fetch_olivetti_faces
数据集下载
fetch_olivetti_faces
sklearn.datasets.fetch_olivetti_faces(*, data_home=None, shuffle=False, random_state=0, download_if_missing=True, return_X_y=False, n_retries=3, delay=1.0)[source]
Load the Olivetti faces data-set from AT&T (classification).
Download it if necessary.
| Classes | 40 |
| Samples total | 400 |
| Dimensionality | 4096 |
| Features | real, between 0 and 1 |
Read more in the User Guide.
Parameters:
data_homestr or path-like, default=None
Specify another download and cache folder for the datasets. By default all scikit-learn data is stored in ‘~/scikit_learn_data’ subfolders.
shufflebool, default=False
If True the order of the dataset is shuffled to avoid having images of the same person grouped.
random_stateint, RandomState instance or None, default=0
Determines random number generation for dataset shuffling. Pass an int for reproducible output across multiple function calls. See Glossary.
download_if_missingbool, default=True
If False, raise an OSError if the data is not locally available instead of trying to download the data from the source site.
return_X_ybool, default=False
If True, returns instead of a object. See below for more information about the and object.(data, target)Bunchdatatarget
Added in version 0.22.
n_retriesint, default=3
Number of retries when HTTP errors are encountered.
Added in version 1.5.
delayfloat, default=1.0
Number of seconds between retries.
Added in version 1.5.
Returns:
dataBunch
Dictionary-like object, with the following attributes.
data: ndarray, shape (400, 4096)
Each row corresponds to a ravelled face image of original size 64 x 64 pixels.
imagesndarray, shape (400, 64, 64)
Each row is a face image corresponding to one of the 40 subjects of the dataset.
targetndarray, shape (400,)
Labels associated to each face image. Those labels are ranging from 0-39 and correspond to the Subject IDs.
DESCRstr
Description of the modified Olivetti Faces Dataset.
(data, target)tuple if
return_X_y=True
Tuple with the and objects described above.datatarget
Added in version 0.22.
Olivetti Faces人脸数据集合处理
简介
本资源文件提供了Olivetti Faces人脸数据集的处理方法和相关代码。Olivetti Faces是一个经典的人脸识别数据集,包含了40个不同个体的400张灰度图像。每个个体有10张图像,这些图像在不同的光照和表情条件下拍摄。
数据集特点
- 图像数量:400张
- 个体数量:40个
- 每张图像大小:47x47像素
- 图像格式:灰度图像
数据集下载
数据集可以从以下地址下载:
- 官方地址:http://cs.nyu.edu/~roweis/data/olivettifaces.gif
- 备用地址:百度网盘 请输入提取码 提取码:9m3c
数据处理
由于数据集是一张大图,每个人脸需要进行切割处理。可以使用Python脚本进行图像切割,具体代码如下:
# 导入所需的库 import cv2 import numpy as np # 读取大图 image = cv2.imread('olivettifaces.gif', cv2.IMREAD_GRAYSCALE) # 获取图像的尺寸 height, width = image.shape # 每个人脸的大小 face_height = height // 20 face_width = width // 20 # 切割并保存每个人脸 faces = [] for i in range(20): for j in range(20): face = image[i*face_height:(i+1)*face_height, j*face_width:(j+1)*face_width] faces.append(face) cv2.imwrite(f'face_{i*20 + j}.png', face) print("图像切割完成,共保存了400张人脸图像。")使用方法
- 下载数据集并保存为
olivettifaces.gif。- 运行上述Python脚本进行图像切割。
- 切割后的人脸图像将保存在当前目录下,文件名为
face_0.png到face_399.png。参考资料
- 本资源文件的详细处理方法和代码参考自CSDN博客文章。
注意事项
- 请确保Python环境已安装OpenCV库。
- 如果遇到下载问题,可以使用备用地址进行下载。
贡献
欢迎对本资源文件进行改进和优化,提交Pull Request或Issue。
Examples
>>> from sklearn.datasets import fetch_olivetti_faces >>> olivetti_faces = fetch_olivetti_faces() >>> olivetti_faces.data.shape (400, 4096) >>> olivetti_faces.target.shape (400,) >>> olivetti_faces.images.shape (400, 64, 64)
读入人脸数据
import matplotlib.pyplot as plt
fig,ax=plt.subplots(8,8,figsize=(8,8))
fig.subplots_adjust(hspace=0,wspace=0)
from sklearn.datasets import fetch_olivetti_faces
faces=fetch_olivetti_faces().images
for i in range(8):
for j in range(8):
ax[i,j].xaxis.set_major_locator(plt.NullLocator())
ax[i,j].yaxis.set_major_locator(plt.NullLocator())
ax[i,j].imshow(faces[i*10+j],cmap='bone')

import warnings
warnings.filterwarnings('ignore')
#fetch_olivetti_faces图像分割
import numpy as np
from sklearn.datasets import fetch_olivetti_faces
faces=fetch_olivetti_faces().images
X=faces.reshape(-1,64*64)
y=np.arange(40).repeat(10)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=42)
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
param_grid={'C':[0.1,1,10,100,1000],'gamma':[0.0001,0.001,0.01,0.1]}
grid=GridSearchCV(SVC(),param_grid,cv=5)
grid.fit(X_train,y_train)
print(grid.best_params_)
print(grid.score(X_test,y_test)){'C': 100, 'gamma': 0.001}
0.97
人脸图像切分:
#读取olivettifaces.gif文件
import matplotlib.pyplot as plt
from PIL import Image
import cv2
im=Image.open('olivettifaces.gif')
plt.imshow(im,cmap='gray')
plt.show()
#分割图片
im_array=np.array(im)
im_array.shape
# 获取图像的尺寸
height, width = im_array.shape
# 每个人脸的大小
face_height = height // 20
face_width = width // 20
# 切割并保存每个人脸
faces = []
for i in range(20):
for j in range(20):
face = im_array[i*face_height:(i+1)*face_height, j*face_width:(j+1)*face_width]
faces.append(face)
# 保存人脸
face = Image.fromarray(face)
face.save(f'./人脸识别/picture/face_{i*20+j}.png')
print('人脸切割完成')

人脸识别
# 读取人脸图片
import os
import numpy as np
from PIL import Image
import cv2
faces = []
for i in range(400):
face = Image.open(f'./人脸识别/picture/face_{i}.png')
face = np.array(face)
faces.append(face)
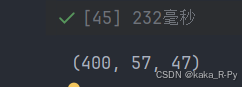
faces = np.array(faces)
faces.shape
import warnings
warnings.filterwarnings('ignore')
# 人脸识别
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X = faces.reshape(400, -1)
y = np.arange(40).repeat(10)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
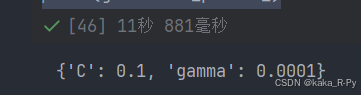
param_grid = {'C': [0.1, 1, 10, 100, 1000], 'gamma': [0.0001, 0.001, 0.01, 0.1]}
grid = GridSearchCV(SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)
print(grid.best_params_)
{kind=link}