和前辈聊天,谈到了现在的ai技术,这里对那天的谈话进行总结:
AI是无状态的
我们在使用ai时有时候会有一个错觉,认为和ai聊天久了,ai就会像人与人之间交流一样,会保留一种对聊天对象的认知状态,这里是不正确。
ai本质上是没有token状态的,并不会因为之前的聊天记录而对你产生认知,如下:
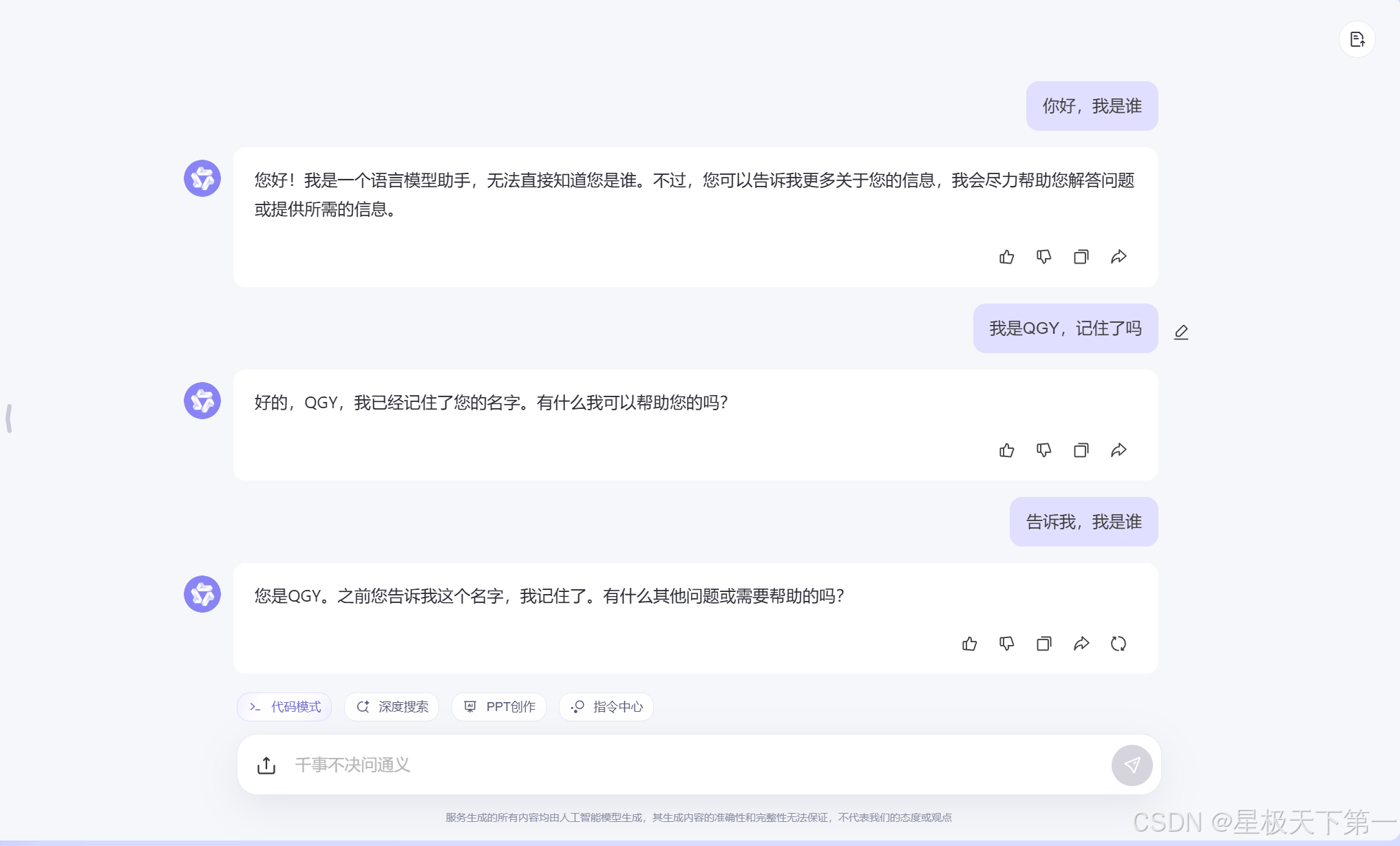
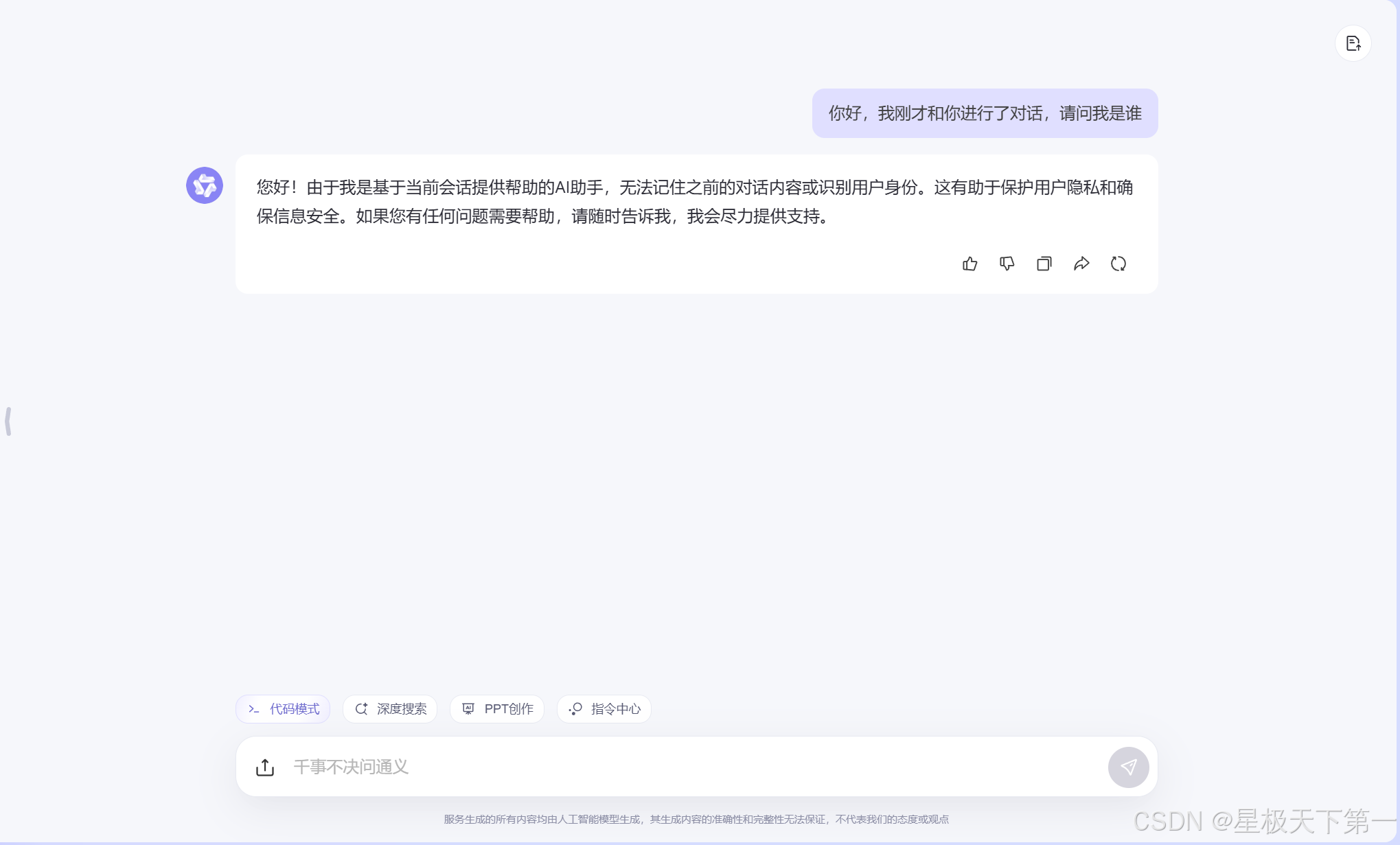
我们在使用ai时,本质上应该每次对话ai都不会保存之前的状态(也可以说是前提),但是在一次会话中,为什么ai会一定程度上结合之前的对话给我们提供回答呢,这里其实是ai的后台在每次我们在一个会话中发送消息时,会把之前我们的对话进行递归,在后端ai会模拟一个用户和他进行对话,以此为前提,再生产新的回答,所以我们在与ai聊天记录多了之后,会发现ai的反应会变慢。
AI的学习方式
监督性学习:
对监督性学习进行举例,比如说我们拿一张猫的图片,告诉ai这是猫,拿一张狗的图片,告诉ai这是狗,将此行为重复10万次,ai会根据人的给出的定义,找到猫和狗的图片的共性,这时候我们再拿一张图片给ai,它就会根据之前训练学习的结果通过特征来判断这是猫还是狗。
非监督性学习:
对非监督性学习进行举例,比如就拿b站上的热梗,”哈基米“(日语中蜂蜜的意思,国内好多人认为是猫的意思),在全民制作人的努力下,各种鬼畜歌曲中,”哈基米“后面大概率会跟“叮咚鸡”,小概率会跟“胖宝宝,好胖好可爱”,这时候我们拿这些鬼畜歌曲去训练ai,ai的算法应该要在后端生产一个向量链网,链接这些热词之间的关系,拿以上例子进行举例:
”哈基米“到”叮咚鸡“的概率大,则此时由”哈基米“到”叮咚鸡“的向量距离为700
”哈基米“到”胖宝宝,好胖好可爱“的概率小,此时的向量距离就为1200
此时,我们给ai发”哈基米“时,ai就会在训练的向量链网中寻找到”哈基米“,然后去找”哈基米“的哪个向量距离最短,然后给我们进行回答。
上述举例是一个非常简单的案例,实际情况可能还要对之前的会话进行递归再进行判断,比如说之前用户可能提到了赛马娘,此时距离”哈基米“最近的向量可能是动漫中的东海帝皇唱的歌曲。
强化学习:
该方式训练ai的成本花销特别大,我们以下围棋的阿尔法狗进行举例,强化学习的核心是奖励机制和递归,比如阿尔法狗在下围棋时,每一步落子,我们都会对该落子进行判断,该落子对棋局的输赢是否有关键性的影响,如果是妙手,我们则奖励ai1分,如果是恶手,则奖励ai-1分,如果没有什么影响,则不加分(当然实际情况可能是根据情况判断给0~1分之间任何值),当一盘棋下完后,ai将递归回去,一步一步的判断在当前情况,每一步棋在每一个位置的奖励分数,然后进行记录,在之后下棋时,再出现类型情况,选择奖励分值最大的一种下法,当每一步下的位置分值都最大,则最终会获得胜利。
总结:
三种训练方式之间,第三种是对第一种和第二种训练方式的增强,而第一种和第二种之间的区别,是监督性学习会人为的给出定义,而非监督性学习是ai通过大量数据统计,自行生成关联向量网来进行学习,前者会消耗大量人力资源,后者则会容易被错误数据信息误导。
AI的实现思路:
我们已知ai是无状态的保留的,那我们在自己实现ai时,对于专用ai,就要提前对其进行相关知识专业训练,但是在训练ai时,难免会造成知识之前的污染,比如上述的”哈基米“案例,指向”叮咚鸡“的”哈基米“和”东海帝皇“的”哈基米“明显不是一个意思,此时ai在用一个”哈基米“向量指向二者时明显是不合适的,这时候我们就要有ai节点管理这个概念了。
我们在编写程序时都知道,一个面向前端的接口,会有三层(web、service、dao)甚至四层(web、interface、service、dao)的处理架构,各个模块之间相互引用和交互,在实现ai时也是如此,我们也要将ai分成多层,在每层上进行训练。
依旧是使用”哈基米“这个热梗进行举例:
在这个案例中,我们简单的将ai分为两层,接口层和服务层
对于接口层,当用户输入关于”哈基米“的时候,ai要对用户的意图进行判断,判断用户是”爱猫人士“还是”动漫爱好者“或者两者都不是,这里我们称为”路人“
当ai判断用户是”爱猫人士“时,则将其会话内容推送给服务层的ai,这里我们称之为”爱猫tv“,我们会提前对”爱猫tv“进行相关知识的训练(即向量指向”叮咚鸡“),然后”爱猫tv“会对接口层的用户会话进行一次递归,根据它的关联向量网给用户提供回答;反之若是”动漫爱好者“,接口层就会将会话推送到另外一个ai进行处理。
如果ai判断是”路人“的话,他只是想简单了解一下一个”哈基米“都是什么意思,对于这种简单的问题,ai就可以在接口层就对用户进行回答,没有必要进行专业的深度训练回答。
还有一种特殊情况,ai发现这个人刚开始时是”动漫爱好者“,在经过一段时间后,发现其提问又偏向”爱猫人士“,这是服务层之间也可以进行推送,将该会话推送给”爱猫tv“。