同学你是否对ai生成图方面感兴趣,同学你想不想进步,同学不要再刷抖音看有声小说里面ai美女了,来吧和我一起探索ai扩图在暑假里面卷鼠他们,重生之我在暑假学AIGC文生图校花开始倒追我现在开始(要是想看专业关于概念或者别的历程之类的,还是跳过我这篇吧,主要我本人也不太喜欢那么死板的概念,我也记不住)。
咳咳(敲小黑板),首先我们面对赛题可图Kolors——Lora风格故事挑战赛咱们抛开别的不说,面对丰厚的奖品,你是否已经非常心动,那么开始咱们的逆袭之路。

一、算法平台
抛开文生图的各种算法,各种经历进化史,我们敲代码需要一个便宜又实惠的平台,自己电脑跑可能要到明年了。这一步非常重要,不然你会像我一样付出45.08的惨痛教训,我就是没看这一步,感觉跟诈骗一样,莫名其妙就扣我这么多钱。
接下来就是免费使用环节开通阿里云PAI—DSW试用进入网页之后选择左下角第一个的免费试用,因为我已经买过付过费了所以是选购更多规格这个样子,你们要是第一次登陆就会有个立刻使用。点完这个之后继续点立刻试用,然后完成就行了。

然后在魔塔社区进行授权,当然都是要先登陆的宝。点击个人云账户授权实例,然后从左边开始的第一个的去授权,因为我是做完之后才写的笔记,稍微不一样。之后估计会有阿里云的工作人员给你打电话,就顺着说了解大模型的就好了,点完授权之后,复制他给你的数字,接着点授权,然后粘贴,返回之后点击从左边开始的第二个的去授权,然后就可以了。
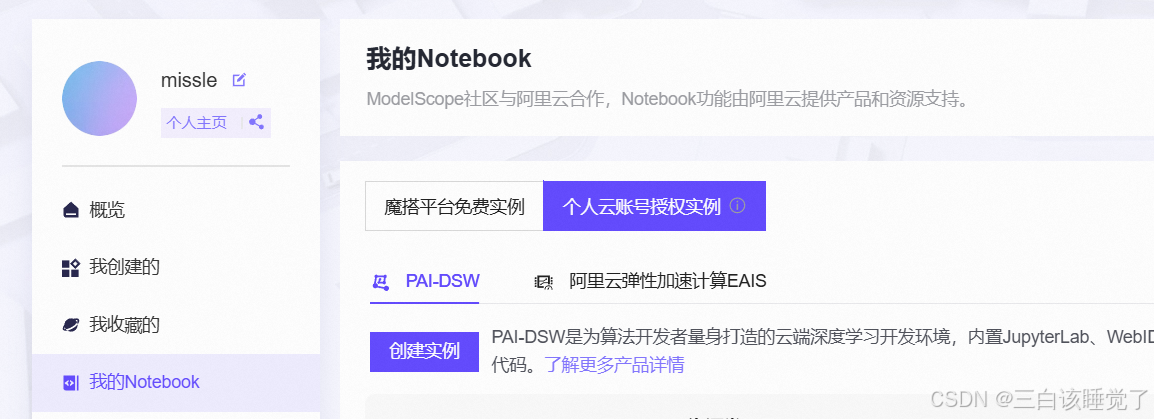
然后就是开启平台,有个简单的直接免费的36个小时和我下图选的一样选择方式二然后点启动,也可以选另一个如下图。
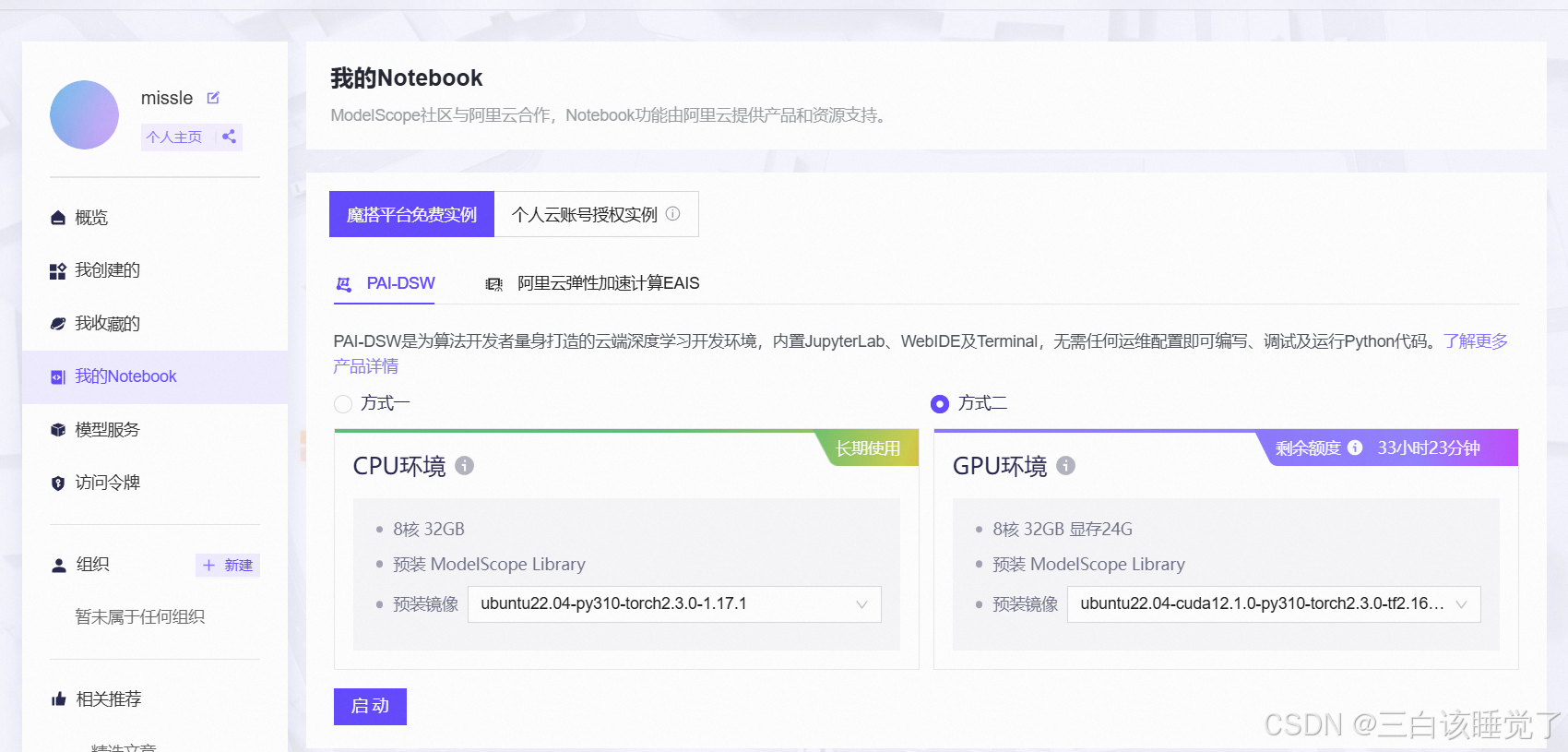
就按照我下面的图把第一个启动,第二个关闭,开着都是浪费算力的,呜呜呜呜呜,谁能赔我45.08啊,我真是个好人给你们强调强调。然后你们做完之后一定要记得关闭,重要的事说三遍,一定要关闭,一定要关闭,一定要关闭。
二、代码
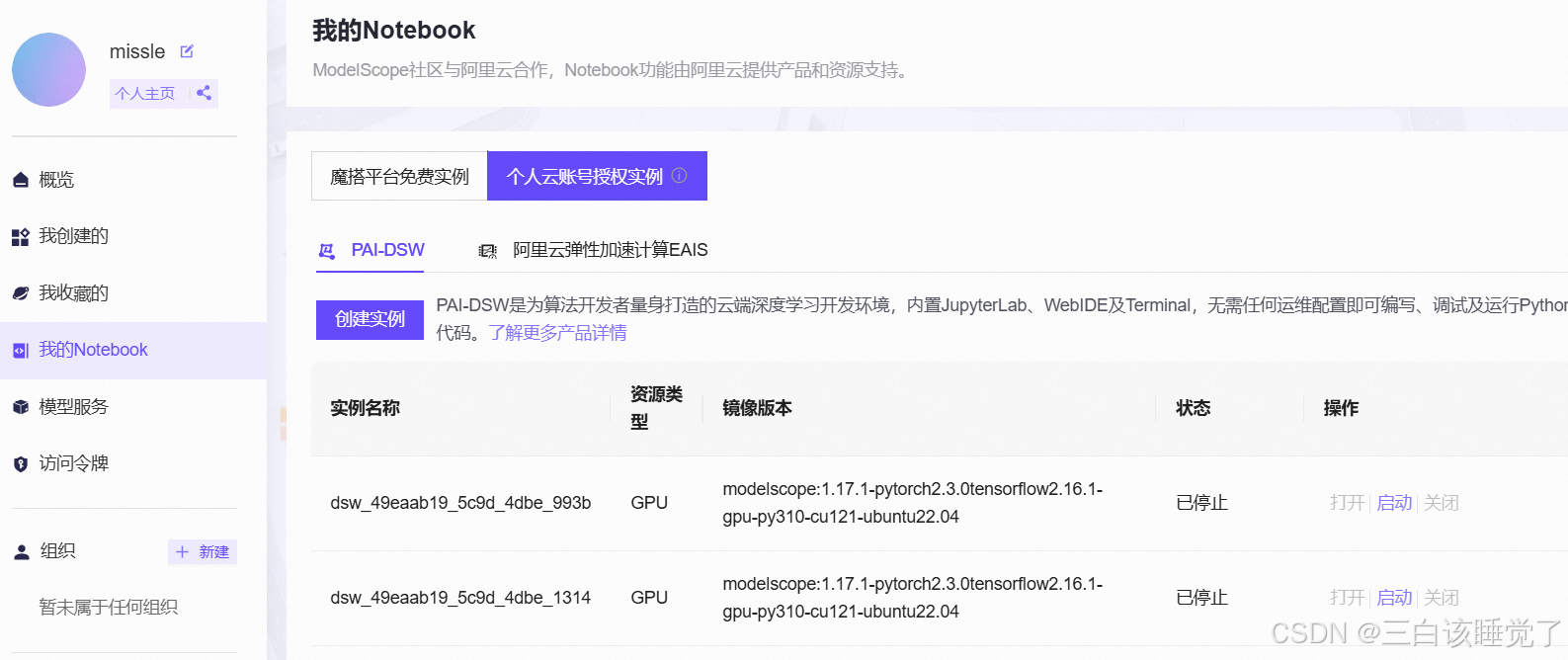
开启之后就进入下面那个界面了,然后打开终端第三行第一个白色的那个Terminal。
进入之后输入这个命令,然后回车,如果鼠标粘贴不了,那就ctrl+v,因为我就是鼠标粘贴不了。估计还要等个两分钟不急。
git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors.git然后点击左边的kolors文件,点击baseline这个文件,把上面的!pip的代码全部运行一下,就是第一行的,那个开始按钮,。
运行完之后,点击上面的第三个按钮,点完就是重启了,然后点击第四个那个就是全部运行,运行比较慢要有耐心。
哦对,如果你想要修改图片的内容可以翻翻代码最下面那个文字描述,就可以修改生成的图片。

三、上传模型
运行完之后点击file,点新建,然后点击终端Terminal,粘贴下面的代码。
mkdir /mnt/workspace/kolors/output & cd
cp /mnt/workspace/kolors/models/lightning_logs/version_0/checkpoints/epoch\=0-step\=500.ckpt /mnt/workspace/kolors/output/
cp /mnt/workspace/kolors/1.jpg /mnt/workspace/kolors/output/之后点击kolors里面的output文件,把里面的两个文件都下载了,在下载的时候不能把那个实例或者那个关闭了,不然下载不了,因为我就这样干了,最后又重新运行一遍,无语死我了,啊啊啊啊。
然后点击魔塔,模型名字就是xxx——LoRA,中文名就是队伍名—可图Kolors训练—xxx,然后选择公开模型,下面那个选1.5就可以了。之后在创空间搜索你的名字点模型,就可以知道发没发成功了,然后一定要记得关闭一定要记得关闭一定要记得关闭。
四、拓展知识
我看这边有个零代码生成图片,这是网址。原谅我夹带私货,没错官宣了,玩恋与深空,做幸福女人,秦彻贼帅的好吧。感觉他运行着挺慢的,慢慢等待........但效果还是比上面的代码要差点意思的。(所以为什么我就放了一张男女抱着的照片就是非法了,投诉,这必须需要改改)
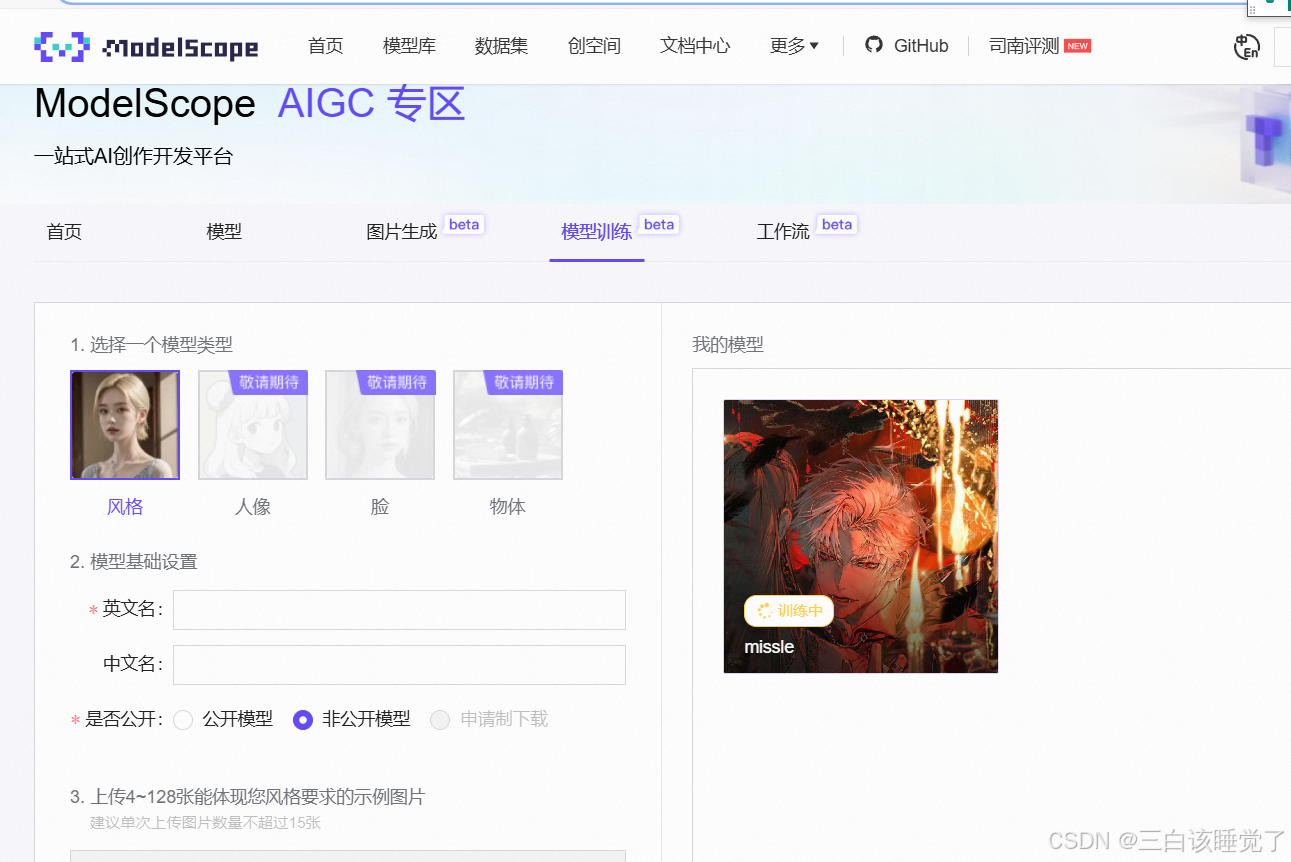
怎么说呢这很难评,看来抽象也是一种艺术,果然世界上不能没有画师太太 ,嗯也可能是我的问题我说的太少了太抽象了,对比一下太抽象了,我明明传进去那么好看的图。
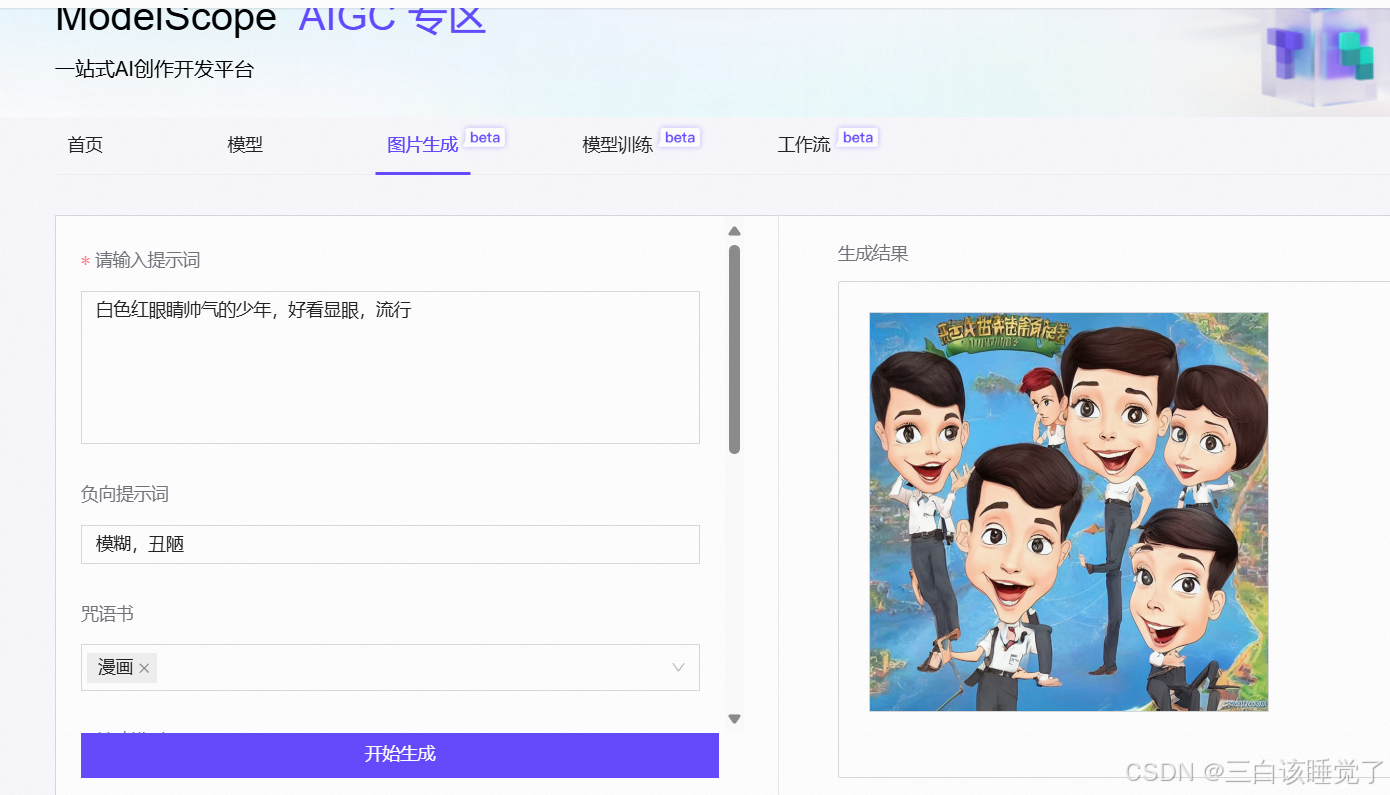
其他的还有阿里muse研究的FLUX,快手研究的文生图等等,有兴趣可以点进去玩玩。
五、分析优化
咳咳(敲小黑板了),来众所周知第一步肯定是要导包了。这步是肯定不需要再优化的。
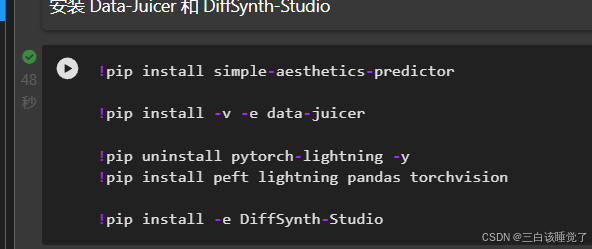
!pip install simple-aesthetics-predictor
!pip install -v -e data-juicer
!pip uninstall pytorch-lightning -y
!pip install peft lightning pandas torchvision
!pip install -e DiffSynth-Studio那么就该导入数据了,下面下载数据集,因为这个数据集不是我找的是自带的,我就没有再次修改了,你们可以修改或者再添加数据集,更进一步优化。
#下载数据集
from modelscope.msdatasets import MsDataset
ds = MsDataset.load(
'AI-ModelScope/lowres_anime',
subset_name='default',
split='train',
cache_dir="/mnt/workspace/kolors/data"
)
import json, os
from data_juicer.utils.mm_utils import SpecialTokens
from tqdm import tqdm
os.makedirs("./data/lora_dataset/train", exist_ok=True)
os.makedirs("./data/data-juicer/input", exist_ok=True)
with open("./data/data-juicer/input/metadata.jsonl", "w") as f:
for data_id, data in enumerate(tqdm(ds)):
image = data["image"].convert("RGB")
image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg")
metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]}
f.write(json.dumps(metadata))
f.write("\n")
有了数据集,那么就要把数据集转化为机器能够看懂的数据,并且数据集还有些需要处理的地方,所以这就是机器学习里面的数据预处理。
那么对于数据预处理这方面,可以从下面几个方面对代码进行优化:
1、可以批量处理,加快模型的图形处理速度。
2、直接构架DataFarme模型,在读取时时候构建模型
import pandas as pd
import os
import json
from PIL import Image
from tqdm import tqdm
from multiprocessing import Pool
# 定义处理每个数据项的函数
def process_data(data_item):
data_id, data = data_item
text = data["text"]
image = Image.open(data["image"][0])
image_path = f"./data/lora_dataset_processed/train/{data_id}.jpg"
image.save(image_path)
return (f"{data_id}.jpg", text)
# 写入配置文件
data_juicer_config = """
# global parameters
project_name: 'data-process'
dataset_path: './data/data-juicer/input/metadata.jsonl' # path to your dataset directory or file
np: 4 # number of subprocess to process your dataset
text_keys: 'text'
image_key: 'image'
image_special_token: '<__dj__image>'
export_path: './data/data-juicer/output/result.jsonl'
# process schedule
# a list of several process operators with their arguments
process:
- image_shape_filter:
min_width: 1024
min_height: 1024
any_or_all: any
- image_aspect_ratio_filter:
min_ratio: 0.5
max_ratio: 2.0
any_or_all: any
"""
config_file_path = "data/data-juicer/data_juicer_config.yaml"
os.makedirs(os.path.dirname(config_file_path), exist_ok=True)
with open(config_file_path, "w") as file:
file.write(data_juicer_config.strip())
# 运行数据处理命令
os.system(f"dj-process --config {config_file_path}")
# 创建数据目录
os.makedirs("./data/lora_dataset_processed/train", exist_ok=True)
# 读取 JSONL 文件并解析
with open("./data/data-juicer/output/result.jsonl", "r") as file:
data_list = [(i, json.loads(line)) for i, line in enumerate(file)]
# 使用并行处理优化图像保存和数据处理
with Pool() as pool:
results = list(tqdm(pool.imap(process_data, data_list), total=len(data_list)))
# 创建 DataFrame
file_names, texts = zip(*results)
data_frame = pd.DataFrame({"file_name": file_names, "text": texts})
# 保存到 CSV 文件
data_frame.to_csv("./data/lora_dataset_processed/train/metadata.csv", index=False, encoding="utf-8-sig")
在下载和训练模型方面有如下优化:
1、使用subprocess代替原来的可以提供更好的功能
2、使用函数封装
3、添加错误处理
4、目录检查
import os
import subprocess
from diffsynth import download_models
def download_and_prepare_models():
"""下载所需的模型。"""
try:
download_models(["Kolors", "SDXL-vae-fp16-fix"])
except Exception as e:
print(f"Error downloading models: {e}")
raise
def train_model():
"""执行模型训练。"""
cmd = [
"python", "DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py",
"--pretrained_unet_path", "models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"--pretrained_text_encoder_path", "models/kolors/Kolors/text_encoder",
"--pretrained_fp16_vae_path", "models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors",
"--lora_rank", "16",
"--lora_alpha", "4.0",
"--dataset_path", "data/lora_dataset_processed",
"--output_path", "./models",
"--max_epochs", "1",
"--center_crop",
"--use_gradient_checkpointing",
"--precision", "16-mixed"
]
try:
result = subprocess.run(cmd, check=True, text=True, capture_output=True)
print(result.stdout)
except subprocess.CalledProcessError as e:
print(f"Error during model training: {e.stderr}")
raise
def ensure_directories_exist():
"""确保必要的目录存在。"""
os.makedirs("models", exist_ok=True)
os.makedirs("data/lora_dataset_processed", exist_ok=True)
if __name__ == "__main__":
ensure_directories_exist()
download_and_prepare_models()
train_model()
在加载和LoRA应用流程方面:增加异常处理,只加载必要的权重,减小负担。
from diffsynth import ModelManager, SDXLImagePipeline
from peft import LoraConfig, inject_adapter_in_model
import torch
def load_lora(model, lora_rank, lora_alpha, lora_path):
try:
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",
target_modules=["to_q", "to_k", "to_v", "to_out"],
)
model = inject_adapter_in_model(lora_config, model)
state_dict = torch.load(lora_path, map_location="cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(state_dict, strict=False)
return model
except Exception as e:
print(f"Error loading LoRA weights: {e}")
raise
# Load models with proper device and dtype
model_manager = ModelManager(
torch_dtype=torch.float16,
device="cuda" if torch.cuda.is_available() else "cpu",
file_path_list=[
"models/kolors/Kolors/text_encoder",
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors"
]
)
pipe = SDXLImagePipeline.from_model_manager(model_manager)
# Load LoRA into the model
pipe.unet = load_lora(
pipe.unet,
lora_rank=16,
lora_alpha=2.0,
lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt"
)
下面是优化之后出来的图像,我懒得改文字了就还是原来的文字描述。





最后祝大家七夕快乐 。祝大家都可以找到对象,而不是像我一样七夕还在敲代码。