文章目录
修改哈希表
我们基于链地址法实现的哈希表来封装实现 unordered_set 和 unordered_map ,但是由于实现的哈希表是 Key-Value 结构的并且我们的实现的哈希表缺少了迭代器,所以我们需要对之前实现的哈希表进行改造。
模板参数
HashNode
节点里不再存储确定的 pair<K, V> ,而是类型 T ,代表代表存储的数据可能是 key 或者 key-Value 。
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
HashTable
template<class K, class T, class KeyOfT, class hash = HashFunc<K>>
class HashTable
K:代表的是keyT:代表是存的可能是key或者key-valueKeyOfT:仿函数,目的是拿到T里面的key
迭代器
哈希表的迭代器其实就是对节点指针进行封装,而且是单向迭代器,只需实现 ++ 即可。
//哈希表与迭代器相互依赖,需要前置声明
template<class K, class T, class KeyOfT, class hash>
class HashTable;
template<class K, class T, class KeyOfT, class Hash, class Ref, class Ptr>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef HTIterator<K, T, KeyOfT, Hash, Ref, Ptr> Self;
Node* _node;
//需要用到哈希表里的数组大小,故需要指向哈希表的指针
const HT* _pht;
HTIterator(Node* node, const HT* pht)
:_node(node)
,_pht(pht)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
Self& operator++()
{
//...
}
};
由于哈希表的特殊性,其迭代器的 ++ 较为复杂,也是实现哈希表迭代器的重点。
重载 ++
迭代器的++分为两种情况:
- 当前迭代器不是哈希桶的最后一个节点,直接走到下一个节点。
- 当前迭代器是哈希桶的最后一个节点,需要找下一个不为空的哈希桶的头节点。
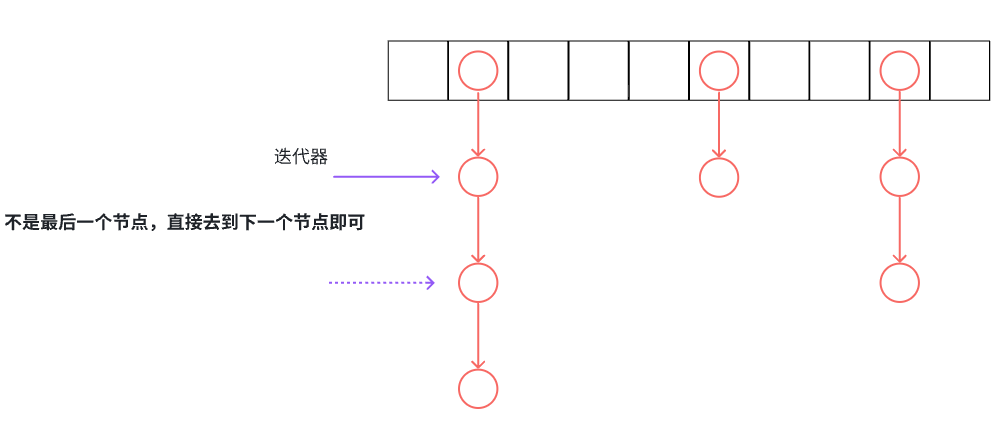
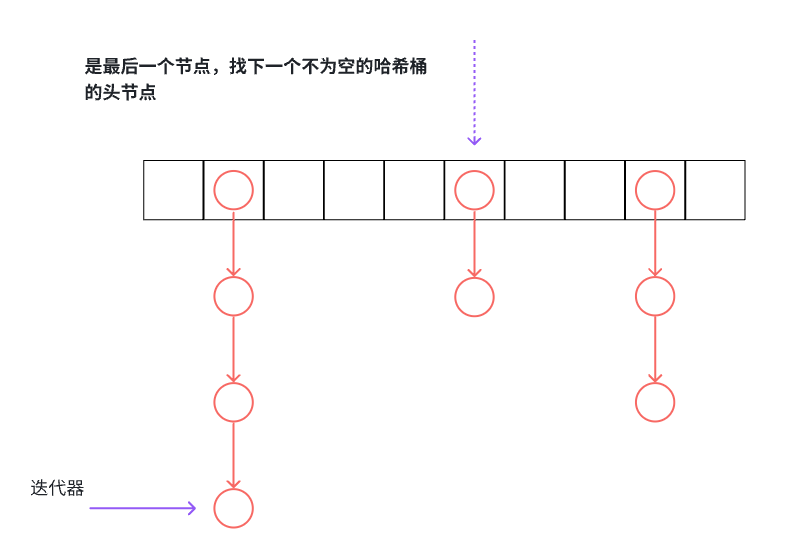
Self& operator++()
{
//当前哈希桶还有数据,直接到下一个节点
if (_node->_next)
{
_node = _node->_next;
}
//当前哈希桶走完了,寻找下一个不为空的哈希桶
else if (_node->_next == nullptr)
{
KeyOfT kot;
Hash hashfunc;
size_t hashi = hashfunc(kot(_node->_data)) % _pht->_tables.size();
++hashi;
while (hashi < _pht->_tables.size())
{
_node = _pht->_tables[hashi];
//找到了下一个桶
if (_node)
break;
else
++hashi;
}
//处理迭代器在最后一个不为空的哈希桶的最后一个节点的情况
if (hashi == _pht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
Self& operator++(int)
{
Self tmp = *this;
++(*this);
return tmp;
}
HashTable 的默认成员函数
//构造函数
HashTable()
: _tables(__stl_next_prime(0))
, _n(0)
{}
//拷贝构造函数
HashTable(const HashTable<K, T, KeyOfT, hash>& ht)
{
_tables.resize(ht._tables.size());
for (auto& data : ht)
{
Insert(data);
}
}
//赋值重载
HashTable<K, T, KeyOfT, hash>& operator=(const HashTable<K, T, KeyOfT, hash>& ht)
{
vector<Node*> newtables(ht._tables.size());
for (size_t i = 0; i < ht._tables.size(); ++i)
{
Node* cur = ht._tables[i];
while (cur)
{
Node* newnode = new Node(cur->_data);
newnode->_next = newtables[i];
newtables[i] = newnode;
cur = cur->_next;
}
}
_tables.swap(newtables);
return *this;
}
//析构函数
~HashTable()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
HashTable 迭代器相关函数
typedef HTIterator<K, T, KeyOfT, hash, T&, T*> Iterator;
typedef HTIterator<K, T, KeyOfT, hash, const T&, const T*> Const_Iterator;
Iterator begin()
{
if (_n == 0)
return end();
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
if (cur)
{
return Iterator(cur, this);
}
}
return end();
}
Iterator end()
{
return Iterator(nullptr, this);
}
Const_Iterator begin() const
{
if (_n == 0)
return end();
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
if (cur)
{
return Const_Iterator(cur, this);
}
}
}
Const_Iterator end() const
{
return Const_Iterator(nullptr, this);
}
begin() 对应的迭代器应该是哈希表中第一个非空的哈希桶的头节点,需要特别处理。
end() 直接返回空指针对应的迭代器即可。
HashTable 的 Insert 函数
对于 Insert 函数,只需将其返回值改成迭代器与布尔值的 pair ,再将原本关于使用到 key 的地方套一层 KeyOfT 实例化出来的对象即可。
void CheckCapacity()
{
if (_n == _tables.size())
{
//把哈od希桶里的链表每个节点拆下来插入newht效率太低了
/*HashTable<K, V> newht;
newht._tables.resize(__stl_next_prime(_tables.size() + 1));
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
newht.Insert(cur->_kv);
cur = cur->_next;
}
}
_tables.swap(newht._tables);*/
KeyOfT kot;
hash hashfunc;
vector<Node*> newtables(__stl_next_prime(_tables.size() + 1));
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = hashfunc(kot(cur->_data)) % newtables.size();
//头插
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
}
pair<Iterator, bool> Insert(const T& data)
{
KeyOfT kot;
Iterator it = Find(kot(data));
//不等于end()说明哈希表里有重复元素
if (it != end())
return { it, false };
//检查是否需要扩容
CheckCapacity();
hash hashfunc;
size_t hashi = hashfunc(kot(data)) % _tables.size();
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return { Iterator(newnode, this), false };
}
HashTable 的 Find函数
将返回值改为迭代器,原本用到 key 的地方套一层 KeyOfT 实例化出来的对象即可。
Iterator Find(const K& key)
{
KeyOfT kot;
hash hashfunc;
size_t hashi = hashfunc(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return Iterator(cur, this);
}
cur = cur->_next;
}
//没找到就返回
return end();
}
HashTable 的 Erase函数
跟 Insert 函数的处理基本一样,不多叙述了。
bool Erase(const K& key)
{
KeyOfT kot;
hash hashfunc;
size_t hashi = hashfunc(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
//删除头节点的情况
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
//非头节点的情况
else
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
else {
prev = cur;
cur = cur->_next;
}
}
return false;
}
封装 unordered_set
对 HashTable 的迭代器和函数进行封装即可,灰常简单。
template<class K, class hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, hash>::Iterator iterator;
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, hash>::Const_Iterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin() const
{
return _ht.begin();
}
const_iterator end() const
{
return _ht.end();
}
pair<iterator, bool> Insert(const K& key)
{
return _ht.Insert(key);
}
iterator Find(const K& key)
{
return _ht.Find(key);
}
bool Erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, const K, SetKeyOfT, hash> _ht;
};
封装 unordered_map
也是对 HashTable 的迭代器和函数进行封装,但有所不同的是,还需要多重载 [] ,也比较简单。
template<class K, class V, class hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, hash>::Iterator iterator;
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, hash>::Const_Iterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin() const
{
return _ht.begin();
}
const_iterator end() const
{
return _ht.end();
}
pair<iterator, bool> Insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = Insert({ key, V() });
return ret.first->second;
}
iterator Find(const K& key)
{
return _ht.Find(key);
}
bool Erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, hash> _ht;
};
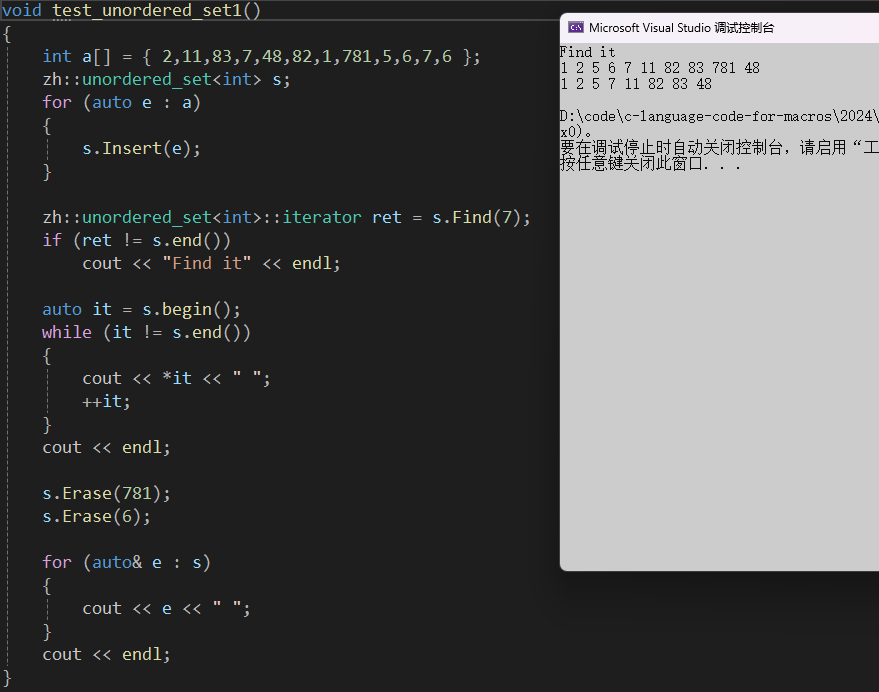
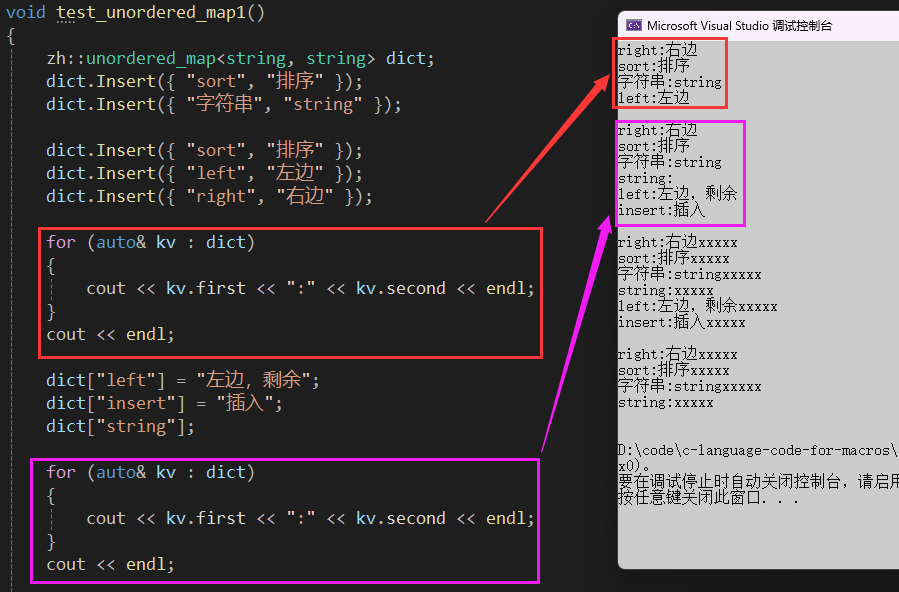
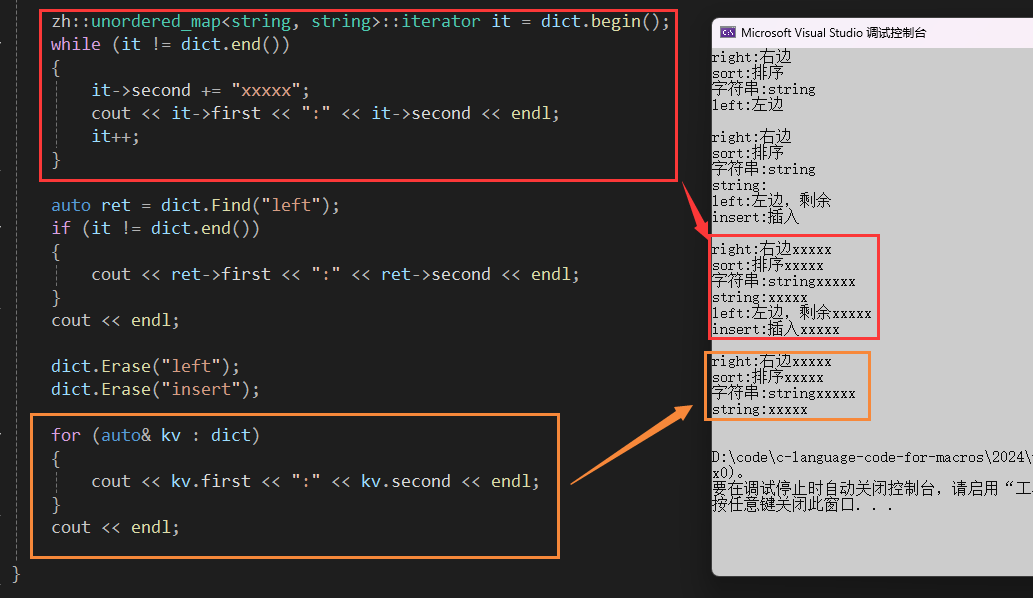
测试 unordered_set 和 unordered_map
拜拜,下期再见😏
摸鱼ing😴✨🎞
