一. 关于前后端分离需要知道的一些术语
(一)什么是RESTful API?
要弄清楚什么是RESTful API,首先要弄清楚什么是REST。REST – REpresentational State Transfer,英语的直译就是“表现层状态转移”。如果看这个概念,估计没几个人能明白是什么意思。那下面就让我来用一句人话解释一下什么是RESTful:URL定位资源,用HTTP动词(GET,POST,PUT,DELETE)描述操作。RESTful 是典型的基于HTTP的协议。
Resource:资源,即数据。
Representational:某种表现形式,比如用JSON,XML,JPEG等;
State Transfer:状态变化。通过HTTP动词实现。
所以RESTful API就是REST风格的API。 那么在什么场景下使用RESTful API呢?在当今的互联网应用的前端展示媒介很丰富。有手机、有平板电脑还有PC以及其他的展示媒介。那么这些前端接收到的用户请求统一由一个后台来处理并返回给不同的前端肯定是最科学和最经济的方式,RESTful API就是一套协议来规范多种形式的前端和同一个后台的交互方式。
RESTful API由后台也就是SERVER来提供前端来调用。前端调用API向后台发起HTTP请求,后台响应请求将处理结果反馈给前端。也就是说RESTful 是典型的基于HTTP的协议。那么RESTful API有哪些设计原则和规范呢?
资源。首先是弄清楚资源的概念。资源就是网络上的一个实体,一段文本,一张图片或者一首歌曲。资源总是要通过一种载体来反应它的内容。文本可以用TXT,也可以用HTML或者XML、图片可以用JPG格式或者PNG格式,JSON是现在最常用的资源表现形式。
统一接口。RESTful风格的数据元操CRUD(create,read,update,delete)分别对应HTTP方法:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源,这样就统一了数据操作的接口。
URI。可以用一个URI(统一资源定位符)指向资源,即每个URI都对应一个特定的资源。要获取这个资源访问它的URI就可以,因此URI就成了每一个资源的地址或识别符。一般的,每个资源至少有一个URI与之对应,最典型的URI就是URL。
无状态。所谓无状态即所有的资源都可以URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而变化。有状态和无状态的区别,举个例子说明一下,例如要查询员工工资的步骤为第一步:登录系统。第二步:进入查询工资的页面。第三步:搜索该员工。第四步:点击姓名查看工资。这样的操作流程就是有状态的,查询工资的每一个步骤都依赖于前一个步骤,只要前置操作不成功,后续操作就无法执行。如果输入一个URL就可以得到指定员工的工资,则这种情况就是无状态的,因为获取工资不依赖于其他资源或状态,且这种情况下,员工工资是一个资源,由一个URL与之对应可以通过HTTP中的GET方法得到资源,这就是典型的RESTful风格。
说了这么多,到底RESTful长什么样子的呢?
GET:http://www.xxx.com/source/id 获取指定ID的某一类资源。例如GET:http://www.xxx.com/friends/123表示获取ID为123的会员的好友列表。如果不加id就表示获取所有会员的好友列表。
POST:http://www.xxx.com/friends/123表示为指定ID为123的会员新增好友。其他的操作类似就不举例了。
(二)RESTful API设计准则
应该尽量将API部署在专用域名之下 [https://example.org/api/]
应该将API的版本号放入URL [https://example.org/app/1.0/foo], 但这个是不强制的
路径又被称为终点,表示API的具体地址,每个地址代表一种资源。资源只能是名词不能是动词,而且名词往往和数据库的表名相对应。同时,利用HTTP方法(post, get, put, delete)可以分离网址中资源名称的操作。
GET /products #返回所有的产品清单
POST /products #将产品新建到集合
GET /products/4 #将获取产品4
PATCH /products/4 #更新产品4(客户端提供改变后的完整资源)
PUT /products/4 #更新产品4(客户端提高改变的额属性)
DELETE /products/4 #删除产品4
HEAD #获取资源的元数据
OPTIONS #获取信息
API中的名词应该使用复数,无论是子资源或者所有资源
过滤信息;如果记录数量很多,服务器不可能都将它们全部返回。API需要提供参数,过滤返回结果
?limit=10 #指定返回记录的数量
?offset=10 #指定返回记录的开始位置
?page=2&per_page=100 #指定第几页,以及每页的记录数
?shortby=name&order=asc #指定返回结果按照哪个属性排序以及排序顺序
?animal_type_id=1 #指定筛选条件
RESTful API最好做到Hypermedia(即返回结果中提供链接,连向其它API方法)
服务器返回的数据格式,应该尽量采用json格式,避免使用XML
(三)后端开发(REST接口开发)的核心任务
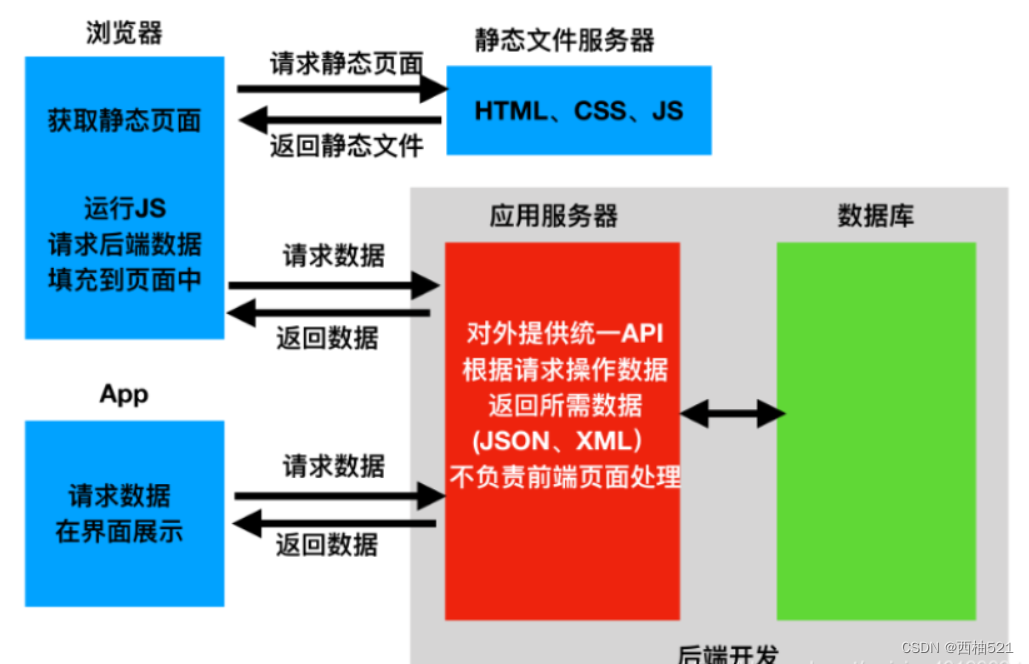
后端只负责返回前端需要的数据,不再渲染HTML页面,不再控制前端的效果。无论哪种前端,所需的数据基本相同,所以后端只需要开发一套逻辑对外提供数据就可以了。
在前后端分离的应用模式中,我们通常将后端开发的每个视图都称为一个接口,或者API,前端通过访问接口来对数据进行增删改查。
将请求的数据(如json格式的数据)转换成模型类对象
操作数据库
将模型类对象转换成响应的数据,比如Json格式
因此:数据类型的转换就涉及到序列化和反序列化:
在开发REST API 接口时,视图中要频繁地进行序列化和反序列化的编写。
(四)序列化和反序列化
序列化:将程序中的一个数据结构类型转换为其它格式(字典,json, xml等),比如将django中的模型类对象转换为json字符串,这个转换过程我们成为序列化。
books_all=Books.objects.all()
book_list=[]
#序列化
for book in books_all:
book_list.append({
'id':book.id,
'title':book.title,
'author':book.author,
'publish_time':book.publish_time
})
return JsonResponse(book_list, safe=False)
反序列化:将其它格式(json,字典,XML等)转换成程序中的数据。例如将Json字符串转换成Django中的模型类对象。
json_bytes=request.body
json_str=json_bytes.decode()
#反序列化
book_dict=json.loads(json_str)
book = Books.objects.create(
title=book_dict.get('title'),
publish_time=datetime.striptime(book_dict.get('publish_time'), '%Y-%m-%d').date()
)
二. 使用前后端分离的优缺点
(一)优点
1、耦合度低, 前端通过访问接口来对数据进行增删改查
2、快速实现序列化和反序列化;提供了定义序列化器serilizer的方法,可以快速根据Django ORM或者非ORM数据源序列化/反序列化
3、提供了丰富的类视图, Mixin扩展类,简化视图的编写
4、丰富的定制层级:函数视图/类视图/视图集合到自动生成API,满足各种需求
5、多种身份认证和权限认证方式的支持,认证策略包括OAuth1和Oauth2的包
6、内置了限流系统
7、直观的API web界面
8、可扩展性,插件丰富
9、适合开放性高的API。这几年的由于移动互联网流行使得前端设备多样化,业界急需一种统一的机制来规范API设计,使得API适用于各 种各样的前端设备,REST符合这种需求。
10、行为和资源分离,更容易理解。
11、提出使用版本号(例如v1、v2),更加规范。
12、前后端分离,减少流量(减少后端服务器的并发压力,除了接口以外的其他所有http请求全部转移到前端服务器上。
页面不再是全局刷新,而是异步加载,局部刷新,减轻压力。)
13、安全问题集中在接口上,由于接受json格式,防止了注入型等安全问题
14、前端无关化,后端只负责数据处理,前端表现方式可以是任何前端语言(android,ios,html5)
15、前端和后端人员更加专注于各自开发,只需接口文档便可完成前后端交互,无需过多相互了解
16、服务器性能优化:由于前端是静态页面,通过nginx便可获取,服务器主要压力放在了接口上
(二)缺点
1、对后端开发人员要求高,业务逻辑有时难以被抽象为资源的增删改查。
2、对前端开发人员不友好,API粒度较粗,难以查询符合特殊要求的数据,同样的业务要比普通的API需要更多次HTTP请求。
业务逻辑有时难以被抽象为资源的增删改查。
3、对前端开发人员不友好,API粒度较粗,难以查询符合特殊要求的数据,同样的业务要比普通的API需要更多次HTTP请求。