
智慧工地资产盘点,超大规模钢筋计数数据集,共23400组图像,多视角,多角度,多场景,采用voc方式标注
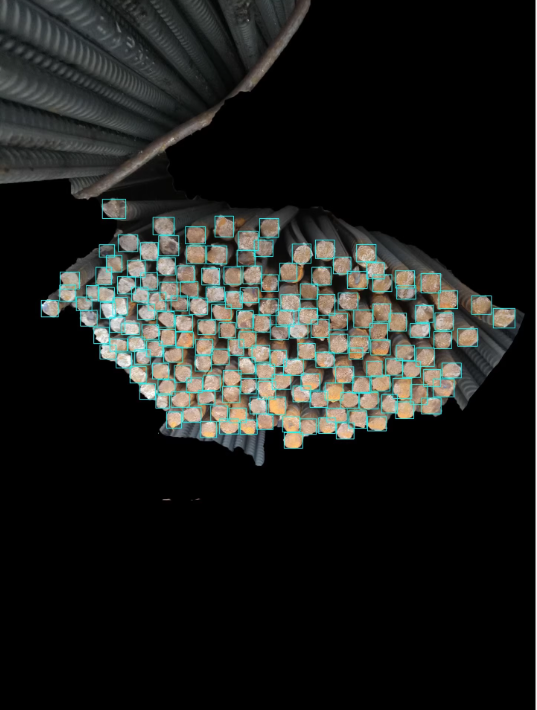

数据集介绍
- 名称:智慧工地钢筋计数数据集
- 规模:23,400组图像
- 特点:
- 多视角、多角度拍摄,以模拟现实中的复杂环境。
- 包含多种施工场景,确保模型能够适应不同背景下的识别任务。
- 每张图片都配有详细的VOC格式标注信息,包括但不限于钢筋的位置(边界框)、类别等。
- 应用:主要用于开发自动化钢筋计数系统,帮助提高施工现场资产管理效率。
- 标注格式:采用Pascal VOC标准进行对象标注,每张图片对应一个XML文件记录其内所有目标物体的信息。
关键代码示例
这里给出一个使用Python和常用的计算机视觉库OpenCV以及xml.etree.ElementTree来解析VOC格式标签并显示带有标注框的图像的基本示例。
import os
import cv2
import xml.etree.ElementTree as ET
def parse_voc_annotation(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像路径
image_path = root.find('path').text
# 解析每个对象
for obj in root.findall('object'):
name = obj.find('name').text
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
yield (image_path, name, (xmin, ymin, xmax, ymax))
# 假设你的数据集位于 'dataset' 文件夹下
dataset_dir = 'path_to_your_dataset'
for xml_file in os.listdir(dataset_dir):
if not xml_file.endswith('.xml'):
continue
for img_path, label, bbox in parse_voc_annotation(os.path.join(dataset_dir, xml_file)):
img = cv2.imread(img_path)
cv2.rectangle(img, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
cv2.putText(img, label, (bbox[0], bbox[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36, 255, 12), 2)
cv2.imshow("Image with Annotations", img)
cv2.waitKey(0)
cv2.destroyAllWindows()这段代码首先定义了一个函数parse_voc_annotation用来读取VOC XML标注文件,并从中提取出图像路径及各目标物体的边界框坐标。然后遍历指定目录下的所有XML文件,对每一幅图像及其对应的标注进行可视化处理。