目录
正则表达式
简介
Regular Expression, 正则表达式, ⼀种使⽤表达式的⽅式对字符串进⾏匹配的语法规则 正则的语法: 使⽤元字符进⾏排列组合⽤来匹配字符串 在线测试正则表达式:https://tool.oschina.net/regex/
语法:
常用元字符:
(具有固定含义的特殊符号)
. 匹配除换⾏符以外的任意字符 \w 匹配字⺟或数字或下划线 \s 匹配任意的空⽩符 \d 匹配数字 \n 匹配⼀个换⾏符 \t 匹配⼀个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配⾮字⺟或数字或下划线 \D 匹配⾮数字 \S 匹配⾮空⽩符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示⼀个组 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符
例子:
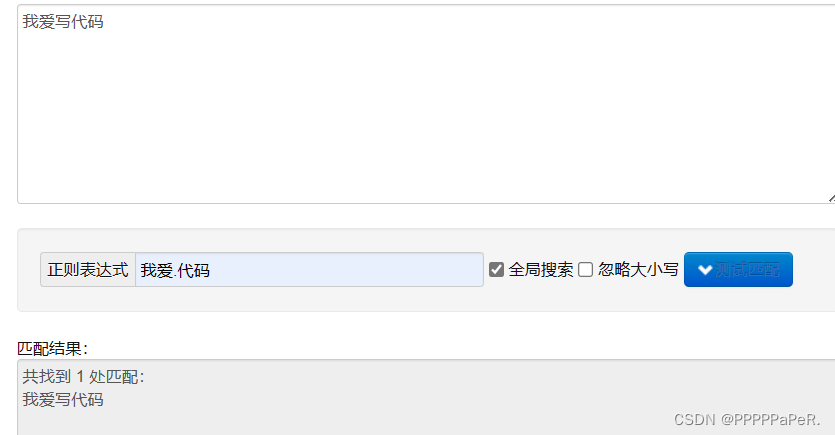
量词:
(控制前⾯的元字符出现的次数)
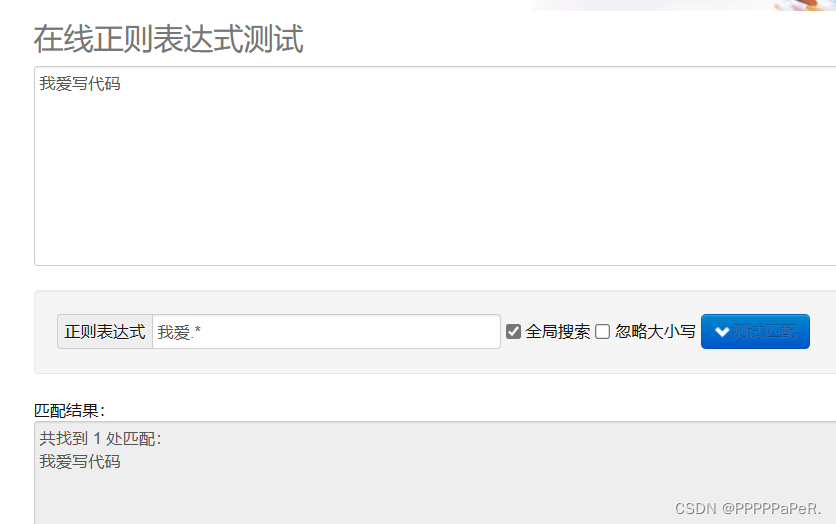
* 重复零次或更多次
+ 重复⼀次或更多次
? 重复零次或⼀次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
例子:
贪婪匹配和惰性匹配:
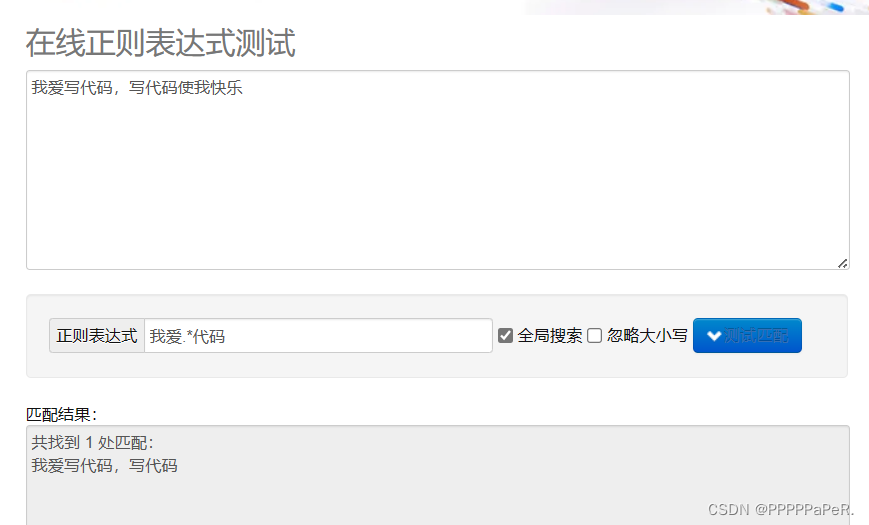
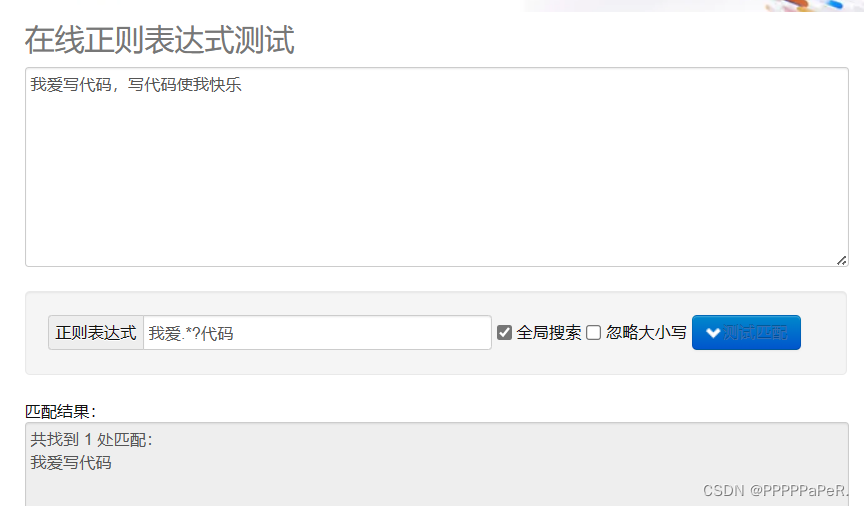
.* 贪婪匹配:寻找匹配的最远的区间 .*? 惰性匹配:寻找匹配的最近的区间
例子:
re模块
简介:
re 是 Python 内置的正则表达式模块,提供了丰富的功能,用于处理字符串的模式匹配。它允许您使用正则表达式来搜索、匹配、替换和操作字符串。
re模块函数语法:
常用的几个模块:
1.findall
函数介绍:
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。
代码演示:
import re
#引用re模块
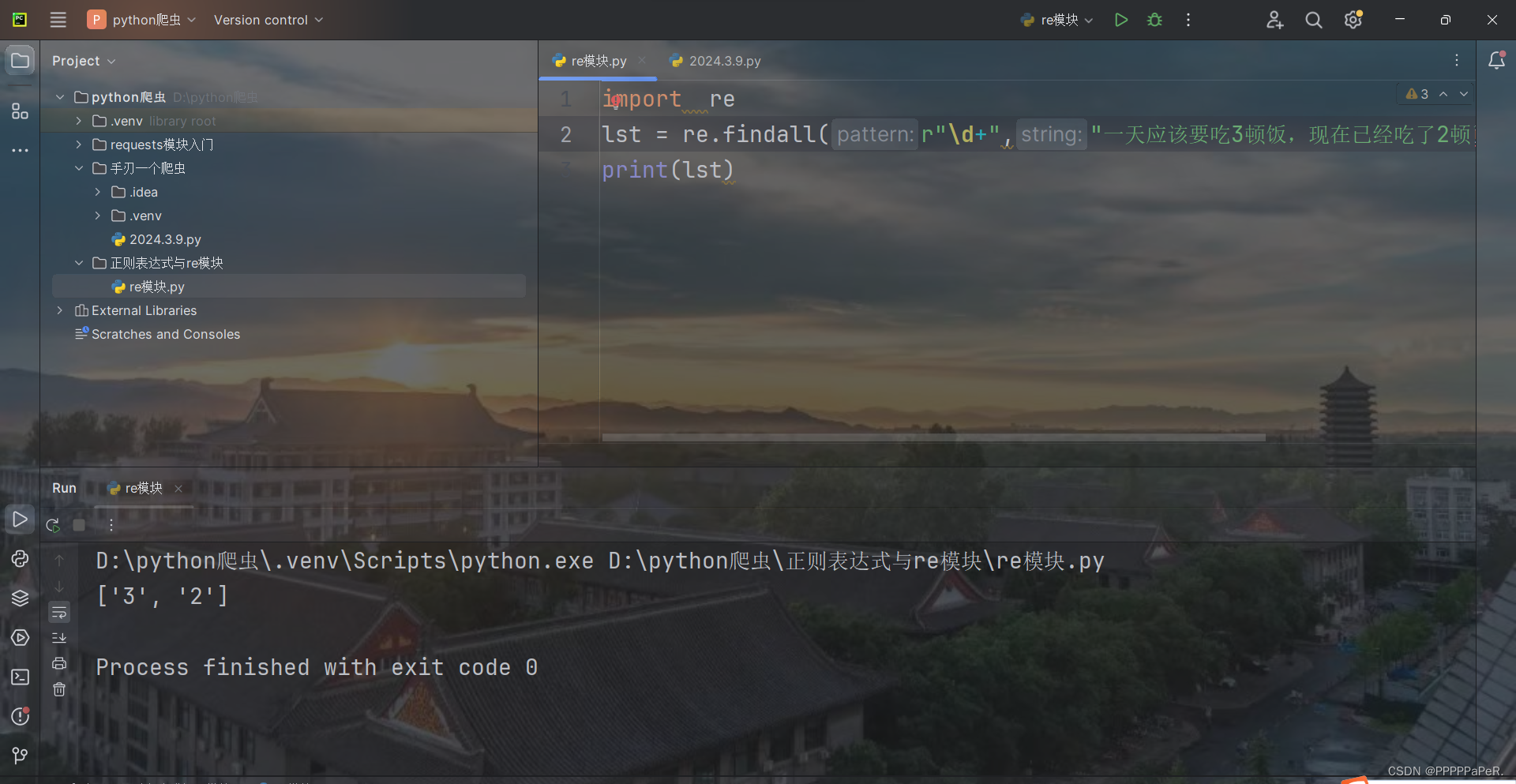
lst = re.findall(r"\d+","一天应该要吃3顿饭,现在已经吃了2顿了,还有一顿晚饭")
print(lst)结果:
2.search
函数介绍:
re.search 扫描整个字符串并返回第一个成功的匹配,如果没有匹配,就返回一个 None。
re.match与re.search的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
代码演示:
import re
#引用re模块
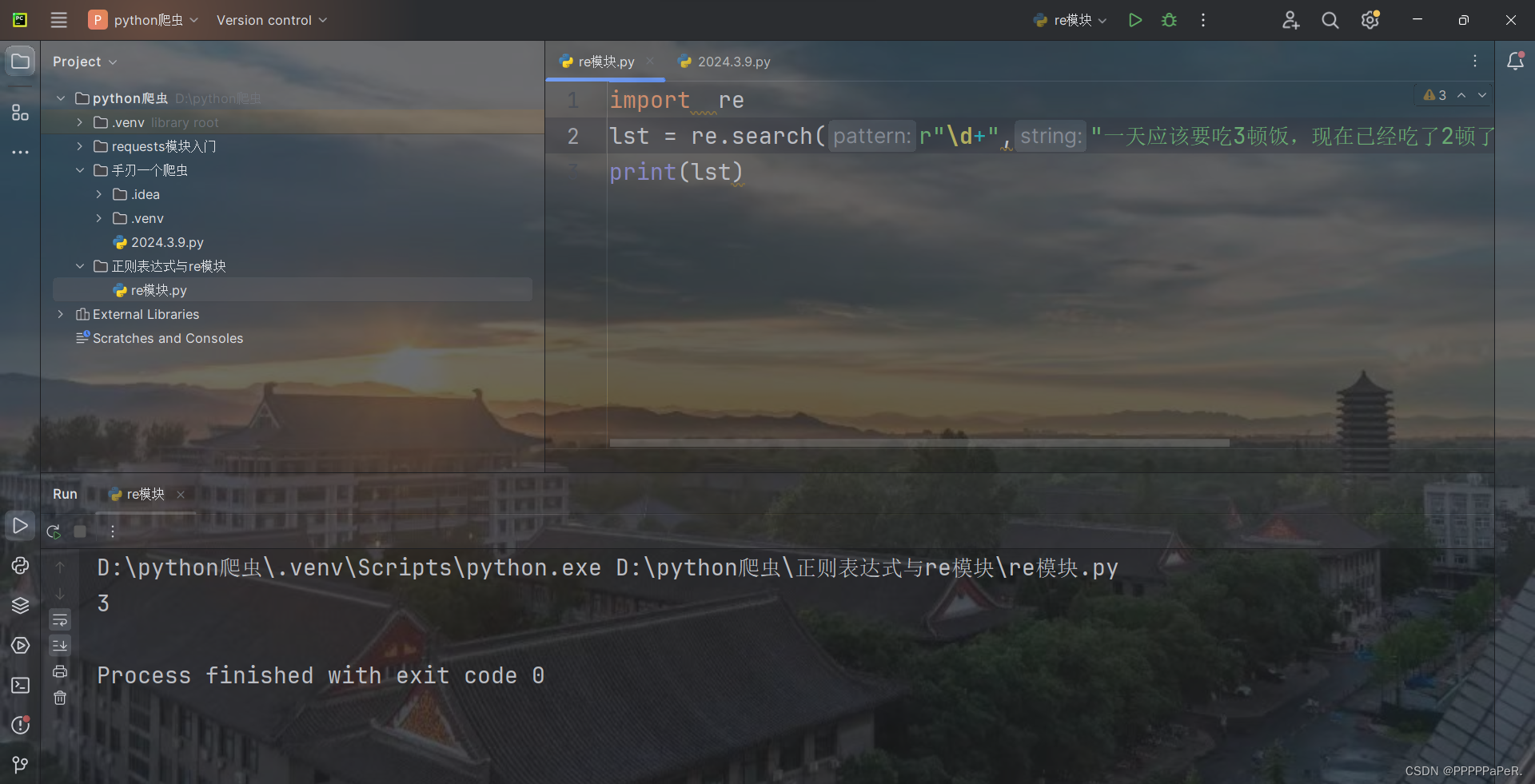
lst = re.search(r"\d+","一天应该要吃3顿饭,现在已经吃了2顿了,还有一顿晚饭").group()
print(lst)结果:
3.finditer
函数介绍:
与findall差不多. 只不过这时返回的是迭代器
代码演示:
import re
#引用re模块
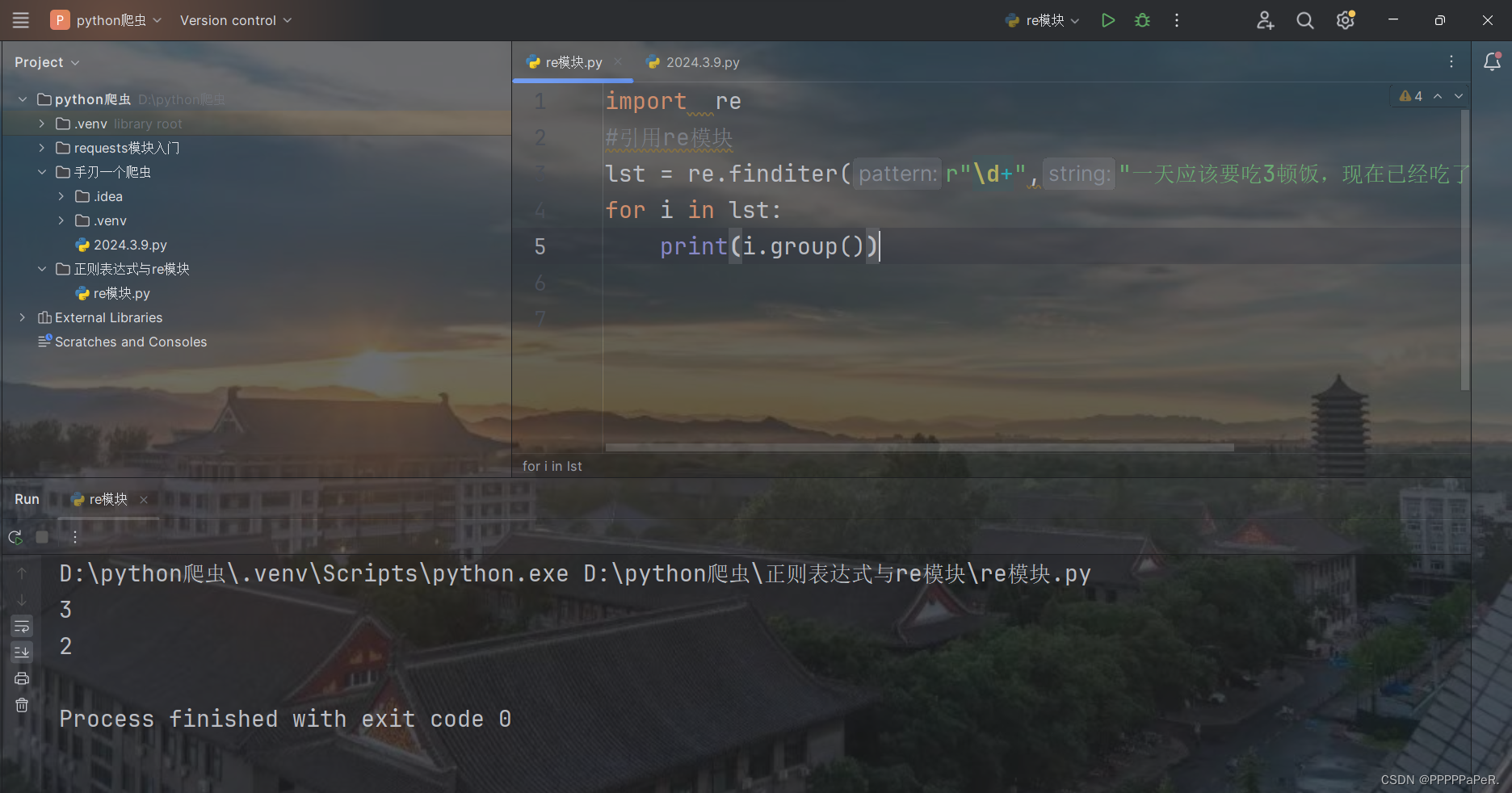
lst = re.finditer(r"\d+","一天应该要吃3顿饭,现在已经吃了2顿了,还有一顿晚饭")
for i in lst:
print(i.group()) #分组
结果:
4.compile
函数介绍:
将⼀个⻓⻓的正则进⾏预加载. ⽅便后⾯的使⽤
代码演示:
import re
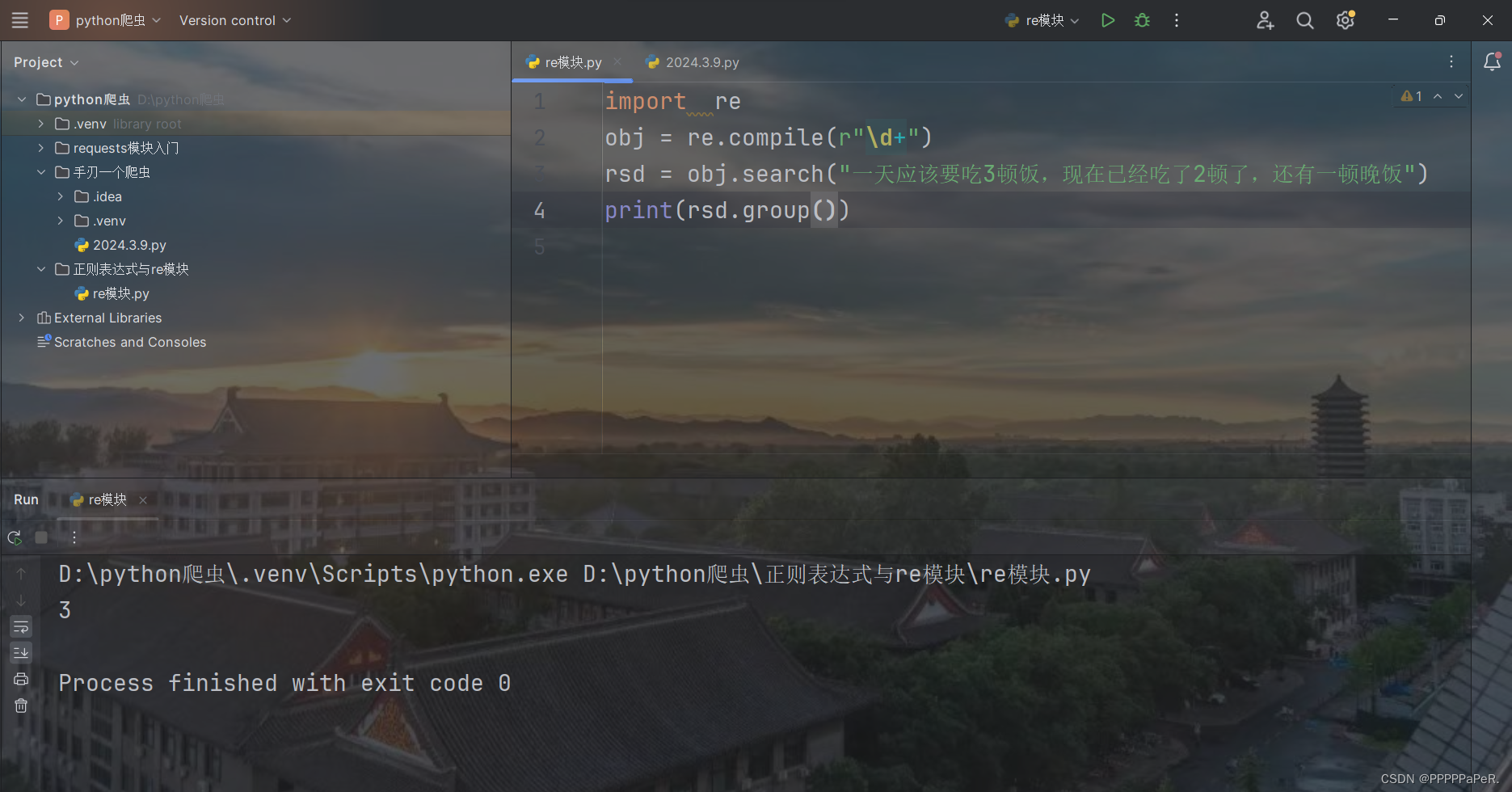
obj = re.compile(r"\d+")
rsd = obj.search("一天应该要吃3顿饭,现在已经吃了2顿了,还有一顿晚饭")
print(rsd.group())结果:
案例展示:
爬取豆瓣电影排行Top250信息
需求:
目标:获取电影名称、电影导演、电影上映日期、电影评分、评分人数
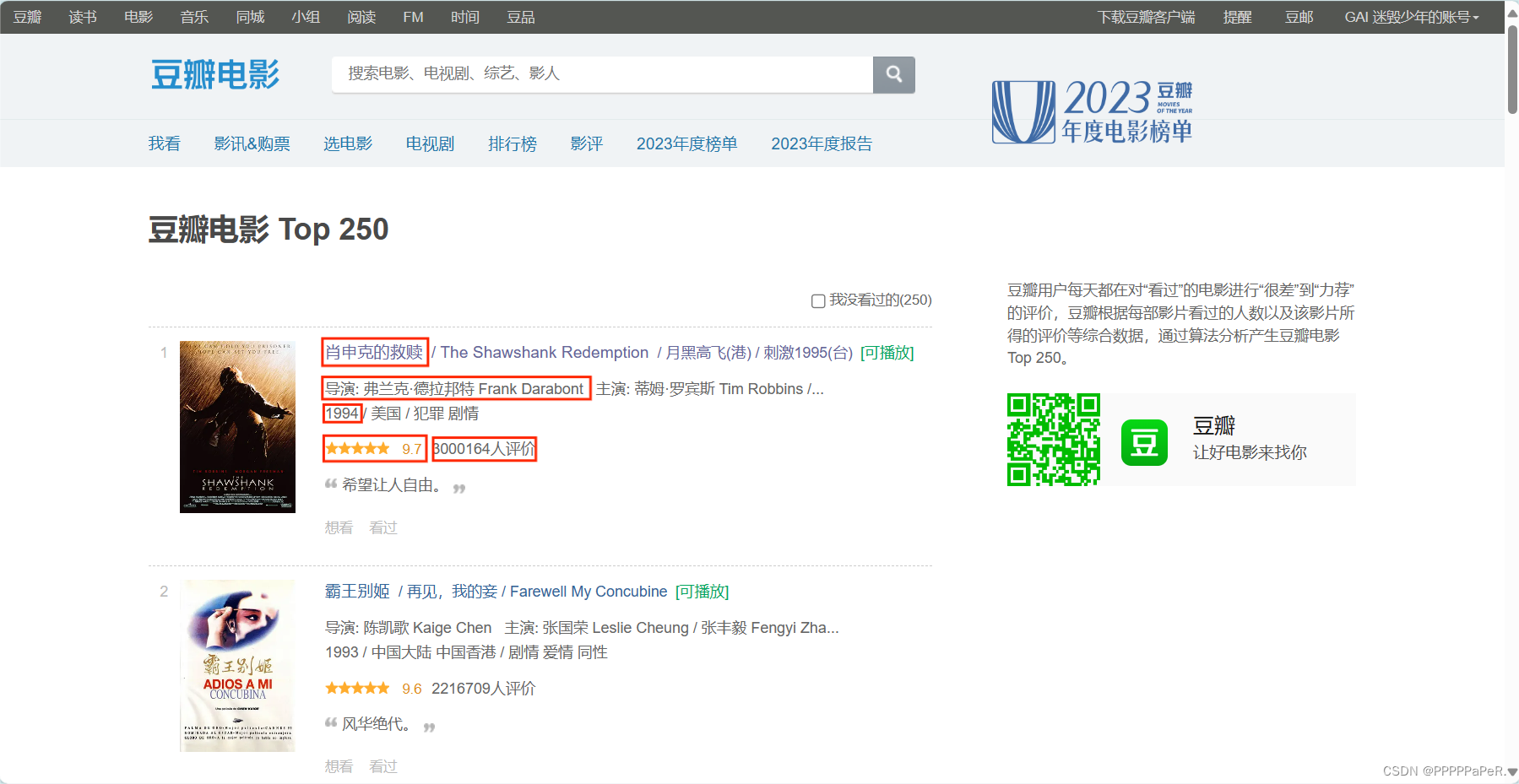
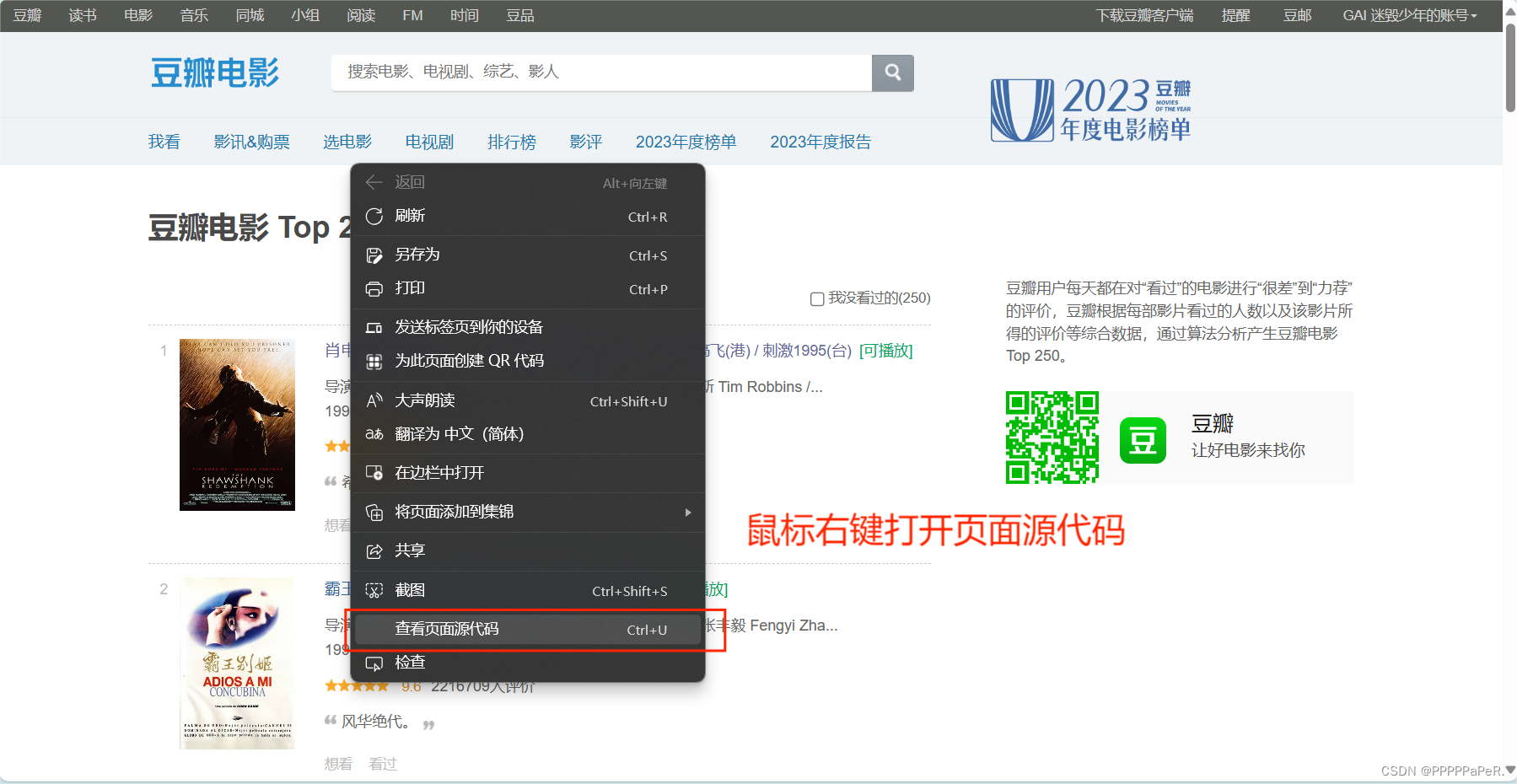
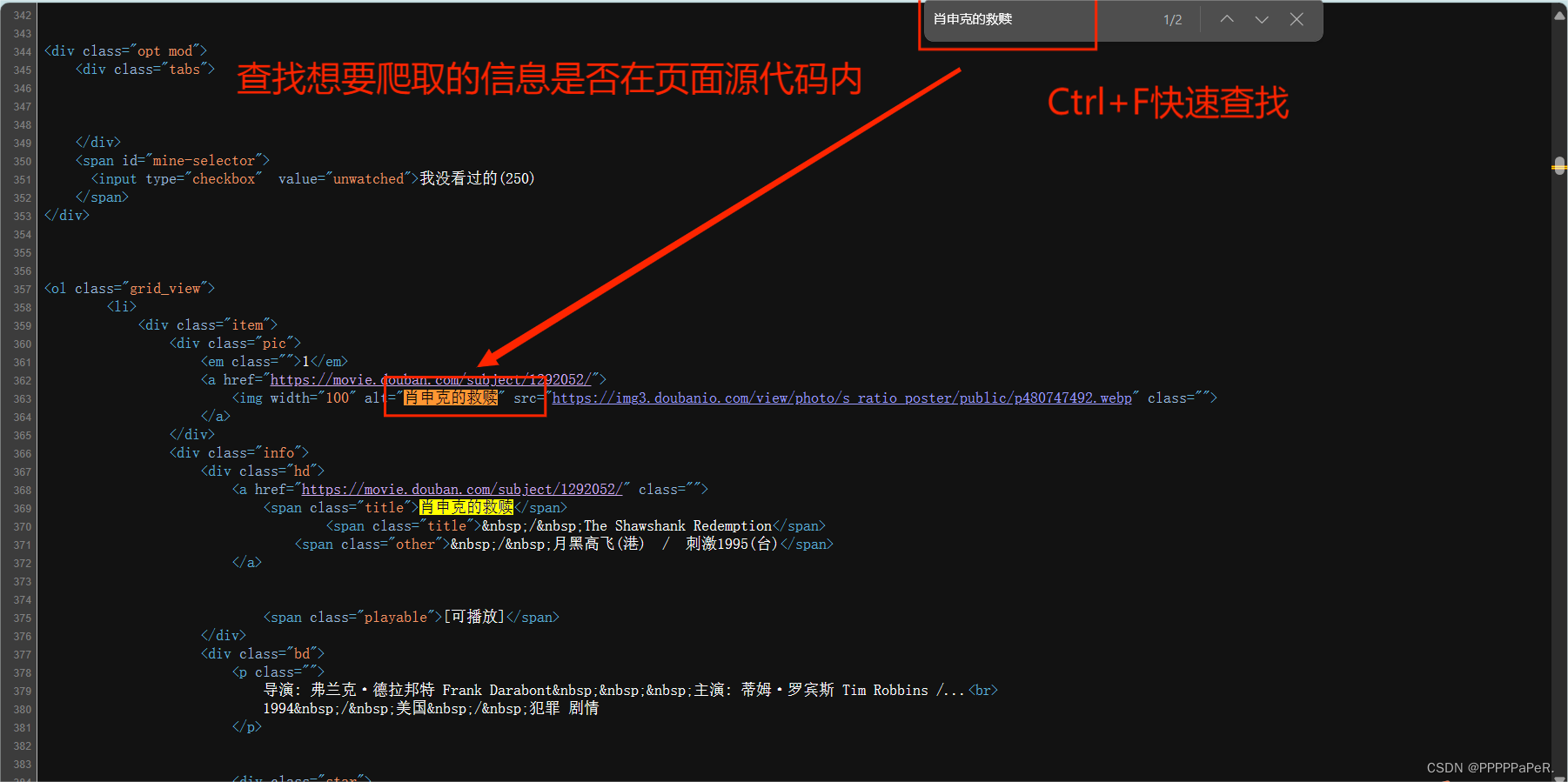
页面源代码内有想爬取的信息,可直接进行爬虫
思路分析:
1.获取页面源代码:
import re
import requests
url = "https://movie.douban.com/top250"
head ={
"User-Agent":"Mozilla/5.0 (Linux; Android "
"6.0; Nexus 5 Build/MRA58N) AppleWeb"
"Kit/537.36 (KHTML, like Gecko) Chro"
"me/122.0.0.0 Mobile Safari/537.36"
" Edg/122.0.0.0"
}
rsp = requests.get(url,headers=head)
print(rsp.text)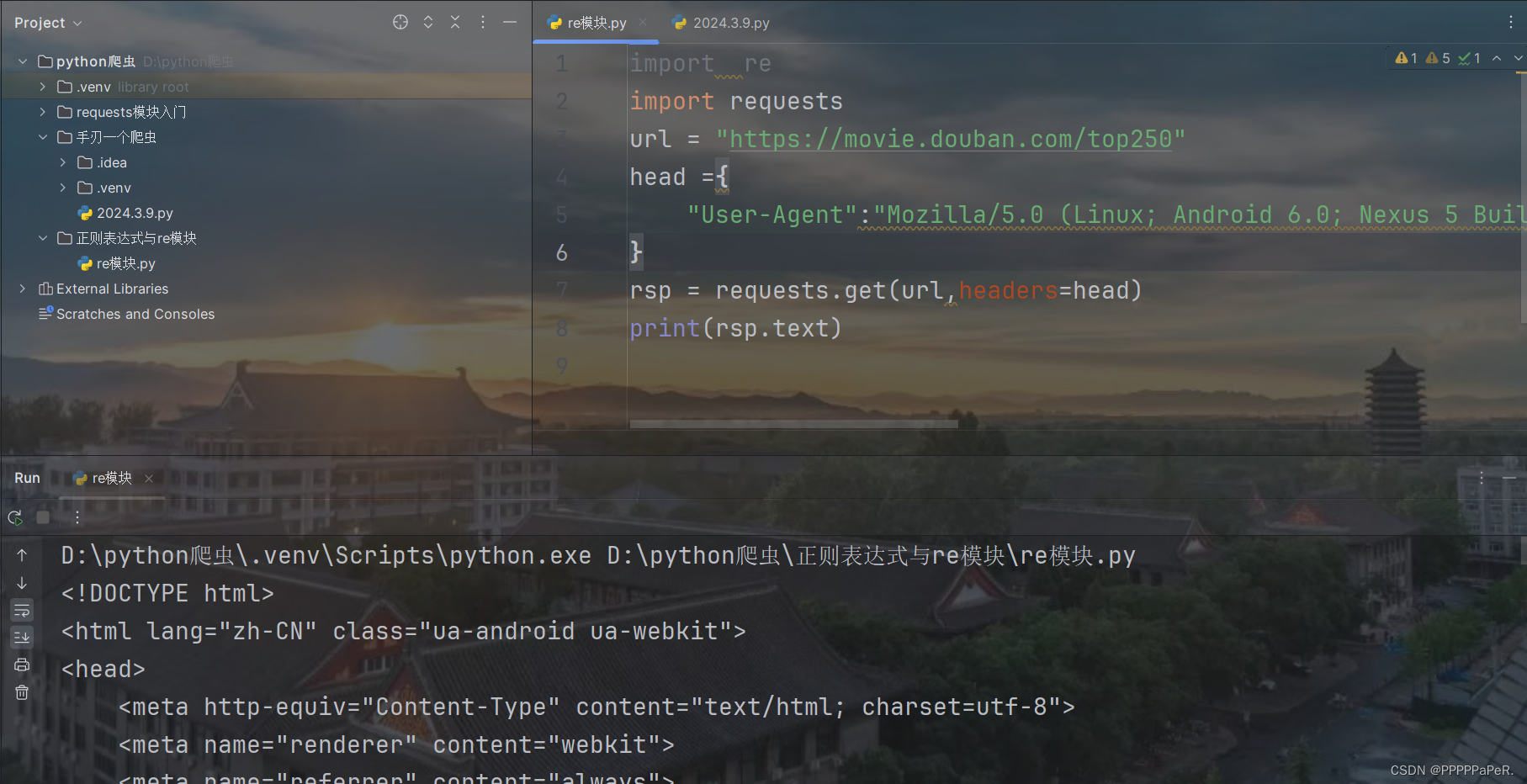
2.正则书写
obj = re.compile(r'<li>.*?<div class="item">'
r'.*?<div class="pic">.*?<em class'
r'="">(?P<num>\d+)</em>.*?<span cl'
r'ass="title">(?P<name>.*?)</span>'
r'.*?<p class="">.*?<br>\n(?P<year>'
r'.*?) .*?property="v:average"'
r'>(?P<average>.*?)</span>.*?<span>'
r'(?P<people>\d+)⼈评价</span>', re.S)3.开始匹配
rst = obj.findall(rsp.text)
for item in rst:
dic = item.groupdict()
dic['year'] = dic['year'].strip()
with open("mydouban.html",mode = 'w',encoding = 'utf-8')as f:
f.write(rsp.text)