在上篇文章中YOLO11环境部署 || 从检测到训练https://blog.csdn.net/2301_79442295/article/details/145414103#comments_36164492,我们详细探讨了YOLO11的部署以及推理训练,但是评论区的观众老爷就说了:“博主博主,你这个只能推理只能推理图片,还要将图片放在文件夹下,有没有更简单方便的推理方法?” 有的兄弟,有的,像这样更简单的方法还有10086个,下面我挑一个用于流式视频文件检测。
视频文件
对于视频或者摄像头等输入,可以将以下代码复制到predict_camera.py运行检测:
from ultralytics import YOLO
import cv2
import torch
from pathlib import Path
import sys
import os
import tkinter as tk
from tkinter import filedialog
def choose_input_source():
print("请选择输入来源:")
print("[1] 摄像头")
print("[2] 视频文件")
choice = input("请输入数字 (1 或 2): ").strip()
if choice == "1":
return 0, "摄像头"
elif choice == "2":
#选择视频文件
root = tk.Tk()
root.withdraw()
video_path = filedialog.askopenfilename(
title="选择视频文件",
filetypes=[("视频文件", "*.mp4;*.avi;*.mkv;*.mov"), ("所有文件", "*.*")]
)
if not video_path:
print("未选择视频文件,程序退出")
sys.exit(0)
return video_path, video_path
else:
print("无效的输入,程序退出")
sys.exit(1)
def detect_media():
# ======================= 配置区 =======================
# 模型配置
model_config = {
'model_path': r'E:\git-project\YOLOV11\ultralytics-main\weights\yolo11n.pt', # 本地模型路径,注意配置!!!!!!!!!!!!!!!!!!!!!!!
'download_url': 'https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt' # 如果没有模型文件下载URL
}
# 推理参数
predict_config = {
'conf_thres': 0.25, # 置信度阈值
'iou_thres': 0.45, # IoU阈值
'imgsz': 640, # 输入分辨率
'line_width': 2, # 检测框线宽
'device': 'cuda:0' if torch.cuda.is_available() else 'cpu' # 自动选择设备
}
# ====================== 配置结束 ======================
try:
# 选择输入来源
input_source, source_desc = choose_input_source()
# 初始化视频源
cap = cv2.VideoCapture(input_source)
if isinstance(input_source, int):
# 如果使用摄像头,设置分辨率
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 720)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
if not cap.isOpened():
raise IOError(f"无法打开视频源 ({source_desc}),请检查设备连接或文件路径。")
# 询问是否保存推理出的视频文件
save_video = False
video_writer = None
output_path = None
answer = input("是否保存推理出的视频文件?(y/n): ").strip().lower()
if answer == "y":
save_video = True
# 创建保存目录:代码文件所在目录下的 predict 文件夹
save_dir = os.path.join(os.getcwd(), "predict")
os.makedirs(save_dir, exist_ok=True)
# 获取视频属性(宽度、高度、fps)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
if fps == 0 or fps is None:
fps = 25 # 如果无法获取fps,设定默认值
# 构造输出视频文件路径
output_path = os.path.join(save_dir, "output_inference.mp4")
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
video_writer = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))
print(f"推理视频将保存至: {output_path}")
# 加载模型(带异常捕获)
if not Path(model_config['model_path']).exists():
if model_config['download_url']:
print("开始下载模型...")
YOLO(model_config['download_url']).download(model_config['model_path'])
else:
raise FileNotFoundError(f"模型文件不存在: {model_config['model_path']}")
# 初始化模型
model = YOLO(model_config['model_path']).to(predict_config['device'])
print(f"✅ 模型加载成功 | 设备: {predict_config['device'].upper()}")
print(f"输入来源: {source_desc}")
# 实时检测循环
while True:
ret, frame = cap.read()
if not ret:
print("视频流结束或中断")
break
# 执行推理
results = model.predict(
source=frame,
stream=True, # 流式推理
verbose=False,
conf=predict_config['conf_thres'],
iou=predict_config['iou_thres'],
imgsz=predict_config['imgsz'],
device=predict_config['device']
)
# 遍历生成器获取结果(取第一个结果)
for result in results:
annotated_frame = result.plot(line_width=predict_config['line_width'])
break
# 摄像头模式下显示FPS
if isinstance(input_source, int):
fps = cap.get(cv2.CAP_PROP_FPS)
cv2.putText(annotated_frame, f'FPS: {fps:.2f}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示实时画面
cv2.imshow('YOLO Real-time Detection', annotated_frame)
# 如保存视频,写入视频文件
if save_video and video_writer is not None:
video_writer.write(annotated_frame)
# 按键退出q
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
if video_writer is not None:
video_writer.release()
cv2.destroyAllWindows()
print("✅ 检测结束")
if save_video and output_path is not None:
print(f"推理结果视频已保存至: {output_path}")
except Exception as e:
print(f"\n❌ 发生错误: {str(e)}")
print("问题排查建议:")
print("1. 检查视频源是否正确连接或文件路径是否正确")
print("2. 确认模型文件路径正确")
print("3. 检查CUDA是否可用(如需GPU加速)")
print("4. 尝试降低分辨率设置")
if __name__ == "__main__":
detect_media()
需要更改的参数:
1.model_path:模型文件位置,默认使用的是yolo11n.pt
2.predict_config下置信度等
3.分辨率等
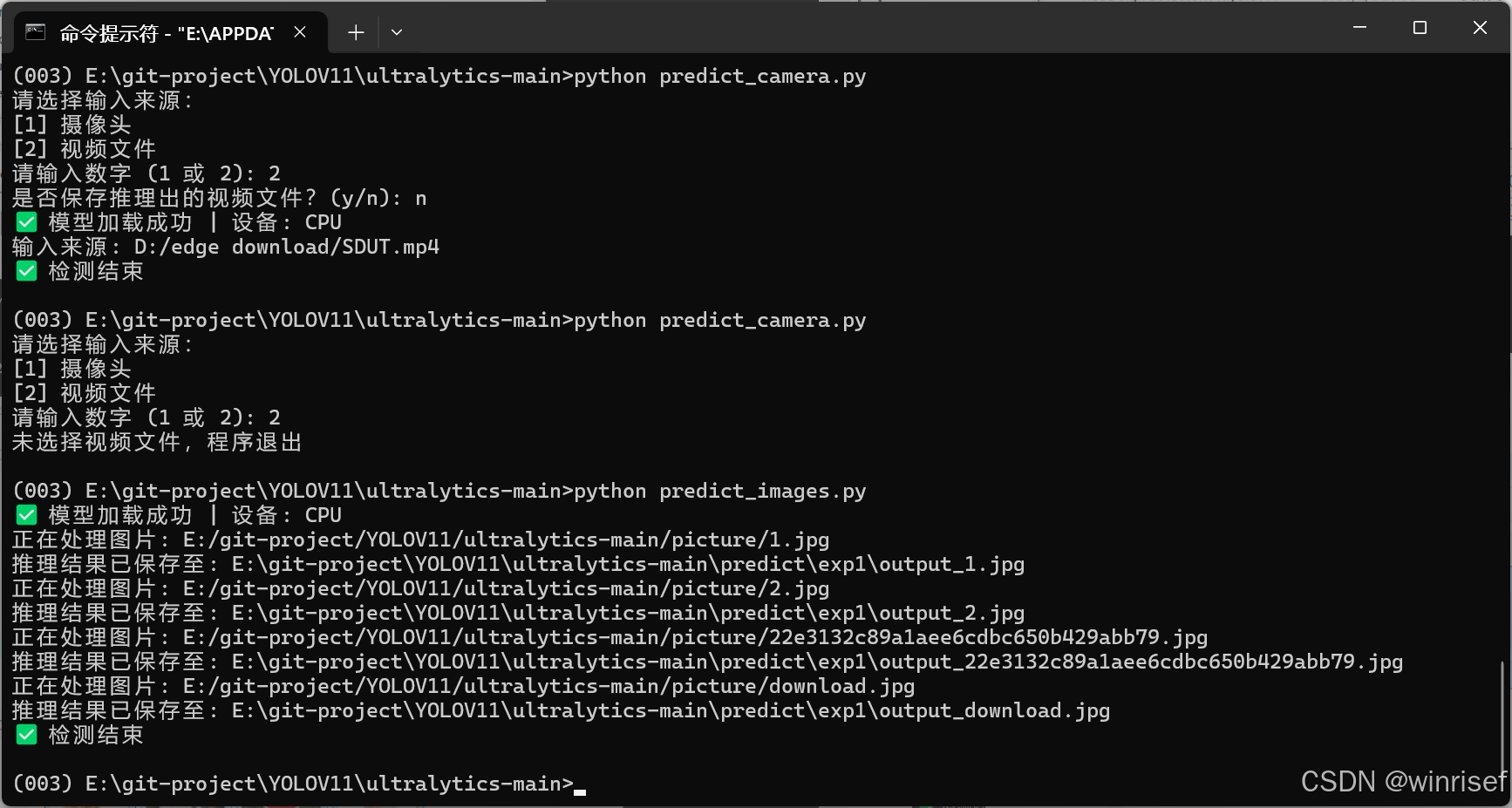
需要注意的是退出按q,点击视频框的×是无法退出的,当然也可以使用Ctrl+C方式退出,退出不会造成摄像头不保存推理文件,文件保存在代码所在文件夹下predict文件夹内。
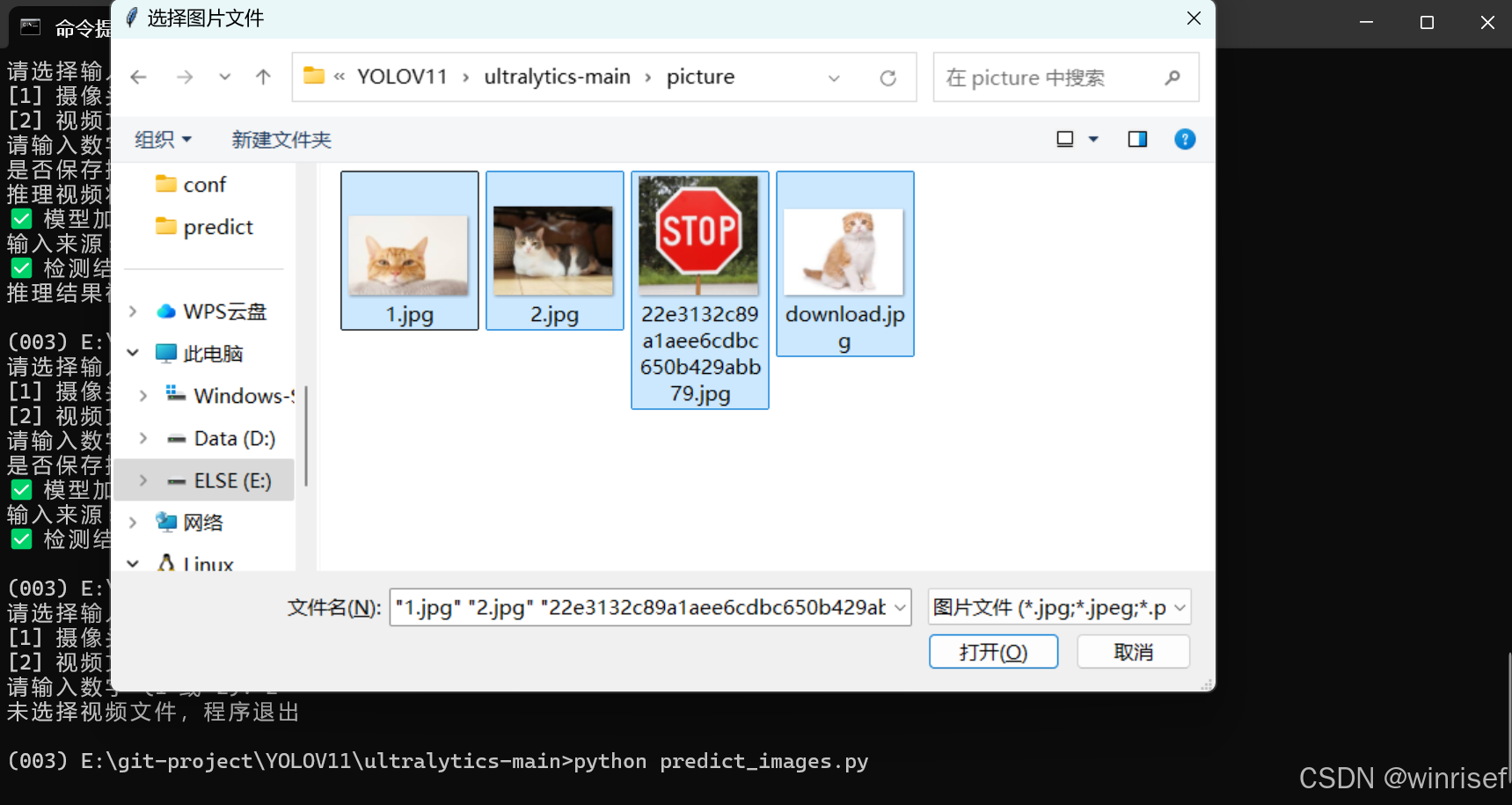
图片文件
对于图片文件,将图片放在picture文件夹下太麻烦,同样采用选择图片进行检测,同时可以框选多个图片,可以将以下代码复制到predict_images.py运行检测:
from ultralytics import YOLO
import cv2
import torch
from pathlib import Path
import os
import tkinter as tk
from tkinter import filedialog
def choose_input_files():
root = tk.Tk()
root.withdraw() # 隐藏主窗口
image_paths = filedialog.askopenfilenames(
title="选择图片文件",
filetypes=[("图片文件", "*.jpg;*.jpeg;*.png;*.bmp;*.tiff;*.gif"), ("所有文件", "*.*")]
)
if not image_paths:
print("未选择任何图片文件,程序退出")
exit(0)
return image_paths
def detect_images():
# ======================= 配置区 =======================
# 模型配置
model_config = {
'model_path': r'E:\git-project\YOLOV11\ultralytics-main\weights\yolo11n.pt', # 本地模型路径
'download_url': 'https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt' # 如果没有模型文件可在此处添加下载URL
}
# 推理参数
predict_config = {
'conf_thres': 0.25, # 置信度阈值
'iou_thres': 0.45, # IoU阈值
'imgsz': 640, # 输入分辨率
'line_width': 2, # 检测框线宽
'device': 'cuda:0' if torch.cuda.is_available() else 'cpu' # 自动选择设备
}
# ====================== 配置结束 ======================
try:
# 选择图片文件
image_paths = choose_input_files()
# 创建保存目录:代码文件所在目录下的 predict 文件夹
save_dir = os.path.join(os.getcwd(), "predict", "exp")
os.makedirs(save_dir, exist_ok=True)
if os.path.exists(save_dir):
i = 1
while os.path.exists(f"{save_dir}{i}"):
i += 1
save_dir = f"{save_dir}{i}"
os.makedirs(save_dir)
# 加载模型(带异常捕获)
if not Path(model_config['model_path']).exists():
if model_config['download_url']:
print("开始下载模型...")
YOLO(model_config['download_url']).download(model_config['model_path'])
else:
raise FileNotFoundError(f"模型文件不存在: {model_config['model_path']}")
# 初始化模型
model = YOLO(model_config['model_path']).to(predict_config['device'])
print(f"✅ 模型加载成功 | 设备: {predict_config['device'].upper()}")
# 处理每个选定的图片文件
for image_path in image_paths:
print(f"正在处理图片: {image_path}")
img = cv2.imread(image_path)
if img is None:
print(f"无法读取图片: {image_path}")
continue
# 执行推理
results = model.predict(
source=img, # 输入图片
stream=False, # 禁用流模式
verbose=False,
conf=predict_config['conf_thres'],
iou=predict_config['iou_thres'],
imgsz=predict_config['imgsz'],
device=predict_config['device']
)
# 解析并绘制结果(取第一个结果)
for result in results:
annotated_img = result.plot(line_width=predict_config['line_width'])
break
# 保存推理结果图像到文件
output_image_path = os.path.join(save_dir, f"output_{os.path.basename(image_path)}")
cv2.imwrite(output_image_path, annotated_img)
print(f"推理结果已保存至: {output_image_path}")
# 显示实时画面,取消下面注释就会边检测边弹出结果
# cv2.imshow('YOLO Real-time Detection', annotated_img)
# 等待按键退出当前图片查看
if cv2.waitKey(0) & 0xFF == ord('q') :
break
cv2.destroyAllWindows()
print("✅ 检测结束")
except Exception as e:
print(f"\n❌ 发生错误: {str(e)}")
print("问题排查建议:")
print("1. 检查图片文件路径是否正确")
print("2. 确认模型文件路径正确")
print("3. 检查CUDA是否可用(如需GPU加速)")
print("4. 尝试降低分辨率设置")
if __name__ == "__main__":
detect_images()
同样需要更改模型文件地址、置信度等,图片文件保存在代码文件夹的predict文件夹下exp中,如果想要检测时就查看图片,可以将这段代码取消注释:
# 显示实时画面
cv2.imshow('YOLO Real-time Detection', annotated_img)
效果如下
视频与摄像头

图片文件
所有推理出的文件都会在代码同级的predict目录下,按q退出。