目录
1 插入数据
1.1 insert优化
1.1.1 批量插入
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry'),(5,'LiuBei'),(6,'ZhangSan')
批量插入数据推荐在500-1000,不建议超过1000
可以分批次插入
1.1.2 手动提交事务
原因:MySQL事务是默认提交的,一条insert插入语句开启一次事务,比较耗费性能

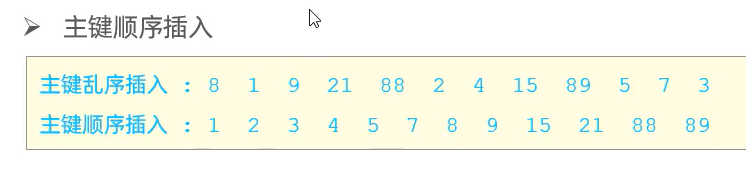
1.1.3 主键顺序插入
MySQL主键是B+Tree结构,每插入一条数据都要去维护B+Tree的性质
1.2 大批量插入数据
百万级数据使用load指令进行插入
主键顺序插入性能高于乱序插入

步骤
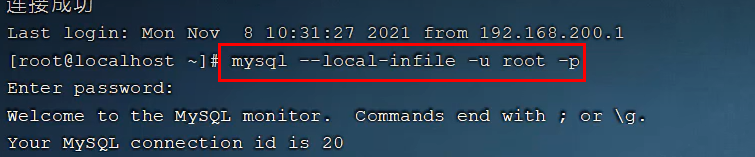
1.连接MySQL客户端时指定参数
mysql --local-infile -u -root -p
2.设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
MySQL查看某个参数的指令 select @@local_infile
set global local_infile =1
3.将数据上传到Linux服务器上,使用指令加载到表结构中
load data local infile '/root/sql.log' into table 'tb_user' fields terminated by ',' lines terminated by '\n';
字段用可以用‘,’隔开,行之间换行隔开(这两个可以自己指定)
2 主键优化
2.1 数据组织方式
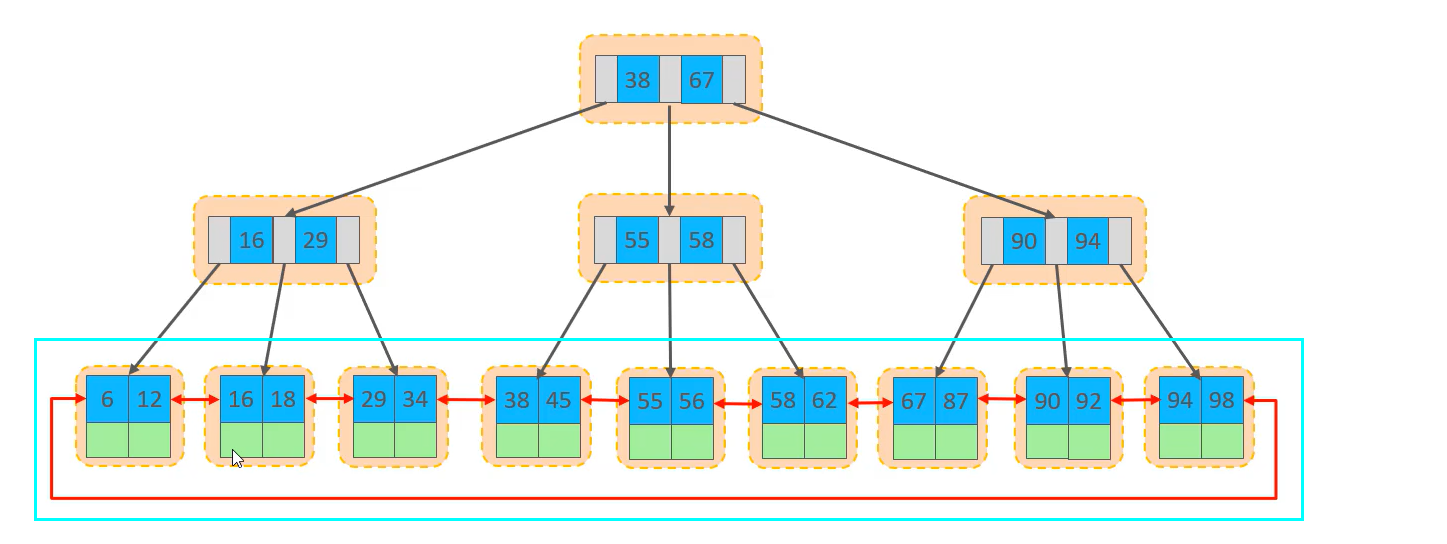
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)
主键索引是聚集索引,索引结构下存储的是行数据
2.2 页分裂
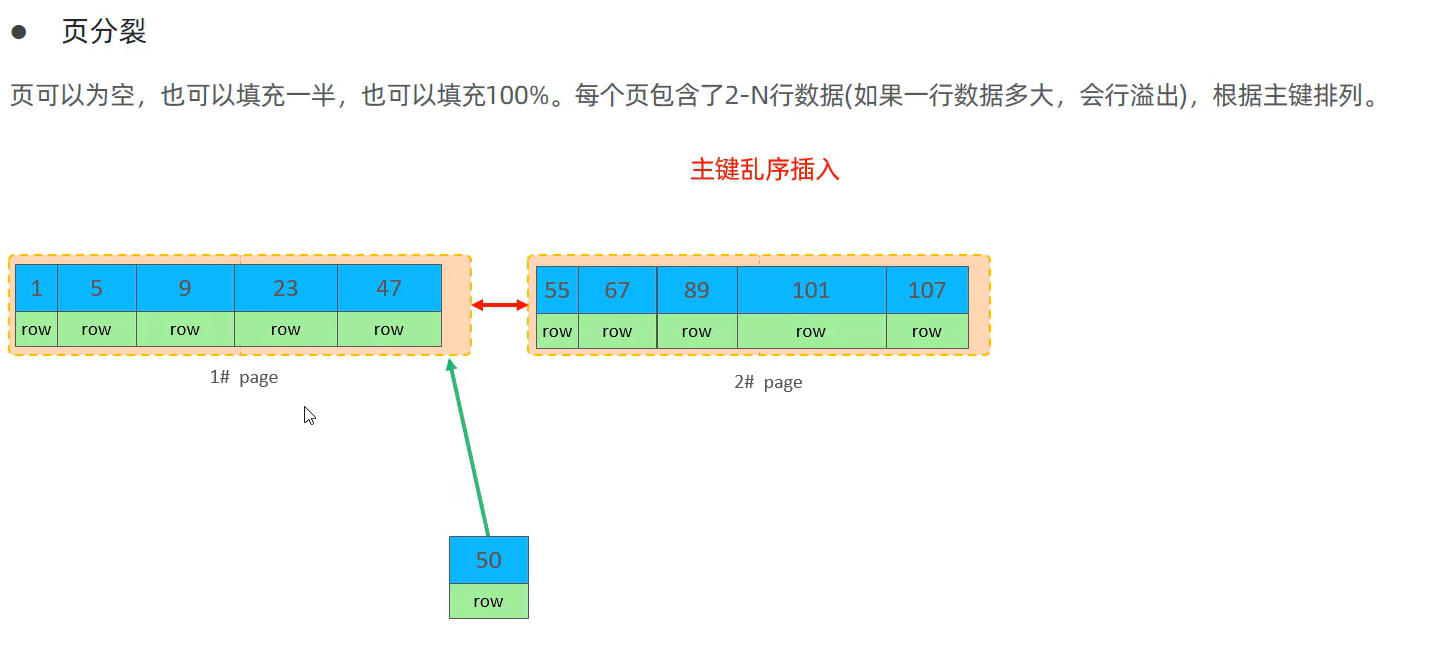
主键乱序插入会造成页分裂
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会造成行溢出),根据主键排列

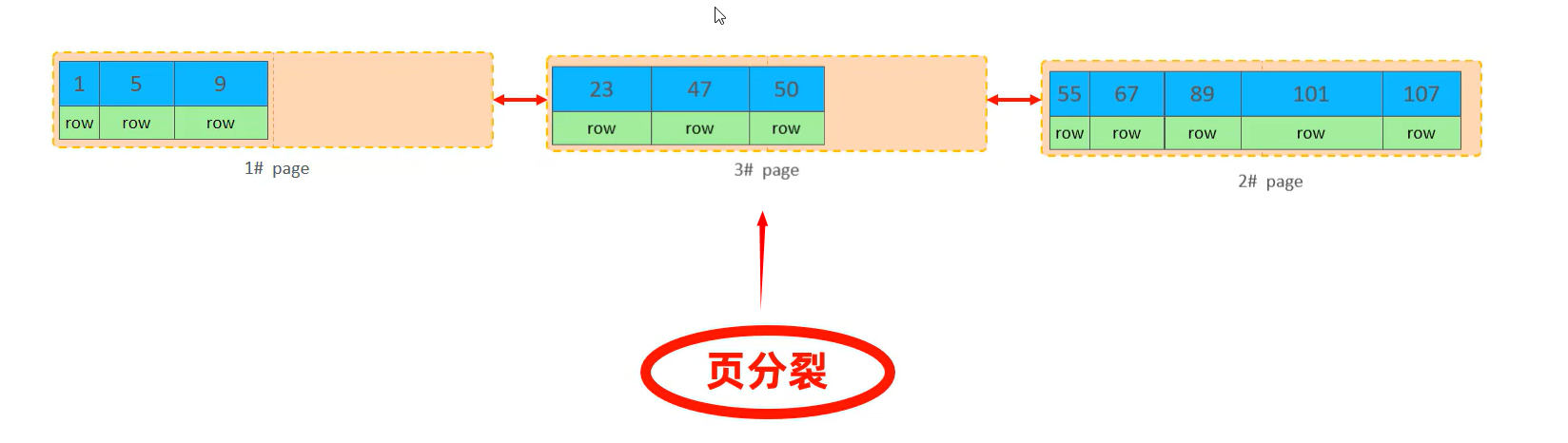
id为50的数据要插入,它应该存储在47以后的位置,但是该页已经不够存储这行数据了,它会开辟一个新页page3,id为50的数据不会直接放在page3中,而是将page1中后50%的数据一起放在page3中

最后需要对链表重新连接
2.3 页合并
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记 (flaged) 为删除并且它的空间变得允许被其他记录声明使用。当页中删除的记录达到MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用


知识小贴士:
MERGE THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
2.4 主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度
原因:二级索引结构下挂的是id,如果二级索引较多,id较长,会加大需要的数据库存储空间
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
原因:乱序插入时会造成页分裂
- 尽量不要使用UUID做主键或者是其他自然主键,如身份证号
- 业务操作时,避免对主键的修改
3 order by优化
1 Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引返回排序结果的排序都叫FileSort排序
2 Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高
有tb_user表,现根据age,phone排序,当age相同时,根据phone排序
没有创建索引时,根据age,phone进行排序 此时为Using filesort
explain select id,age,phone from tb_user order by age,phone;

#创建索引
create index idx_user_age_phone on tb user(age,phone);
#创建索引后,根据age,phone进行升序排序 此时为Using Index
explain select id,age,phone from tb_user order by age,phone;
#创建索引后,根据age,phone:进行降序排序 此时倒着扫描索引
explain select id,age,phone from tb user order by age desc,phone desc
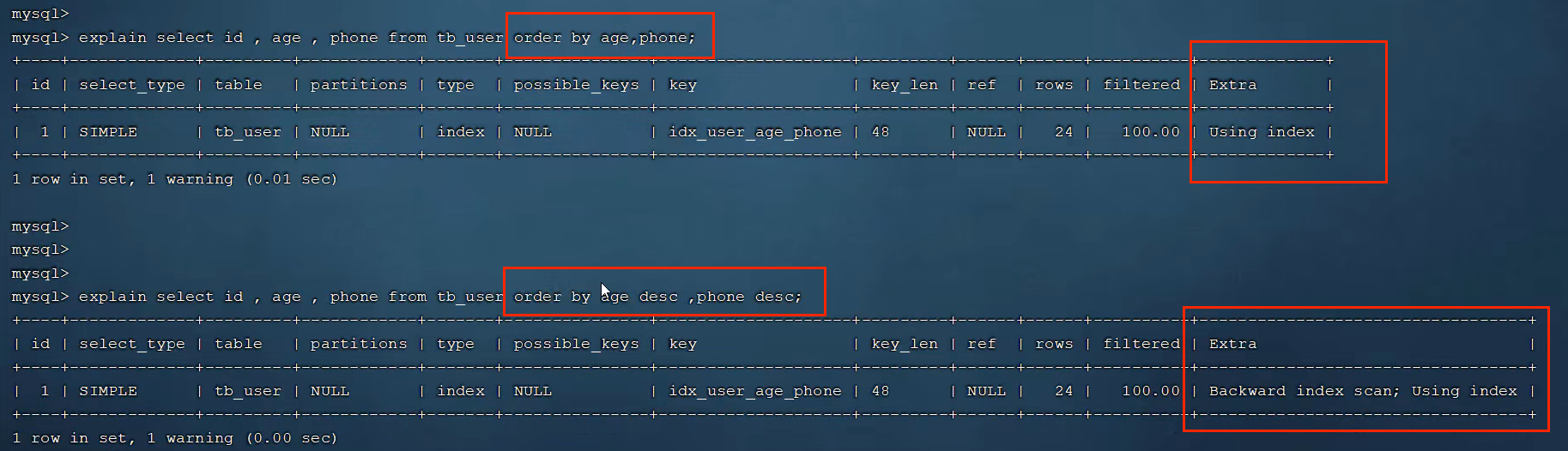
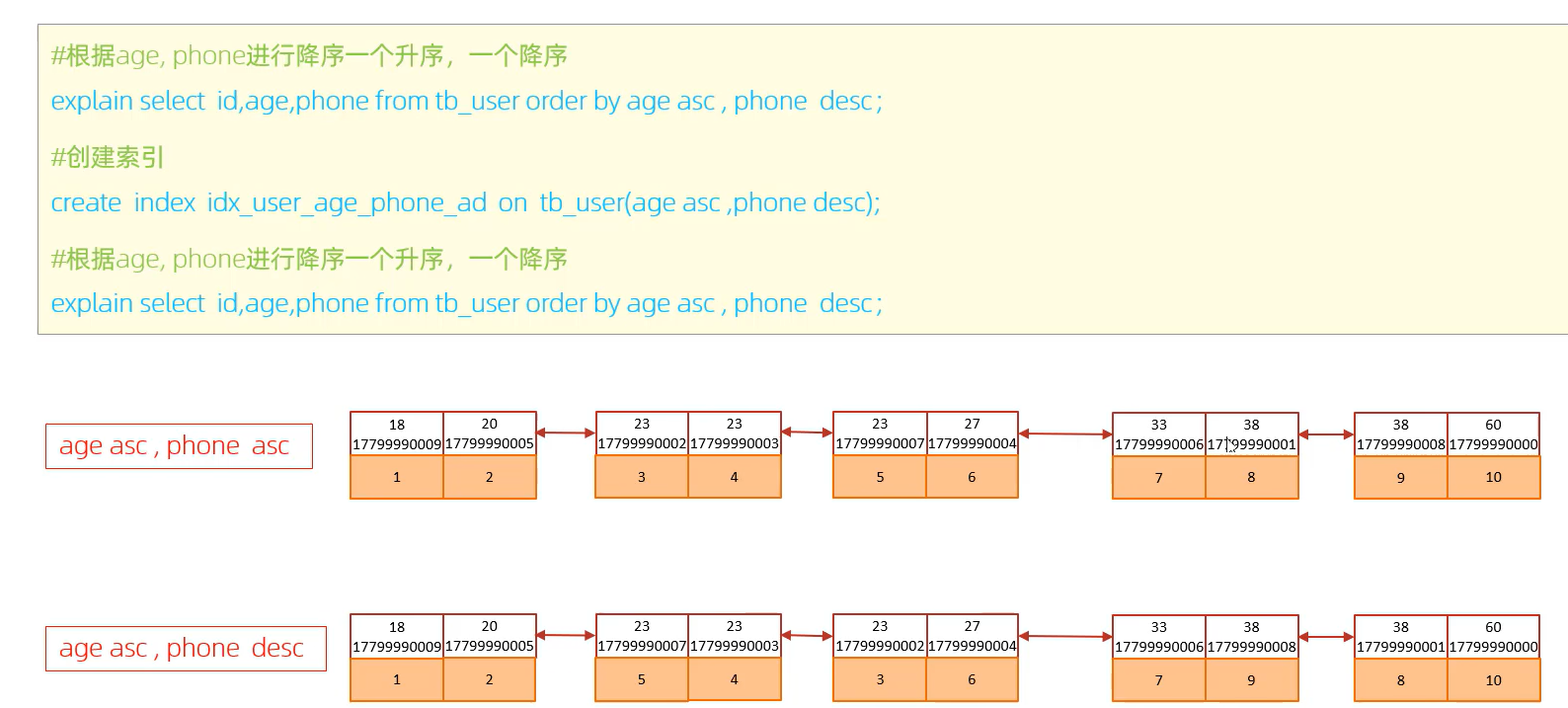
当我们的order排序条件为age升序,phone倒序时,age走索引,phone不走索引,因为创建索引默认是按照升序排序的,age为前缀索引,此时就无法倒着扫描phone索引


扩大缓冲区空间的原因:如果缓冲区空间不足,会在磁盘中开辟一块空间用来排序,效率低
4 group by优化
GROUP BY 是 SQL 查询中常用的功能,主要用于对结果集进行分组,以便进行聚合计算。不过,GROUP BY 操作可能会影响查询性能,特别是在处理大数据集时。以下是一些优化 GROUP BY 查询性能的策略:
1. 使用索引
- 创建索引:在
GROUP BY的字段上创建索引可以显著提高查询性能。索引帮助数据库更快地查找和排序数据。 - 组合索引:如果查询中涉及多个字段,可以考虑创建组合索引。分组操作时,索引的使用也是满足最左前缀法则的
2. 减少数据集大小
- 过滤条件:在
GROUP BY之前使用WHERE子句来过滤数据,减少处理的数据量。 - 选择必要的列:仅选择需要的列,避免使用
SELECT *,可以减少数据传输和处理的负担。
3. 使用合适的聚合函数
- 选择高效的聚合函数:使用更高效的聚合函数,例如
COUNT(*)相较于COUNT(column),后者需要检查列的值。
4. 避免重复数据
- 使用
DISTINCT:在某些情况下,可以使用DISTINCT代替GROUP BY,以避免不必要的分组操作。
5. 分区表
- 使用分区表:如果表非常大,可以考虑将其分区。分区可以提高查询性能,因为数据库只需扫描相关的分区。
6. 临时表或子查询
- 使用临时表:将复杂的
GROUP BY查询结果存储在临时表中,然后再对临时表进行查询。 - 子查询:使用子查询将部分计算结果提前计算出来,然后在外层查询中进行
GROUP BY。
7. 分析执行计划
- 查看执行计划:使用数据库的执行计划分析工具,查看
GROUP BY查询的性能瓶颈,找出慢查询的原因。
示例
-- 使用索引
CREATE INDEX idx_example ON your_table(column1, column2);
-- 使用 WHERE 子句过滤数据
SELECT column1, COUNT(*)
FROM your_table
WHERE condition
GROUP BY column1;
5 limit优化
在处理深分页(例如 LIMIT 10000000, 10)时,数据库的性能通常会受到严重影响,因为数据库需要扫描和跳过大量的记录才能返回所需的数据。
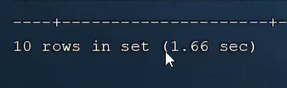
深分页 当limit100万时 查询为1.66s

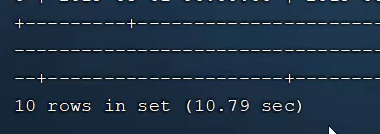
深分页 当limit500万时 查询为10.79s

深分页 当limit900万时 查询为19.39s

以下是一些处理深分页问题的策略:
(1)基于唯一标识符的分页:
1.使用索引:
- 确保在分页所依据的列上建立了索引。这可以加快记录的定位速度,但即使如此,深分页仍然可能涉及大量的跳过操作。
- 如果表中有一个唯一标识符(如自增主键),可以记录上一次分页的最后一个唯一标识符的值,并在下一次分页请求中使用这个值作为起点。例如,如果上一次分页的最后一个记录的ID是10000009,则下一次查询可以从ID大于10000009的记录开始,然后限制结果数量。
- 示例SQL:
SELECT * FROM table WHERE id > 10000009 ORDER BY id ASC LIMIT 10;(2) 一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
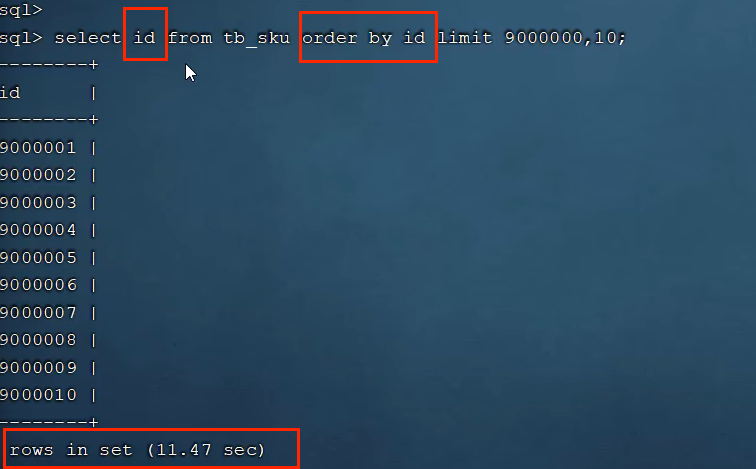
select * from tb_sku where id in (select id from tb_sku order by id limit 9000000,10)
为什么分步查询更高效?
如果直接执行:
SELECT * FROM tb_sku ORDER BY id LIMIT 9000000, 10;- 性能瓶颈:
-
- MySQL 必须扫描前 9,000,010 条记录,并加载完整的行数据(包括所有列),即便最终只需要 10 条记录。
- 加载和传输大量不必要的数据,增加了 I/O 和内存消耗。
而分步查询:
- 第一步:
-
- 只加载
id列,扫描性能更高,因为不需要访问行的其他数据。 - 即便有 9,000,010 条记录需要跳过,单列扫描的 I/O 开销远小于整行扫描。
- 只加载
- 第二步:
-
- 主查询只处理 10 条记录,根据子查询结果的
id精确定位行数据,避免大规模表扫描。
- 主查询只处理 10 条记录,根据子查询结果的
总结:分步查询中的数据访问量对比
| 步骤 | 直接查询 ( ) | 分步查询 |
| 第一阶段 | 扫描并加载 9,000,010 条完整行数据 | 扫描并加载 9,000,010 条 (单列数据) |
| 第二阶段 | 无 | 加载目标行(精确查询 10 条完整行数据) |
| 总开销 | I/O 和内存开销高,尤其在大偏移量时非常慢 | I/O 和内存开销更低,因分步减少不必要的数据传输 |
6 count优化
explain select count(*) from tb_user
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高;
InnoDB引擎就麻烦了,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累计计数
6.1 count的几种用法
count(主键)
InnoDB引擎会遍历整张表,把每一行的主键id值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)。
count(字段)
没有not null约束:InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为nul,不为nul,计数累加。
有not null约束:InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count (1)
InnoDB引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字"1”进去,直接按行进行累加。
count (*)
InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(*),所以尽量使用count(*)。
7 update优化
在update语句中where条件必须走索引,否则行锁会被升级为表锁,在并发时性能降低
7.1 InnoDB 的行锁机制
InnoDB 的行锁是基于索引实现的,而不是直接锁定表中的物理数据行。其工作方式是:
- 锁是加在索引记录上的,而不是直接加在数据行上。
- 如果 SQL 语句需要扫描的记录没有使用索引(或者索引失效),InnoDB 会锁住整张表(即表锁),而不是锁住特定的行。
7.2 行锁升级为表锁的原因
当 UPDATE 或 DELETE 语句的 WHERE 条件没有命中索引 时,InnoDB 无法通过索引定位到特定的行,只能扫描整张表。这时:
- InnoDB 不知道具体要锁定哪些行,因为没有索引支撑。
- 为了确保数据一致性,InnoDB 只能对整个表加锁(表锁)。
- 表锁会显著降低并发性能,因为其他事务需要等待锁释放。
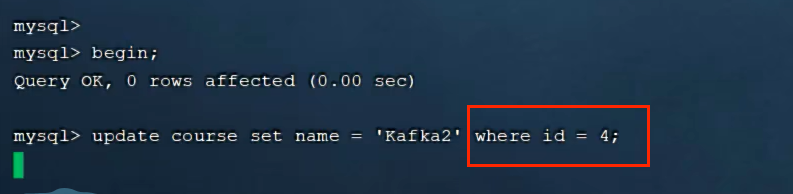
7.2.1当根据id修改时,行锁
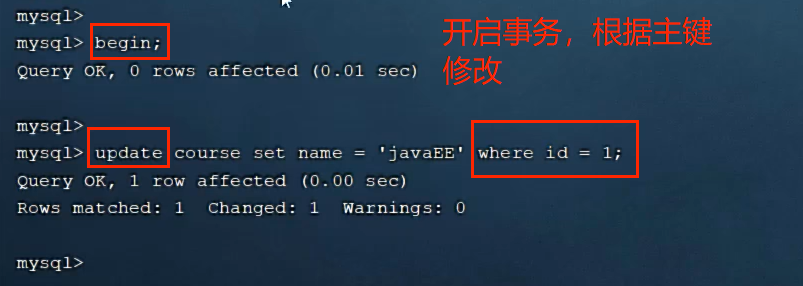
此时,另一个事务去修改另一行数据,可修改
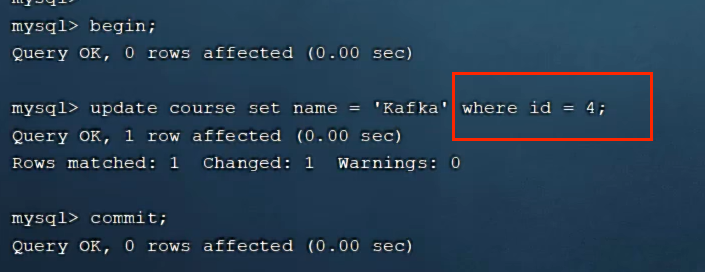
7.2.2 当根据非索引字段name修改时,表锁
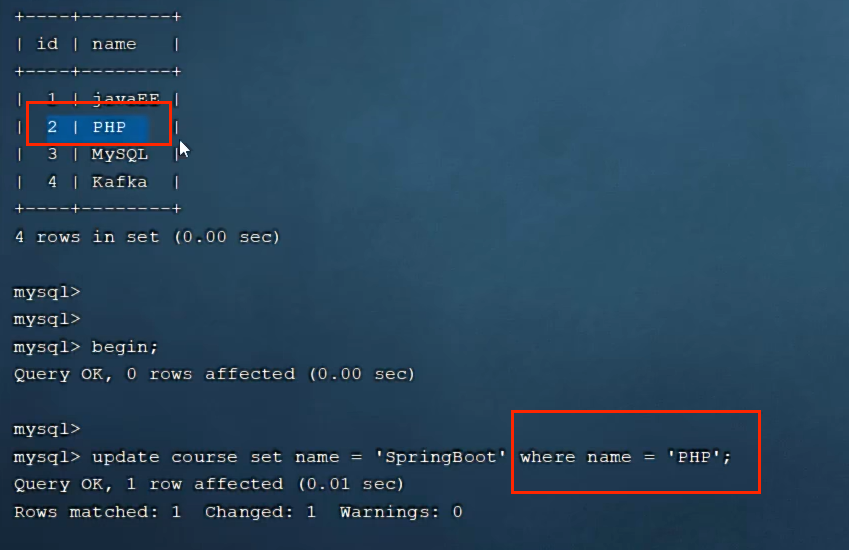
更新其它数据,此时无法更新