非静无以成学。——诸葛亮
数据结构概括
1、什么是数据结构呢?
如果让我现在来看的话,数据结构是什么,我觉得就是数据存储的一种方式,在特定条件要求之下存储的数据能够在我们需要的条件下实现高效的优化。换简单的话说,这就是像是,你即使在你自己的书房中找自己的书本,都可能比你去图书馆问图书管理员找到一本特定的书的时间长,因为图书馆存储书的时候是会根据特定的方式去存储(换句话说这时候的数据就像是按照特定的一种数据结构存储,而你自己的却像是没有做过处理的数据)。
所以学习数据结构是为了方便对于不同数据然后解决不同问题时候的加快速度和效率的方式。
2、讲述过的结构
2、1、前言
对于之前讲过的数据结构来说的话,会详细的讲解这些类似的特点,或者其中有关于模拟实现时候的会出现的比较容易出错的地方。这里的讲述是概括,同时也是对于之前文章以及知识点的回顾。
我在写这篇文章的时候也知道了前几篇文章的一些优缺点,已近创建文件夹准备在之前文章的基础上加上番外。等这篇写完+Linux差不多之后就可以正式“启航”。
2、2、树->二叉树->两种平衡二叉树
这个部分就是概括一下之前讲过的一些数据结构,像是之前的由树的结构一步一步的推导得到树的结构的作用,树结构的缺点和可能实现的数据结构的形式,由此一步一步的深入,让我们知道,树结构的明显缺陷是不能够有多大的意义,就是说,一个父节点如果有太多的子节点的话可能会造成数据的冗杂,我们如果想通过父节点找到子节点的话可能没有太多的优势,如果说,一个父节点直接拥有的子节点就是剩下来的所有数据的话,显然,是一个又臭又长的,没有意义的树结构。
所以在此基础之上,我们学习二叉树,二叉树就是在树的基础之上进行的改进,让父节点只有两个子节点,并且依次下去。当子节点作为父节点的时候,其的子节点也只能最多有两个。此时的话,如果将我们的数据导到这样的数据结构,根据特定的排序方式能够实现最终在查找等方面上实现 对数级别的优化。当然对数级别的优化是存在的,但是往往现实中也会出现一些比较巧合的时刻,会对我们的二叉树进行降维打击,把一个我们辛辛苦苦维护起来的树给弄成链表,还是单链表的结构。如果想要了解更多,或者说之前学过,但是现在忘记了的话,可以看看作者之前写的关于树结构的文章。
这是一个入门级的关于树的文章。
这是一个扩展关于二叉树的文章。
这是一个优化二叉树缺点的文章一。AVL树
这是一个优化二叉树缺点的文章二。红黑树
其中好像是少讲了一个数据结构关于二叉树拓展,堆结构。这个在这个月一定会出的!(立下flag=1)
2、3、单链表->双链表->带有哨兵位的链表
对于单链表来说,这里介绍了单链表,以及讲述了单链表的实现方式,可能存在的问题(包括开始时候创建头节点需要用到二级指针之类的问题)。
这里的文章中介绍的链表实现方式是先假定plist为空,如果第一个设置为哨兵位的话,就能够不考虑是否为空,也不需要考虑第一个是否存在,是否需要处理。
这就是带有哨兵位的好处。
对于双链表的话就是说每个节点除了能够指向后一个节点之外,还能指向前一个节点,有时候这样的操作是很重要的。
3、B树
3、1、概念及图示
直接看的话,其实能够知道这个数据结构代表的含义就是树的结构。
然后更近一步理解的话,B树的特性是一个父节点有着多个的子节点,每个子结点中能够存储多个数,而不是像之前二叉树只存两个,一个左,一个右,并且他们还都只是包含一个Value值。
但是这也像是之前说的感觉可能没多大用处的树的变形,之前那个没多大用处的树是由于每一个节点存放子节点不受约束,没有控制条件,所以才被我称为没有用的树,但是这里的话,B树的存在能够缓解CPU和磁盘上的数据交互带来的数据访问时间上的优化。
那是因为如果是一个平衡二叉树的话,相比较而言想要在其中找到一个数,必须要从根目录开始,一次只能访问一个数,但是相对于B树来说的话,B树一次访问能够访问多个数,能够做到避免生成单支二叉树的同时减少CPU调度内存访问磁盘的时间。(对于磁盘来说,当读取地址连续数字的时候和读取一个数字的时间相差不大)
这里的话为什么能够实现小的原因就是因为冯诺依曼结构的特点,是按照CPU为中心,但是CPU只能通过内存来访问。
本质上相对于之前的两个树来讲的话,这个B树相当于是一个多叉平衡搜索树。
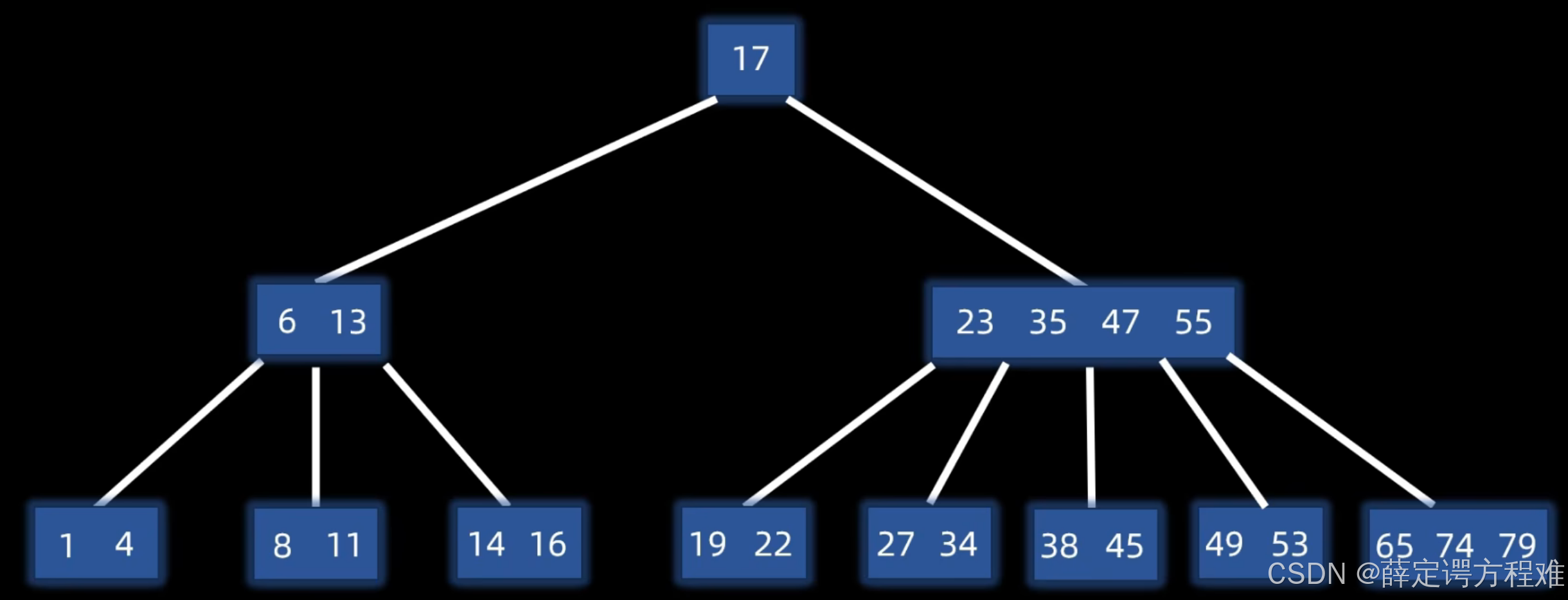
类似的话就长这个样子。
对于上图知道是一个B树的情况下,还能够更加细致的描述,这是一个几阶的B树。
对于这样的一个B树而言,这个树是一个5阶B树。
注意:B树可以是多个阶的树,不止5阶,也有可能超过5阶。
B树的特点就是:
1、所有的叶子节点都在一层
2、任何一个节点内部的数据都是有顺序的,任何一个节点的左子树都小于该节点,右子树都大于该节点。
3、对于一个m阶B树,任何一个节点最多m个分支,m-1个元素。
特别的对于根节点来说,最少会有两个分支,一个元素,对于其他节点来说,有[m/2]个分支,[m/2]-1个元素(这里是上取整的含义)。
3、2、B树数据处理
3、2、1、查找
对于B树来说,一个简单的图示结构就像是上面的那样,如果想要在其中找到一个特定的数值,我们需要类似于像二叉树那样,从根节点开始,然后依次根据判断,是去左还是右还是中间的某一个地方。这里的话,由于每一次读取可能会读取到多个数,所以进行比较的时候有两个方法,一个是一个一个一个比较,还有一种就是类似于二分法来进行比较。但是这里的方法还是看m阶的B树到底有多大,如果真的m很大的话,二分法提升判断速度才会和顺序比较有明显的区别,要不然数据较小的话,还是直接顺序实现比较简单的。
3、2、2、插入
对于一个B树的维护,插入操作是必不可少的,对于插入来说,如果一个节点的数据超过了规定的m阶的限制,那么对于多出来的数据就可能需要向上移动,调整节点数据的个数,从而保证数据的合理性。如果遇到上一个节点中的数据也超过了规定的上限的话就需要再向上移动,**这个操作挺像之前的那个AVL树,当平衡因子的绝对值为2的时候,需要的操作类似。**只有当符合条件之后,才能够算插入完成。
4、哈希表
4、1、概念
对于哈希表的理解,我们从一个简单易懂的实例来理解。
假设你是一个老板,开着一家说大不大说小不小的有着将近1000个不同商品价格的“小”超市。如果每次用户来付钱的话,你作为老板是希望,对着将近1000个产品的价格表来寻找,还是说直接能够找到价格。那肯定是后者了。
实际上对于数据结构来说,像前面的一个一个的存储的话,这就像是一个数组来进行操作,要找特定的产品名称就需要遍历数组,然后才能够找到对应的值。每一次的遍历都需要花费接近O(N)的时间。
而对于老板的第二种表现来说,其实就是哈希表的作用,通过一个存储的形式,能够每一次的填入一个数,都能够通过某种形式来实现结果的返回,这里的结果的返回每次输入的是一样的话,返回的也是一样的。输入不同的,返回的也是不同的,但是返回的数据都是有着特定关系的,并不是随意返回的。这里的神秘操作就是哈希表的作用。
4、2、哈希解决简单算法
对于哈希表具体怎么实现,其实通过一个简单的例题就能够帮助我们理解。
题目找不到原题了,但是具体细节就是,给一段字符串,其中只会出现大小写字母,然后让我们去找到出现最多的符号。
这里的题目的话就能够用哈希表来帮助我们解决问题。对于这个问题,我们简单的设置一个数组128的,这里的128能够存储题目所规定的各个符号。然后遍历一遍所给的字符串,相同的字符串出现时候所加的1是在同一个位置(这里能够直接hash[x-‘a’]来实现不超过128并且能够存下所有可能的字符),然后遍历完一遍之后,再走一个128,就能够找到最大的值了。
这里哈希表的特定操作很简单,就是将字符串都减去字符a的大小,剩下的值就是存储在hash中的位置。
==对于这个来说,这个定义是简单的,因为题目所要求的就是很简单的。==但是我们如果要解决更难一点,或者更复杂一点的问题的时候,特定的规律,或者说是映射就不会像现在这样简单。这样的话,就能够帮助我们实现时间上的提升。
4、3、实际问题
对于现在的网络环境来讲,我们需要时刻注意在网上下载软件的时候会不会出现网络拦截或者说下载错误的情况,这时候就用到了MD5,这就是以一个哈希的实际运用,对于一个几个G的文件来说,如果能够下载下来的话,是必须要保证文件的完整性,这时候就需要用到hash,因为hash的特性就是改变任何形式的时候输出的结果都是不一样的,我们可以将下载之后的文件和下载前提供的MD5码相对比,如果是一样的话,就说明没有问题。如果不一样,那就说明其中肯定是存在文件的错误或者遗漏。
5、图
5、1、概念和图示
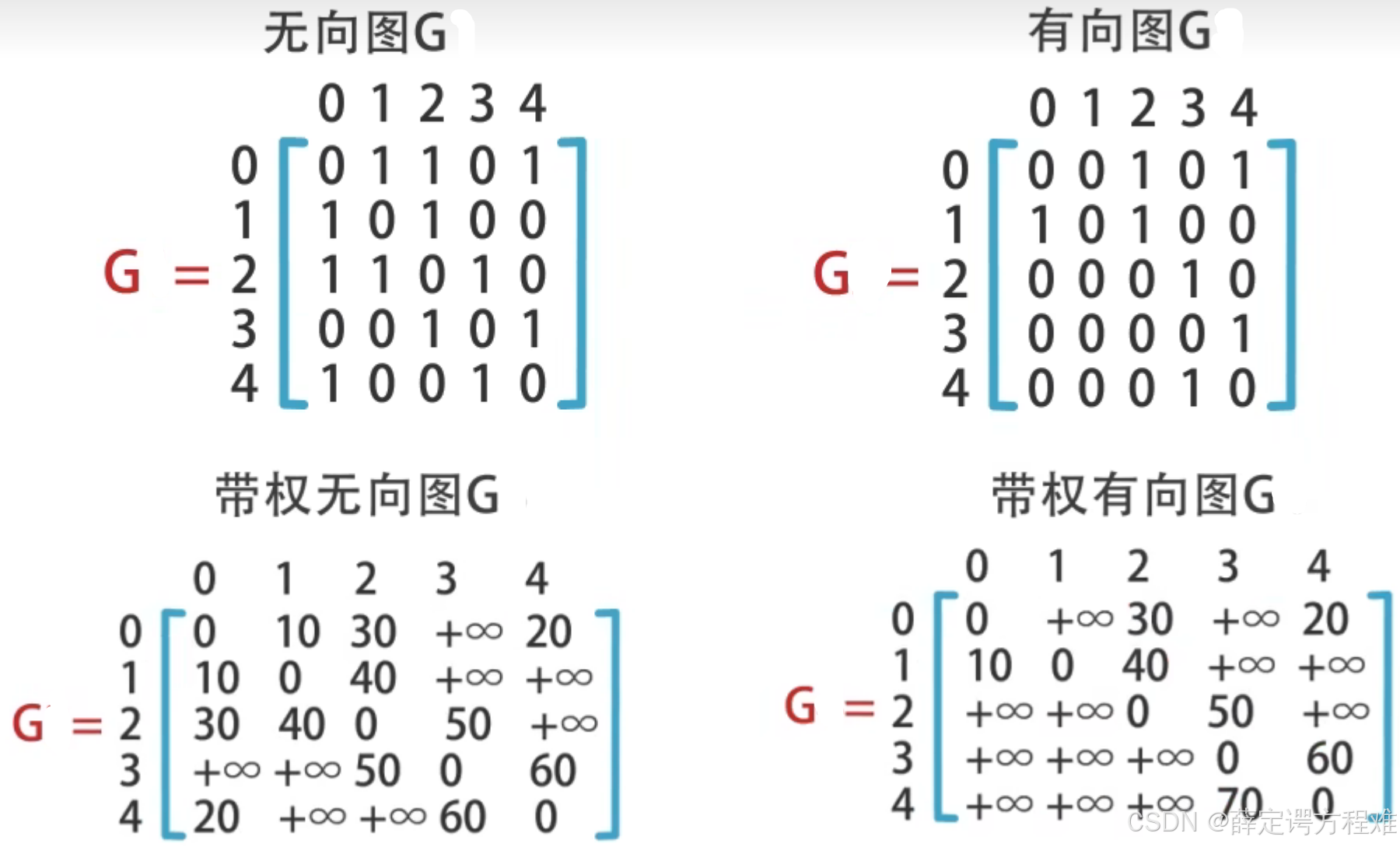
图的形式有很多种。图的表示方式为G(V,E),其中G表示的就是整个的图的结构,V表示的是节点,E表示的是边。
通常来说,图分为有向图和无向图,带权或者不带权,还能够分为连通或者非连通。
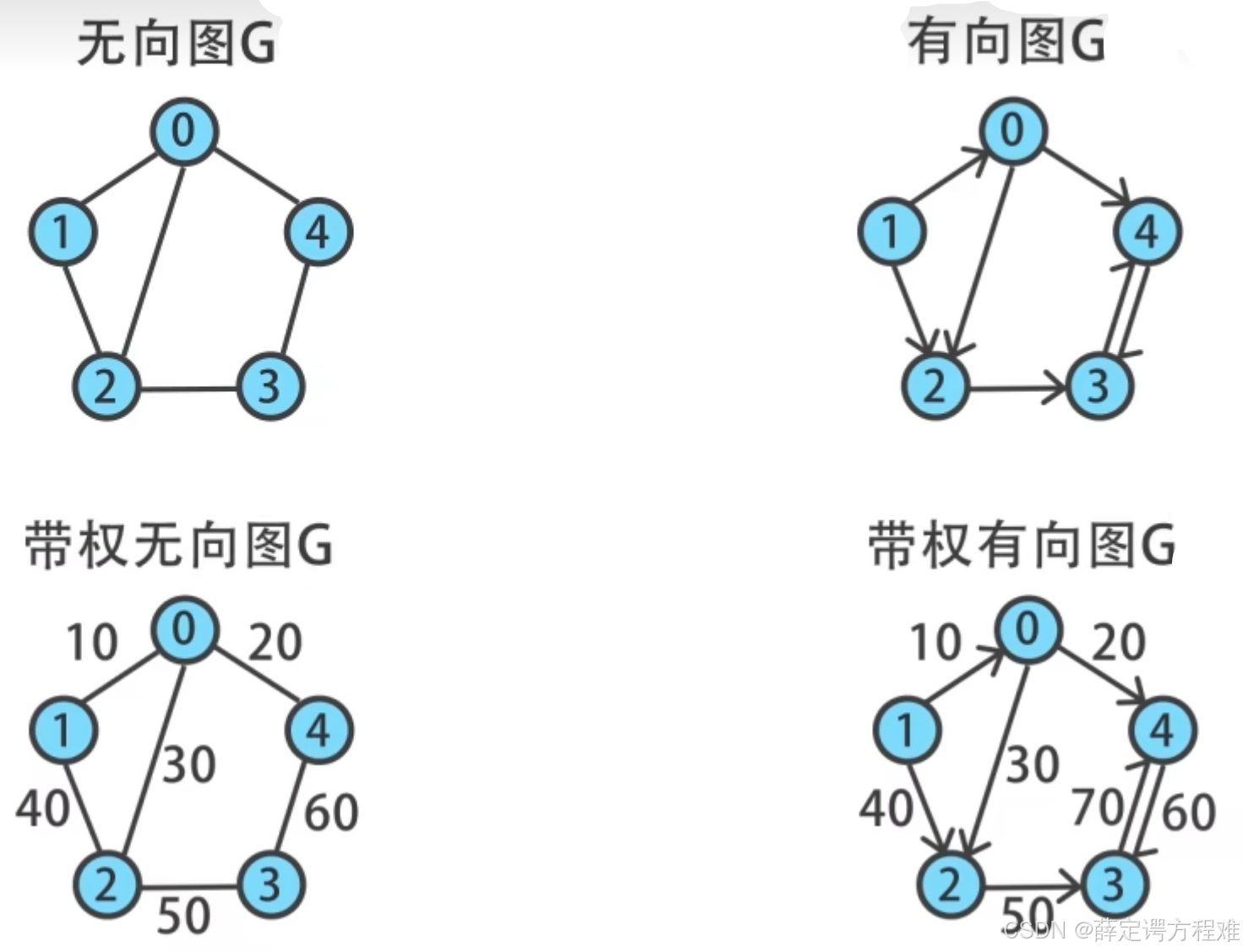
其中的权值,能够代表不同的代价,可能是通过两个节点需要的时间,或者说是金钱,经历,距离等等。
其中的有向,能够代表节点之间的可行性,可能会规定某些特定情况下不能够两个节点相互交换。此时有向的时候不同方向,但是还是一个边的时候的权值也有可能是不同的。
5、2、图的实现方式
如果想要实现一个简单的图的话,我们可以通过二维数组来构建。此时这个数组又称为邻接矩阵。
这样的二维数组就能够表示举出示例的那个图的形式。
这个二维数组中,如果不带权的图的话,0或者1代表的就是是否连通两个节点是否连通。
带权的图,矩阵代表的不连通顶点之间的权值是正无穷,来表示顶点之间无法到达,自己到自己的权值是0。
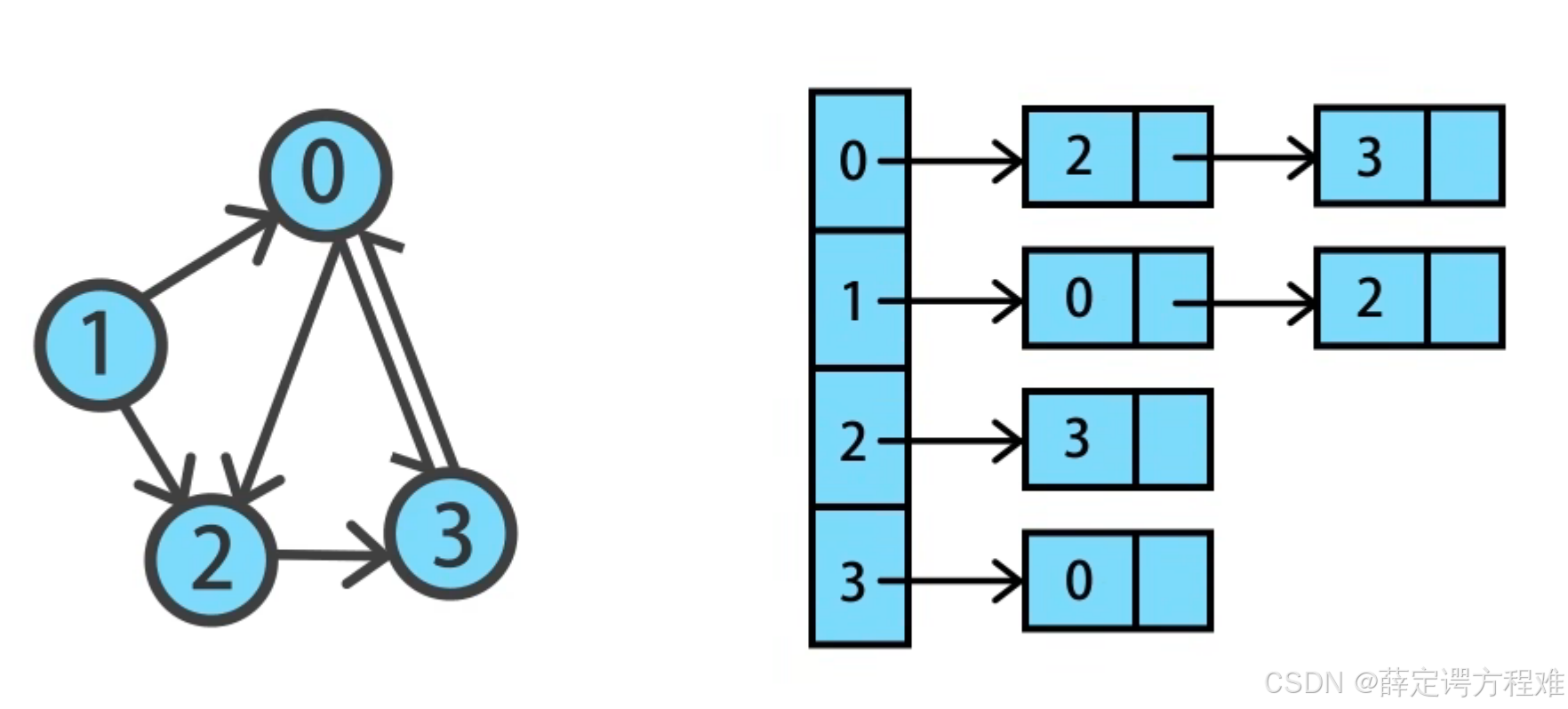
除此之外,我们还能够使用链表来存储图,使用链表的表示方法被称为图的邻接表。
这时候,这是一个顺序和链式相结合的存储方式,表头表示的是图的节点数组,每个节点后连接一个链表,存储这个顶点连接的其他顶点。
这两种方式表示的图会稍微有点不同,当图为稠密图的时候,我们使用邻接矩阵来表示,图为稀疏图的时候用邻接表来表示。
5、3、图的深度/广度优先遍历
无论是深度优先遍历还是深度优先遍历都是一种想要走过图中每一个顶点,不遗漏,不重复的走过。
这里的图深度优先遍历要是之前了解过深度优先遍历的话,这里的特性也还是那样的方式,特点几乎都是没有什么变化的,没什么特别的,也是从起点开始一个一个的走过节点,当遇到无法下一个的时候,开始回溯之前有多个路径选项的时候,然后再一次的进行深度遍历,直到所有的节点都走完。当然这里在遍历节点的时候多个选项的时候可能会因为每个人编写的代码不同导致最后的遍历结果也有所不同。
图的广度优先遍历和之前的广度优先也是差不多的。掌握广度优先之后,以此类推到图的话,那就是图的广度优先遍历。这里的话一个顶点可能有多个相连接的顶点,其中也会有差别,所以也可能会存在一个节点,但是最后生成的路径反而是不一样的。
6、位图
6、1、概念
对于位图来说,这里需要掌握的是,关于位的操作,什么是关于位的操作呢?
首先需要知道的是,存在位操作是因为一个数字在存储的时候不是说就像是我们看到的那样,只存数字表面那样,存储在内存中的时候一个数字能够占据32位,这32位0-1共同表示出一个数字,此时的32位就是我们说到的位的含义。我们的操作也是根据这样来进行的。
而对于位图来说,对于不同问题,但是能够用二项分布这样类似的形式表示出来的就能够利用位图来实现数据存储以及利用。对于一个顶点来说,最多只有两个状态,0-1分别表示这两种状态就行了。
6、2、实际应用
对于位图来说,这样的存储方式能够大大的减少内存的消耗量,能够对一个拥有大数据的实例就行优化数据,一个整型能够代替32个原本的数据内存。这让我们运行时候对于内存的压力减小。
7、最小生成树(MST)
7、1、概念
对于最小生成树这样的概念,为了能够方便我们理解,可以把这个词分开成为多个,然后分别理解。
首先是其中的最后一个字,虽然这其中有树的字,但是这不是一个简单的树。
这里的最小生成树的结构实际上是上面图的基础上的定义拓展使用得到的数据结构。如果记得树结构就是最好的了,可以先想一想之前树的结构是什么,这里就是用到树的结构来推导到图中。通过树的结构,我们能够很容易的观察到,有n个节点的时候,就必定会有n-1个边,并且没有环生成的,此外还是一个连通的。
综合上述的特点,能够总结在图之上扩展的最小生成树的其中的树拥有以下几种特点:
1、是一个无向连通非循环图
2、如果在图中添加任意一条边,则立即形成环路
3、途中任意两点之间,有且仅有一条独特的路径
4、途中有n-1条边,n为图中顶点的数量
这里可以想一下之前讲述过的AVL或者红黑树的定义,这里的定义总是相互有关联的。这里的图的树的结构也是如此。对于第一条来说是一个总体的概括,对于后面的其他几条来说,是对第一条的补充,后面三条的内容也是相互印证的。
其中的生成代表的就是利用一个图来转换出符合上述条件的“树”出来。
而最小表示的就是所生成的结构中边权和最小。
既然可能不太明白这样的数据结构的概念的话,我来举个例子。实际生活中我们可能会存在新建几个城市,那么城市间的建造高速的成本将会有所不同,目的是要让所有的城市之间都能够连通,但是花费需要最少,那么在一开始规划的时候,肯定是两两城市之间都做了相对应的估算,大概需要花费多少的成本,而最小生成树的应用就在这里,从一个两两城市之间都有权值的图结构简化到最小生成树,这样就能得到需要花费的最小成本。
这里实现图的方法有两个,一个是普里姆(Prim)算法,还有一个就是克鲁斯卡尔(Kruskal)算法具体就不细讲了,因为讲起来的话会脱离本文的纲要的概念,有兴趣的可以自行搜索,到时候我出到这一篇的时候也会在详细讲的。