Redis(Remote Dictionary Server)是一款开源的、基于内存的数据结构存储系统,常用于构建高性能、可扩展的应用程序。
而缓存是 Redis 最常见的应用场景之一。将经常被访问的数据(如数据库查询结果、热门文章内容等)存储在 Redis 中,下次请求时直接从 Redis 中获取,减少对后端数据源(如数据库)的访问压力,提升系统整体性能。例如在新闻资讯类网站,将热门新闻详情缓存到 Redis,大量用户浏览时能快速响应。
但是Redis在Java盛行可不只是做缓存这一种功能的实现,他还有其他的功能也都可以实现,下面我们就来用Redis去完成几个其他的功能实现。
1.朋友圈点赞功能实现
1.1原理
在实现点赞功能之前,我先讲一下实现原理,以便我们可以可以更好的去理解程序
数据存储选择:
- 字符串(String)类型:
- Redis 的字符串类型可以用来存储点赞数的数值。每一条朋友圈动态会对应一个唯一的标识(比如动态的 ID),以这个标识为基础构建一个特定的键(key),例如
post:{post_id}:likes(这里post_id是具体朋友圈动态的编号),而这个键对应的值(value)就是点赞的数量,以字符串形式存储的数字。通过 Redis 的INCR(自增)和DECR(自减)等命令可以方便地对这个存储点赞数的字符串值进行原子操作,实现点赞数的增加或减少。 - 例如,刚开始一条动态的点赞数是 0,对应的 Redis 键值对可能是
"post:12345:likes" : "0",当有用户点赞时,执行INCR命令后就变为"post:12345:likes" : "1",后续再有点赞操作就持续自增。
- Redis 的字符串类型可以用来存储点赞数的数值。每一条朋友圈动态会对应一个唯一的标识(比如动态的 ID),以这个标识为基础构建一个特定的键(key),例如
- 集合(Set)类型(可选,用于记录点赞用户等拓展功能):
- 除了记录点赞数量,还可以使用集合类型来记录哪些用户对该动态进行了点赞。同样以动态的 ID 构建一个集合的键,如
post:{post_id}:liked_users,将点赞用户的唯一标识(比如用户 ID)添加到这个集合中。利用集合的特性,可以方便地判断某个用户是否已经点赞(通过SISMEMBER命令查看元素是否在集合中),也能方便地统计点赞用户的数量(通过SCARD命令获取集合元素个数)等操作。 - 比如用户 1、用户 2 对动态
post_id为 12345 的朋友圈动态进行了点赞,那么在 Redis 中对应的集合可能是"post:12345:liked_users",其集合元素有"user1", "user2"。
- 除了记录点赞数量,还可以使用集合类型来记录哪些用户对该动态进行了点赞。同样以动态的 ID 构建一个集合的键,如
原子操作特性
- Redis 的操作大多是原子性的,像
INCR、DECR这些命令在执行时不会被其他客户端的命令打断。在高并发的场景下(例如很多用户同时对某条朋友圈动态进行点赞或者取消点赞操作),这种原子性能够保证点赞数的计算准确无误。- 假设同时有两个用户 A 和 B 对同一条朋友圈动态发起点赞操作,如果没有原子操作保证,可能会出现并发问题,比如先读取到点赞数是 5,然后两个用户同时基于这个 5 去加 1,最终点赞数可能错误地变为 6 而不是 7。但由于 Redis 的
INCR命令是原子的,它能确保无论多少个并发请求,都会准确地逐个增加点赞数,不会出现数据不一致的情况。
- 假设同时有两个用户 A 和 B 对同一条朋友圈动态发起点赞操作,如果没有原子操作保证,可能会出现并发问题,比如先读取到点赞数是 5,然后两个用户同时基于这个 5 去加 1,最终点赞数可能错误地变为 6 而不是 7。但由于 Redis 的
1.2代码实现
现在pom.xml里面集成redis的客户端jedis
<!-- 添加jedis依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>写一个代码示例:
package com.lcyy;
import redis.clients.jedis.Jedis;
public class WeChatMomentsLikesCounter {
private Jedis jedis;
public WeChatMomentsLikesCounter() {
// 连接Redis服务器,这里假设Redis在本地运行,端口为6379,可根据实际情况修改
this.jedis = new Jedis("localhost", 6379);
}
// 点赞操作
public void likePost(String postId) {
String key = "post:" + postId + ":likes";
jedis.incr(key);
}
// 取消点赞操作
public void unlikePost(String postId) {
String key = "post:" + postId + ":likes";
jedis.decr(key);
}
// 获取点赞数
public long getLikesCount(String postId) {
String key = "post:" + postId + ":likes";
String count = jedis.get(key);
if (count == null) {
return 0;
}
return Long.parseLong(count);
}
// 关闭Redis连接
public void close() {
if (jedis!= null) {
jedis.close();
}
}
public static void main(String[] args) {
WeChatMomentsLikesCounter counter = new WeChatMomentsLikesCounter();
// 模拟点赞操作
counter.likePost("12345");
counter.likePost("12345");
// 获取点赞数并打印
long likesCount = counter.getLikesCount("12345");
System.out.println("点赞数: " + likesCount);
// 模拟取消点赞操作
counter.unlikePost("12345");
// 再次获取点赞数并打印
likesCount = counter.getLikesCount("12345");
System.out.println("点赞数: " + likesCount);
// 关闭Redis连接
counter.close();
}
}在redis的客户端可以看到实现点赞功能

2.排行榜功能实现
2.1实现原理
基于有序集合(Sorted Set)的数据结构基础
-
结构特点:
- Redis 的有序集合是一种同时具备集合特性与有序特性的数据结构。它的每个元素都由一个成员(member,比如上述例子中的玩家 ID)和一个分数(score,如玩家的得分)组成,并且会根据分数对集合中的元素自动进行排序。这种排序是按照分数的大小来进行的,默认是从小到大排序(也可以通过配置实现从大到小排序)。
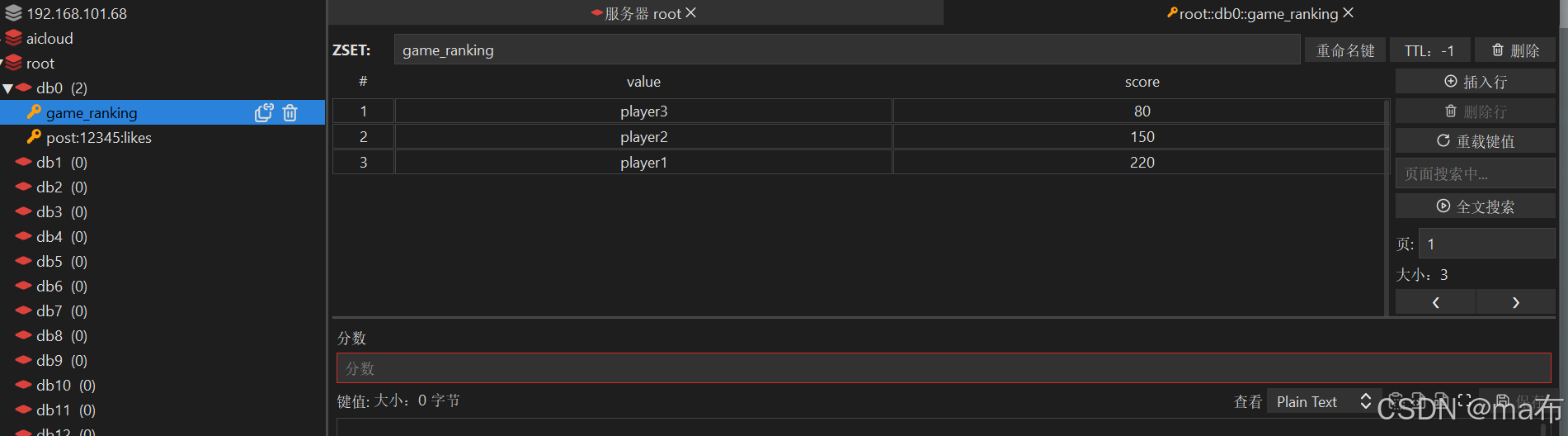
- 例如,有玩家 1(ID 为 “player1”)得分 100,玩家 2(ID 为 “player2”)得分 150,玩家 3(ID 为 “player3”)得分 80,存储在名为 “game_ranking” 的有序集合中,其内部结构类似如下形式(以简单示意,实际底层更复杂):
| 成员(member)| 分数(score)|
| ---- | ---- |
|player3|80|
|player1|100|
|player2|150|
-
内存存储与高效操作:
- 有序集合的数据是存储在内存中的,这使得数据的读写操作非常迅速,能够快速响应排行榜相关的添加、查询、更新等操作请求。相比于传统基于磁盘存储的数据库,在频繁操作排行榜数据(像游戏中玩家得分不断变化、频繁查看排行榜等场景)时,Redis 的内存存储方式极大地提升了性能,保障了良好的用户体验。
核心命令的运用原理
- ZADD 命令(添加元素及分数):
- 当要将玩家的得分添加到排行榜时,使用
ZADD命令。这个命令会将指定的成员(玩家 ID)及其对应的分数插入到有序集合中,同时按照分数对整个集合进行重新排序(如果有需要),以确保集合始终保持有序状态。 - 例如,执行
ZADD game_ranking 120 player4,就是将玩家 4(ID 为 “player4”)及其得分 120 添加到 “game_ranking” 这个有序集合中,集合会自动根据新插入的元素调整排序顺序。
- 当要将玩家的得分添加到排行榜时,使用
- ZRANGE 命令(获取指定范围元素):
- 用于获取排行榜中指定范围的元素,比如获取前 N 名玩家的信息。它是根据有序集合中元素的排序顺序(基于分数)来返回相应的成员(玩家 ID)。可以指定起始索引和结束索引来确定获取的范围,索引从 0 开始计数。
- 例如,
ZRANGE game_ranking 0 2会返回 “game_ranking” 有序集合中排名前 3(索引 0 到 2)的玩家 ID,结合后续使用ZSCORE命令获取对应分数,就能完整呈现排行榜前几名的情况。
- ZINCRBY 命令(增加成员的分数):
- 当玩家的得分需要更新时,使用
ZINCRBY命令。这个命令会按照指定的增量去改变指定成员(玩家 ID)的分数,然后同样会根据更新后的分数对有序集合进行重新排序,确保排行榜始终反映最新的得分情况。 - 比如,玩家 1 原本得分 100,执行
ZINCRBY game_ranking 20 player1后,玩家 1 的得分变为 120,并且 “game_ranking” 有序集合会自动调整排序,将玩家 1 放在新的合适位置上。
- 当玩家的得分需要更新时,使用
2.2代码实现
package com.lcyy;
import redis.clients.jedis.Jedis;
import java.util.Set;
import java.util.TreeMap;
public class LeaderboardExample {
private Jedis jedis;
public LeaderboardExample() {
// 连接Redis服务器,这里假设Redis在本地运行,端口为6379,可根据实际情况修改
this.jedis = new Jedis("localhost", 6379);
}
// 添加玩家得分到排行榜
public void addPlayerScore(String playerId, double score) {
String key = "game_ranking";
jedis.zadd(key, score, playerId);
}
// 获取排行榜前N名玩家信息
public TreeMap<Double, String> getRanking(int topN) {
String key = "game_ranking";
Set<String> playerIds = jedis.zrange(key, 0, topN - 1);
TreeMap<Double, String> ranking = new TreeMap<>();
for (String playerId : playerIds) {
double score = jedis.zscore(key, playerId);
ranking.put(score, playerId);
}
return ranking;
}
// 更新玩家得分
public void updatePlayerScore(String playerId, double newScore) {
String key = "game_ranking";
jedis.zincrby(key, newScore, playerId);
}
// 关闭Redis连接
public void close() {
if (jedis!= null) {
jedis.close();
}
}
public static void main(String[] args) {
LeaderboardExample leaderboard = new LeaderboardExample();
// 添加玩家得分
leaderboard.addPlayerScore("player1", 100.0);
leaderboard.addPlayerScore("player2", 150.0);
leaderboard.addPlayerScore("player3", 80.0);
// 获取排行榜前3名玩家信息
TreeMap<Double, String> ranking = leaderboard.getRanking(3);
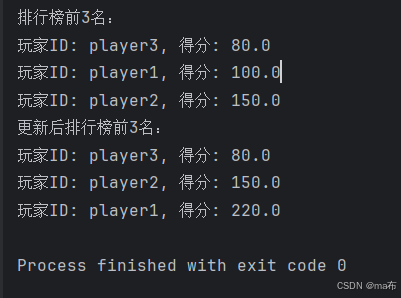
System.out.println("排行榜前3名:");
for (Double score : ranking.keySet()) {
System.out.println("玩家ID: " + ranking.get(score) + ", 得分: " + score);
}
// 更新玩家得分
leaderboard.updatePlayerScore("player1", 120.0);
// 再次获取排行榜前3名玩家信息
ranking = leaderboard.getRanking(3);
System.out.println("更新后排行榜前3名:");
for (Double score : ranking.keySet()) {
System.out.println("玩家ID: " + ranking.get(score) + ", 得分: " + score);
}
// 关闭Redis连接
leaderboard.close();
}
}
在客户端工具也可以看到
3.布隆过滤器实现
3.1实现原理
- 布隆过滤器本质上是一种概率型的数据结构,用于快速判断一个元素是否可能存在于一个集合中。它通过使用多个哈希函数对元素进行处理,将元素映射到一个位数组(bit array)中的多个位置,并把这些位置对应的比特位设置为 1。当要判断一个元素是否存在时,同样用这些哈希函数对该元素进行计算,得到相应的比特位位置,如果这些位置的比特位都为 1,那么就认为该元素可能存在;但如果有任何一个比特位为 0,则可以确定该元素一定不存在。不过需要注意的是,由于哈希冲突等原因,存在误判的可能性,即可能会判断某个实际上不存在的元素为可能存在,但不会出现把存在的元素判断为不存在的情况。
Redis 在布隆过滤器中的角色
- 利用 Redis 存储位数组:
- Redis 在这里主要是作为位数组的存储介质,使用 Redis 的字符串(String)类型来模拟位数组。在 Redis 中,字符串的每个字节(byte)由 8 个比特位(bit)组成,可以通过
SETBIT和GETBIT等命令来操作这些比特位。例如,把一个元素经过哈希函数计算后对应到 Redis 字符串表示的位数组中的第 10 位,若要添加该元素到布隆过滤器,就可以使用SETBIT命令将这个第 10 位的比特位设置为 1;当要判断元素是否存在时,通过GETBIT命令获取对应比特位的值进行判断。 - 以一个简单的例子来说明,假设有一个 Redis 键名为
bloom_filter的字符串用来存储布隆过滤器的位数组,初始时所有比特位都为 0,元素"apple"经过两个哈希函数计算后对应到第 5 位和第 12 位,那么添加"apple"时,就会分别执行SETBIT bloom_filter 5 1和SETBIT bloom_filter 12 1这两个命令,将相应比特位设置为 1。
- Redis 在这里主要是作为位数组的存储介质,使用 Redis 的字符串(String)类型来模拟位数组。在 Redis 中,字符串的每个字节(byte)由 8 个比特位(bit)组成,可以通过
3.2代码实现
在代码实现之前首先需要加入一个Guaua框架
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.2-jre</version>
</dependency>运行代码
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import com.google.common.hash.HashFunction;
import com.google.common.hash.Hashing;
import redis.clients.jedis.Jedis;
import java.nio.charset.StandardCharsets;
public class RedisBloomFilter {
private static final String BLOOM_FILTER_KEY = "bloom_filter";
private Jedis jedis;
private BloomFilter<String> bloomFilter;
private HashFunction hashFunction;
// 初始化布隆过滤器,设置预计元素数量和误判率
public RedisBloomFilter(int expectedInsertions, double falsePositiveRate) {
this.jedis = new Jedis("localhost", 6379);
this.bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8),
expectedInsertions, falsePositive率);
this.hashFunction = Hashing.murmur3_128(); // 这里选择了murmur3_128哈希函数,可根据需要更换
}
// 计算元素的哈希值(用于在Redis中定位比特位)
private long hash(String element) {
return hashFunction.hashBytes(element.getBytes(StandardCharsets.UTF_8)).asLong();
}
// 将元素添加到布隆过滤器(同时添加到Redis和本地布隆过滤器实例)
public void add(String element) {
if (!contains(element)) {
bloomFilter.put(element);
jedis.setbit(BLOOM_FILTER_KEY, hash(element), true);
}
}
// 检查元素是否可能存在于布隆过滤器中(先在本地布隆过滤器实例检查,再在Redis中检查)
public boolean contains(String element) {
if (!bloomFilter.mightContain(element)) {
return false;
}
return jedis.getbit(BLOOM_FILTER_KEY, hash(element)) == true;
}
// 关闭Redis连接
public void close() {
if (jedis!= null) {
jedis.close();
}
}
public static void main(String[] args) {
// 初始化布隆过滤器,预计插入1000个元素,误判率为0.01
RedisBloomFilter bloomFilter = new RedisBloomFilter(1000, 0.01);
// 添加元素到布隆过滤器
bloomFilter.add("element1");
bloomFilter.add("element2");
// 检查元素是否存在
System.out.println("element1是否存在: " + bloomFilter.contains("element1"));
System.out.println("element2是否存在: " + bloomFilter.contains("element2"));
System.out.println("element3是否存在: " + bloomFilter.contains("element3"));
// 关闭Redis连接
bloomFilter.close();
}
}