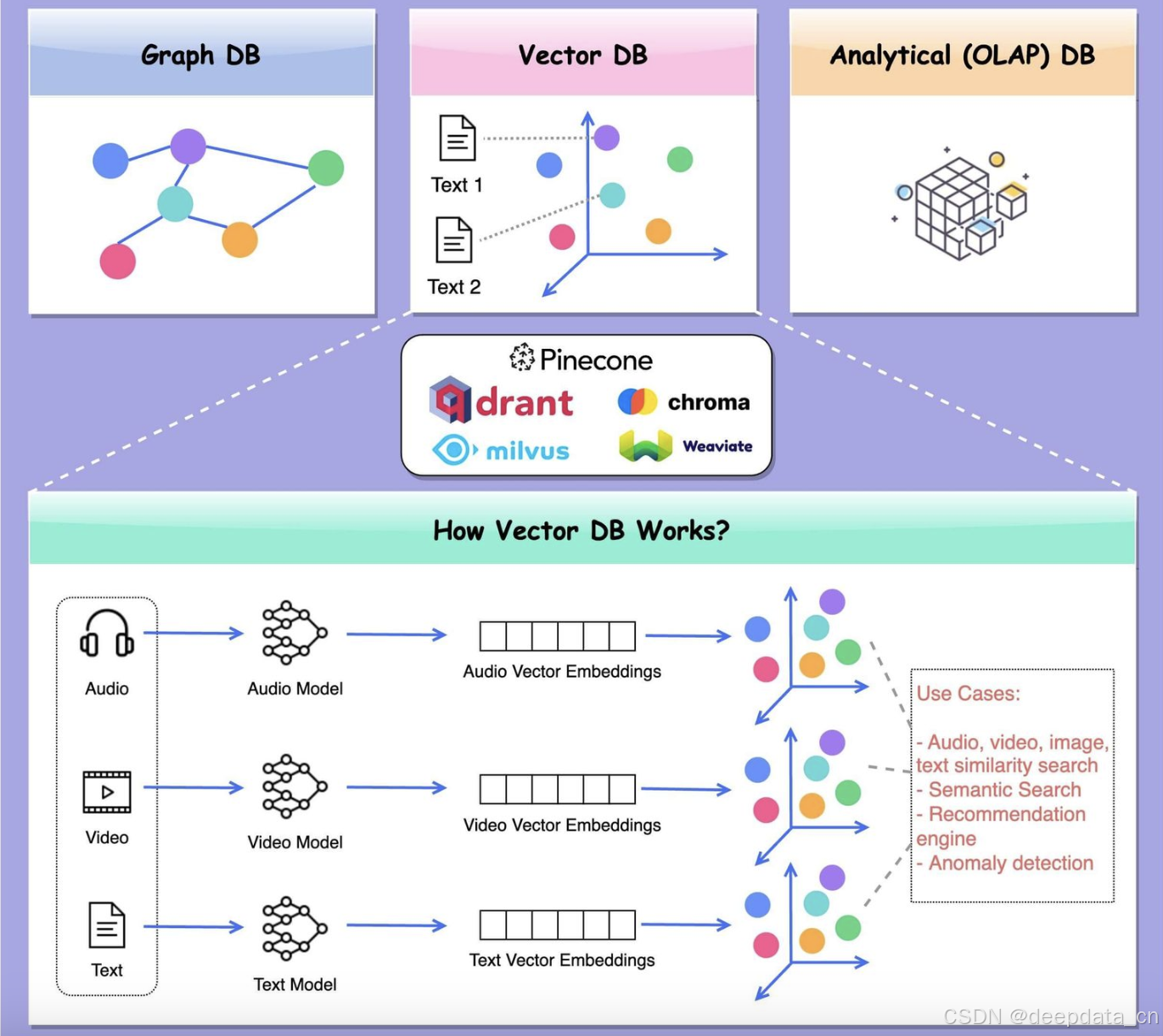
向量数据库的起源可以追溯到十多年前,当时深度神经网络快速发展,对非结构化和高维数据的处理需求不断增加,向量搜索技术也随之发展和优化。Facebook开源的FAISS插件库是早期向量数据库的代表,主要应用于推荐系统等相似性推荐领域。随着向量检索需求的增长,一些标准化数据库产品开始集成向量特性,如Elastic Search、PostgreSQL和Redis等,但在性能和适用场景上存在局限性。ChatGPT等大规模语言模型的爆火,让向量数据库成为AI领域的焦点,在机器学习和大模型预训练中发挥出得天独厚的优势。
一、主要特点
1.高效查询:采用如kd-tree、LSH、HNSW等特殊的数据结构和索引方法,能在大规模数据集中快速找到与查询向量最相似的向量。
2.支持高维向量:可直接处理图像、音频处理以及自然语言处理等领域的高维数据,无需降维,避免信息丢失。
3.支持复杂查询:能够支持范围查询、布尔查询、聚合查询等复杂操作,满足不同类型的查询需求。
4.支持高并发:多采用多线程或分布式架构,具备良好的并发处理能力,可同时处理多个查询请求,提高系统吞吐量。
二、技术架构
1.数据存储层:将数据以向量形式存储,每个向量代表一个数据对象,通常会采用专门的数据格式和存储方式来优化向量的存储效率和访问速度。
2.向量索引层:为加速查询,使用向量索引来存储向量数据,常见索引结构有树形结构(如KD树、R树)、哈希结构(如LSH)以及图结构(如HNSW)。
3.相似度计算层:提供多种距离度量方法,如欧氏距离、余弦相似度、内积等,来评估向量之间的相似性,以确定向量的相似程度。
4.查询优化层:采用一系列查询优化技术,如基于向量索引的查询优化、基于近似相似度计算的查询优化等,提高查询效率。
三、不足之处
1.存储成本高:向量数据的多个维度信息需要较大存储空间,大规模高维向量数据集的存储成本更高。
2.查询效率受维度影响:向量维度越高,查询的计算量和时间成本通常会增加,处理极高维度向量时性能挑战较大。
3.数据更新困难:索引结构和数据组织方式复杂,更新向量数据可能需重新计算相似度、重新构建或调整索引,成本较高。
4.适用场景有限:主要适用于大规模向量数据的存储和查询,对结构化数据的处理能力和效率不如传统关系型数据库,不太适合对数据精确性和事务处理要求高的场景。
5.技术门槛较高:涉及向量计算、索引结构、分布式系统等多方面技术知识,设计、实现和优化需要具备一定的数学和计算机技术背景。
四、应用场景
1.推荐系统:计算用户历史行为和物品向量的相似性,为用户推荐相关物品,应用于电商、音乐、视频等领域。
2.搜索引擎:将网页内容表示为向量,建立索引,实现与查询相关的快速检索,提高搜索质量和效率。
3.社交媒体分析:支持相似性查询和聚合操作,用于情感分析、主题建模和社区发现等。
4.生物信息学:将基因序列和蛋白质表示为向量,进行高效的模式识别、聚类和预测。
5.图像和视频分析:用于图像检索、物体识别和场景分类等,通过向量索引实现对相似图像或视频的快速检索。
6.自然语言处理:可实现语义搜索、问答系统、相似文本检索等功能。
五、常用向量数据库的对比
1.Milvus
项目地址:https://milvus.io
性能:处理大规模数据性能出色,搜索性能高,可扩展性强,支持GPU加速,能满足企业级大规模数据处理需求。
可扩展性:高度可扩展,分布式架构使其能通过增加节点应对海量数据。
易用性:配置和使用有一定技术门槛,不过提供了丰富的API和SDK,方便开发人员集成。
数据类型支持:对常见向量数据类型支持良好。
社区与文档:开源社区活跃,文档丰富。
成本:开源免费,可本地部署,自行承担硬件和维护成本;也有商业化的Zilliz云服务,需付费。
适用场景:图像、音频、文本等多领域的大规模向量数据管理和搜索,如推荐系统、图像和视频相似性搜索等。
2.Pinecone
项目地址:https://www.pinecone.io
性能:响应时间快,在云环境中优化良好,能高效处理大量向量数据,实现低延迟检索。
可扩展性:在云环境中扩展能力佳。
易用性:API和管理界面简洁易用,易于集成到应用中,无需维护基础设施。
数据类型支持:支持常见向量数据类型。
社区与文档:作为云服务,文档和支持完善。
成本:作为云服务,根据使用量收费,成本相对较高。
适用场景:大规模搜索、推荐系统、AI应用等,适合快速部署和易于管理的向量搜索需求。
3.Weaviate
项目地址:https://weaviate.io
性能:性能稳定,可应对一定规模数据量。
可扩展性:可通过增加节点扩展。
易用性:使用有一定复杂性,学习曲线较陡,但功能丰富,提供GraphQL接口,便于集成。
数据类型支持:支持多种数据类型,包括结构化、半结构化和非结构化数据,可处理多模态数据。
社区与文档:社区逐渐活跃,文档不断完善。
成本:有免费沙箱试用,无服务器版从$25/月开始,企业版按需提供。
适用场景:语义搜索、知识图谱集成、AI开发等复杂数据集成场景。
4.Qdrant
性能:轻量级设计,在小规模数据上搜索速度快,有不错的低延迟性能。
可扩展性:相对容易在小规模基础上扩展。
易用性:部署和使用简单,提供REST API和客户端库。
数据类型支持:支持常见向量数据类型。
社区与文档:社区在发展中,文档能满足基本需求。
成本:开源可本地部署,成本可控。
适用场景:小型到中型项目,适用于对部署要求简单、需要快速搜索性能的场景。
5.Chroma
性能:针对与语言模型集成有较好性能支持,在中小规模数据处理上表现良好。
可扩展性:扩展方面表现中规中矩。
易用性:对开发者友好,与语言模型结合方便,提供Python API,使用门槛低。
数据类型支持:支持常见向量数据类型。
社区与文档:随着应用增加,社区和文档不断发展。
成本:开源可本地部署,成本较低。
适用场景:与语言模型相关的自然语言处理项目,如文档检索、聊天机器人、问答系统等中小规模AI应用。
6.FAISS
项目地址:https://github.com/facebookresearch/faiss
性能:高效的相似性搜索和聚类,支持大规模数据集,处理速度快,支持多种索引类型优化搜索,支持CPU和GPU计算。
可扩展性:部分分布式功能需自实现,在大规模数据处理上如果配合其他系统可实现扩展。
易用性:使用门槛高,安装依赖复杂。
数据类型支持:主要针对向量数据,无特别特殊数据类型支持。
社区与文档:开源社区有一定活跃度,文档相对聚焦于技术层面。
成本:开源免费。
适用场景:需要高性能和低延迟的大规模相似性搜索,如图像搜索、推荐系统、语义搜索等。
7.Annoy
性能:基于随机树的近似最近邻搜索,内存使用高效,在读取场景表现较好。
可扩展性:不支持分布式架构,扩展能力有限。
易用性:简单易用,无需额外依赖,轻量级。
数据类型支持:支持常见向量数据类型用于推荐和音频分析等场景。
社区与文档:开源有一定社区维护,文档能满足基本使用。
成本:开源免费。
适用场景:推荐系统、音频分析等读取多于写入的场景。