前言
在上篇文章中,我们深入探讨了图像分类数据集的制作流程。图像分类作为计算机视觉领域的一个基础任务,通常被认为是最为简单直接的子任务之一。然而,当我们转向目标检测任务时,复杂度便显著提升,尤其是在标注框的处理环节。不同的模型架构往往对标注框的处理方式有着各自独特的要求。以 YOLO 系列为例,它自有一套成熟且高效的方法来应对这一挑战。鉴于篇幅有限,本文暂不深入展开 YOLO 的相关内容,感兴趣的读者可以查阅其官方文档,深入了解其背后的原理与实现细节。
实战
文件存放路径
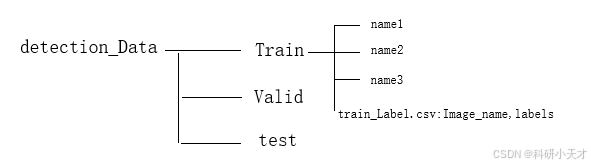
先提供一个伪代码来看一下我们要具体做什么:主要就是要输出图片和对应的标注信息。
def my_dataset(batch):
images = []
bboxes = []
for img, box in batch:
images.append(img)
bboxes.append(box)
images = np.array(images)
return images, bboxes接下来直接上完整代码,都打上了注释,就不多解释了:
class MyDataset(torch.utils.data.Dataset):
"""一个用于加载检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = self.read_data(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def read_data(is_train=True):
"""读取检测数据集中的图像和标签"""
data_dir = '../data' # 检测数据集所在的位置
csv_fname = os.path.join(data_dir, 'train' if is_train
else 'valid', '_label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name') # 将img_name设置为索引
images, targets = [], []
for img_name, target in csv_data.iterrows():# 返回元组
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'data_train' if is_train else
'data_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
def load_datas(batch_size):
"""加载检测数据集"""
train_iter = torch.utils.data.DataLoader(MyDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(MyDataset(is_train=False),
batch_size)
return train_iter, val_iter