.NewTracer(options...)
// 继承别的进程传递过来的上下文
spanContext, _ := tracer.Extract(opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(header))
return tracer, closer, spanContext, err
}
type HttpClientSession struct {
*MsHttpClient
ReqHandler func(req *http.Request)
}
func (c *MsHttpClient) NewSession() *HttpClientSession {
return &HttpClientSession{c, nil}
}
//在响应时请求 先将自己的span inject 函数打包上下文到 Header 中
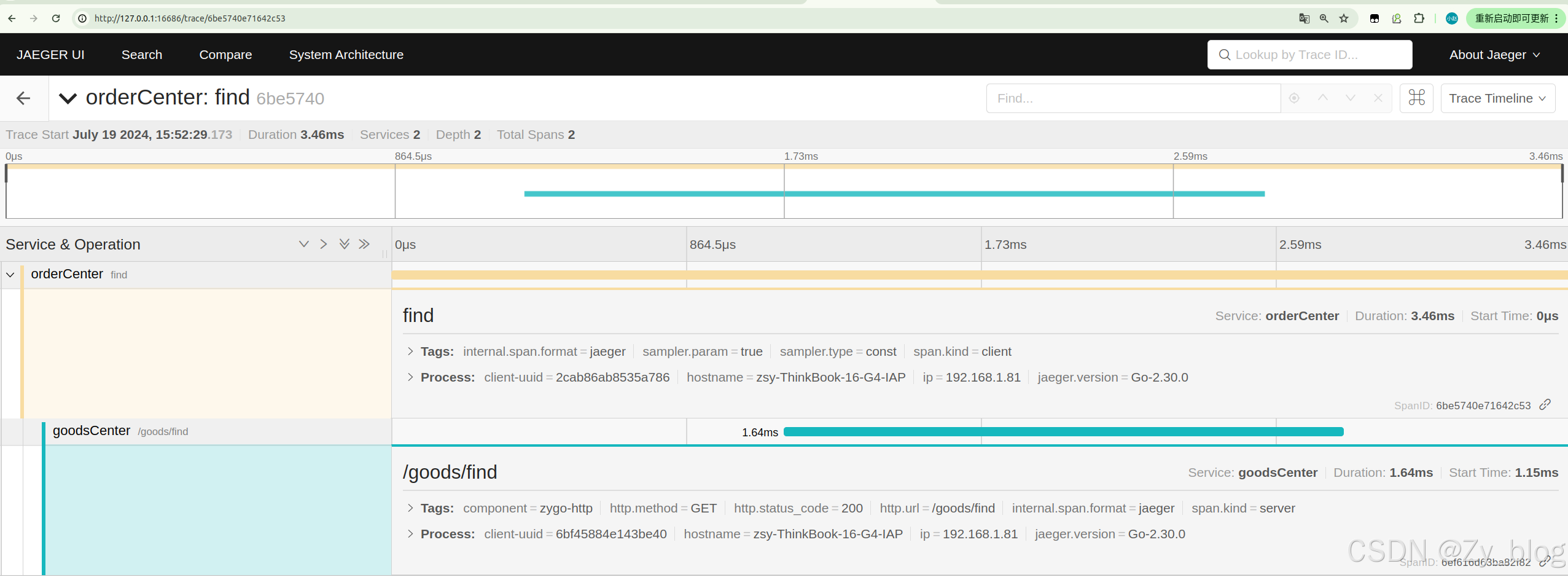
createTracer, closer, err := tracer.CreateTracer("orderCenter",
&config.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
&config.ReporterConfig{
LogSpans: true,
CollectorEndpoint: "http://192.168.200.100:14268/api/traces",
}, config.Logger(jaeger.StdLogger),
)
if err != nil {
log.Println(err)
}
defer closer.Close()
g.Get("/find", func(ctx *ms.Context) {
span := createTracer.StartSpan("find")
defer span.Finish()
//查询商品
v := &model.Result{}
session := client.NewSession()
session.ReqHandler = func(req *http.Request) {
//
ext.SpanKindRPCClient.Set(span)
createTracer.Inject(span.Context(), opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(req.Header))
}
bytes, err := session.Do("goodsService", "Find").(*service.GoodsService).Find(nil)
if err != nil {
ctx.Logger.Error(err)
}
fmt.Println(string(bytes))
json.Unmarshal(bytes, v)
ctx.JSON(http.StatusOK, v)
})
使用中间件,解析和header信息,创建 trace 时与调用端传递而来的 上下文关联
engine.Use(tracer.Tracer("goodsCenter", &config.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
&config.ReporterConfig{
LogSpans: true,
CollectorEndpoint: "http://192.168.200.100:14268/api/traces",
}, config.Logger(jaeger.StdLogger)))