节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、算法项目落地经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
想象一下,AI 助手可以无缝地与你互动,动态地根据你的需求检索信息并完成任务。随着智能体检索增强生成(RAG)的兴起,这一愿景正逐渐成为现实。
在本文中,我们将深入探讨这个令人兴奋的领域,探索如何利用强大的工具组合:LlamaIndex、Claude-3.5 Sonnet 和 MongoDB 来创建具有检索超级能力的 AI 智能体。
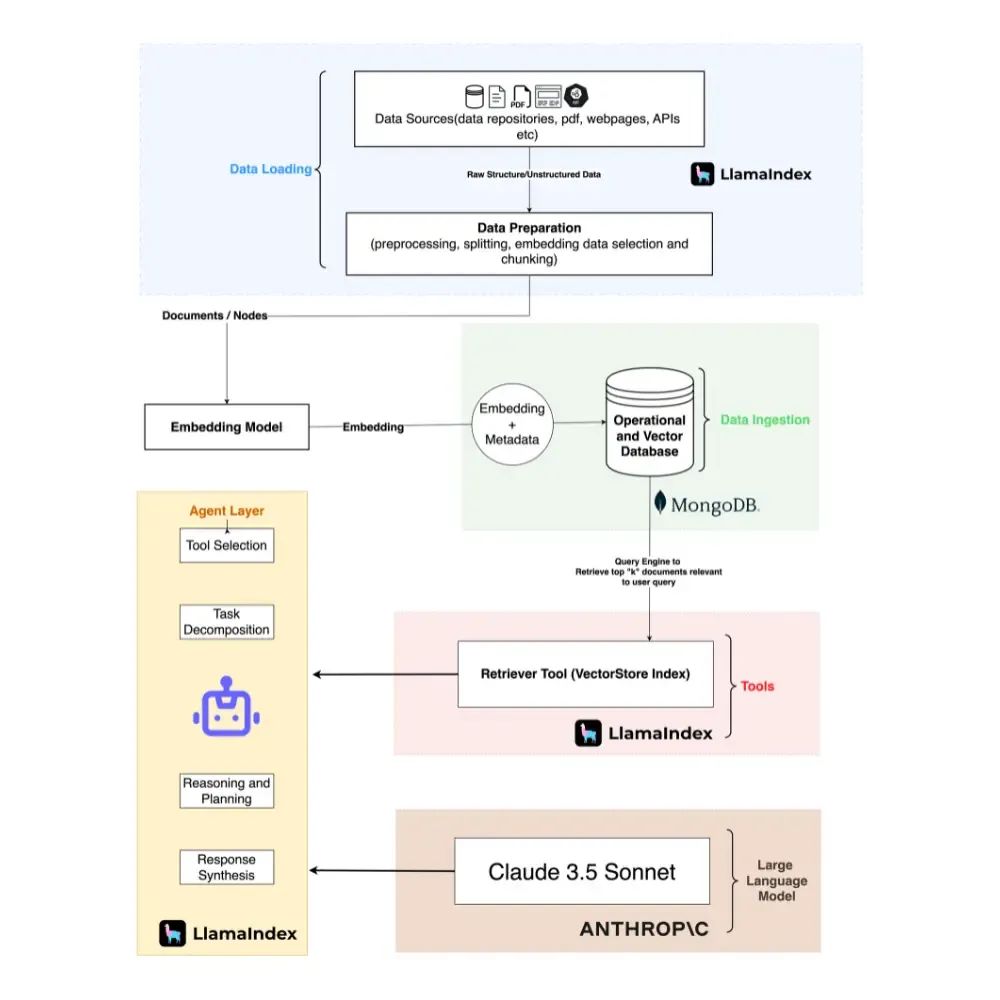
工具集成
让我们看看如何将这些强大的工具结合在一起:
-
LlamaIndex:这个先进的搜索引擎擅长基于意义而不是关键词查找相似信息。它充当 AI 智能体的“眼睛”,在海量信息中定位最相关的数据。
-
Claude-3.5 Sonnet:它允许智能体处理 LlamaIndex 检索到的信息,生成响应。
-
MongoDB:一个强大的 NoSQL 数据库,MongoDB 在存储和管理支持 AI 智能体的知识库中起着关键作用。其灵活性允许存储各种数据类型,使其成为复杂信息检索任务的理想选择。
集成优势
这种协同作用带来了许多好处:
-
增强的信息检索:LlamaIndex 的向量搜索功能确保 AI 智能体检索到最相关的信息,即使是细微的查询也不例外。
-
动态任务完成:Claude-3.5 Sonnet 使 AI 智能体能够分析检索到的数据并采取适当的行动,使其真正成为能够独立行动的智能体。
-
可扩展性和灵活性:MongoDB 处理大型数据集的能力允许系统随着信息需求的增加而增长。
代码实现
让我们深入研究使用 LlamaIndex、Claude-3.5 Sonnet 和 MongoDB 的智能体 RAG。
第一步:安装库
!pip install --quiet llama-index # main llamaindex library
!pip install --quiet llama-index-vector-stores-MongoDB # mongodb vector database
!pip install --quiet llama-index-llms-anthropic # anthropic LLM provider
!pip install --quiet llama-index-embeddings-openai # openai embedding provider
!pip install --quiet pymongo pandas datasets # others
第二步:设置环境变量
import os
os.environ["ANTHROPIC_API_KEY"] = ""
os.environ["HF_TOKEN"] = ""
os.environ["OPENAI_API_KEY"] = ""
# WARNING: Never commit API keys or sensitive information to public repositories
LLM 和嵌入模型配置
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.anthropic import Anthropic
from llama_index.core import Settings
llm = Anthropic(model="claude-3-5-sonnet-20240620")
embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
dimensions=256,
embed_batch_size=10,
openai_api_key=os.environ["OPENAI_API_KEY"]
)
Settings.embed_model = embed_model
Settings.llm = llm
第三步:数据加载和处理
from datasets import load_dataset
import pandas as pd
# https://huggingface.co/datasets/MongoDB/airbnb_embeddings
dataset = load_dataset("MongoDB/airbnb_embeddings", split="train", streaming=True)
dataset = dataset.take(4000)
# Convert the dataset to a pandas dataframe
dataset_df = pd.DataFrame(dataset)
# Dataset comes with embeddings created with OpenAI, but we will recreate new ones
dataset_df = dataset_df.drop(columns=['text_embeddings'])
dataset_df.head(5)
第四步:生成嵌入
import json
from llama_index.core import Document
from llama_index.core.schema import MetadataMode
documents_json = dataset_df.to_json(orient='records')
documents_list = json.loads(documents_json)
llama_documents = []
for document in documents_list:
# Convert complex objects to JSON strings
for field in ["amenities", "images", "host", "address", "availability", "review_scores", "reviews", "image_embeddings"]:
document[field] = json.dumps(document[field])
# Create a Document object
llama_document = Document(
text=document["description"],
metadata=document,
excluded_llm_metadata_keys=["_id", "transit", "minimum_nights", "maximum_nights", "cancellation_policy", "last_scraped", "calendar_last_scraped", "first_review", "last_review", "security_deposit", "cleaning_fee", "guests_included", "host", "availability", "reviews", "image_embeddings"],
excluded_embed_metadata_keys=["_id", "transit", "minimum_nights", "maximum_nights", "cancellation_policy", "last_scraped", "calendar_last_scraped", "first_review", "last_review", "security_deposit", "cleaning_fee", "guests_included", "host", "availability", "reviews", "image_embeddings"],
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
llama_documents.append(llama_document)
# Observing input examples
print("\nThe LLM sees this: \n", llama_documents[0].get_content(metadata_mode=MetadataMode.LLM))
print("\nThe Embedding model sees this: \n", llama_documents[0].get_content(metadata_mode=MetadataMode.EMBED))
from llama_index.core.node_parser import SentenceSplitter, SemanticSplitterNodeParser
from llama_index.core.schema import MetadataMode
from tqdm import tqdm
# semantic_splitter = SemanticSplitterNodeParser(
# buffer_size=10, breakpoint_percentile_threshold=95, embed_model=embed_model
# )
base_splitter = SentenceSplitter(chunk_size=5000, chunk_overlap=200)
nodes = base_splitter.get_nodes_from_documents(llama_documents)
# Progress bar
pbar = tqdm(total=len(nodes), desc="Embedding Progress", unit="node")
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode=MetadataMode.EMBED)
)
node.embedding = node_embedding
# Update the progress bar
pbar.update(1)
# Close the progress bar
pbar.close()
print("Embedding process completed!")
第五步:MongoDB 设置
import pymongo
os.environ["MONGO_URI"] = ""
def get_mongo_client(mongo_uri):
"""Establish and validate connection to the MongoDB."""
client = pymongo.MongoClient(mongo_uri, appname="devrel.showcase.python")
# Validate the connection
ping_result = client.admin.command('ping')
if ping_result.get('ok') == 1.0:
# Connection successful
print("Connection to MongoDB successful")
return client
else:
print("Connection to MongoDB failed")
return None
mongo_client = get_mongo_client(mongo_uri)
DB_NAME = "airbnb"
COLLECTION_NAME = "listings_reviews"
db = mongo_client.get_database(DB_NAME)
collection = db.get_collection(COLLECTION_NAME)
第六步:向量数据库集成
from llama_index.vector_stores.mongodb import MongoDBAtlasVectorSearch
vector_store = MongoDBAtlasVectorSearch(
mongo_client,
db_name=DB_NAME,
collection_name=COLLECTION_NAME,
index_name="vector_index"
)
vector_store.add(nodes)
第七步:创建检索工具和智能体
from llama_index.core import VectorStoreIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.agent import FunctionCallingAgentWorker
index = VectorStoreIndex.from_vector_store(vector_store)
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)
query_engine_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="knowledge_base",
description=(
"Provides information about Airbnb listings and reviews."
"Use a detailed plain text question as input to the tool."
),
),
)
agent_worker = FunctionCallingAgentWorker.from_tools(
[query_engine_tool], llm=llm, verbose=True
)
agent = agent_worker.as_agent()
response = agent.chat("Tell me the best listing for a place in New York")
print(str(response))
结论
LlamaIndex、Claude-3.5 Sonnet 和 MongoDB 共同构建的智能体 RAG 未来充满可能性。
资料获取和交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型算法技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流